Nationality Classification Using Name Embeddings
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
![Arxiv:2104.00880V2 [Astro-Ph.HE] 6 Jul 2021](https://docslib.b-cdn.net/cover/4859/arxiv-2104-00880v2-astro-ph-he-6-jul-2021-94859.webp)
Arxiv:2104.00880V2 [Astro-Ph.HE] 6 Jul 2021
Draft version July 7, 2021 Typeset using LATEX twocolumn style in AASTeX63 Refined Mass and Geometric Measurements of the High-Mass PSR J0740+6620 E. Fonseca,1, 2, 3, 4 H. T. Cromartie,5, 6 T. T. Pennucci,7, 8 P. S. Ray,9 A. Yu. Kirichenko,10, 11 S. M. Ransom,7 P. B. Demorest,12 I. H. Stairs,13 Z. Arzoumanian,14 L. Guillemot,15, 16 A. Parthasarathy,17 M. Kerr,9 I. Cognard,15, 16 P. T. Baker,18 H. Blumer,3, 4 P. R. Brook,3, 4 M. DeCesar,19 T. Dolch,20, 21 F. A. Dong,13 E. C. Ferrara,22, 23, 24 W. Fiore,3, 4 N. Garver-Daniels,3, 4 D. C. Good,13 R. Jennings,25 M. L. Jones,26 V. M. Kaspi,1, 2 M. T. Lam,27, 28 D. R. Lorimer,3, 4 J. Luo,29 A. McEwen,26 J. W. McKee,29 M. A. McLaughlin,3, 4 N. McMann,30 B. W. Meyers,13 A. Naidu,31 C. Ng,32 D. J. Nice,33 N. Pol,30 H. A. Radovan,34 B. Shapiro-Albert,3, 4 C. M. Tan,1, 2 S. P. Tendulkar,35, 36 J. K. Swiggum,33 H. M. Wahl,3, 4 and W. W. Zhu37 1Department of Physics, McGill University, 3600 rue University, Montr´eal,QC H3A 2T8, Canada 2McGill Space Institute, McGill University, 3550 rue University, Montr´eal,QC H3A 2A7, Canada 3Department of Physics and Astronomy, West Virginia University, Morgantown, WV 26506-6315, USA 4Center for Gravitational Waves and Cosmology, Chestnut Ridge Research Building, Morgantown, WV 26505, USA 5Cornell Center for Astrophysics and Planetary Science and Department of Astronomy, Cornell University, Ithaca, NY 14853, USA 6NASA Hubble Fellowship Program Einstein Postdoctoral Fellow 7National Radio Astronomy Observatory, 520 Edgemont Road, Charlottesville, VA 22903, USA 8Institute of Physics, E¨otv¨osLor´anUniversity, P´azm´anyP. -

Liste Des Classés Sur Liste Complémentaire Du ENS Paris-Saclay
Session 2021 Liste des classés sur liste complémentaire du 06/07/2021 06:59 ENS Paris-Saclay - PSI 12927 Monsieur GRZECZKOWICZ Rémi, Jacques, Edouard 37 25148 Madame KOCH Marie-Liesse, Inès Isabelle 38 13389 Monsieur SCHULTZ Vincent, Arthur, François 39 258 Monsieur SOUFFRONT Alexandre, Roger, William 40 42457 Monsieur LE CORRE Baptiste, Pierre, Gildas 41 9319 Monsieur PLANCHE Victor, Louis 42 31393 Madame PLU Agathe, Agnès, Geneviève 43 2191 Monsieur BODELET Mathys, Ivan 44 25127 Monsieur DEMEY Pierre, François, Corneille 45 6989 Monsieur MANGONE Sébastien, Jean, Francesco 46 14099 Monsieur LOUVARD Enzo, Léo, Hugo 47 20290 Madame HEGRON Charlotte, Agathe 48 20509 Monsieur GAUDRON-DESJARDINS Antoine, Paul, Baptiste 49 17778 Monsieur CADET Antonin, Lucien, Aurélien 50 15528 Madame JEAN--MACTOUX Séléna, Justine 51 3033 Monsieur HATMI Bilel 52 36903 Madame DE MONTGOLFIER Inès, Iname 53 16880 Monsieur TYMINSKI- -PEREIRA Clément, Louis 54 3182 Monsieur BAALI Ilias 55 48474 Monsieur LE GUENNIC Yuan, Edwin 56 16075 Monsieur VALETTE Lino, Bruce, Tancrède 57 5574 Monsieur FAVIN-LÉVÊQUE Tanguy, Louis, Bernard 58 28886 Monsieur COURANT Clément, Louis, Takumi 59 15349 Monsieur TEROUANNE Cyprien, Justin, Christophe 60 26549 Monsieur TEINTURIER Arnaud 61 5798 Monsieur RICHE Arthur, Jean, Alain 62 14480 Madame RENAUD Marion, Claire, Chloé 63 40822 Monsieur POTTIER Julien, Alexandre, Léonard 64 24104 Madame TERNOIS Alice, Sophie, Stéphanie 65 2960 Monsieur LÉPICIER Damien, Jean-Max, André 66 1875 Monsieur DODEL Marc, Philippe Marie 67 21178 Monsieur -

