Relativity Processing User Guide V10.3
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Translators' Tool
The Translator’s Tool Box A Computer Primer for Translators by Jost Zetzsche Version 9, December 2010 Copyright © 2010 International Writers’ Group, LLC. All rights reserved. This document, or any part thereof, may not be reproduced or transmitted electronically or by any other means without the prior written permission of International Writers’ Group, LLC. ABBYY FineReader and PDF Transformer are copyrighted by ABBYY Software House. Acrobat, Acrobat Reader, Dreamweaver, FrameMaker, HomeSite, InDesign, Illustrator, PageMaker, Photoshop, and RoboHelp are registered trademarks of Adobe Systems Inc. Acrocheck is copyrighted by acrolinx GmbH. Acronis True Image is a trademark of Acronis, Inc. Across is a trademark of Nero AG. AllChars is copyrighted by Jeroen Laarhoven. ApSIC Xbench and Comparator are copyrighted by ApSIC S.L. Araxis Merge is copyrighted by Araxis Ltd. ASAP Utilities is copyrighted by eGate Internet Solutions. Authoring Memory Tool is copyrighted by Sajan. Belarc Advisor is a trademark of Belarc, Inc. Catalyst and Publisher are trademarks of Alchemy Software Development Ltd. ClipMate is a trademark of Thornsoft Development. ColourProof, ColourTagger, and QA Solution are copyrighted by Yamagata Europe. Complete Word Count is copyrighted by Shauna Kelly. CopyFlow is a trademark of North Atlantic Publishing Systems, Inc. CrossCheck is copyrighted by Global Databases, Ltd. Déjà Vu is a trademark of ATRIL Language Engineering, S.L. Docucom PDF Driver is copyrighted by Zeon Corporation. dtSearch is a trademark of dtSearch Corp. EasyCleaner is a trademark of ToniArts. ExamDiff Pro is a trademark of Prestosoft. EmEditor is copyrighted by Emura Software inc. Error Spy is copyrighted by D.O.G. GmbH. FileHippo is copyrighted by FileHippo.com. -

ACS – the Archival Cytometry Standard
http://flowcyt.sf.net/acs/latest.pdf ACS – the Archival Cytometry Standard Archival Cytometry Standard ACS International Society for Advancement of Cytometry Candidate Recommendation DRAFT Document Status The Archival Cytometry Standard (ACS) has undergone several revisions since its initial development in June 2007. The current proposal is an ISAC Candidate Recommendation Draft. It is assumed, however not guaranteed, that significant features and design aspects will remain unchanged for the final version of the Recommendation. This specification has been formally tested to comply with the W3C XML schema version 1.0 specification but no position is taken with respect to whether a particular software implementing this specification performs according to medical or other valid regulations. The work may be used under the terms of the Creative Commons Attribution-ShareAlike 3.0 Unported license. You are free to share (copy, distribute and transmit), and adapt the work under the conditions specified at http://creativecommons.org/licenses/by-sa/3.0/legalcode. Disclaimer of Liability The International Society for Advancement of Cytometry (ISAC) disclaims liability for any injury, harm, or other damage of any nature whatsoever, to persons or property, whether direct, indirect, consequential or compensatory, directly or indirectly resulting from publication, use of, or reliance on this Specification, and users of this Specification, as a condition of use, forever release ISAC from such liability and waive all claims against ISAC that may in any manner arise out of such liability. ISAC further disclaims all warranties, whether express, implied or statutory, and makes no assurances as to the accuracy or completeness of any information published in the Specification. -

