Monzur Murshed
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Webové Diskusní Fórum
MASARYKOVA UNIVERZITA F}w¡¢£¤¥¦§¨ AKULTA INFORMATIKY !"#$%&'()+,-./012345<yA| Webové diskusní fórum BAKALÁRSKÁˇ PRÁCE Martin Bana´s Brno, Jaro 2009 Prohlášení Prohlašuji, že tato bakaláˇrskápráce je mým p ˚uvodnímautorským dílem, které jsem vy- pracoval samostatnˇe.Všechny zdroje, prameny a literaturu, které jsem pˇrivypracování používal nebo z nich ˇcerpal,v práci ˇrádnˇecituji s uvedením úplného odkazu na pˇríslušný zdroj. V Brnˇe,dne . Podpis: . Vedoucí práce: prof. RNDr. JiˇríHˇrebíˇcek,CSc. ii Podˇekování Dˇekujivedoucímu prof. RNDr. JiˇrímuHˇrebíˇckovi,CSc. za správné vedení v pr ˚ubˇehucelé práce a trpˇelivostpˇrikonzutacích. Dále dˇekujicelému kolektivu podílejícímu se na reali- zaci projektu FEED za podnˇetnépˇripomínkya postˇrehy. iii Shrnutí Bakaláˇrskápráce se zabývá analýzou souˇcasnýchdiskusních fór typu open-source a vý- bˇerem nejvhodnˇejšíhodiskusního fóra pro projekt eParticipation FEED. Další ˇcástpráce je zamˇeˇrenána analýzu vybraného fóra, tvorbu ˇceskéhomanuálu, ˇceskélokalizace pro portál a rozšíˇrenípro anotaci pˇríspˇevk˚u. Poslední kapitola je vˇenovánanasazení systému do provozu a testování rozšíˇrení pro anotaci pˇríspˇevk˚u. iv Klíˇcováslova projekt FEED, eParticipation, diskusní fórum, portál, PHP, MySQL, HTML v Obsah 1 Úvod ...........................................3 2 Projekt eParticipation FEED .............................4 2.1 eGovernment ...................................4 2.2 Úˇcastníciprojektu FEED .............................4 2.3 Zamˇeˇreníprojektu FEED .............................5 2.4 Cíl -

Inequalities in Open Source Software Development: Analysis of Contributor’S Commits in Apache Software Foundation Projects
RESEARCH ARTICLE Inequalities in Open Source Software Development: Analysis of Contributor’s Commits in Apache Software Foundation Projects Tadeusz Chełkowski1☯, Peter Gloor2☯*, Dariusz Jemielniak3☯ 1 Kozminski University, Warsaw, Poland, 2 Massachusetts Institute of Technology, Center for Cognitive Intelligence, Cambridge, Massachusetts, United States of America, 3 Kozminski University, New Research on Digital Societies (NeRDS) group, Warsaw, Poland ☯ These authors contributed equally to this work. * [email protected] a11111 Abstract While researchers are becoming increasingly interested in studying OSS phenomenon, there is still a small number of studies analyzing larger samples of projects investigating the structure of activities among OSS developers. The significant amount of information that OPEN ACCESS has been gathered in the publicly available open-source software repositories and mailing- list archives offers an opportunity to analyze projects structures and participant involve- Citation: Chełkowski T, Gloor P, Jemielniak D (2016) Inequalities in Open Source Software Development: ment. In this article, using on commits data from 263 Apache projects repositories (nearly Analysis of Contributor’s Commits in Apache all), we show that although OSS development is often described as collaborative, but it in Software Foundation Projects. PLoS ONE 11(4): fact predominantly relies on radically solitary input and individual, non-collaborative contri- e0152976. doi:10.1371/journal.pone.0152976 butions. We also show, in the first published study of this magnitude, that the engagement Editor: Christophe Antoniewski, CNRS UMR7622 & of contributors is based on a power-law distribution. University Paris 6 Pierre-et-Marie-Curie, FRANCE Received: December 15, 2015 Accepted: March 22, 2016 Published: April 20, 2016 Copyright: © 2016 Chełkowski et al. -

