Supplementary Table 1 Genes in the Yellow Module
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

University of California, San Diego
UNIVERSITY OF CALIFORNIA, SAN DIEGO The post-terminal differentiation fate of RNAs revealed by next-generation sequencing A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Biomedical Sciences by Gloria Kuo Lefkowitz Committee in Charge: Professor Benjamin D. Yu, Chair Professor Richard Gallo Professor Bruce A. Hamilton Professor Miles F. Wilkinson Professor Eugene Yeo 2012 Copyright Gloria Kuo Lefkowitz, 2012 All rights reserved. The Dissertation of Gloria Kuo Lefkowitz is approved, and it is acceptable in quality and form for publication on microfilm and electronically: __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ __________________________________________________________________ Chair University of California, San Diego 2012 iii DEDICATION Ma and Ba, for your early indulgence and support. Matt and James, for choosing more practical callings. Roy, my love, for patiently sharing the ups and downs of this journey. iv EPIGRAPH It is foolish to tear one's hair in grief, as though sorrow would be made less by baldness. ~Cicero v TABLE OF CONTENTS Signature Page .............................................................................................................. iii Dedication .................................................................................................................... -
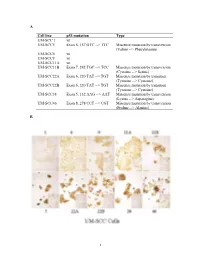
A Cell Line P53 Mutation Type UM
A Cell line p53 mutation Type UM-SCC 1 wt UM-SCC5 Exon 5, 157 GTC --> TTC Missense mutation by transversion (Valine --> Phenylalanine UM-SCC6 wt UM-SCC9 wt UM-SCC11A wt UM-SCC11B Exon 7, 242 TGC --> TCC Missense mutation by transversion (Cysteine --> Serine) UM-SCC22A Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC22B Exon 6, 220 TAT --> TGT Missense mutation by transition (Tyrosine --> Cysteine) UM-SCC38 Exon 5, 132 AAG --> AAT Missense mutation by transversion (Lysine --> Asparagine) UM-SCC46 Exon 8, 278 CCT --> CGT Missense mutation by transversion (Proline --> Alanine) B 1 Supplementary Methods Cell Lines and Cell Culture A panel of ten established HNSCC cell lines from the University of Michigan series (UM-SCC) was obtained from Dr. T. E. Carey at the University of Michigan, Ann Arbor, MI. The UM-SCC cell lines were derived from eight patients with SCC of the upper aerodigestive tract (supplemental Table 1). Patient age at tumor diagnosis ranged from 37 to 72 years. The cell lines selected were obtained from patients with stage I-IV tumors, distributed among oral, pharyngeal and laryngeal sites. All the patients had aggressive disease, with early recurrence and death within two years of therapy. Cell lines established from single isolates of a patient specimen are designated by a numeric designation, and where isolates from two time points or anatomical sites were obtained, the designation includes an alphabetical suffix (i.e., "A" or "B"). The cell lines were maintained in Eagle's minimal essential media supplemented with 10% fetal bovine serum and penicillin/streptomycin. -

Seq2pathway Vignette
seq2pathway Vignette Bin Wang, Xinan Holly Yang, Arjun Kinstlick May 19, 2021 Contents 1 Abstract 1 2 Package Installation 2 3 runseq2pathway 2 4 Two main functions 3 4.1 seq2gene . .3 4.1.1 seq2gene flowchart . .3 4.1.2 runseq2gene inputs/parameters . .5 4.1.3 runseq2gene outputs . .8 4.2 gene2pathway . 10 4.2.1 gene2pathway flowchart . 11 4.2.2 gene2pathway test inputs/parameters . 11 4.2.3 gene2pathway test outputs . 12 5 Examples 13 5.1 ChIP-seq data analysis . 13 5.1.1 Map ChIP-seq enriched peaks to genes using runseq2gene .................... 13 5.1.2 Discover enriched GO terms using gene2pathway_test with gene scores . 15 5.1.3 Discover enriched GO terms using Fisher's Exact test without gene scores . 17 5.1.4 Add description for genes . 20 5.2 RNA-seq data analysis . 20 6 R environment session 23 1 Abstract Seq2pathway is a novel computational tool to analyze functional gene-sets (including signaling pathways) using variable next-generation sequencing data[1]. Integral to this tool are the \seq2gene" and \gene2pathway" components in series that infer a quantitative pathway-level profile for each sample. The seq2gene function assigns phenotype-associated significance of genomic regions to gene-level scores, where the significance could be p-values of SNPs or point mutations, protein-binding affinity, or transcriptional expression level. The seq2gene function has the feasibility to assign non-exon regions to a range of neighboring genes besides the nearest one, thus facilitating the study of functional non-coding elements[2]. Then the gene2pathway summarizes gene-level measurements to pathway-level scores, comparing the quantity of significance for gene members within a pathway with those outside a pathway. -