Metadefender Core V4.12.2
MetaDefender Core v4.12.2 © 2018 OPSWAT, Inc. All rights reserved. OPSWAT®, MetadefenderTM and the OPSWAT logo are trademarks of OPSWAT, Inc. All other trademarks, trade names, service marks, service names, and images mentioned and/or used herein belong to their respective owners. Table of Contents About This Guide 13 Key Features of Metadefender Core 14 1. Quick Start with Metadefender Core 15 1.1. Installation 15 Operating system invariant initial steps 15 Basic setup 16 1.1.1. Configuration wizard 16 1.2. License Activation 21 1.3. Scan Files with Metadefender Core 21 2. Installing or Upgrading Metadefender Core 22 2.1. Recommended System Requirements 22 System Requirements For Server 22 Browser Requirements for the Metadefender Core Management Console 24 2.2. Installing Metadefender 25 Installation 25 Installation notes 25 2.2.1. Installing Metadefender Core using command line 26 2.2.2. Installing Metadefender Core using the Install Wizard 27 2.3. Upgrading MetaDefender Core 27 Upgrading from MetaDefender Core 3.x 27 Upgrading from MetaDefender Core 4.x 28 2.4. Metadefender Core Licensing 28 2.4.1. Activating Metadefender Licenses 28 2.4.2. Checking Your Metadefender Core License 35 2.5. Performance and Load Estimation 36 What to know before reading the results: Some factors that affect performance 36 How test results are calculated 37 Test Reports 37 Performance Report - Multi-Scanning On Linux 37 Performance Report - Multi-Scanning On Windows 41 2.6. Special installation options 46 Use RAMDISK for the tempdirectory 46 3. Configuring Metadefender Core 50 3.1. Management Console 50 3.2. -

Comunicado 23 Técnico
Comunicado 23 ISSN 1415-2118 Abril, 2007 Técnico Campinas, SP Armazenagem e transporte de arquivos extensos André Luiz dos Santos Furtado Fernando Antônio de Pádua Paim Resumo O crescimento no volume de informações transportadas por um mesmo indivíduo ou por uma equipe é uma tendência mundial e a cada dia somos confrontados com mídias de maior capacidade de armazenamento de dados. O objetivo desse comunicado é explorar algumas possibilidades destinadas a permitir a divisão e o transporte de arquivos de grande volume. Neste comunicado, tutoriais para o Winrar, 7-zip, ALZip, programas destinados a compactação de arquivos, são apresentados. É descrita a utilização do Hjsplit, software livre, que permite a divisão de arquivos. Adicionalmente, são apresentados dois sites, o rapidshare e o mediafire, destinados ao compartilhamento e à hospedagem de arquivos. 1. Introdução O crescimento no volume de informações transportadas por um mesmo indivíduo ou por uma equipe é uma tendência mundial. No início da década de 90, mesmo nos países desenvolvidos, um computador com capacidade de armazenamento de 12 GB era inovador. As fitas magnéticas foram substituídas a partir do anos 50, quando a IBM lançou o primogenitor dos atuais discos rígidos, o RAMAC Computer, com a capacidade de 5 MB, pesando aproximadamente uma tonelada (ESTADO DE SÃO PAULO, 2006; PCWORLD, 2006) (Figs. 1 e 2). Figura 1 - Transporte do disco rígido do RAMAC Computer criado pela IBM em 1956, com a capacidade de 5 MB. 2 Figura 2 - Sala de operação do RAMAC Computer. Após três décadas, os primeiros computadores pessoais possuíam discos rígidos com capacidade significativamente superior ao RAMAC, algo em torno de 10 MB, consumiam menos energia, custavam menos e, obviamente, tinham uma massa que não alcançava 100 quilogramas. -

Electronic Data Deliverables Reference Guide EPA Region 4
Electronic Data Deliverables Reference Guide Version 1.0 EPA Region 4 Prepared By: for Region 4 Superfund Division Environmental Protection Agency March 2010 DISCLAIMER OF ENDORSEMENT Reference herein to any specific commercial products, process, or service by trade name, trademark, manufacturer, or otherwise, does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government, and shall not be used for advertising or product endorsement purposes. STATUS OF DOCUMENT As of March 2010, this document and all contents contained herein are considered DRAFT and are subject to revision and subsequent republication. Ecological EDD specifications do not appear in this guidance as they are currently under development, and will appear in future addenda. CONTACTS For questions and comments, contact: Your RPM or, DART Coordinator Superfund Division, 11th Floor East United States Environmental Protection Agency, Region 4 Sam Nunn Atlanta Federal Center 61 Forsyth Street, SW Atlanta, GA 30303-8960 (404) 562-8558 [email protected] Acronyms CAS RN – Chemical Abstracts Service Registry Number DART – Data Archival and ReTrieval EDD – Electronic Data Deliverable EDP – EQuIS Data Processor EPA – Environmental Protection Agency O&M – Operation and Maintenance SESD – Science and Ecosystem Support Division SRS – Substance Registry System CLP – Contract Laboratory Program PRP – Potentially Responsible Party Definitions Darter - Darter is a set of software utilities written by EPA that assist in moving data from other platforms such as FORMS, Niton, YSI and Scribe to the Region 4 EDD format. Data Provider – It is important to distinguish between “Data Provider” and “Sample Provider” with regard to EDD submittals. -

