Wa Documentation Release 3.3.1.Dev1
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

How to Play Angry Birds
wikiho w.co m http://www.wikihow.com/Play-Angry-Birds How to Play Angry Birds Edit Edited by Snailpet, Mel, Spyagent, Postoum and 43 others Angry Birds is a very widely known smartphone and electronic tablet application game that has been downloaded over 500 million times across platf orms[1]. Here's how to play this f amous game if you haven't already tried it. Steps 1. 1 Download the game to your phone, iPod, tablet or computer. There are both f ree and paid versions of Angry Birds, plus an occasional seasonal special. Try the f ree version f irst; that way you can determine whether you even enjoy the game or not (it's very likely that you will). 2. 2 Understand what you're trying to do. The goal in each level is to get rid of the pigs. The complacent pigs are usually blocked by wood, glass, stone or another material arranged into creative structures. You will need to use the angry birds to get rid of both the obstacles and pigs. You can now get Angry Birds on a MacBook if you have the MacBook App store. Likewise, the PC version can also be downloaded f rom the of f icial website (in the f orm of a trial, similar to the f ree versions on handheld devices). You have to purchase an activation key in order to f ully unlock the game. You can also download the game through the Google Chrome web browser's app store. On an Android device the f ull version is available f or f ree. -

June 2012 FPF Mobile Apps Study INSIDE COVER
COVER June 2012 FPF Mobile Apps Study INSIDE COVER ABOUT THE FUTURE OF PRIVACY FORUM The Future of Privacy Forum (FPF) is a Washington, DC-based think tank that seeks to advance responsible data practices. The forum is led by Internet privacy experts Jules Polonetsky and Christopher Wolf and includes DQDGYLVRU\ERDUGFRPSULVHGRIOHDGLQJĺJXUHVIURPLQGXVWU\DFDGHPLDODZDQG advocacy groups. FPF hosts ApplicationPrivacy.org that aims to provide application GHYHORSHUV ZLWK WKH WRROV DQG UHVRXUFHV QHFHVVDU\ WR LPSOHPHQW UHVSRQVLEOH information collection and use practices. The site includes links to privacy policy generators and our recently released “Best Practices for Mobile $SSOLFDWLRQ'HYHORSHUV5HSRUWrFUHDWHGMRLQWO\ZLWKWKH&HQWHUIRU'HPRFUDF\ and Technology. 5HVHDUFK IRU WKH -XQH )3) 0RELOH $SSV 6WXG\ ZDV OHG E\ )3) /HJDO 3ROLF\ )HOORZ /LD 6KHHQD DQG DVVLVWHG E\ OHJDO LQWHUQV -RKQ $OIRUG DQG Rachel Coffin. June 2012 FPF Mobile Apps Study TABLE OF CONTENTS I. Introduction ...............................................................1 II. Description ...............................................................1 III. Study Results ..........................................................2 IV. Methodology ............................................................6 V. Resources .................................................................6 Exhibit 1: Free Apps .....................................................7 Exhibit 2: Paid Apps .....................................................9 1 I. INTRODUCTION II. DESCRIPTION 6PDUWSKRQHVKDYHEHFRPHXELTXLWRXVZLWK -

A Study on the Successfulness of Mobile Game: the Case of Angrybirds
International Journal of Emerging Science and Engineering (IJESE) ISSN: 2319–6378, Volume-1, Issue-11, September 2013 A Study on the Successfulness of Mobile Game: The Case of Angrybirds Farahwahida Mohd, Ezri Hielmi Che Daud Abstract— This research is to study on the successfulness of the The market for mobile games change radically with the mobile game. An Angrybirds game has been chosen as a case launch of the Apple App Store in 2008, giving a big boost to study. One of the reasons of using Angry Birds as a case study is develop power in particular and broadening the market from due to its high popularity worldwide, including our country niche proposition to virtually every Smartphone owner Malaysia. It is so popular that even children at the age of 5-12 years old are also very familiar with this title. Due to that matter, a downloading mobile games (European Games Developer model adopted majorly through the adaptation of mobile game Federation, 2010). features stated by Mark Overmars and some little combination the Among of all mobile games available on the market, Angry Nielsen’s Ten Heuristics were used in order to design Birds game has been one of the great runaway hits of 2010. questionnaire for surveys. This study would identify the The game topped the iTunes charts for most of the year – the relationship among Games Design, Controls, Social Features, price tag on the Apple marketplace was only a buck, making Assets and Navigational Features in determining mobile game Angry Birds very attractive to casual gamers – and a free successfulness. -