Introduction Points
Introduction Points Ahmia.fi - Clearnet search engine for Tor Hidden Services (allows you to add new sites to its database) TORLINKS Directory for .onion sites, moderated. Core.onion - Simple onion bootstrapping Deepsearch - Another search engine. DuckDuckGo - A Hidden Service that searches the clearnet. TORCH - Tor Search Engine. Claims to index around 1.1 Million pages. Welcome, We've been expecting you! - Links to basic encryption guides. Onion Mail - SMTP/IMAP/POP3. ***@onionmail.in address. URSSMail - Anonymous and, most important, SECURE! Located in 3 different servers from across the globe. Hidden Wiki Mirror - Good mirror of the Hidden Wiki, in the case of downtime. Where's pedophilia? I WANT IT! Keep calm and see this. Enter at your own risk. Site with gore content is well below. Discover it! Financial Services Currencies, banks, money markets, clearing houses, exchangers. The Green Machine Forum type marketplace for CCs, Paypals, etc.... Some very good vendors here!!!! Paypal-Coins - Buy a paypal account and receive the balance in your bitcoin wallet. Acrimonious2 - Oldest escrowprovider in onionland. BitBond - 5% return per week on Bitcoin Bonds. OnionBC Anonymous Bitcoin eWallet, mixing service and Escrow system. Nice site with many features. The PaypalDome Live Paypal accounts with good balances - buy some, and fix your financial situation for awhile. EasyCoin - Bitcoin Wallet with free Bitcoin Mixer. WeBuyBitcoins - Sell your Bitcoins for Cash (USD), ACH, WU/MG, LR, PayPal and more. Cheap Euros - 20€ Counterfeit bills. Unbeatable prices!! OnionWallet - Anonymous Bitcoin Wallet and Bitcoin Laundry. BestPal BestPal is your Best Pal, if you need money fast. Sells stolen PP accounts. -

Exploring Factors and Measures to Select Open Source Software
Exploring Factors and Measures to Select Open Source Software Xiaozhou Li*a, Sergio Moreschini*a, Zheying Zhanga, Davide Taibia aTampere University, Tampere (Finland) ∗ the two authors equally contributed to the paper Abstract [Context] Open Source Software (OSS) is nowadays used and integrated in most of the commercial products. However, the selection of OSS projects for integration is not a simple process, mainly due to a of lack of clear selection models and lack of information from the OSS portals. [Objective] We investigated the current factors and measures that prac- titioners are currently considering when selecting OSS, the source of infor- mation and portals that can be used to assess the factors, and the possibility to automatically get this information with APIs. [Method] We elicited the factors and the measures adopted to assess and compare OSS performing a survey among 23 experienced developers who often integrate OSS in the software they develop. Moreover, we investigated the APIs of the portals adopted to assess OSS extracting information for the most starred 100K projects in GitHub. [Result] We identified a set consisting of 8 main factors and 74 sub- factors, together with 170 related metrics that companies can use to select OSS to be integrated in their software projects. Unexpectedly, only a small part of the factors can be evaluated automatically, and out of 170 metrics, only 40 are available, of which only 22 returned information for all the 100K projects. [Conclusion.] OSS selection can be partially automated, by extracting arXiv:2102.09977v1 [cs.SE] 19 Feb 2021 the information needed for the selection from portal APIs. -

Student Authored Textbook on Software Architectures