Symantec Web Security Service Policy Guide
Web Security Service Policy Guide Revision: NOV.07.2020 Symantec Web Security Service/Page 2 Policy Guide/Page 3 Copyrights Broadcom, the pulse logo, Connecting everything, and Symantec are among the trademarks of Broadcom. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. Copyright © 2020 Broadcom. All Rights Reserved. The term “Broadcom” refers to Broadcom Inc. and/or its subsidiaries. For more information, please visit www.broadcom.com. Broadcom reserves the right to make changes without further notice to any products or data herein to improve reliability, function, or design. Information furnished by Broadcom is believed to be accurate and reliable. However, Broadcom does not assume any liability arising out of the application or use of this information, nor the application or use of any product or circuit described herein, neither does it convey any license under its patent rights nor the rights of others. Policy Guide/Page 4 Symantec WSS Policy Guide The Symantec Web Security Service solutions provide real-time protection against web-borne threats. As a cloud-based product, the Web Security Service leverages Symantec's proven security technology, including the WebPulse™ cloud community. With extensive web application controls and detailed reporting features, IT administrators can use the Web Security Service to create and enforce granular policies that are applied to all covered users, including fixed locations and roaming users. If the WSS is the body, then the policy engine is the brain. While the WSS by default provides malware protection (blocks four categories: Phishing, Proxy Avoidance, Spyware Effects/Privacy Concerns, and Spyware/Malware Sources), the additional policy rules and options you create dictate exactly what content your employees can and cannot access—from global allows/denials to individual users at specific times from specific locations. -
![Archive and Compressed [Edit]](https://docslib.b-cdn.net/cover/8796/archive-and-compressed-edit-1288796.webp)
Archive and Compressed [Edit]
Archive and compressed [edit] Main article: List of archive formats • .?Q? – files compressed by the SQ program • 7z – 7-Zip compressed file • AAC – Advanced Audio Coding • ace – ACE compressed file • ALZ – ALZip compressed file • APK – Applications installable on Android • AT3 – Sony's UMD Data compression • .bke – BackupEarth.com Data compression • ARC • ARJ – ARJ compressed file • BA – Scifer Archive (.ba), Scifer External Archive Type • big – Special file compression format used by Electronic Arts for compressing the data for many of EA's games • BIK (.bik) – Bink Video file. A video compression system developed by RAD Game Tools • BKF (.bkf) – Microsoft backup created by NTBACKUP.EXE • bzip2 – (.bz2) • bld - Skyscraper Simulator Building • c4 – JEDMICS image files, a DOD system • cab – Microsoft Cabinet • cals – JEDMICS image files, a DOD system • cpt/sea – Compact Pro (Macintosh) • DAA – Closed-format, Windows-only compressed disk image • deb – Debian Linux install package • DMG – an Apple compressed/encrypted format • DDZ – a file which can only be used by the "daydreamer engine" created by "fever-dreamer", a program similar to RAGS, it's mainly used to make somewhat short games. • DPE – Package of AVE documents made with Aquafadas digital publishing tools. • EEA – An encrypted CAB, ostensibly for protecting email attachments • .egg – Alzip Egg Edition compressed file • EGT (.egt) – EGT Universal Document also used to create compressed cabinet files replaces .ecab • ECAB (.ECAB, .ezip) – EGT Compressed Folder used in advanced systems to compress entire system folders, replaced by EGT Universal Document • ESS (.ess) – EGT SmartSense File, detects files compressed using the EGT compression system. • GHO (.gho, .ghs) – Norton Ghost • gzip (.gz) – Compressed file • IPG (.ipg) – Format in which Apple Inc. -