University of Leicester, Msc Medical Statistics, Thesis, Wilmar
Thesis MSc in Medical Statistics Department of Health Sciences University of Leicester, United Kingdom Application of Bayesian hierarchical generalized linear models using weakly informative prior distributions to identify rare genetic variant effects on blood pressure Wilmar Igl March 2015 Summary Background Currently rare genetic variants are discussed as a source of \missing heritability" of complex traits. Bayesian hierarchical models were proposed as an efficient method for the estimation and aggregation of conditional effects of rare variants. Here, such models are applied to identify rare variant effects on blood pressure. Methods Empirical data provided by the Genetic Analysis Workshop 19 (2014) included 1,851 Mexican-American individuals with diastolic blood pressure (DBP), systolic blood pressure (SBP), hypertension (HTN) and 461,868 variants from whole- exome sequencing of odd-numbered chromosomes. Bayesian hierarchical generalized linear models using weakly informative prior distributions were applied. Results Associations of rare variants chr1:204214013 (estimate = 39.6, Credible In- terval (CrI) 95% = [25.3, 53.9], Bayesian p = 6:8 × 10−8) in the PLEKHA6 gene and chr11:118518698 (estimate = 32.2, CrI95% = [20.6, 43.9], Bayesian p = 7:0 × 10−8) in the PHLEDB1 gene were identified. Joint effects of grouped rare variants on DBP in 23 genes (Bayesian p = [8:8 × 10−14, 9:3 × 10−8]) and on SBP in 21 genes (Bayesian p = [8:6 × 10−12, 7:8 × 10−8]) in pathways related to hemostasis, sodi- um/calcium transport, ciliary activity, and others were found. No association with hypertension was detected. Conclusions Bayesian hierarchical generalized linear models with weakly informa- tive priors can successfully be applied in exome-wide genetic association analyses of rare variants. -

Gene Knockdown of CENPA Reduces Sphere Forming Ability and Stemness of Glioblastoma Initiating Cells
Neuroepigenetics 7 (2016) 6–18 Contents lists available at ScienceDirect Neuroepigenetics journal homepage: www.elsevier.com/locate/nepig Gene knockdown of CENPA reduces sphere forming ability and stemness of glioblastoma initiating cells Jinan Behnan a,1, Zanina Grieg b,c,1, Mrinal Joel b,c, Ingunn Ramsness c, Biljana Stangeland a,b,⁎ a Department of Molecular Medicine, Institute of Basic Medical Sciences, The Medical Faculty, University of Oslo, Oslo, Norway b Norwegian Center for Stem Cell Research, Department of Immunology and Transfusion Medicine, Oslo University Hospital, Oslo, Norway c Vilhelm Magnus Laboratory for Neurosurgical Research, Institute for Surgical Research and Department of Neurosurgery, Oslo University Hospital, Oslo, Norway article info abstract Article history: CENPA is a centromere-associated variant of histone H3 implicated in numerous malignancies. However, the Received 20 May 2016 role of this protein in glioblastoma (GBM) has not been demonstrated. GBM is one of the most aggressive Received in revised form 23 July 2016 human cancers. GBM initiating cells (GICs), contained within these tumors are deemed to convey Accepted 2 August 2016 characteristics such as invasiveness and resistance to therapy. Therefore, there is a strong rationale for targeting these cells. We investigated the expression of CENPA and other centromeric proteins (CENPs) in Keywords: fi CENPA GICs, GBM and variety of other cell types and tissues. Bioinformatics analysis identi ed the gene signature: fi Centromeric proteins high_CENP(AEFNM)/low_CENP(BCTQ) whose expression correlated with signi cantly worse GBM patient Glioblastoma survival. GBM Knockdown of CENPA reduced sphere forming ability, proliferation and cell viability of GICs. We also Brain tumor detected significant reduction in the expression of stemness marker SOX2 and the proliferation marker Glioblastoma initiating cells and therapeutic Ki67. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Functional Screening of Alzheimer Risk Loci Identifies PTK2B
OPEN Molecular Psychiatry (2017) 22, 874–883 www.nature.com/mp ORIGINAL ARTICLE Functional screening of Alzheimer risk loci identifies PTK2B as an in vivo modulator and early marker of Tau pathology P Dourlen1,2,3, FJ Fernandez-Gomez4,5,6, C Dupont1,2,3, B Grenier-Boley1,2,3, C Bellenguez1,2,3, H Obriot4,5,6, R Caillierez4,5,6, Y Sottejeau1,2,3, J Chapuis1,2,3, A Bretteville1,2,3, F Abdelfettah1,2,3, C Delay1,2,3, N Malmanche1,2,3, H Soininen7, M Hiltunen7,8, M-C Galas4,5,6, P Amouyel1,2,3,9, N Sergeant4,5,6, L Buée4,5,6, J-C Lambert1,2,3,11 and B Dermaut1,2,3,10,11 A recent genome-wide association meta-analysis for Alzheimer’s disease (AD) identified 19 risk loci (in addition to APOE) in which the functional genes are unknown. Using Drosophila, we screened 296 constructs targeting orthologs of 54 candidate risk genes within these loci for their ability to modify Tau neurotoxicity by quantifying the size of 46000 eyes. Besides Drosophila Amph (ortholog of BIN1), which we previously implicated in Tau pathology, we identified p130CAS (CASS4), Eph (EPHA1), Fak (PTK2B) and Rab3-GEF (MADD) as Tau toxicity modulators. Of these, the focal adhesion kinase Fak behaved as a strong Tau toxicity suppressor in both the eye and an independent focal adhesion-related wing blister assay. Accordingly, the human Tau and PTK2B proteins biochemically interacted in vitro and PTK2B co-localized with hyperphosphorylated and oligomeric Tau in progressive pathological stages in the brains of AD patients and transgenic Tau mice. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