Angry Birds Seasons Cheat Codes
Angry birds seasons cheat codes Angry Birds Seasons cheat codes will allow you to unlock and get all In-App purchases for free. You can get Shockwave Small Pack. We have 3 questions and 3 answers for this game. Check them out to find answers or ask your own to get the exact game help you need. Levels 16 to Angry Birds Seasons Questions. We have 4 questions and 1 answers for this game. Check them out to find answers or ask your own to get the exact game help. Get all the inside info, cheats, hacks, codes, walkthroughs for Angry Birds: Seasons on GameSpot. Cheats, Tips, Tricks, Video Walkthroughs and Secrets for Angry Birds: Seasons on the Windows Phone, with a game help system for those that are stuck. Angry Birds: Seasons cheats, codes, walkthroughs, guides, FAQs and more for Android. Android Cheats - Angry Birds: This page contains a list of cheats, codes, Easter eggs, tips, and other secrets for Angry Birds Rio for Android. If you've discovered a cheat Angry Birds Seasons Walkthrough · Angry Birds Rio. For Angry Birds: Seasons on the iOS (iPhone/iPad), GameFAQs has 4 cheat codes and secrets. 1. put trainer in game folder 2. open trainer and locate game exe 3. start game and then Alt& tap the game 4. This Angry Birds Seasons Hack Cheat Codes Free for Android and iOS is what you need to bypass in-app purchases and gain additional extra items at no. Angry Birds. Cheatbook is the resource for the latest Cheats, tips, cheat codes, unlockables, hints and secrets to get the edge to win. -

Angry Birds 2 Hack Apk
angry birds 2 hack apk mod Angry Birds 2 v 2.40.0 Hack mod apk (Unlimited Money) Join hundreds of millions of players for FREE and start your sling adventure on Angry Birds now! Join your friends, gather in clans and face challenges and events in the new game modes. Are you ready to evolve your birds and show your skills in the most daring game of Angry Birds? Angry Birds 2 is the best way to meet all the iconic characters and experience the fun gameplay that has won the hearts (and free time) of millions of players. Features: - CHOOSE YOUR BIRD. Choose which bird to put in the slingshot and defeat the pigs with strategy! - MULTI-STAGE LEVELS. Play fun and challenging levels with multiple stages - just watch out for Boss Pigs! - DAILY CHALLENGES. Got a minute? Complete a daily challenge and earn quick rewards. - LEVEL your birds with feathers and increase your scoring power. Build the ultimate herd! - JOIN A CLAN to take down the pigs with friends and players from around the world. - IMPRESS THE MIGHTY EAGLE in the Mighty Eagle Bootcamp and earn coins to use in your exclusive store. - COMPETE in the ARENA. Compete with other players to have friendly fun by throwing birds and proving who is the best. Supported Android (4.1 and up) Ice Cream Sandwich (4.0 - 4.0.4),Jelly Bean (4.1 - 4.3.1),KitKat (4.4 - 4.4.4),Lollipop (5.0 - 5.1.1),Marshmallow (6.0 - 6.0.1),Nougat (7.0 – 7.1.1),Oreo (8.0-8.1), Pie(9.0) Angry Birds Go! MOD APK 2.9.1 (Unlimited Money) Angry Birds Go! MOD APK is a racing game produced by Rovio publisher and inspired by Mario Kart. -