Software Architectures: Case Studies Authors: Students in Software Architectures course Computer Science and Computer Engineering Department University of Arkansas May 2014 Table of Contents Chapter 1 - HTML5 Chapter 2 – XML, XML Schema, XSLT, and XPath Chapter 3 – Design Patterns: Model-View-Controller Chapter 4 – Push Notification Services: Google and Apple Chapter 5 - Understanding Access Control and Digital Rights Management Chapter 6 – Service-Oriented Architectures, Enterprise Service Bus, Oracle and TIBCO Chapter 7 – Cloud Computing Architecture Chapter 8 – Architecture of SAP and Oracle Chapter 9 – Spatial and Temporal DBMS Extensions Chapter 10 – Multidimensional Databases Chapter 11 – Map-Reduce, Hadoop, HDFS, Hbase, MongoDB, Apache HIVE, and Related Chapter 12 –Business Rules and DROOLS Chapter 13 – Complex Event Processing Chapter 14 – User Modeling Chapter 15 – The Semantic Web Chapter 16 – Linked Data, Ontologies, and DBpedia Chapter 17 – Radio Frequency Identification (RFID) Chapter 18 – Location Aware Applications Chapter 19 – The Architecture of Virtual Worlds Chapter 20 – Ethics of Big Data Chapter 21 – How Hardware Has Altered Software Architecture SOFTWARE ARCHITECTURES Chapter 1 – HTML5 Anh Au Summary In this chapter, we cover HTML5 and the specifications of HTML5. HTML takes a major part in defining the Web platform. We will cover high level concepts, the history of HTML, and famous HTML implementations. This chapter also covers how this system fits into a larger application architecture. Lastly, we will go over the high level architecture of HTML5 and cover HTML5 structures and technologies. Introduction High level concepts – what is the basic functionality of this system HyperText Markup Language (HTML) is the markup language used by to create, interpret, and annotate hypertext documents on any platform. -

Publishing Research Software As Open Source on Github
Publishing Research Software as Open Source on GitHub Table of Contents 1. Introduction 2. Scope & Goals 3. Science & Software i. Reproducibility ii. Software Quality iii. Software Development iv. Software Documentation v. Guide 4. Open Source Basics i. Mindset ii. Arguments against open source... and how to disprove them iii. Success Stories iv. Legal Stuff v. People vi. Guide 5. GitHub i. Basics: Accounts & Repositories ii. Fork & Pull Workflow iii. Social Coding iv. GitHub for Education 6. Software Communities i. Community Building and Openness ii. Marketing and Public Relations iii. Types of Contributors and Tasks iv. Open Source in Your Domain 7. Scientific Publishing of Data and Software 8. Contribute 9. Glossary 2 Publishing Research Software as Open Source on GitHub Introduction How can you publish research software as open source? And do so without too much overhead and actually gain impact by leveraging the open source approach? These questions are answered in this best practice "Publishing Research Software as Open Source on GitHub". It is published by the GLUES project's SDI team. LICENSE This work is licensed under a Creative Commons Attribution 4.0 International License. About this best practice The "source code" of this document is hosted on GitHub and the book was written and published using GitBook. The text is designed to be read in the web view, but PDF and other formats, e.g. for e- readers, area available as well. Version: 0.1 Contributors Thanks to these people for providing contents, giving valuable feedback, reporting errors, ... Daniel Nüst Simon Jirka Ann Hitchcock Want to become a contributor? Check our contribution guidelines. -

