Detection of Vulnerabilities and Automatic Protection for Web Applications
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Customer Relationship Management Software February 2019
CUSTOMER RELATIONSHIP MANAGEMENT SOFTWARE FEBRUARY 2019 Powered by Methodology CONTENTS 3 Introduction 5 Defining CRM Software 6 FrontRunners (Small Vendors) 8 FrontRunners (Enterprise Vendors) 10 Runners Up 24 Methodology Basics 2 INTRODUCTION his FrontRunners analysis graphic had a minimum qualifying Tis a data-driven assessment score of 4.01 for Usability and 4.11 identifying products in the Customer for User Recommended, while Relationship Management (CRM) the Small Vendor graphic had a software market that offer the minimum qualifying score of 4.31 best capability and value for small for Usability and 4.31 for User businesses. For a given market, Recommended. products are evaluated and given a score for Usability (x-axis) and To be considered for the CRM User Recommended (y-axis). FrontRunners, a product needed FrontRunners then plots 10-15 a minimum of 20 user reviews products each on a Small Vendor published within 18 months of the and an Enterprise Vendor graphic, evaluation period. Products needed based on vendor business size, per a minimum user rating score of category. 3.0 for both Usability and User Recommended in both the Small In the CRM FrontRunners and Enterprise graphics. infographic, the Enterprise Vendor 3 INTRODUCTION The minimum score cutoff to be included in the FrontRunners graphic varies by category, depending on the range of scores in each category. No product with a score less than 3.0 in either dimension is included in any FrontRunners graphic. For products included, the Usability and User Recommended scores determine their positions on the FrontRunners graphic. 4 DEFINING CRM SOFTWARE ustomer Relationship Software Advice’s FrontRunners CManagement (CRM) software is focused on the North American helps organizations manage CRM market. -
Software Übersicht
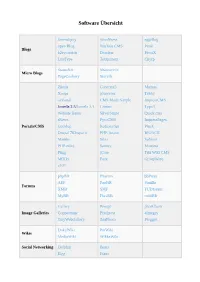
Software Übersicht Serendipity WordPress eggBlog open Blog Nucleus CMS Pixie Blogs b2evolution Dotclear PivotX LifeType Textpattern Chyrp StatusNet Sharetronix Micro Blogs PageCookery Storytlr Zikula Concrete5 Mahara Xoops phpwcms Tribiq ocPortal CMS Made Simple ImpressCMS Joomla 2.5/Joomla 3.1 Contao Typo3 Website Baker SilverStripe Quick.cms sNews PyroCMS ImpressPages Portals/CMS Geeklog Redaxscript Pluck Drupal 7/Drupal 8 PHP-fusion BIGACE Mambo Silex Subrion PHP-nuke Saurus Monstra Pligg jCore Tiki Wiki CMS MODx Fork GroupWare e107 phpBB Phorum bbPress AEF PunBB Vanilla Forums XMB SMF FUDforum MyBB FluxBB miniBB Gallery Piwigo phpAlbum Image Galleries Coppermine Pixelpost 4images TinyWebGallery ZenPhoto Plogger DokuWiki PmWiki Wikis MediaWiki WikkaWiki Social Networking Dolphin Beatz Elgg Etano Jcow PeoplePods Oxwall Noahs Classifieds GPixPixel Ad Management OpenX OSClass OpenClassifieds WebCalendar phpScheduleIt Calenders phpicalendar ExtCalendar BlackNova Traders Word Search Puzzle Gaming Shadows Rising MultiPlayer Checkers phplist Webmail Lite Websinsta maillist OpenNewsletter Mails SquirrelMail ccMail RoundCube LimeSurvey LittlePoll Matomo Analytics phpESP Simple PHP Poll Open Web Analytics Polls and Surveys CJ Dynamic Poll Aardvark Topsites Logaholic EasyPoll Advanced Poll dotProject Feng Office Traq phpCollab eyeOSh Collabtive Project PHProjekt The Bug Genie Eventum Management ProjectPier TaskFreak FlySpray Mantis Bug tracker Mound Zen Cart WHMCS Quick.cart Magento Open Source Point of Axis osCommerce Sale TheHostingTool Zuescart -

