Infoprint Font Collection V3.5
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

ST.36 Page: 3.36.1
HANDBOOK ON INDUSTRIAL PROPERTY INFORMATION AND DOCUMENTATION Ref.: Standards – ST.36 page: 3.36.1 STANDARD ST.36 Version 1.2 RECOMMENDATION FOR THE PROCESSING OF PATENT INFORMATION USING XML (EXTENSIBLE MARKUP LANGUAGE) Revision adopted by ST.36 Task Force of the Standards and Documentation Working Group (SDWG) on November 23, 2007 TABLE OF CONTENTS INTRODUCTION ............................................................................................................................................................ 2 DEFINITIONS ................................................................................................................................................................. 3 SCOPE OF THE STANDARD ........................................................................................................................................ 3 REQUIREMENTS OF THE STANDARD........................................................................................................................ 4 General ......................................................................................................................................................................... 4 Characters .................................................................................................................................................................... 5 Naming international common elements....................................................................................................................... 6 Naming office-specific elements -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Hong Kong Supplementary Character Set – 2016 (Draft)
中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Hong Kong Supplementary Character Set – 2016 (Draft) Office of the Government Chief Information Officer & Official Languages Division, Civil Service Bureau The Government of the Hong Kong Special Administrative Region April 2017 1/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Table of Contents Preface Section 1 Overview……………….……………………………………………. 1 - 1 Section 2 Coding Scheme of the HKSCS–2016….……………………………. 2 - 1 Section 3 HKSCS–2016 under the Architecture of the ISO/IEC 10646………. 3 - 1 Table 1: Code Table of the HKSCS–2016……………………………………….. i - 1 Table 2: Newly Included Characters in the HKSCS–2016...………………….…. ii - 1 Table 3: Compatibility Characters in the HKSCS–2016…......………………..…. iii - 1 2/21 中 文 界 面 諮 詢 委 員 會 工 作 小 組 文 件 編 號 2017/02 (B) Preface After the first release of the Hong Kong Supplementary Character Set (HKSCS) in 1999, there have been three updated versions. The HKSCS-2001, HKSCS-2004 and HKSCS-2008 were published with 116, 123 and 68 new characters added respectively. A total of 5 009 characters were included in the HKSCS-2008. These publications formed the foundation for promoting the adoption of the ISO/IEC 10646 international coding standard, and were widely supported and adopted by the IT sector and members of the public. The ISO/IEC 10646 international coding standard is developed by the International Organization for Standardization (ISO) to provide a common technical basis for the storage and exchange of electronic information. -
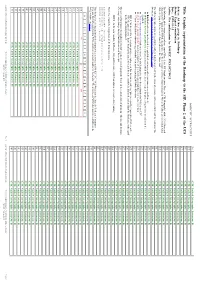
Netscape: Roadmap to Plane 2 (SIP) of ISO/IEC 10646 and Unicode
14 (CJK Unified Ideographs Extension B) ISO/IEC JTC1/SC2/WG2 N2115 15 (CJK Unified Ideographs Extension B) Title: Graphic representation of the Roadmap to the SIP, Plane 2 of the UCS 16 (CJK Unified Ideographs Extension B) 17 (CJK Unified Ideographs Extension B) Source: Ad hoc group on Roadmap 18 (CJK Unified Ideographs Extension B) Status: Expert contribution 19 (CJK Unified Ideographs Extension B) Date: 1999-09-15 Action: For confirmation by ISO/IEC JTC1/SC2/WG2 1A (CJK Unified Ideographs Extension B) 1B (CJK Unified Ideographs Extension B) The following tables comprise a real-size map of Plane 2, the SIP (Supplementary Plane for CJK Ideographs) of the UCS (Universal 1C (CJK Unified Ideographs Extension B) Character Set). To print the HTML document it may be necessary to set the print percentage to 90% as the tables are wider than A4 or US Letter paper. The tables are formatted to use the Times font. 1D (CJK Unified Ideographs Extension B) 1E (CJK Unified Ideographs Extension B) The following conventions are used in the table to help the user identify the status of (colours can be seen in the online version of this document, http://www.dkuug.dk/jtc1/sc2/wg2/docs/n2115.pdf): 1F (CJK Unified Ideographs Extension B) 20 (CJK Unified Ideographs Extension B) Bold text indicates an allocated (i.e. published) character collection (none as yet in Plane 2). (Bold text between parentheses) indicates scripts which have been accepted for processing toward inclusion in the 21 (CJK Unified Ideographs Extension B) standard. 22 (CJK Unified Ideographs Extension B) (Text between parentheses) indicates scripts for which proposals have been submitted to WG2 or the UTC. -