DNA Methylation Changes in Down Syndrome Derived Neural Ipscs Uncover Co-Dysregulation of ZNF and HOX3 Families of Transcription
Laan et al. Clinical Epigenetics (2020) 12:9 https://doi.org/10.1186/s13148-019-0803-1 RESEARCH Open Access DNA methylation changes in Down syndrome derived neural iPSCs uncover co- dysregulation of ZNF and HOX3 families of transcription factors Loora Laan1†, Joakim Klar1†, Maria Sobol1, Jan Hoeber1, Mansoureh Shahsavani2, Malin Kele2, Ambrin Fatima1, Muhammad Zakaria1, Göran Annerén1, Anna Falk2, Jens Schuster1 and Niklas Dahl1* Abstract Background: Down syndrome (DS) is characterized by neurodevelopmental abnormalities caused by partial or complete trisomy of human chromosome 21 (T21). Analysis of Down syndrome brain specimens has shown global epigenetic and transcriptional changes but their interplay during early neurogenesis remains largely unknown. We differentiated induced pluripotent stem cells (iPSCs) established from two DS patients with complete T21 and matched euploid donors into two distinct neural stages corresponding to early- and mid-gestational ages. Results: Using the Illumina Infinium 450K array, we assessed the DNA methylation pattern of known CpG regions and promoters across the genome in trisomic neural iPSC derivatives, and we identified a total of 500 stably and differentially methylated CpGs that were annotated to CpG islands of 151 genes. The genes were enriched within the DNA binding category, uncovering 37 factors of importance for transcriptional regulation and chromatin structure. In particular, we observed regional epigenetic changes of the transcription factor genes ZNF69, ZNF700 and ZNF763 as well as the HOXA3, HOXB3 and HOXD3 genes. A similar clustering of differential methylation was found in the CpG islands of the HIST1 genes suggesting effects on chromatin remodeling. Conclusions: The study shows that early established differential methylation in neural iPSC derivatives with T21 are associated with a set of genes relevant for DS brain development, providing a novel framework for further studies on epigenetic changes and transcriptional dysregulation during T21 neurogenesis. -