Facultad De Ingeniería Carrera Profesional De Ingeniería De Sistemas E Informática
UNIVERSIDAD PRIVADA DE TRUJILLO FACULTAD DE INGENIERÍA CARRERA PROFESIONAL DE INGENIERÍA DE SISTEMAS E INFORMÁTICA CRITERIOS DE EVALUACIÓN PARA LA SELECCIÓN DE UN SISTEMA ERP OPEN SOURCE PARA LA EMPRESA INVERSIONES AVÍCOLA GÉNESIS, TRUJILLO, 2020. TESIS PARA OPTAR EL TÍTULO PROFESIONAL DE INGENIERO DE SISTEMAS E INFORMÁTICA AUTOR: Bach. Kennedy Vidal Valverde Alvites ASESOR: Ing. José Alberto Gómez Ávila Trujillo – Perú 2021 CRITERIOS DE EVALUACIÓN PARA LA SELECCIÓN DE UN SISTEMA ERP OPEN SOURCE PARA LA EMPRESA INVERSIONES AVÍCOLA GÉNESIS, TRUJILLO, 2020. APROBACIÓN DE LA TESIS El asesor y los miembros del jurado evaluador asignados, APRUEBAN la tesis desarrollada por el Bachiller Kennedy Vidal Valverde Alvites, denominada: “CRITERIOS DE EVALUACIÓN PARA LA SELECCIÓN DE UN SISTEMA ERP OPEN SOURCE PARA LA EMPRESA INVERSIONES AVÍCOLA GÉNESIS, TRUJILLO, 2020” Dr. Gómez Ávila José Alberto PRESIDENTE Mg. Santos Fernández Juan Pedro SECRETARIO Mg. Díaz Díaz Franklin Alexis VOCAL VALVERDE ALVITES, KENNEDY VIDAL Pág. ii CRITERIOS DE EVALUACIÓN PARA LA SELECCIÓN DE UN SISTEMA ERP OPEN SOURCE PARA LA EMPRESA INVERSIONES AVÍCOLA GÉNESIS, TRUJILLO, 2020. DEDICATORIA A Dios todopoderoso, creador de los cielos y la tierra, el Alfa y la Omega, el que es y que era y que ha de venir. A mi padre Vidal y a mi madre Alvina, con mucho amor. A mis hermanos Joel, Benony, Paúl, Rafael y mi hermana Jackelyne, en mis alegrías y tristezas, con mucho cariño. VALVERDE ALVITES, KENNEDY VIDAL Pág. iii CRITERIOS DE EVALUACIÓN PARA LA SELECCIÓN DE UN SISTEMA ERP OPEN SOURCE PARA LA EMPRESA INVERSIONES AVÍCOLA GÉNESIS, TRUJILLO, 2020. AGRADECIMIENTO A mi Dios Eterno, por darme la vida, la sabiduría, por cuidarme y guiarme en sus caminos. -

Application of Open-Source Enterprise Information System Modules: an Empirical Study
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Dissertations, Theses, and Student Research from the College of Business Business, College of Summer 7-20-2010 APPLICATION OF OPEN-SOURCE ENTERPRISE INFORMATION SYSTEM MODULES: AN EMPIRICAL STUDY Sang-Heui Lee University of Nebraska-Lincoln Follow this and additional works at: https://digitalcommons.unl.edu/businessdiss Part of the Management Information Systems Commons, Other Business Commons, and the Technology and Innovation Commons Lee, Sang-Heui, "APPLICATION OF OPEN-SOURCE ENTERPRISE INFORMATION SYSTEM MODULES: AN EMPIRICAL STUDY" (2010). Dissertations, Theses, and Student Research from the College of Business. 13. https://digitalcommons.unl.edu/businessdiss/13 This Article is brought to you for free and open access by the Business, College of at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Dissertations, Theses, and Student Research from the College of Business by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. APPLICATION OF OPEN-SOURCE ENTERPRISE INFORMATION SYSTEM MODULES: AN EMPIRICAL STUDY by Sang-Heui Lee A DISSERTATION Presented to the Faculty of The Graduate College at the University of Nebraska In Partial Fulfillment of Requirements For the Degree of Doctor of Philosophy Major: Interdepartmental Area of Business (Management) Under the Supervision of Professor Sang M. Lee Lincoln, Nebraska July 2010 APPLICATION OF OPEN-SOURCE ENTERPRISE INFORMATION SYSTEM MODULES: AN EMPIRICAL STUDY Sang-Heui Lee, Ph.D. University of Nebraska, 2010 Advisor: Sang M. Lee Although there have been a number of studies on large scale implementation of proprietary enterprise information systems (EIS), open-source software (OSS) for EIS has received limited attention in spite of its potential as a disruptive innovation. -

