Oriented Spatial Box Plot, a New Pattern for Points Clusters Laurent
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-
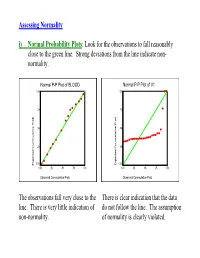
Assessing Normality I) Normal Probability Plots : Look for The
Assessing Normality i) Normal Probability Plots: Look for the observations to fall reasonably close to the green line. Strong deviations from the line indicate non- normality. Normal P-P Plot of BLOOD Normal P-P Plot of V1 1.00 1.00 .75 .75 .50 .50 .25 .25 0.00 0.00 Expected Cummulative Prob Expected Cummulative Expected Cummulative Prob Expected Cummulative 0.00 .25 .50 .75 1.00 0.00 .25 .50 .75 1.00 Observed Cummulative Prob Observed Cummulative Prob The observations fall very close to the There is clear indication that the data line. There is very little indication of do not follow the line. The assumption non-normality. of normality is clearly violated. ii) Histogram: Look for a “bell-shape”. Severe skewness and/or outliers are indications of non-normality. 5 16 14 4 12 10 3 8 2 6 4 1 Std. Dev = 60.29 Std. Dev = 992.11 2 Mean = 274.3 Mean = 573.1 0 N = 20.00 0 N = 25.00 150.0 200.0 250.0 300.0 350.0 0.0 1000.0 2000.0 3000.0 4000.0 175.0 225.0 275.0 325.0 375.0 500.0 1500.0 2500.0 3500.0 4500.0 BLOOD V1 Although the histogram is not perfectly There is a clear indication that the data symmetric and bell-shaped, there is no are right-skewed with some strong clear violation of normality. outliers. The assumption of normality is clearly violated. Caution: Histograms are not useful for small sample sizes as it is difficult to get a clear picture of the distribution. -

Recent Outlier Detection Methods with Illustrations Loss Reserving Context
Recent outlier detection methods with illustrations in loss reserving Benjamin Avanzi, Mark Lavender, Greg Taylor, Bernard Wong School of Risk and Actuarial Studies, UNSW Sydney Insights, 18 September 2017 Recent outlier detection methods with illustrations loss reserving Context Context Reserving Robustness and Outliers Robust Statistical Techniques Robustness criteria Heuristic Tools Robust M-estimation Outlier Detection Techniques Robust Reserving Overview Illustration - Robust Bivariate Chain Ladder Robust N-Dimensional Chain-Ladder Summary and Conclusions References 1/46 Recent outlier detection methods with illustrations loss reserving Context Reserving Context Reserving Robustness and Outliers Robust Statistical Techniques Robustness criteria Heuristic Tools Robust M-estimation Outlier Detection Techniques Robust Reserving Overview Illustration - Robust Bivariate Chain Ladder Robust N-Dimensional Chain-Ladder Summary and Conclusions References 1/46 Recent outlier detection methods with illustrations loss reserving Context Reserving The Reserving Problem i/j 1 2 ··· j ··· I 1 X1;1 X1;2 ··· X1;j ··· X1;J 2 X2;1 X2;2 ··· X2;j ··· . i Xi;1 Xi;2 ··· Xi;j . I XI ;1 Figure: Aggregate claims run-off triangle I Complete the square (or rectangle) I Also - multivariate extensions. 1/46 Recent outlier detection methods with illustrations loss reserving Context Reserving Common Reserving Techniques I Deterministic Chain-Ladder I Stochastic Chain-Ladder (Hachmeister and Stanard, 1975; England and Verrall, 2002) I Mack’s Model (Mack, 1993) I GLMs -

Boxplots for Grouped and Clustered Data in Toxicology
Penultimate version. If citing, please refer instead to the published version in Archives of Toxicology, DOI: 10.1007/s00204-015-1608-4. Boxplots for grouped and clustered data in toxicology Philip Pallmann1, Ludwig A. Hothorn2 1 Department of Mathematics and Statistics, Lancaster University, Lancaster LA1 4YF, UK, Tel.: +44 (0)1524 592318, [email protected] 2 Institute of Biostatistics, Leibniz University Hannover, 30419 Hannover, Germany Abstract The vast majority of toxicological papers summarize experimental data as bar charts of means with error bars. While these graphics are easy to generate, they often obscure essen- tial features of the data, such as outliers or subgroups of individuals reacting differently to a treatment. Especially raw values are of prime importance in toxicology, therefore we argue they should not be hidden in messy supplementary tables but rather unveiled in neat graphics in the results section. We propose jittered boxplots as a very compact yet comprehensive and intuitively accessible way of visualizing grouped and clustered data from toxicological studies together with individual raw values and indications of statistical significance. A web application to create these plots is available online. Graphics, statistics, R software, body weight, micronucleus assay 1 Introduction Preparing a graphical summary is usually the first if not the most important step in a data analysis procedure, and it can be challenging especially with many-faceted datasets as they occur frequently in toxicological studies. However, even in simple experimental setups many researchers have a hard time presenting their results in a suitable manner. Browsing recent volumes of this journal, we have realized that the least favorable ways of displaying toxicological data appear to be the most popular ones (according to the number of publications that use them). -