Corporate Registry Registrar's Periodical Template
Service Alberta ____________________ Corporate Registry ____________________ Registrar’s Periodical REGISTRAR’S PERIODICAL, OCTOBER 15, 2009 SERVICE ALBERTA Corporate Registrations, Incorporations, and Continuations (Business Corporations Act, Cemetery Companies Act, Companies Act, Cooperatives Act, Credit Union Act, Loan and Trust Corporations Act, Religious Societies’ Land Act, Rural Utilities Act, Societies Act, Partnership Act) 0858562 B.C. LTD. Other Prov/Territory Corps 1487822 ALBERTA LTD. Numbered Alberta Registered 2009 SEP 08 Registered Address: 2700 Corporation Incorporated 2009 SEP 01 Registered COMMERCE PLACE, 10155 - 102 STREET, Address: 127 SENECA ROAD, SHERWOOD PARK EDMONTON ALBERTA, T5J 4G8. No: 2114889252. ALBERTA, T8A 4G6. No: 2014878223. 0859953 B.C. LTD. Other Prov/Territory Corps 1487828 ALBERTA LTD. Numbered Alberta Registered 2009 SEP 15 Registered Address: 1200, 700 - Corporation Incorporated 2009 SEP 01 Registered 2ND STREET SW, CALGARY ALBERTA, T2P 4V5. Address: 10040 87 AVE NW, EDMONTON No: 2114902543. ALBERTA, T6E 2N9. No: 2014878280. 101142932 SASKATCHEWAN LTD. Other 1487831 ALBERTA LTD. Numbered Alberta Prov/Territory Corps Registered 2009 SEP 11 Registered Corporation Incorporated 2009 SEP 01 Registered Address: 499 - 1 STREET SE, MEDICINE HAT Address: 3812 MACNEIL HEATH, EDMONTON ALBERTA, T1A 0A7. No: 2114895259. ALBERTA, T6R 0H5. No: 2014878314. 1481801 ALBERTA LTD. Numbered Alberta 1487832 ALBERTA LTD. Numbered Alberta Corporation Incorporated 2009 SEP 07 Registered Corporation Incorporated 2009 SEP 01 Registered Address: 1013 5TH AVENUE, WAINWRIGHT Address: 2056 TANNER WYND, EDMONTON ALBERTA, T9W 1L6. No: 2014818013. ALBERTA, T6R 2R4. No: 2014878322. 1485500 ALBERTA LTD. Numbered Alberta 1487845 ALBERTA LTD. Numbered Alberta Corporation Incorporated 2009 SEP 02 Registered Corporation Incorporated 2009 SEP 03 Registered Address: 2401 TD TOWER, 10088 102 AVENUE, Address: 4007-34A AVENUE NW, EDMONTON EDMONTON ALBERTA, T5J 2Z1. -

A Taxonomy of SQL Injection Defense Techniques
Master’s Thesis Computer Science Thesis no: MCS-2011-46 June 2011 A Taxonomy of SQL Injection Defense Techniques Anup Shakya, Dhiraj Aryal School of Computing Blekinge Institute of Technology SE – 371 79 Karlskrona Sweden This thesis is submitted to the School of Computing at Blekinge Institute of Technology in partial fulfillment of the requirements for the degree of Master of Science in Computer Science. The thesis is equivalent to 20 weeks of full time studies. Contact Information: Author(s): Anup Shakya Address: Älgbacken 8, 372 34 Ronneby E-mail: [email protected] Author(s): Dhiraj Aryal Address: Lindblomsvågen 96, 372 33 Ronneby E-mail: [email protected] University advisor(s): Dr. Stefan Axelsson School of Computing Blekinge Institute of Technology School of Computing Internet : www.bth.se/com Blekinge Institute of Technology Phone : +46 455 38 50 00 SE – 371 79 Karlskrona Fax : +46 455 38 50 57 Sweden Abstract Context: SQL injection attack (SQLIA) poses a serious defense threat to web appli- cations by allowing attackers to gain unhindered access to the underlying databases containing potentially sensitive information. A lot of methods and techniques have been proposed by different researchers and practitioners to mitigate SQL injection problem. However, deploying those methods and techniques without a clear under- standing can induce a false sense of security. Classification of such techniques would provide a great assistance to get rid of such false sense of security. Objectives: This paper is focused on classification of such techniques by building taxonomy of SQL injection defense techniques. Methods: Systematic literature review (SLR) is conducted using five reputed and familiar e-databases; IEEE, ACM, Engineering Village (Inspec/Compendex), ISI web of science and Scopus. -