Beyond Traditional Assumptions in Fair Machine Learning
Beyond traditional assumptions in fair machine learning Niki Kilbertus Supervisor: Prof. Dr. Carl E. Rasmussen Advisor: Dr. Adrian Weller Department of Engineering University of Cambridge arXiv:2101.12476v1 [cs.LG] 29 Jan 2021 This thesis is submitted for the degree of Doctor of Philosophy Pembroke College October 2020 Acknowledgments The four years of my PhD have been filled with enriching and fun experiences. I owe all of them to interactions with exceptional people. Carl Rasmussen and Bernhard Schölkopf have put trust and confidence in me from day one. They enabled me to grow as a researcher and as a human being. They also taught me not to take things too seriously in moments of despair. Thank you! Adrian Weller’s contagious positive energy gave me enthusiasm and drive. He showed me how to be considerate and relentless at the same time. I thank him for his constant support and sharing his extensive network. Among others, he introduced me to Matt J. Kusner, Ricardo Silva, and Adrià Gascón who have been amazing role models and collaborators. I hope for many more joint projects with them! Moritz Hardt continues to be an inexhaustible source of inspiration and I want to thank him for his mentorship and guidance during my first paper. I was extremely fortunate to collaborate with outstanding people during my PhD beyond the ones already mentioned. I have learned a lot from every single one of them, thank you: Philip Ball, Stefan Bauer, Silvia Chiappa, Elliot Creager, Timothy Gebhard, Manuel Gomez Rodriguez, Anirudh Goyal, Krishna P. Gummadi, Ian Harry, Dominik Janzing, Francesco Locatello, Krikamol Muandet, Frederik Träuble, Isabel Valera, and Michael Veale. -

Ontario County Marriage Records 1908-1935 (Files)
Ontario County Marriage Records 1908-1935 (Files) License Groom Last Name Groom First Name Bride Last Name Bride First Name Year Number Bin ABBEY W. CHANCEY MARKS ABIGAIL A. 1909 545 AM24-019 ABBOTT MICHAEL MOSES CATHERINE 1909 347 AM24-006 ABBOTT SAMUEL JACOB SALOOM 1913 2254 AM24-032 ABBOTT STANLEY FREI EVELYN 1929 1146 AM24-073 ABEL CARL J. FREI ALBERTINA 1909 578 AM24-019 ABEL PERRY H. BAKER ETHEL M. 1912 1654 AM24-017 ABERCROMBE VAUGH F. WOODCOCK ROBY 1927 398 AM24-059 ABESHENE ARTHUR WALTERS VINA 1932 2036 AM24-088 ABRAHAM JOHN BROWN MARY 1908 52 AM24-005 ABRAHAM ALBERT A. BARRY ELIZABETH 1912 1900 AM24-018 ABRAMSKY MORRIS GRUSKIN SYLVIA 1932 4031 AM24-102 ACE ELMER GETMAN CAROL 1934 5701 AM24-130 ACHESON RALPH H. STERLING MARIE E. 1911 1306 AM24-004 ACQUILANO DOMINIC TAYLOR HELEN 1934 5596 AM24-130 ADAM GEORGE S. BLEYER JOSEPHINE A. 1909 375 AM24-006 ADAM JOHN TOWERS CARRIE 1927 543 AM24-059 ADAMS FRED PENNER NINA 1908 98 AM24-005 ADAMS FRED M. DONNELLY ETHEL M. 1912 1629 AM24-017 ADAMS MILLER BAUM ELIZABETH 1912 1687 AM24-017 ADAMS ARTHUR L. BURNETT BERTHA B. 1914 2352 AM24-032 ADAMS LESTER G. LEWIS BERTHA M. 1926 162 AM24-045 ADAMS FLOYD MARSH HELEN 1931 1820 AM24-088 ADAMS HAROLD ARGETSINGER LUCILE 1932 1992 AM24-088 ADAMS THOMAS GAUDET EMMA 1934 5597 AM24-130 ADAMSON WILLIAM GOODMAN CARRIE 1928 646 AM24-060 ADAMSON FREDERICK MELIOUS AGNES 1930 1363 AM24-074 ADSITT ARNOLD SMITH MARY 1929 1011 AM24-073 ADSITT FLOYD KEAR DOROTHY 1934 5477 AM24-116 AEBERSOLD ELMER J. -

IN TAX LEADERS WOMEN in TAX LEADERS | 4 AMERICAS Latin America