User Manual Defender Smart Call HD2 Smart TV Box and Skype Camera for TV the Device Runs on the Operating System Android
User manual Defender Smart Call HD2 Smart TV box and Skype camera for TV The device runs on the operating system Android General rules The user manual contains all the information about the security and instruction of proper usage. To avoid accidents and the device damage make sure that before use, you read the instruction carefully . Use and store the product at a room temperature and humidity. Do not drop the device. Do not disconnect the device when formatting or updating in process, it may cause operating error system. Do not disassemble the device. Do not clean it by alcohol, thinner and benzol. We reserve the right to upgrade and to modify the device. We take responsibility only for a guarantee on products. Users should care about the safety of their data in the device. We are not responsible for the loss of data. The product is not waterproof. The illustrations in the manual and the illustrations on your device can be different. I Appearance 1. On/off button 2. Camera 3. Backlight 4. Microphone 5. MicroSD slot 6. USB connector 7. mini-USB connector 8. Power supply connector 9. HDMI output 10. AV-out 11. Output for connecting headphones 1. On/off button. When connecting to the source the power, the device starts automatically. Hold button for 5 seconds to turn off or turn on the device. 2. Camera. Built-in HD camera 5 megapixel. 3. Backlight. Turnes on when using the camera in low light 4. Microphone. Built-in microphone with a unique noise reduction system is able to take sound at a distance of 3-5 m. -

Uncovering the Corporate Brand Identity: a Qualitative Study of Rovio Entertainment
Lund School of Economics and Management Department of Business Administration BUSN39 – Business Administration: Global Marketing Master Thesis – MSc Business and Economics in International Marketing & Brand Management Spring 2014 Uncovering the Corporate Brand Identity: A qualitative study of Rovio Entertainment Authors: Gabriele Di Napoli Thomas Koponen Supervisor: Clara Gustafsson Di Napoli and Koponen Acknowledgments We would like to acknowledge a few people who have contributed greatly to our Masters thesis. They have facilitated the completion of this Master thesis and provided us with guidance, knowledge and support throughout the process. First, we would like to thank Rovio Entertainment and all the respondents who have given us their time and commitment to understand the company and to successfully complete our thesis. Second, we would like to thank our supervisor Clara Gustafsson for her advice and useful insights regarding the thesis writing process. Finally, a special thank you goes out to our families. Your continuous love and support means the world to us. We would not be here, if it were not for you and your sacrifices. Thank you. 24th of May 2014, Lund ______________________ ______________________ Gabriele Di Napoli Thomas Koponen 1 Di Napoli and Koponen Abstract Title: Uncovering the Corporate Brand Identity: A Case Study on Rovio Entertainment Date of the Seminar: 2014-06-02 Course: BUSN39 - Global Marketing Authors: Gabriele Di Napoli and Thomas Koponen Supervisor: Clara Gustafsson Keywords: product brand identity, corporate brand, corporate brand identity, corporate brand building functions, SME growth, strategic brand management. Thesis purpose: To identify and describe the corporate brand identity of a successful company from the mobile gaming industry, examining its corporate brand development at different growth stages. -
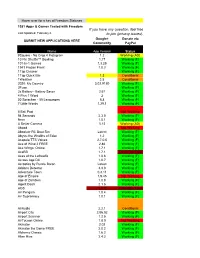
Want to C If You Have Any Question, Feel Free to Visit the F to Join (Privacy
Hover over for a key of Freedom Statuses Freedom is now updated to 1.0.2. Update now and try it with new applications! 1381 Apps & Games Tested with Freedom Want to contribute new apps and submit changes? Feel free to add them to the http://bit.ly/WWLmaV and fill out the form. If you have any question, feel free to visit the FAQ section of "Freedom for Android" Google+ community or ask a question. The community is currently private but is accepting everyone that wants Last Updated: February 6 to join (privacy issues). Note:The status of the application may not be 100% correct as Freedom has been updated or the game's in-app purchase system has been changed. Google+ Donate via SUBMIT NEW APPLICATIONS HERE Community PayPal Name App Version Status #Square - No Crop 4 Instagram 1.2 Working (AD) 10 Pin Shuffle™ Bowling 1.17 Working (F) 101-in-1 Games 1.3.29 Working (F) 1941 Frozen Front 1.0.3 Working (F) 1Tap Cleaner Working (F) 1Tap Quick Bar 1.3 Conditional 1Weather 2.5 Conditional 2020: My Country 3.02.9180 Working (F) 2Fuse Working (F) 2x Battery - Battery Saver 2.61 Working (F) 4 Pics 1 Word 2 Working (F) 50 Sprachen - 50 Languages 6.8 Working (F) 7 Little Words 1.29.1 Working (F) 8 Ball Pool Not Working 94 Seconds 2.3.0 Working (F) 9mm 1.0.1 Working (F) A Better Camera 3.12 Working (AD) Abood Not Working Absolute RC Boat Sim Latest Working (F) Abyss: the Wraiths of Eden 1.2 Working (F) Acapela TTS Voices 2.7.0.5 Working (F) Ace of Wind 2 FREE 2.86 Working (F) Ace Wings: Online 1.7.1 Working (F) AceBB 1.7.1 Cannot be Free Aces of the Luftwaffe 1.0.8 Working (F) Across Age DX 1.0.7 Working (F) Acrostics by Puzzle Baron Latest Working (F) Addons Detector 3.3.0 Working (F) Adventure Town 0.3.11 Working (F) Age of Empire 1.9.45 Not Working Age of Zombies 1.0.8 Working (F) Agent Dash 2.1.6 Working (F) AGS 1.0.8 Cannot be Free Air Penguin 1.0.4 Working (F) Air Supremacy 1.0.1 Working (F) AirAudio 2.2.1 Conditional Airport City 2.06.02 Working (F) Airport Scanner 1.2.5 Working (F) AirTycoon Online. -