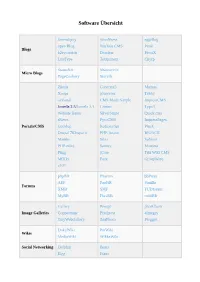
Software Übersicht
Software Übersicht Serendipity WordPress eggBlog open Blog Nucleus CMS Pixie Blogs b2evolution Dotclear PivotX LifeType Textpattern Chyrp StatusNet Sharetronix Micro Blogs PageCookery Storytlr Zikula Concrete5 Mahara Xoops phpwcms Tribiq ocPortal CMS Made Simple ImpressCMS Joomla 2.5/Joomla 3.1 Contao Typo3 Website Baker SilverStripe Quick.cms sNews PyroCMS ImpressPages Portals/CMS Geeklog Redaxscript Pluck Drupal 7/Drupal 8 PHP-fusion BIGACE Mambo Silex Subrion PHP-nuke Saurus Monstra Pligg jCore Tiki Wiki CMS MODx Fork GroupWare e107 phpBB Phorum bbPress AEF PunBB Vanilla Forums XMB SMF FUDforum MyBB FluxBB miniBB Gallery Piwigo phpAlbum Image Galleries Coppermine Pixelpost 4images TinyWebGallery ZenPhoto Plogger DokuWiki PmWiki Wikis MediaWiki WikkaWiki Social Networking Dolphin Beatz Elgg Etano Jcow PeoplePods Oxwall Noahs Classifieds GPixPixel Ad Management OpenX OSClass OpenClassifieds WebCalendar phpScheduleIt Calenders phpicalendar ExtCalendar BlackNova Traders Word Search Puzzle Gaming Shadows Rising MultiPlayer Checkers phplist Webmail Lite Websinsta maillist OpenNewsletter Mails SquirrelMail ccMail RoundCube LimeSurvey LittlePoll Matomo Analytics phpESP Simple PHP Poll Open Web Analytics Polls and Surveys CJ Dynamic Poll Aardvark Topsites Logaholic EasyPoll Advanced Poll dotProject Feng Office Traq phpCollab eyeOSh Collabtive Project PHProjekt The Bug Genie Eventum Management ProjectPier TaskFreak FlySpray Mantis Bug tracker Mound Zen Cart WHMCS Quick.cart Magento Open Source Point of Axis osCommerce Sale TheHostingTool Zuescart -

A South Vietnam Pocket Guide, 1962
ARMY UNIFORMS Of VtnN.AM 7 Ill VIETNAM I 1 rlmJJ- NINE RULES For Personnel of U.S. Military Assistance Command, Vietnam HOW MUCH DO YOU KNOW ABOUT VIETNAM ? The Victnameae have p!Ud • hetJvy price in ruff~ for t hC'lr Ion& fiaht a«Aintt the Commumst.. We mtlitsry attn .,-c in ViCUUU'D o.ow bccau'le their r;ovcr1'mcnt hai Mlccd ue to help iu toldiCTt iaM peopk in winnin& their ttnigglc. Tbc Viet Cone wi11 aucmpt to tum th«' Vietnamese people qainat you. You can defeat. them At c•u:ry lum Why Is It o (Lcn diftkull to by the strength, undcnl.And~. and gcn\!:n:l5ity you display with tell a Viet Cona from a loyol the people. Hett are the nine simple rules: South VictnA~ ? 8 " Remember we are spcdal e;ucats here; we make no demands And aedt no 1pccud U'eAtmc:nt. h 11uoc mam 110mcth1na to wear, "Join with the people! Underatand tbclr life, uee phruct from 1omethin& to or the of e11t , name t hci:r IAneuai:e. end honor their cu1tomt and lawt. t'U\ orglU\i..rotlon? ··Treat womm witb Politcuc!IS and ropc:c:l. ''Malec pcnonal friends am(lng the 110ldicn and common people. Why would a South V1ct.ruuneac be puzzled or off'cndcd J you u1cd " Always i;\vc tbc Vict..o.amcao tllc ril(ht oC way. the American gesture fot beckonini ''Be alert. lo MCUrity and ttady to tellct with your mlllt.ar)' hlm to come to )'OU] alcill. " Don't Al trfct attention by loud, rude. -

CMS, LMS, LCMS Kavramları