IRG N2153 IRG Principles and Procedures 2016-10-20 Version 8Confirmed Page 1 of 40 2.3.3
INTERNATIONAL ORGANIZATION FOR STANDARDIZATION ORGANISATION INTERNATIONALE DE NORMALISATION ISO/IEC JTC 1/SC 2/WG 2/IRG Universal Coded Character Set (UCS) ISO/IEC JTC 1/SC 2/WG 2/IRGN2153 SC2N5405 (Revision of IRG N1503/N1772/N1823/N1920/N1942/N1975/N2016/N2092) 2016-10-20 Title: IRG Principles and Procedures(IRG PnP) Version 9 Source: IRG Rapporteur Action: For review by the IRG and WG2 Distribution: IRG Member Bodies and Ideographic Experts Editor in chief: Lu Qin, IRG Rapporteur References: IRG Meeting No. 45 Recommendations(IRGN2150), IRG Special Meeting No. 44 discussions and recommendation No. 44.6(IRGN2080), IRGN2016, and IRGN 1975 and IRG Meeting No. 42 discussions IRGN 1952 and feedback from HKSARG, Japan, ROK and TCA, IRG 1920 Draft(2012-11-15), Draft 2(2013-05-04) and Draft 3(2013-05-22); feedback from Japan(2013-04-23) and ROK(2013-05-16 and 2013-05-21); and IRG Meeting No. 40 discussions IRG 1823 Draft 3 and feedback from HKSAR, Korea and IRG Meeting No. 39 discussions IRGN1823 Draft2 feedback from HKSAR and Japan IRG N1823Draft_gimgs2_Feedback IRG N1781 and N1782 Feedback from KIM Kyongsok IRGN1772 (P&P Version 5) IRG N1646 (P&P Version 4 draft) IRG N1602 (P&P Draft 4) and IRG N1633 (P&P Editorial Report) IRG N1601 (P&P Draft 3 Feedback from HKSAR) IRG N1590 and IRGN 1601(P&P V2 and V3 draft and all feedback) IRG N1562 (P&P V3 Draft 1 and Feedback from HKSAR) IRG N1561 (P&P V2 and all feedback) IRG N1559 (P&P V2 Draft and all feedback) IRG N1516 (P&P V1 Feedback from HKSAR) IRG N1489 (P&P V1 Feedback from Taichi Kawabata) IRG N1487 (P&P V1 Feedback from HKSAR) IRG N1465, IRG N1498 and IRG N1503 (P&P V1 drafts) Table of Contents 1. -

Character and String Representation
Character and String Representation CS520 Department of Computer Science University of New Hampshire CDC 6600 • 6-bit character encodings • i.e. only 64 characters • Designers were not too concerned about text processing! The table is from Assembly Language Programming for the Control Data 6000 series and the Cyber 70 series by Grishman. C Strings • Usually implemented as a series of ASCII characters terminated by a null byte (0x00). • ″abc″ in memory is: n 0x61 n+1 0x62 n+2 0x63 n+3 0x00 Unicode • The space of values is divided into 17 planes. • Plane 0 is the Basic Multilingual Plane (BMP). – Supports nearly all modern languages. – Encodings are 0x0000-0xFFFF. • Planes 1-16 are supplementary planes. – Supports historic scripts and special symbols. – Encodings are 0x10000-0x10FFFF. • Planes are divided into blocks. Unicode and ASCII • ASCII is the bottom block in the BMP, known as the Basic Latin block. • So ASCII values are embedded “as is” into Unicode. • i.e. 'a' is 0x61 in ASCII and 0x0061 in Unicode. Special Encodings • The Byte-Order Mark (BOM) is used to signal endian-ness. • Has no other meaning (i.e. usually ignored). • Encoded as 0xFEFF. • 0xFFFE is a noncharacter. – Cannot appear in any exchange of Unicode. • So file can be started with a BOM; the reader can then know the endian-ness of the file. • In absence of a BOM, Big Endian is assumed. Other Noncharacters • There are a total of 66 noncharacters: – 0xFFFE and 0xFFFF of the BMP – 0x1FFFE and 0x1FFFF of plane 1 – 0x2FFFE and 0x2FFFF of plane 2 – etc., up to – 0x10FFFE and 0x10FFFF of plane 16 – Also 0xFDD0-0xFDEF of the BMP. -