Story of Birds Who Cannot Fly but They Have Enough Angriness
RISUS - Journal on Innovation and Sustainability Volume 5, número 1 – 2014 ISSN: 2179-3565 Editor Científico: Arnoldo José de Hoyos Guevara Editora Assistente: Letícia Sueli de Almeida Avaliação: Melhores práticas editoriais da ANPAD What Lead to the Successful Mobile Phone Game? – Story of birds who cannot fly but they have enough angriness Yang Liu Department of Production, University of Vaasa Address: Wolffintie 34, 65200, Vaasa E-mail: [email protected] Jaakko Iivonen Department of Production, University of Vaasa E-mail: [email protected] Abstract: This article will consist of analyzing some factors which are the most important for the successful mobile phone game. There are going to be some common history of how mobile phone games are developed and how this whole game application business has started. Main focus in this article is based on analyzing and finding some key factors which are the most relevant for successful mobile phone game and how they can be designed. This article is not based on technical details of mobile phones and there is only some information which consists of a little bit of technical phrases. Angry Birds mobile phone game is excellent example of successful mobile game and it will be analyzed rather deeply in this article. Analyzing will not be based on only how to play game but whole Angry Birds phenomenon will be considered. Developments of mobile phone games have been very fast even though the first and nowadays classic mobile phone games (such as Snake) become in 1970s. Last year has been golden age for mobile phone game designers and this business area is still developing very fast. -