Download from the Resource and Environment Data Cloud Platform (
sustainability Article Quantitative Assessment for the Dynamics of the Main Ecosystem Services and their Interactions in the Northwestern Arid Area, China Tingting Kang 1,2, Shuai Yang 1,2, Jingyi Bu 1,2 , Jiahao Chen 1,2 and Yanchun Gao 1,* 1 Key Laboratory of Water Cycle and Related Land Surface Processes, Institute of Geographic Sciences and Natural Resources Research, Chinese Academy of Sciences, P.O. Box 9719, Beijing 100101, China; [email protected] (T.K.); [email protected] (S.Y.); [email protected] (J.B.); [email protected] (J.C.) 2 University of the Chinese Academy of Sciences, Beijing 100049, China * Correspondence: [email protected] Received: 21 November 2019; Accepted: 13 January 2020; Published: 21 January 2020 Abstract: Evaluating changes in the spatial–temporal patterns of ecosystem services (ESs) and their interrelationships provide an opportunity to understand the links among them, as well as to inform ecosystem-service-based decision making and governance. To research the development trajectory of ecosystem services over time and space in the northwestern arid area of China, three main ecosystem services (carbon sequestration, soil retention, and sand fixation) and their relationships were analyzed using Pearson’s coefficient and a time-lagged cross-correlation analysis based on the mountain–oasis–desert zonal scale. The results of this study were as follows: (1) The carbon sequestration of most subregions improved, and that of the oasis continuously increased from 1990 to 2015. Sand fixation decreased in the whole region except for in the Alxa Plateau–Hexi Corridor area, which experienced an “increase–decrease” trend before 2000 and after 2000; (2) the synergies and trade-off relationships of the ES pairs varied with time and space, but carbon sequestration and soil retention in the most arid area had a synergistic relationship, and most oases retained their synergies between carbon sequestration and sand fixation over time. -

Of Typicality and Predictive Distributions in Discriminant Function Analysis Lyle W
Wayne State University Human Biology Open Access Pre-Prints WSU Press 8-22-2018 Of Typicality and Predictive Distributions in Discriminant Function Analysis Lyle W. Konigsberg Department of Anthropology, University of Illinois at Urbana–Champaign, [email protected] Susan R. Frankenberg Department of Anthropology, University of Illinois at Urbana–Champaign Recommended Citation Konigsberg, Lyle W. and Frankenberg, Susan R., "Of Typicality and Predictive Distributions in Discriminant Function Analysis" (2018). Human Biology Open Access Pre-Prints. 130. https://digitalcommons.wayne.edu/humbiol_preprints/130 This Open Access Article is brought to you for free and open access by the WSU Press at DigitalCommons@WayneState. It has been accepted for inclusion in Human Biology Open Access Pre-Prints by an authorized administrator of DigitalCommons@WayneState. Of Typicality and Predictive Distributions in Discriminant Function Analysis Lyle W. Konigsberg1* and Susan R. Frankenberg1 1Department of Anthropology, University of Illinois at Urbana–Champaign, Urbana, Illinois, USA. *Correspondence to: Lyle W. Konigsberg, Department of Anthropology, University of Illinois at Urbana–Champaign, 607 S. Mathews Ave, Urbana, IL 61801 USA. E-mail: [email protected]. Short Title: Typicality and Predictive Distributions in Discriminant Functions KEY WORDS: ADMIXTURE, POSTERIOR PROBABILITY, BAYESIAN ANALYSIS, OUTLIERS, TUKEY DEPTH Pre-print version. Visit http://digitalcommons.wayne.edu/humbiol/ after publication to acquire the final version. Abstract While discriminant function analysis is an inherently Bayesian method, researchers attempting to estimate ancestry in human skeletal samples often follow discriminant function analysis with the calculation of frequentist-based typicalities for assigning group membership. Such an approach is problematic in that it fails to account for admixture and for variation in why individuals may be classified as outliers, or non-members of particular groups. -