WOMEN IN TAX LEADERS THECOMPREHENSIVEGUIDE TO THE WORLD’S LEADING FEMALE TAX ADVISERS SIXTH EDITION IN ASSOCIATION WITH PUBLISHED BY WWW.INTERNATIONALTAXREVIEW.COM Contents 2 Introduction and methodology 8 Bouverie Street, London EC4Y 8AX, UK AMERICAS Tel: +44 20 7779 8308 4 Latin America: 30 Costa Rica Fax: +44 20 7779 8500 regional interview 30 Curaçao 8 United States: 30 Guatemala Editor, World Tax and World TP regional interview 30 Honduras Jonathan Moore 19 Argentina 31 Mexico Researchers 20 Brazil 31 Panama Lovy Mazodila 24 Canada 31 Peru Annabelle Thorpe 29 Chile 32 United States Jason Howard 30 Colombia 41 Venezuela Production editor ASIA-PACIFIC João Fernandes 43 Asia-Pacific: regional 58 Malaysia interview 59 New Zealand Business development team 52 Australia 60 Philippines Margaret Varela-Christie 53 Cambodia 61 Singapore Raquel Ipo 54 China 61 South Korea Managing director, LMG Research 55 Hong Kong SAR 62 Taiwan Tom St. Denis 56 India 62 Thailand 58 Indonesia 62 Vietnam © Euromoney Trading Limited, 2020. The copyright of all 58 Japan editorial matter appearing in this Review is reserved by the publisher. EUROPE, MIDDLE EAST & AFRICA 64 Africa: regional 101 Lithuania No matter contained herein may be reproduced, duplicated interview 101 Luxembourg or copied by any means without the prior consent of the 68 Central Europe: 102 Malta: Q&A holder of the copyright, requests for which should be regional interview 105 Malta addressed to the publisher. Although Euromoney Trading 72 Northern & 107 Netherlands Limited has made every effort to ensure the accuracy of this Southern Europe: 110 Norway publication, neither it nor any contributor can accept any regional interview 111 Poland legal responsibility whatsoever for consequences that may 86 Austria 112 Portugal arise from errors or omissions, or any opinions or advice 87 Belgium 115 Qatar given. -

Amazon's Antitrust Paradox
LINA M. KHAN Amazon’s Antitrust Paradox abstract. Amazon is the titan of twenty-first century commerce. In addition to being a re- tailer, it is now a marketing platform, a delivery and logistics network, a payment service, a credit lender, an auction house, a major book publisher, a producer of television and films, a fashion designer, a hardware manufacturer, and a leading host of cloud server space. Although Amazon has clocked staggering growth, it generates meager profits, choosing to price below-cost and ex- pand widely instead. Through this strategy, the company has positioned itself at the center of e- commerce and now serves as essential infrastructure for a host of other businesses that depend upon it. Elements of the firm’s structure and conduct pose anticompetitive concerns—yet it has escaped antitrust scrutiny. This Note argues that the current framework in antitrust—specifically its pegging competi- tion to “consumer welfare,” defined as short-term price effects—is unequipped to capture the ar- chitecture of market power in the modern economy. We cannot cognize the potential harms to competition posed by Amazon’s dominance if we measure competition primarily through price and output. Specifically, current doctrine underappreciates the risk of predatory pricing and how integration across distinct business lines may prove anticompetitive. These concerns are height- ened in the context of online platforms for two reasons. First, the economics of platform markets create incentives for a company to pursue growth over profits, a strategy that investors have re- warded. Under these conditions, predatory pricing becomes highly rational—even as existing doctrine treats it as irrational and therefore implausible. -

Amicus Brief