Declaration of Matthew Fischer in Support of 18 MOTION For
Apple Inc. v. Amazon.Com, Inc. Doc. 23 Att. 13 EXHIBIT 10 TO DECLARATION OF MATTHEW FISCHER Dockets.Justia.com Amazon Media Room: News Release Page 1 of 3 Hello. Sign in to get personalized recommendations. New customer? Start here. Your Amazon.com | Today's Deals | Gifts & Wish Lists | Gift Cards Your Account | Help Shop All Departments Search All Departments Cart Wish List Media Room Home News Release News Releases << Back Media Room Updates Media Kit Introducing Amazon Appstore for Android Inquiries Receive E-mail Alerts Customers Can Try Apps Before They Buy with New Test Sign up to receive e-mail alerts Drive Feature Images whenever Amazon.com posts Angry Birds Rio for Android Available Exclusively in the new information in the Media Special Content Amazon Appstore--Free for a Limited Time Room. Just enter your e-mail address and click Submit. Amazon Support for Author SEATTLE, Mar 22, 2011 (BUSINESS WIRE) -- Amazon.com, Inc. (NASDAQ:AMZN) today announced the launch of the and Writer Groups Amazon Appstore for Android at www.amazon.com/appstore. Amazon and the Customers can now find, discover - test! - and buy Android apps using the convenient shopping experience that Amazon Submit Environment customers know and love. An innovative new feature called Investor Relations "Test Drive" will enable customers to test apps on a simulated Android phone. Customers control the app through their Quick Links Kindle Media Room computer using a mouse. Media Tools Amazon Payments Media "Test Drive lets customers truly experience an app before they Room commit to buying. It is a unique, new way to shop for apps," • Bestsellers (For Example: MP3 says Paul Ryder, vice president of electronics for Amazon.com. -

Free Angry Birds Game Info
Free angry birds game info Angry Birds is a video game franchise created by Finnish company Rovio Entertainment. Tile-matching, This is the 14th game of the series that features match-3 gameplay that has the player popping balloons to free the Angry Birds. June .. According to The Register, the information was leaked through the in-game Angry Birds (video game) · The Angry Birds Movie · Rovio Entertainment. Use the unique powers of the Angry Birds to destroy the greedy pigs' defenses! The survival of the Angry Birds is at stake. Dish out revenge on the greedy pigs. Playing Angry Birds is great, but playing for free is even better. Each game on our portal doesn't require you to sign in, provide your information or pay to play. Angry Birds Games: Enjoy the world's most popular mobile game, launch birds into pigs, and play one of our many free, online Angry Birds games! Play the best Angry Birds games and watch Angry Birds videos! Free online fun with the Angry Birds and the bad pigs.Angry Birds Space · Free Angry Birds · Bad Piggies · Angry Birds Halloween HD. All of our iconic Angry Birds games on one page. Download them all Birdier. The Angry Birds are back in the sequel to the biggest mobile game of all time. The home of Rovio - maker of Angry Birds, Bad Piggies, Battle Bay and many more! Read our privacy policy for information on how we handle sensitive. Angry Birds has become the most downloaded mobile game in history. No biggie. Read more for info on the latest updates, gameplay videos, and more! Angry Birds, free and safe download. -

Shining Stars: Supercell
The Finnish Game Industry The Finnish game industry has been growing dramatically during the past three years. In Q1/2014 Finnish game industry consists of more than 200 companies. Significant part of the companies develop mobile games, but there is development virtually to all existing platforms. The start- up scene is vibrant. Over 50% of the existing game companies have been established during last couple of years. The most well-known Finnish game companies are at the moment Supercell with its Clash of Clans, and Rovio with its Angry Birds, but these superstar companies are just the tip of the iceberg. Though most of the well established companies are located in capital area, the development of the game industry is rapid in regional areas also. Picture: Supercell | HayDay The Finnish Game Industry The Finnish Game Industry Pictures of the front cover; • Fingersoft / Hill Climb Racing The global nature of game business and small • Frogmind / Badland GROWTH: • Grand Cru / Supernauts 2012-2013 size of the domestic market mean that the • Rovio / Angry Birds Classic • Supercell / Clash of Clans game industry is now a key component in Finland’s exports and economy, with well over Pictures of the back cover 260% • Cornfox & Brothers / Oceanhorn 90% of the production exported. • Redlynx / Trials Frontier • Remedy / Quantum Break • Supercell / Hay Day • Tribeflame / Benji Bananas It is also worth noticing that the total impact of the Finnish game business is even bigger than the value of the core of the industry (game development and services). When additional business activities and investments are taken into consideration, the total value of the entire branch is over two billion Euros.