When Helping Hurts: an Ideographic Critique of Faith-Based Organizations in International Aid and Development
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by ePublications at Regis University Regis University ePublications at Regis University All Regis University Theses Spring 2018 When Helping Hurts: An Ideographic Critique of Faith-Based Organizations in International Aid and Development Allison Foust Regis University Follow this and additional works at: https://epublications.regis.edu/theses Recommended Citation Foust, Allison, "When Helping Hurts: An Ideographic Critique of Faith-Based Organizations in International Aid and Development" (2018). All Regis University Theses. 899. https://epublications.regis.edu/theses/899 This Thesis - Open Access is brought to you for free and open access by ePublications at Regis University. It has been accepted for inclusion in All Regis University Theses by an authorized administrator of ePublications at Regis University. For more information, please contact [email protected]. i WHEN HELPING HURTS: AN IDEOGRAPHIC CRITIQUE OF FAITH-BASED ORGANIZATIONS IN INTERNATIONAL AID AND DEVELOPMENT A thesis submitted to Regis College Honors Program in partial fulfillment of the requirements for Graduation with Honors by Allison Foust May 2018 ii Thesis written by Allison Foust Approved by __________________________________________________________________ Thesis Advisor __________________________________________________________________ Thesis Reader Accepted by __________________________________________________________________ Director, University Honors Program iii iv Acknowledgements This thesis is dedicated to the individuals who have molded me and supported me through the high points and low points of this project. I appreciate you all more than words can express. To Glenn, Char, Jeff, and Honey, thank you for opening your home and your hearts to me. I don’t think I would have been able to pursue this project nor become who I am today without your unconditional support the last two years. -

Information, Characters, Unicode
Information, Characters, Unicode Unicode © 24 August 2021 1 / 107 Hidden Moral Small mistakes can be catastrophic! Style Care about every character of your program. Tip: printf Care about every character in the program’s output. (Be reasonably tolerant and defensive about the input. “Fail early” and clearly.) Unicode © 24 August 2021 2 / 107 Imperative Thou shalt care about every Ěaracter in your program. Unicode © 24 August 2021 3 / 107 Imperative Thou shalt know every Ěaracter in the input. Thou shalt care about every Ěaracter in your output. Unicode © 24 August 2021 4 / 107 Information – Characters In modern computing, natural-language text is very important information. (“number-crunching” is less important.) Characters of text are represented in several different ways and a known character encoding is necessary to exchange text information. For many years an important encoding standard for characters has been US ASCII–a 7-bit encoding. Since 7 does not divide 32, the ubiquitous word size of computers, 8-bit encodings are more common. Very common is ISO 8859-1 aka “Latin-1,” and other 8-bit encodings of characters sets for languages other than English. Currently, a very large multi-lingual character repertoire known as Unicode is gaining importance. Unicode © 24 August 2021 5 / 107 US ASCII (7-bit), or bottom half of Latin1 NUL SOH STX ETX EOT ENQ ACK BEL BS HT LF VT FF CR SS SI DLE DC1 DC2 DC3 DC4 NAK SYN ETP CAN EM SUB ESC FS GS RS US !"#$%&’()*+,-./ 0123456789:;<=>? @ABCDEFGHIJKLMNO PQRSTUVWXYZ[\]^_ `abcdefghijklmno pqrstuvwxyz{|}~ DEL Unicode Character Sets © 24 August 2021 6 / 107 Control Characters Notice that the first twos rows are filled with so-called control characters. -

Iso/Iec 10646:2011 Fdis
Proposed Draft Amendment (PDAM) 2 ISO/IEC 10646:2012/Amd.2: 2012 (E) Information technology — Universal Coded Character Set (UCS) — AMENDMENT 2: Caucasian Albanian, Psalter Pahlavi, Old Hungarian, Mahajani, Grantha, Modi, Pahawh Hmong, Mende, and other characters Page 22, Sub-clause 16.3 Format characters Insert the following entry in the list of format characters: 061C ARABIC LETTER MARK 1107F BRAHMI NUMBER JOINER Page 23, Sub-clause 16.5 Variation selectors and variation sequences Remove the first sentence of the third paragraph (starting with ‘No variation sequences using characters’). Insert the following text at the end of the sub-clause. The following list provides a list of variation sequences corresponding to the use of appropriate variation selec- tors with allowed pictographic symbols. The range of presentations may include a traditional black and white text style, using FE0E VARIATION SELECTOR-15, or an ‘emoji’ style, using FE0F VARIATION SELECTOR-16, whose presentation often involves color/grayscale and/or animation. Sequence (UID notation) Description of sequence <0023, FE0E, 20E3> NUMBER SIGN inside a COMBINING ENCLOSING KEYCAP <0023, FE0F, 20E3> <0030, FE0E, 20E3> DIGIT ZERO inside a COMBINING ENCLOSING KEYCAP <0030, FE0F, 20E3> <0031, FE0E, 20E3> DIGIT ONE inside a COMBINING ENCLOSING KEYCAP <0031, FE0F, 20E3> <0032, FE0E, 20E3> DIGIT TWO inside a COMBINING ENCLOSING KEYCAP <0032, FE0F, 20E3> <0033, FE0E, 20E3> DIGIT THREE inside a COMBINING ENCLOSING KEYCAP <0033, FE0F, 20E3> <0034, FE0E, 20E3> DIGIT FOUR inside a COMBINING -