XI. Akademik Bilişim Konferansı, 11-13 Şubat 2009, Harran Üniversitesi, ŞANLIURFA CMS, LMS, LCMS Kavramları Özlem Ozan Eskişehir Osmangazi Üniversitesi, Bilgisayar ve Öğretim Teknolojileri Eğitimi Bölümü, ESKİŞEHİR Özet: eÖğrenme ve uzaktan eğitim uygulamalarının yaygınlaşmasıyla birlikte eğitim içeriği ve uygulamalarının elektronik ortamdaki yönetimi giderek önem kazanmıştır. Buna paralel olarak içerik ve uygulamaların nasıl yönetileceği tartışılmaya başlanmıştır. Eğitim öğretim süreçlerinin, içeriklerinin veya etkinliklerinin bir arada ya da ayrı ayrı yönetilebileceği pek çok farklı uygulama mevcuttur ancak bu bağlamda konuyla ilgili kavram kargaşası da süregelmektedir. Bu çalışmada, içerik yönetim sistemi (content management system-cms), öğrenme yönetim sistemi (learning management system-lms), ve öğrenme içerik yönetim sistemlerinin (learning content management system-lcms) kavramları irdelenecek ve bu bağlamda ulusal alan yazına katkı sağlanmaya çalışılacaktır. Giriş 1. İçerik Yönetim Sistemi Günümüz dünyasında, bilgi ve iletişim İçerik yönetim sistemleri (Content Management teknolojilerinin hızlı gelişimi ve özellikle Web Systems) günümüzde popüler olan ve çoğu 2.0 sürecinde içerik anlayışının ve öneminin zaman web sistemleri için kullanılan bir kavram artmasıyla, “İçerik Yönetimi” kavramı hemen olarak karşımıza çıkmaktadır. “İçerik” kavramı, hemen bütün alanlarda ihtiyaç duyulan ve Türk Dil Kurumunun Türkçe sözlüğünde bir tartışılan bir kavram haline gelmiştir. şeyin içinde bulunanların bütünü, muhtevası olarak tanımlanmaktadır[1]. -

Designing Online Communities: How Designers, Developers, Community Managers, and Software Structure Discourse and Knowledge Production on the Web
DESIGNING ONLINE COMMUNITIES: HOW DESIGNERS, DEVELOPERS, COMMUNITY MANAGERS, AND SOFTWARE STRUCTURE DISCOURSE AND KNOWLEDGE PRODUCTION ON THE WEB by Trevor J. Owens A Dissertation Submitted to the Graduate Faculty of George Mason University in Partial Fulfillment of The Requirements for the Degree of Doctor of Philosophy Education Committee: ___________________________________________ Chair ___________________________________________ ___________________________________________ ___________________________________________ Program Director ___________________________________________ Dean, College of Education and Human Development Date: _____________________________________ Spring Semester 2014 George Mason University Fairfax, VA Designing Online Communities: How Designers, Developers, Community Managers, and Software Structure Discourse and Knowledge Production on the Web A dissertation submitted in partial fulfillment of the requirements for the degree of Doctorate of Philosophy at George Mason University By Trevor Owens Bachelor of Arts University of Wisconsin-Madison, 2006 Master of Arts George Mason University, 2009 Director: Kimberly Sheridan College of Education and Human Development Spring Semester 2014 George Mason University Fairfax, VA ACKNOWLEDGEMENTS This dissertation represents the beginning of an end, the end of 23 years of school and education. Each of my committee members played a significant role in the design and development of the project. For the four years I worked at the Center for History and New Media Dan Cohen was both a great boss and a great mentor who helped me refine a lot of my ideas about online community in the practice of helping to grow the community of Zotero users. In his digital history course, I was also introduced too much of the new media studies work that shapes much of the framework of this study. Early in the doctoral program at George Mason University I reached out to Kim Sheridan about a study I wanted to do on the RPGmakerVX online community.