Anycount 7.0 User Guide
HelpAndManual_unregistered_evaluation_copy Advanced International Translations AnyCount 7.0 User Guide © 2008 Advanced International Translations, Revision V7R1 I AnyCount 7.0 User Guide Table of Contents Foreword 0 Part I Introduction 1 1 AnyCount 7.0 ................................................................................................................................... 1 2 Using this Guide................................................................................................................................... 1 3 Reference Material................................................................................................................................... 1 Part II Setup 3 1 System Requirements................................................................................................................................... 3 2 Installation ................................................................................................................................... 3 Part III Working with AnyCount 4 1 Overview ................................................................................................................................... 4 2 Selecting Files................................................................................................................................... to Count 4 3 Count Settings................................................................................................................................... 7 4 Count Units .................................................................................................................................. -
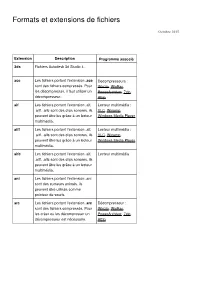
Formats Et Extensions De Fichiers
Formats et extensions de fichiers Octobre 2015 Extension Description Programme associé 3ds Fichiers Autodesk 3d Studio 4. ace Les fichiers portant l'extension .ace Décompresseurs : sont des fichiers compressés. Pour Winzip, WinRar, les décompresser, il faut utiliser un PowerArchiver, 7zip, décompresseur. Alzip aif Les fichiers portant l'extension .aif, Lecteur multimédia : .aiff, .aifc sont des clips sonores, ils VLC, Winamp, peuvent être lus grâce à un lecteur Windows Media Player multimédia. aiff Les fichiers portant l'extension .aif, Lecteur multimédia : .aiff, .aifc sont des clips sonores, ils VLC, Winamp, peuvent être lus grâce à un lecteur Windows Media Player multimédia. aifc Les fichiers portant l'extension .aif, Lecteur multimédia .aiff, .aifc sont des clips sonores, ils peuvent être lus grâce à un lecteur multimédia. ani Les fichiers portant l'extension .ani sont des curseurs animés, ils peuvent être utilisés comme pointeur de souris. arc Les fichiers portant l'extension .arc Décompresseur : sont des fichiers compressés. Pour Winzip, WinRar, les créer ou les décompresser un PowerArchiver, 7zip, décompresseur est nécessaire. Alzip arj quickzip, WinArj, 7zip Les fichiers portant l'extension .arj sont des fichiers compressés, ils nécessitent un décompresseur tel que arj.exe. La syntaxe pour décompresser un fichier de ce type en ligne de commande est: arj x nom_du_fichier_a_decompresser.arj cible -va -r L'attribut -va spécifie que les archives en plusieurs volumes seront traitées automatiquement L'attribut -r spécifie que l'arborescence sera reconstituée La syntaxe pour compresser un fichier avec ARJ est: arj a nom_de_l_archive.arj nom_du_fichier_a_compresser -va - r asp Microsoft Active Server Pages. Il Navigateur Web pour s'agit de pages web dynamiques le client, Serveur Web générées au niveau du serveur web. -