No. 19-1392 In the Supreme Court of the United States THOMAS E. DOBBS, STATE HEALTH OFFICER OF THE MISSISSIPPI DEPARTMENT OF HEALTH, ET AL., PETITIONERS v. JACKSON WOMEN’S HEALTH ORGANIZATION, ET AL. ON WRIT OF CERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE FIFTH CIRCUIT BRIEF FOR THE STATES OF TEXAS, ALABAMA, ALASKA, ARIZONA, ARKANSAS, FLORIDA, GEORGIA, IDAHO, INDIANA, KANSAS, KENTUCKY, LOUISIANA, MISSOURI, MONTANA, NEBRASKA, NORTH DAKOTA, OHIO, OKLAHOMA, SOUTH CAROLINA, SOUTH DAKOTA, TENNESSEE, UTAH, WEST VIRGINIA, AND WYOMING AS AMICI CURIAE IN SUPPORT OF PETITIONERS KEN PAXTON JUDD E. STONE II Attorney General of Texas Solicitor General Counsel of Record BRENT WEBSTER First Assistant Attorney KYLE D. HIGHFUL General BETH KLUSMANN Assistant Solicitors General OFFICE OF THE ATTORNEY GENERAL P.O. Box 12548 (MC 059) Austin, Texas 78711-2548 [email protected] (512) 936-1700 TABLE OF CONTENTS Page Table of authorities ....................................................... II Interest of amici curiae ................................................. 1 Introduction and summary of argument ...................... 2 Argument ........................................................................ 3 I. The Court’s erroneous and constantly changing abortion precedent does not warrant stare decisis deference. ............................................... 3 A. Roe and Casey created and preserved a nonexistent constitutional right. ................. 4 1. The Constitution does not include a right to elective abortion. ....................... 5 2. There is no right to elective abortion in the Nation’s history and tradition. ........ 7 B. The Court continues to change the constitutional test. .......................................10 1. Roe created the trimester test. .............10 2. Casey rejected the trimester test in favor of the undue-burden test. ............11 3. Whole Woman’s Health may have introduced a benefits/burdens balancing test. -

French Names Noeline Bridge
names collated:Chinese personal names and 100 surnames.qxd 29/09/2006 13:00 Page 8 The hundred surnames Pinyin Hanzi (simplified) Wade Giles Other forms Well-known names Pinyin Hanzi (simplified) Wade Giles Other forms Well-known names Zang Tsang Zang Lin Zhu Chu Gee Zhu Yuanzhang, Zhu Xi Zeng Tseng Tsang, Zeng Cai, Zeng Gong Zhu Chu Zhu Danian Dong, Zhu Chu Zhu Zhishan, Zhu Weihao Jeng Zhu Chu Zhu jin, Zhu Sheng Zha Cha Zha Yihuang, Zhuang Chuang Zhuang Zhou, Zhuang Zi Zha Shenxing Zhuansun Chuansun Zhuansun Shi Zhai Chai Zhai Jin, Zhai Shan Zhuge Chuko Zhuge Liang, Zhan Chan Zhan Ruoshui Zhuge Kongming Zhan Chan Chaim Zhan Xiyuan Zhuo Cho Zhuo Mao Zhang Chang Zhang Yuxi Zi Tzu Zi Rudao Zhang Chang Cheung, Zhang Heng, Ziche Tzuch’e Ziche Zhongxing Chiang Zhang Chunqiao Zong Tsung Tsung, Zong Xihua, Zhang Chang Zhang Shengyi, Dung Zong Yuanding Zhang Xuecheng Zongzheng Tsungcheng Zongzheng Zhensun Zhangsun Changsun Zhangsun Wuji Zou Tsou Zou Yang, Zou Liang, Zhao Chao Chew, Zhao Kuangyin, Zou Yan Chieu, Zhao Mingcheng Zu Tsu Zu Chongzhi Chiu Zuo Tso Zuo Si Zhen Chen Zhen Hui, Zhen Yong Zuoqiu Tsoch’iu Zuoqiu Ming Zheng Cheng Cheng, Zheng Qiao, Zheng He, Chung Zheng Banqiao The hundred surnames is one of the most popular reference Zhi Chih Zhi Dake, Zhi Shucai sources for the Han surnames. It was originally compiled by an Zhong Chung Zhong Heqing unknown author in the 10th century and later recompiled many Zhong Chung Zhong Shensi times. The current widely used version includes 503 surnames. Zhong Chung Zhong Sicheng, Zhong Xing The Pinyin index of the 503 Chinese surnames provides an access Zhongli Chungli Zhongli Zi to this great work for Western people. -