Length of Stay Outlier Detection Through Cluster Analysis: a Case Study in Pediatrics Daniel Gartnera, Rema Padmanb
Length of Stay Outlier Detection through Cluster Analysis: A Case Study in Pediatrics Daniel Gartnera, Rema Padmanb aSchool of Mathematics, Cardiff University, United Kingdom bThe H. John Heinz III College, Carnegie Mellon University, Pittsburgh, USA Abstract The increasing availability of detailed inpatient data is enabling the develop- ment of data-driven approaches to provide novel insights for the management of Length of Stay (LOS), an important quality metric in hospitals. This study examines clustering of inpatients using clinical and demographic attributes to identify LOS outliers and investigates the opportunity to reduce their LOS by comparing their order sequences with similar non-outliers in the same cluster. Learning from retrospective data on 353 pediatric inpatients admit- ted for appendectomy, we develop a two-stage procedure that first identifies a typical cluster with LOS outliers. Our second stage analysis compares orders pairwise to determine candidates for switching to make LOS outliers simi- lar to non-outliers. Results indicate that switching orders in homogeneous inpatient sub-populations within the limits of clinical guidelines may be a promising decision support strategy for LOS management. Keywords: Machine Learning; Clustering; Health Care; Length of Stay Email addresses: [email protected] (Daniel Gartner), [email protected] (Rema Padman) 1. Introduction Length of Stay (LOS) is an important quality metric in hospitals that has been studied for decades Kim and Soeken (2005); Tu et al. (1995). However, the increasing digitization of healthcare with Electronic Health Records and other clinical information systems is enabling the collection and analysis of vast amounts of data using advanced data-driven methods that may be par- ticularly valuable for LOS management Gartner (2015); Saria et al. -

Rainbow Plots, Bagplots and Boxplots for Functional Data
Rainbow plots, bagplots and boxplots for functional data Rob J Hyndman and Han Lin Shang Department of Econometrics and Business Statistics, Monash University, Clayton, Australia June 5, 2009 Abstract We propose new tools for visualizing large amounts of functional data in the form of smooth curves. The proposed tools include functional versions of the bagplot and boxplot, and make use of the first two robust principal component scores, Tukey's data depth and highest density regions. By-products of our graphical displays are outlier detection methods for functional data. We compare these new outlier detection methods with existing methods for detecting outliers in functional data, and show that our methods are better able to identify the outliers. An R-package containing computer code and data sets is available in the online supple- ments. Keywords: Highest density regions, Robust principal component analysis, Kernel density estima- tion, Outlier detection, Tukey's halfspace depth. 1 Introduction Functional data are becoming increasingly common in a wide range of fields, and there is a need to develop new statistical tools for analyzing such data. In this paper, we are interested in visualizing data comprising smooth curves (e.g., Ramsay & Silverman, 2005; Locantore et al., 1999). Such functional data may be age-specific mortality or fertility rates (Hyndman & Ullah, 2007), term- structured yield curves (Kargin & Onatski, 2008), spectrometry data (Reiss & Ogden, 2007), or one of the many applications described by Ramsay & Silverman (2002). Ramsay & Silverman (2005) and Ferraty & Vieu (2006) provide detailed surveys of the many parametric and nonparametric techniques for analyzing functional data. 1 Visualization methods help in the discovery of characteristics that might not have been ap- parent using mathematical models and summary statistics; and yet this area of research has not received much attention in the functional data analysis literature to date. -

Non-Parametric Vs. Parametric Tests in SAS® Venita Depuy and Paul A
NESUG 17 Analysis Perusing, Choosing, and Not Mis-using: ® Non-parametric vs. Parametric Tests in SAS Venita DePuy and Paul A. Pappas, Duke Clinical Research Institute, Durham, NC ABSTRACT spread is less easy to quantify but is often represented by Most commonly used statistical procedures, such as the t- the interquartile range, which is simply the difference test, are based on the assumption of normality. The field between the first and third quartiles. of non-parametric statistics provides equivalent procedures that do not require normality, but often require DETERMINING NORMALITY assumptions such as equal variances. Parametric tests (OR LACK THEREOF) (which assume normality) are often used on non-normal One of the first steps in test selection should be data; even non-parametric tests are used when their investigating the distribution of the data. PROC assumptions are violated. This paper will provide an UNIVARIATE can be implemented to help determine overview of parametric tests and their non-parametric whether or not your data are normal. This procedure equivalents; what assumptions are required for each test; ® generates a variety of summary statistics, such as the how to perform the tests in SAS ; and guidelines for when mean and median, as well as numerical representations of both sets of assumptions are violated. properties such as skewness and kurtosis. Procedures covered will include PROCs ANOVA, CORR, If the population from which the data are obtained is NPAR1WAY, TTEST and UNIVARIATE. Discussion will normal, the mean and median should be equal or close to include assumptions and assumption violations, equal. The skewness coefficient, which is a measure of robustness, and exact versus approximate tests. -