Why Use ERP Need, Function ? (R2I2T) Reliable Data: to Make The
Why Use ERP need, function ? (R2I2T) Reliable Data: To make the right business decisions, you need access to the right information at the right time. With an ERP solution configured to your specific needs, you can rest assured that you are receiving accurate data to make smart decisions. Even if you already have an ERP solution in place, years of minor tweaking and connecting with disparate systems may have turned it into a convoluted mess of obscure information. With a new ERP solution, your business can put its trust in an up to date and reliable system. Transparency: A huge boon to business is being able to identify which products and departments are saving/providing money and which are falling behind. With an ERP solution in place you can pin point exactly which areas need to be addressed accordingly. By being able to quickly decipher where your company's strengths and weaknesses are, you can improve profitability before losing it. Reduce Total Cost of Ownership (TCO): While it may seem like a large investment at the time, the cost-saving benefits of an ERP solution will out- weigh the initial expenditure on the solution. Even if your business already has a legacy system in place, maintaining an outdated ERP solution can cost an indefinite amount of time and resources as well as limit new opportunities. An ERP solution needs to be looked at in terms of eventual return on investment, not it's immediate cost. Integration with new technologies: With the rise in use of the internet and technology for business, it would severely inhibit a company's ability to advance and grow if their systems did not stay up to date with current tools and trends. -

An In-Depth Review of Enterprise Resource Planning ERP System Overview, Methodology & List of Software Options Contents
An In-Depth Review of Enterprise Resource Planning ERP System Overview, Methodology & List of Software Options Contents 1 Enterprise resource planning 1 1.1 Origin ................................................. 1 1.2 Expansion ............................................... 1 1.3 Characteristics ............................................. 2 1.4 Functional areas of ERP ........................................ 2 1.5 Components .............................................. 2 1.6 Best practices ............................................. 2 1.7 Connectivity to plant floor information ................................ 3 1.8 Implementation ............................................ 3 1.8.1 Process preparation ...................................... 3 1.8.2 Configuration ......................................... 3 1.8.3 Two tier enterprise resource planning ............................. 4 1.8.4 Customization ......................................... 4 1.8.5 Extensions ........................................... 5 1.8.6 Data migration ........................................ 5 1.9 Comparison to special–purpose applications ............................. 5 1.9.1 Advantages .......................................... 5 1.9.2 Benefits ............................................ 5 1.9.3 Disadvantages ......................................... 6 1.10 See also ................................................ 6 1.11 References ............................................... 6 1.12 Bibliography .............................................. 8 1.13 -