CMF Fraternity English 2020.Indd
Claretian Fraternity News Bulletin for Families and Associates, Province of Bangalore, Vol. 10, 2020 May the Joy and Peace of Christmas be with you all through the New Year. Wishing you a season of blessings from God. Merry Christmasand Prosp erous New Year2021 MESSAGE FROM THE DELEGATE SUPERIOR n 24th October 2020 we celebrated the 150th death The year 2020 is also remarkable O anniversary of our Founder St. Antony Mary Claret. for the Indian Claretians in a very Eighty years after his death Pope Pius XII proclaimed him a special way as our Congregation saint in 1950, formally recognizing that he heroically practiced is completing fi fty years of its the Christian virtues and presenting him to the universal existence and ministry in our Church as an example to follow. Fr. Claret founded religious Country. It was in 1970 that the Congregations of men and women, whose members are fi rst Claretian community was now at the service of the Word of God in over sixty countries. established in a small village in These missionaries give testimony to the Gospel values in Kerala called Kuravilangad, and the past fi fty years have brought different ways, namely through direct preaching of the Word to us immeasurable divine blessings. The small community of God, social and charitable activities in favour of the poor, started with three priests, fi ve novices and a small batch of educational ministry, pastoral service in the local Churches minor seminarians have grown today to a community of over etc. The life of St. Claret has motivated so many young men 550 priests and a good number of seminarians at different that the Claretian Congregation has given to the Church nearly stages of their formation, grouped under fi ve Major Organisms, three hundred martyrs, consisting of priests, lay brothers and namely three full-fl edged Provinces and two independent seminarians, during the Spanish civil war. -

Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation
Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation A/L Krishnan Thiinash Bachelor of Information Technology March 2015 A/L Selvaraju Theeban Raju Bachelor of Commerce January 2015 A/P Balan Durgarani Bachelor of Commerce with Distinction March 2015 A/P Rajaram Koushalya Priya Bachelor of Commerce March 2015 Hiba Mohsin Mohammed Master of Health Leadership and Aal-Yaseen Hussein Management July 2015 Aamer Muhammad Master of Quality Management September 2015 Abbas Hanaa Safy Seyam Master of Business Administration with Distinction March 2015 Abbasi Muhammad Hamza Master of International Business March 2015 Abdallah AlMustafa Hussein Saad Elsayed Bachelor of Commerce March 2015 Abdallah Asma Samir Lutfi Master of Strategic Marketing September 2015 Abdallah Moh'd Jawdat Abdel Rahman Master of International Business July 2015 AbdelAaty Mosa Amany Abdelkader Saad Master of Media and Communications with Distinction March 2015 Abdel-Karim Mervat Graduate Diploma in TESOL July 2015 Abdelmalik Mark Maher Abdelmesseh Bachelor of Commerce March 2015 Master of Strategic Human Resource Abdelrahman Abdo Mohammed Talat Abdelziz Management September 2015 Graduate Certificate in Health and Abdel-Sayed Mario Physical Education July 2015 Sherif Ahmed Fathy AbdRabou Abdelmohsen Master of Strategic Marketing September 2015 Abdul Hakeem Siti Fatimah Binte Bachelor of Science January 2015 Abdul Haq Shaddad Yousef Ibrahim Master of Strategic Marketing March 2015 Abdul Rahman Al Jabier Bachelor of Engineering Honours Class II, Division 1 -