Download Download
Supplementary Figure S1. Results of flow cytometry analysis, performed to estimate CD34 positivity, after immunomagnetic separation in two different experiments. As monoclonal antibody for labeling the sample, the fluorescein isothiocyanate (FITC)- conjugated mouse anti-human CD34 MoAb (Mylteni) was used. Briefly, cell samples were incubated in the presence of the indicated MoAbs, at the proper dilution, in PBS containing 5% FCS and 1% Fc receptor (FcR) blocking reagent (Miltenyi) for 30 min at 4 C. Cells were then washed twice, resuspended with PBS and analyzed by a Coulter Epics XL (Coulter Electronics Inc., Hialeah, FL, USA) flow cytometer. only use Non-commercial 1 Supplementary Table S1. Complete list of the datasets used in this study and their sources. GEO Total samples Geo selected GEO accession of used Platform Reference series in series samples samples GSM142565 GSM142566 GSM142567 GSM142568 GSE6146 HG-U133A 14 8 - GSM142569 GSM142571 GSM142572 GSM142574 GSM51391 GSM51392 GSE2666 HG-U133A 36 4 1 GSM51393 GSM51394 only GSM321583 GSE12803 HG-U133A 20 3 GSM321584 2 GSM321585 use Promyelocytes_1 Promyelocytes_2 Promyelocytes_3 Promyelocytes_4 HG-U133A 8 8 3 GSE64282 Promyelocytes_5 Promyelocytes_6 Promyelocytes_7 Promyelocytes_8 Non-commercial 2 Supplementary Table S2. Chromosomal regions up-regulated in CD34+ samples as identified by the LAP procedure with the two-class statistics coded in the PREDA R package and an FDR threshold of 0.5. Functional enrichment analysis has been performed using DAVID (http://david.abcc.ncifcrf.gov/) -

PDF Output of CLIC (Clustering by Inferred Co-Expression)
PDF Output of CLIC (clustering by inferred co-expression) Dataset: Num of genes in input gene set: 13 Total number of genes: 16493 CLIC PDF output has three sections: 1) Overview of Co-Expression Modules (CEMs) Heatmap shows pairwise correlations between all genes in the input query gene set. Red lines shows the partition of input genes into CEMs, ordered by CEM strength. Each row shows one gene, and the brightness of squares indicates its correlations with other genes. Gene symbols are shown at left side and on the top of the heatmap. 2) Details of each CEM and its expansion CEM+ Top panel shows the posterior selection probability (dataset weights) for top GEO series datasets. Bottom panel shows the CEM genes (blue rows) as well as expanded CEM+ genes (green rows). Each column is one GEO series dataset, sorted by their posterior probability of being selected. The brightness of squares indicates the gene's correlations with CEM genes in the corresponding dataset. CEM+ includes genes that co-express with CEM genes in high-weight datasets, measured by LLR score. 3) Details of each GEO series dataset and its expression profile: Top panel shows the detailed information (e.g. title, summary) for the GEO series dataset. Bottom panel shows the background distribution and the expression profile for CEM genes in this dataset. Overview of Co-Expression Modules (CEMs) with Dataset Weighting Scale of average Pearson correlations Num of Genes in Query Geneset: 13. Num of CEMs: 1. 0.0 0.2 0.4 0.6 0.8 1.0 Cenpk Cenph Cenpp Cenpu Cenpn Cenpq Cenpl Apitd1 -

Conserved and Novel Properties of Clathrin-Mediated Endocytosis in Dictyostelium Discoideum" (2012)
Rockefeller University Digital Commons @ RU Student Theses and Dissertations 2012 Conserved and Novel Properties of Clathrin- Mediated Endocytosis in Dictyostelium Discoideum Laura Macro Follow this and additional works at: http://digitalcommons.rockefeller.edu/ student_theses_and_dissertations Part of the Life Sciences Commons Recommended Citation Macro, Laura, "Conserved and Novel Properties of Clathrin-Mediated Endocytosis in Dictyostelium Discoideum" (2012). Student Theses and Dissertations. Paper 163. This Thesis is brought to you for free and open access by Digital Commons @ RU. It has been accepted for inclusion in Student Theses and Dissertations by an authorized administrator of Digital Commons @ RU. For more information, please contact [email protected]. CONSERVED AND NOVEL PROPERTIES OF CLATHRIN- MEDIATED ENDOCYTOSIS IN DICTYOSTELIUM DISCOIDEUM A Thesis Presented to the Faculty of The Rockefeller University in Partial Fulfillment of the Requirements for the degree of Doctor of Philosophy by Laura Macro June 2012 © Copyright by Laura Macro 2012 CONSERVED AND NOVEL PROPERTIES OF CLATHRIN- MEDIATED ENDOCYTOSIS IN DICTYOSTELIUM DISCOIDEUM Laura Macro, Ph.D. The Rockefeller University 2012 The protein clathrin mediates one of the major pathways of endocytosis from the extracellular milieu and plasma membrane. Clathrin functions with a network of interacting accessory proteins, one of which is the adaptor complex AP-2, to co-ordinate vesicle formation. Disruption of genes involved in clathrin-mediated endocytosis causes embryonic lethality in multicellular animals suggesting that clathrin-mediated endocytosis is a fundamental cellular process. However, loss of clathrin-mediated endocytosis genes in single cell eukaryotes, such as S.cerevisiae (yeast), does not cause lethality, suggesting that clathrin may convey specific advantages for multicellularity.