TESIS SIS38 Luy.Pdf (5.552Mb)
UNIVERSIDAD NACIONAL DE SAN CRISTOBAL DE HUAMANGA Facultad de Ingenieria de Minas, Gcologia y Civil Escuela de Formacion Profesional de Ingenieria de Sistemas "ADOPCION DE UN ERP PARA APOYAR EL MONITOREO DE RIESGOS DE PROYECTOS DE DESARROLLO SOCIAL EN LA ONG TADEPA AYACUCHO, 2016" Tesis presentado por: Bach. Ludmila Luya Castro Para optar el titulo profesional de: Ingeniero Informatico Asesor: Ing. Juan Carlos Carreno Gamarra Ayacucho, Mayo 2016 "ADOPCION DE UN ERP PARA APOYAR EL MONI FOREO DE RIESGOS DE PROYECTOS DE DESARROLLO SOCIAL EN LA ONG TADEPA A YACUCHO, 2016" RECOMENDADO : 29 DE DICIEMBRE DEL 2015 APROBADO : 19 DE MAYO DEL 2016 Ing. Edith F. GUEVARA MOROTE Presidente(e) y^M Ing. Elinar CARRILLO RIVEROS ^RIENO GAMARRA Miembro Miembro Ing0 Jennifer PILLACA DE LA CRUZ Secretaria Docente (e) Segiin el acuerdo constatado en el Acta, levantado el 19 de mayo del 2016, en la Sustentacion de Tesis presentado por la Bachiller en Ingenien'a Informatica Srta. Ludmila LUYA CASTRO, con la Tesis Titulado "ADOPCION DE UN ERP PARA APOYAR EL MONITOREO DE RIESGOS DE PROYECTOS DE DESARROLLO SOCIAL EN LA ONG TADEPA AYACUCHO, 2016", fue calificado con la nota de CATORCE (14) por lo que se da la respectiva APROBACIQN. RECOMENDADO : 29 DE DICIEMBRE DEL 2015 APROBADO : 19 DE MAYO DEL 2016 Ing. Edith F. Presidente(e) Miembro Ing0 Jennifer PILLACA DE LA CRUZ Secretaria Docente (e) AGRADECIMIENTOS A la Universidad Nacional de San Cristobal de Huamanga, mi alma mater y a los docentes. A mis amigos que me apoyaron en los momentos mas dificiles. ii AGRADECIMIENTOS A la Universidad Nacional de San Cristobal de Huamanga, mi alma mater y a los docentes. -

NEAR EAST UNIVERSITY Faculty of Engineering
NEAR EAST UNIVERSITY Faculty of Engineering Department of Computer Engineering AUTO GALLERY MANAGEMENT SYSTEM Graduation Project COM 400 Student: Ugur Emrah CAKMAK Supervisor : Assoc. Prof. Dr. Rahib ABIYEV Nicosia - 2008 ACKNOWLEDGMENTS "First, I would like to thank my supervisor Assoc. Prof. Dr. Rahib Abiyev for his invaluable advice and belief in my work and myself over the course of this Graduation Project.. Second, I would like to express my gratitude to Near East University for the scholarship that made the work possible. Third, I thank my family for their constant encouragement and support during the preparation of this project. Finally, I would like to thank Neu Computer Engineering Department academicians for their invaluable advice and support. TABLE OF CONTENT ACKNOWLEDGEMENT i TABLE OF CONTENTS ii ABSTRACT iii INTRODUCTION 1 CHAPTER ONE - PHP - Personal Home Page 2 1.1 History Of PHP 2 1.2 Usage 5 1.3 Security 6 1 .4 Syntax 7 1.5 Data Types 8 1.6 Functions 9 1.7 Objects 9 1.8 Resources 10 1.9 Certification 12 1 .1 O List of Web Applications 12 1.11 PHP Code Samples 19 CHAPTER TWO - MySQL 35 2.1 Uses 35 2.2 Platform and Interfaces 36 2.3 Features 37 2.4 Distinguishing Features 38 2.5 History 40 2.6 Future Releases 41 2.7 Support and Licensing .41 2.8 Issues 43 2.9Criticism 44 2.10 Creating the MySQL Database 45 2.11 Database Code of a Sample CMS 50 CHAPTER THREE - Development of Auto Gallery Management System 72 CONCLUSION 77 REFERENCES 78 APPENDIX 79 ii ABSTRACT Auto Gallery Management System is a unique Content Management System which supports functionality for auto galleries. -