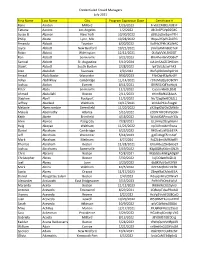
Credentialed Crowd Managers July 2021 First Name Last
Credentialed Crowd Managers July 2021 First Name Last Name City Program Expiration Date Certificate # Rano Aarden Milford 1/26/2023 FrvbECM3ELNUErF Tatiana Aarons Los Angeles 1/2/2022 J8r2x6PSVpDZGKC Susan B. Abanor New York 10/30/2022 s8lELzyDw2qmPTH Philip Abate Lynn, MA 10/28/2022 WqaslYQvPLZk07G Amanda Abbott Taunton 6/20/2022 Ka9Hs2Pkh1KUNAC Joyce Abbott New Bedford 10/21/2021 zVHllaFMm8dCTeK Robin Abbott Wilmington 12/12/2021 0fz5pVVXLSI60OT Ron Abbott Somerville 9/22/2023 8hk4henBxVDbBv7 Samuel Abbott St. Augustine 5/10/2024 xiA1mSAdZE0HG4m Stuart Abbott South Boston 2/28/2022 lpY1blLJbzwFhK3 Alan Abdallah Swansea 2/9/2022 WxFq0DJ9mPqGHof Amaal Abdelkader Worcester 9/30/2023 FYtrOqHF3pfkzOY Adiya Abdilkhay Cambridge 11/14/2021 r97oMqQly3OBcNY Joshua Abdon Everett 8/11/2021 8VW51lQEYwhliyk Peter Abdu Somerville 11/2/2022 Cuaserkl6OLDbIZ Ahmed Abdullahi Boston 2/11/2023 tHImRAfKLS8JsxA Stephen Abell Rockport 11/5/2023 NoT2agXeKIOBZL1 Jeffrey Abellard Waltham 10/17/2021 eCG3eP61sFxog9l Melanie Abercrombie Greenfield 11/20/2022 aY2bpJ0WOsCMN0v Makyla Abernathy Atlanta 5/15/2022 cODN7RFDYaYpDcH Keith Abete Brimfield 4/18/2022 Wxh4f0APmovh33s Alvin Abinas Pasig City 7/28/2021 ULzHHuZOsydr6mI Haig Aboyan Waltham 11/26/2022 np3UfnoLfzH5wca Daniel Abraham Cambridge 6/25/2022 9HDvxEuWGiLiE7A Jeff Abraham Worcester 5/14/2023 gj0TzUxgE5rmA9F Mark Abraham Methuen 4/7/2024 FxZZL4mXMf6JwRY Thomas Abraham Reston 11/28/2021 EVLm0eLZSHSmsq9 Joshua Abrahams Somerville 5/19/2022 Kdp8QRqKtAmGN2h Chris Abrams Boston 10/8/2021 MSbGbeMkEgADg9P Christopher -

Patrick Huges Reverspective Room Photo Project Name:______
Patrick Huges Reverspective Room Photo Project Name:______________ Perspective - The art of drawing solid objects on a two-dimensional surface so as to give the right impression of their height, width, depth. 2. A work created in such a way, esp. one appearing to enlarge or extend the actual space, or to give the effect of distance. Reverspective - are painted on a continuous surface that is made up of one or more truncated pyramids that protrude from a flat plane. When viewed from a sufficiently large distance, either monocularly or binocularly, the parts of the painting that actually protrude appear to recede into the background of the scene portrayed. Patrick Hughes is a British artist working in London. He is the creator of Reverspective , Patrick Hughes – an optical illusion on a 3-dimensional surface where the parts of the picture which seem Reverspective farthest away are actually physically the nearest. Creator Patrick Hughes: Vanishing Venice Patrick Hughes: Reverspective Sculpture Picture Reverspective Sculpture Frame Patrick Hughes, Colour Sings, 2007. STEP ONE: RESEARCH Patrick Hughes and his Reverspective Sculptures on the school network: K://Mr. Arnett/AWQ 3M/06 - Patrick Huges Reverspective Room Photo Project/intro.htm and complete the questions on the attached sheet – “Researching Reverspective Sculpture in Art” by choosing one artwork to answer the questions on. STEP TWO: DRAW a series of at least 3 different possible conceptual sketches incorporating reverspective photo as based on Patrick Huges Sticking Out Room. Consider these specific elements and principles: Line, Shape, Space. REMEMBER: Have your sketches approved by the teacher before start creating your reverspective photo project.