Ten Thousand Security Pitfalls: the ZIP File Format
Ten thousand security pitfalls: The ZIP file format. Gynvael Coldwind @ Technische Hochschule Ingolstadt, 2018 About your presenter (among other things) All opinions expressed during this presentation are mine and mine alone, and not those of my barber, my accountant or my employer. What's on the menu Also featuring: Steganograph 1. What's ZIP used for again? 2. What can be stored in a ZIP? y a. Also, file names 3. ZIP format 101 and format repair 4. Legacy ZIP encryption 5. ZIP format and multiple personalities 6. ZIP encryption and CRC32 7. Miscellaneous, i.e. all the things not mentioned so far. Or actually, hacking a "secure cloud disk" website. EDITORIAL NOTE Everything in this color is a quote from the official ZIP specification by PKWARE Inc. The specification is commonly known as APPNOTE.TXT https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT Cyber Secure CloudDisk Where is ZIP used? .zip files, obviously Default ZIP file icon from Microsoft Windows 10's Explorer And also... Open Packaging Conventions: .3mf, .dwfx, .cddx, .familyx, .fdix, .appv, .semblio, .vsix, .vsdx, .appx, .appxbundle, .cspkg, .xps, .nupkg, .oxps, .jtx, .slx, .smpk, .odt, .odp, .ods, ... .scdoc, (OpenDocument) and Offixe Open XML formats: .docx, .pptx, .xlsx https://en.wikipedia.org/wiki/Open_Packaging_Conventions And also... .war (Web application archive) .rar (not THAT .rar) .jar (resource adapter archive) (Java Archive) .ear (enterprise archive) .sar (service archive) .par (Plan Archive) .kar (Karaf ARchive) https://en.wikipedia.org/wiki/JAR_(file_format) -

Unzip Rar Files Free Software
Unzip rar files free software Packing / unpacking: 7z, XZ, BZIP2, GZIP, TAR, ZIP and WIM; Unpacking only: AR, ARJ, CAB, CHM, CPIO, We compared 7-Zip with WinRAR Archiver, Mozilla Firefox, Google Earth. 65 files 85 bytes, files And 7-Zip compresses to zip format % better than most of other zip compatible programs.Download · 7z Format · FAQ · Support. WinRAR, free and safe download. WinRAR latest version: The king of compressed files. WinRAR is a program that can be used to open, create and decompress. RAR files can be split into multi-volume archives when dealing with large file sets. Click 1-click Unzip and choose Unzip to PC or Cloud in the WinZip toolbar. Free RAR Extract Frog extracts RAR archive files. RAR files aren't uncommon, but some ZIP tools don't handle the format; even if they do, it's often quicker and. Unzip RAR is a free file decompressing (unzip) tool for RAR archives, it can quickly open and extract files and folders in RAR archives, simple and easy to use. Software provides preview function, it will read RAR archives and show all. free Rar files software. Open, extract 7Z ACE CAB RAR TAR ZIP archives, support + formats. Extract Rar files, free Zip Unzip software. PeaZip Portable. Free portable Zip software, extract Rar files. This is the best solution to bring a complete zip & unzip / unrar utility with you (i.e. on an USB drive), make it. To Open RAR files, you need to install WinRar which is not a free application. Files\RAR File Open Knife - Free Opener\); Use notepad to create a text file. -

Security Space
Security Space User Manual © Doctor Web, 2017. All rights reserved This document is the property of Doctor Web. No part of this document may be reproduced, published or transmitted in any form or by any means for any purpose other than the purchaser's personal use without proper attribution. Trademarks Dr.Web, SpIDer Mail, SpIDer Guard, CureIt!, CureNet!, AV-Desk, KATANA and the Dr.WEB logo are trademarks and registered trademarks of Doctor Web in Russia and/or other countries. Other trademarks, registered trademarks and company names used in this document are property of their respective owners. Disclaimer In no event shall Doctor Web and its resellers or distributors be liable for errors or omissions, or any loss of profit or any other damage caused or alleged to be caused directly or indirectly by this document, the use of or inability to use information contained in this document. Dr.Web Security Space Version 11.0 User Manual 9/6/2017 Doctor Web Head Office 2-12A, 3rd str. Yamskogo polya Moscow, Russia 125040 Website: http://www.drweb.com/ Phone: +7 (495) 789-45-87 Refer to the official website for regional and international office information. Doctor Web Doctor Web develops and distributes Dr.Web information security solutions which provide efficient protection from malicious software and spam. Doctor Web customers can be found among home users from all over the world and in government enterprises, small companies and nationwide corporations. Dr.Web antivirus solutions are well known since 1992 for continuing excellence in malware detection and compliance with international information security standards.