Kartoitus Avoimen Lähdekoodin Toiminnanohjausjärjestelmistä
KARTOITUS AVOIMEN LÄHDEKOODIN TOIMINNANOHJAUSJÄRJESTELMISTÄ Pilvi Tontti Opinnäytetyö Maaliskuu 2017 Liiketalouden koulutusohjelma TIIVISTELMÄ Tampereen ammattikorkeakoulu Liiketalouden koulutusohjelma PILVI TONTTI Kartoitus avoimen lähdekoodin toiminnanohjausjärjestelmistä Opinnäytetyö 60 sivua, joista liitteitä 17 sivua Maaliskuu 2017 Sähköisen kaupankäynnin ja tiedonsiirron yleistyttyä on liiketoiminnan sähköisten työ- kalujen käyttö lisääntynyt. Toiminnanohjausjärjestelmät ovat yksi esimerkki edellä mainituista ohjelmistoista. Ne ovat käytössä useilla eri toimialoilla. Usein pieni organi- saatio ei voi hankkia järjestelmää suurten kustannusten takia. Avoimen lähdekoodin ratkaisut ovat lisänneet kilpailuetuaan markkinoilla suljettuihin ohjelmistoihin nähden edullisuutensa ja yhteisö-ideologiansa ansiosta. Yhdistämällä yhteisökehityksen edut ja toiminnanohjaus luodaan pienellekin toimijalle mahdollisuus hankkia järjestelmä. Opinnäytetyö tehdään Suomen avoimien tietojärjestelmien keskukselle - COSS ry:lle. Yhdistyksen tarkoituksena on avoimen teknologian edistäminen ja avoimia ohjelmistoja tarjoavien jäsenyritystensä liiketoiminnan tukeminen. Opinnäytteessä keskityttiin tar- kastelemaan avoimen lähdekoodin ERP-järjestelmiä. Työn tavoitteena oli perehtyä avoimeen lähdekoodiin ja toiminnanohjausjärjestelmiin. Työn tarkoituksena oli tehdä kartoitus markkinoilla olevista avoimen lähdekoodin ERP-järjestelmistä sekä selvittää niiden ominaisuuksia. Avoimen lähdekoodin ERP-järjestelmiä on paljon tarjolla. Kartoituksessa selvisi, että suomalaisia -

Compare Oracle CRM Vs. Microsoft Dynamics 365
Compare Oracle CRM vs. Microsoft Dynamics 365 If you wish for an effective CRM Software product for your company you need to take time to evaluate several alternatives. It doesn’t have to be difficult, and can be as easy as matching their functionalities in a table like the one below. You will also get a quick idea how each product operates. For example, on this page you can find Microsoft Dynamics 365’s overall score of 9.2 and compare it against Oracle CRM’s score of 8.7; or Microsoft Dynamics 365’s user satisfaction level at 96% versus Oracle CRM’s 99% satisfaction score. The evaluation will help you find out the pros and cons of each service, and choose which one suits you requirements better. On top of the rich features, the application which is simple and intuitive is always the better product. At the moment, the leading solutions in our CRM Software category are: Pipedrive, HubSpot CRM, Freshdesk. < Previous Next > HubSpot CRM Compare Oracle CRM Microsoft Dynamics 365 VS ---select option--- VS VS FREE Partner Our Score Our Score Our Score Score 8.7 9.2 9.8 Client Experience Client Experience Client Experience Client Experience 99% 96% 99% Price $75.00 $40 free Price Scheme Monthly payment | Annual Subscription Monthly payment | Quote-based Free Full Review Review of Oracle CRM Review of Microsoft Dynamics 365 Review of HubSpot CRM General Info Oracle CRM handles all customer HubSpot CRM is the winner of our 2018 relationship management issues and Cloud-based CRM solution Microsoft Best CRM Award. -

List of Tools Recommended for the Creation of Website