MSR-4: Annotated Repertoire Tables, Non-CJK
Maximal Starting Repertoire - MSR-4 Annotated Repertoire Tables, Non-CJK Integration Panel Date: 2019-01-25 How to read this file: This file shows all non-CJK characters that are included in the MSR-4 with a yellow background. The set of these code points matches the repertoire specified in the XML format of the MSR. Where present, annotations on individual code points indicate some or all of the languages a code point is used for. This file lists only those Unicode blocks containing non-CJK code points included in the MSR. Code points listed in this document, which are PVALID in IDNA2008 but excluded from the MSR for various reasons are shown with pinkish annotations indicating the primary rationale for excluding the code points, together with other information about usage background, where present. Code points shown with a white background are not PVALID in IDNA2008. Repertoire corresponding to the CJK Unified Ideographs: Main (4E00-9FFF), Extension-A (3400-4DBF), Extension B (20000- 2A6DF), and Hangul Syllables (AC00-D7A3) are included in separate files. For links to these files see "Maximal Starting Repertoire - MSR-4: Overview and Rationale". How the repertoire was chosen: This file only provides a brief categorization of code points that are PVALID in IDNA2008 but excluded from the MSR. For a complete discussion of the principles and guidelines followed by the Integration Panel in creating the MSR, as well as links to the other files, please see “Maximal Starting Repertoire - MSR-4: Overview and Rationale”. Brief description of exclusion -

New Ideographs in Unicode 3.0 and Beyond
New Ideographs in Unicode 3.0 and Beyond John H. Jenkins International and Text Group Apple Computer, Inc. 1) Background The Unicode Standard, version 2.1, contains a total of 21,204 East Asian ideographs. More than half (nearly 55%) of the encoded characters in the standard are ideographs. This ideographic repertoire, commonly referred to as “Unihan,” is already larger than the ideographic repertoires of most other major character set standards. The exceptions, however, use different unification rules than those used in Unihan, so although they provide more glyphic variants for characters than does Unihan, they actually encode about the same number of characters as Unihan. Nonetheless, Unihan is far from being an exhaustive set of ideographs—tens of thousands more remain unencoded. As a result, additions and extensions to Unihan will continue to be made as the Unicode Standard develops. The history of East Asian ideographs can be reliably traced back to the second millennium BCE, and all the major features of the current system were in place by the Zhou dynasty (ca. 1100 BCE). The shapes of the ideographs have altered over the centuries, and the Chinese language has continued to develop with new words coming into existence and old ones being dropped, but the writing system has endured. Chinese ideographs constitute the oldest writing system in the world still in common use. 15th International Unicode Conference 1 San Jose, CA, August/September 1999 New Ideographs in Unicode 3.0 and Beyond This long history is one of the major reasons why the collection of ideographs is so vast. -

Technical Study Universal Multiple-Octet Coded Character Set Coexistence & Migration
Technical Study Universal Multiple-Octet Coded Character Set Coexistence & Migration NIC CH A E L T S T U D Y [This page intentionally left blank] X/Open Technical Study Universal Multiple-Octet Coded Character Set Coexistence and Migration X/Open Company Ltd. February 1994, X/Open Company Limited All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the prior permission of the copyright owners. X/Open Technical Study Universal Multiple-Octet Coded Character Set Coexistence and Migration ISBN: 1-85912-031-8 X/Open Document Number: E401 Published by X/Open Company Ltd., U.K. Any comments relating to the material contained in this document may be submitted to X/Open at: X/Open Company Limited Apex Plaza Forbury Road Reading Berkshire, RG1 1AX United Kingdom or by Electronic Mail to: [email protected] ii X/Open Technical Study (1994) Contents Chapter 1 Introduction............................................................................................... 1 1.1 Background.................................................................................................. 2 1.2 Terminology................................................................................................. 2 Chapter 2 Overview..................................................................................................... 3 2.1 Codesets.......................................................................................................