List of tools recommended for the creation of website. Philemonday Agency recommends tools, scripts and plug-ins to build your website. We list here more than 390 scripts that we had the opportunity to use during our missions of creation of website. We are using to work on all of these scripts. Feel free to contact us. http://www.philemonday-agency.com/ April 2014 [SOURCES] Philemonday Agency recommends tools, scripts and plug-ins to build your website. We list here more than 390 scripts that we had the opportunity to use during our missions of creation of website. We work on all of these scripts. == 4images Chevereto Free Elgg Aardvark Topsite Chive ElkArte AbanteCart Chyrp EPESI AbanteCart CJ Dynamic Poll EspoCRM Admidio Claroline eSyndiCat Adminer ClientExec Etano Advanced Guest.. ClipBucket Eventum Advanced Poll ClipperCMS ExoPHPDesk AEF CMS Made Simple ExtCalendar Agora-Project CMSimple eXtplorer AJAX Chat CodeIgniter eyeOS AlegroCart Codiad Family Connect.. Ampache Collabtive Faveo Helpdesk AmpJuke Commentics Feed On Feeds Anchor Composr Feng Office appRain Concrete5 Fiyo CMS Arastta Contao FlatPress Arfooo Coppermine FluxBB ArticleSetup Cotonti Flyspray ATutor Croogo Fork Avactis CubeCart Form Tools Axis CubeCart FreshRSS b2evolution CumulusClips FrontAccounting bbPress Dada Mail FUDforum Beatz DIY FuelPHP Beehive DoceboLMS Fusio BellaBook Dokeos Gallery BlaB DokuWiki Geeklog BlackNova Trad.. Dolibarr Ghost Blesta Dolphin Gibbon Bludit Dolphin GLPI Bolt DomainMOD GNU social Booked Dotclear GPixPixel Bootstrap dotProject GRAV BoxBilling Drupal Gregarius Brushtail e107 Group Office Bugs EasyPoll Hablator Burden EC-CUBE Help Center Li.. CakePHP eFront HelpDeskZ ccMail eggBlog HelpDEZk Chamilo EGroupware HESK Hotaru CMS Mibew Messenger PHP QR Code HTML Purifier Microweber PHP-Fusion HTMLy miniBB PHP-Nuke HumHub MODX phpAlbum iGalerie Monsta FTP phpBB Impleo Monstra phpBB ImpressCMS Moodle phpBook ImpressPages Movable Type phpCOIN InfiniteWP Multiplayer Ch. -

PHP Programming Language
PHP Programming Language PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Thu, 17 Jun 2010 01:34:21 UTC Contents Articles Active Agenda 1 Active Calendar 2 Adminer 8 Aigaion 10 Aiki Framework 12 Asido 13 Associate- O- Matic 16 AutoTheme 18 Avactis 19 BakeSale 22 Beehive Forum 23 bitcart 25 BlueErp 29 BuddyPress 30 ccHost 32 Claroline 34 Comparison of knowledge base management software 36 concrete5 42 Coppermine Photo Gallery 44 Croogo 46 DBG 47 Delphi for PHP 47 Doctrine (PHP) 49 Dokeos 52 dotProject 55 User:Drietsch/ pimcore 57 DynPG 58 eAccelerator 59 Elgg (software) 60 EpesiBIM 62 Flash Gallery 64 Flash MP3 Player 66 FluxBB 68 Frog CMS 71 Gallery Project 73 Gamboo Web Suite 75 Gateway Anti- Virus 77 GoogleTap 78 Group- Office 79 Habari 81 Horde (software) 85 HuMo- gen 86 IPBWI 89 Icy Phoenix 91 Ingo (software) 94 Injader 95 Intelestream 96 Internet Messaging Program 98 Invision Power Board 99 ionCube 101 Joomla 103 Joomsef 106 KnowledgeBase Manager Pro 108 List of PHP accelerators 109 List of PHP libraries 112 Magic quotes 113 Mambo (software) 115 Merlintalk 120 MetaBB 122 MiaCMS 123 Midgard (software) 125 Midgard Lite 129 MindTouch Deki 130 Monkey Boards 134 Moodle 135 Moxietype 140 MyBB 141 NETSOFTWARE 144 net2ftp 146 User:Nichescript/ Affiliate Niche Sript 147 Ning (website) 148 NolaPro 152 ORMer 154 ocPortal 155 Open Realty 158 OpenBiblio 159 Opus (content management system) 161 osCommerce 163 PEAR 166 PHP accelerator 167 PHP syntax and semantics 168 PHP/