Understanding and Comparing Distributions
Understanding and Comparing Distributions Chapter 4 Objectives: • Boxplot • Calculate Outliers • Comparing Distributions • Timeplot The Big Picture • We can answer much more interesting questions about variables when we compare distributions for different groups. • Below is a histogram of the Average Wind Speed for every day in 1989. The Big Picture (cont.) • The distribution is unimodal and skewed to the right. • The high value may be an outlier Comparing distributions can be much more interesting than just describing a single distribution. The Five-Number Summary • The five-number summary of a distribution reports its Max 8.67 median, quartiles, and Q3 2.93 extremes (maximum and minimum). Median 1.90 • Example: The five-number Q1 1.15 summary for for the daily Min 0.20 wind speed is: The Five-Number Summary • Consists of the minimum value, Q1, the median, Q3, and the maximum value, listed in that order. • Offers a reasonably complete description of the center and spread. • Calculate on the TI-83/84 using 1-Var Stats. • Used to construct the Boxplot. • Example: Five-Number Summary • 1: 20, 27, 34, 50, 86 • 2: 5, 10, 18.5, 29, 33 Daily Wind Speed: Making Boxplots • A boxplot is a graphical display of the five- number summary. • Boxplots are useful when comparing groups. • Boxplots are particularly good at pointing out outliers. Boxplot • A graph of the Five-Number Summary. • Can be drawn either horizontally or vertically. • The box represents the IQR (middle 50%) of the data. • Show less detail than histograms or stemplots, they are best used for side-by-side comparison of more than one distribution. -

Notes Unit 8: Interquartile Range, Box Plots, and Outliers I
Notes Unit 8: Interquartile Range, Box Plots, and Outliers I. Box Plot A. What is it? • Also called a ‘Box and Whiskers’ plot • A 5-numbered summary of data: • Lower extreme • Lower quartile • Median • Upper quartile • Upper extreme • To draw a Box Plot, we need to find all 5 of these numbers B. Steps to Creating a Box Plot 1. Order the numbers smallest to largest 2. Find the 5 numbers- median, lower and upper extremes, lower and upper quartiles 3 Draw the box plot- draw a number line, draw and label the parts C. Examples Example 1: 12, 13, 5, 8, 9, 20, 16, 14, 14, 6, 9, 12, 12 Step 1: Order the numbers from smallest to largest 5, 6, 8, 9, 9, 12, 12, 12, 13, 14, 14, 16, 20 Step 2 – Find the Median 5, 6, 8, 9, 9, 12, 12, 12, 13, 14, 14, 16, 20 Median: 12 2. Find the median. The median is the middle number. If the data has two middle numbers, find the mean of the two numbers. What is the median? Step 2 – Find the Lower and Upper Extremes 5, 6, 8, 9, 9, 12, 12, 12, 13, 14, 14, 16, 20 Median: 12 5 20 2. Find the smallest and largest numbers Step 2 – Upper & Lower Quartiles 5, 6, 8, 9, 9, 12, 12, 12, 13, 14, 14, 16, 20 Median: 5 lower 12 upper 20 quartile: quartile: 8.5 14 3. Find the lower and upper medians or quartiles. These are the middle numbers on each side of the median. -

5. Drawing Graphs
5. Drawing graphs Above all else show the data. –Edward Tufte1 Visualising data is one of the most important tasks facing the data analyst. It’s important for two distinct but closely related reasons. Firstly, there’s the matter of drawing “presentation graphics”, displaying your data in a clean, visually appealing fashion makes it easier for your reader to understand what you’re trying to tell them. Equally important, perhaps even more important, is the fact that drawing graphs helps you to understand the data. To that end, it’s important to draw “exploratory graphics” that help you learn about the data as you go about analysing it. These points might seem pretty obvious but I cannot count the number of times I’ve seen people forget them. To give a sense of the importance of this chapter, I want to start with a classic illustration of just how powerful a good graph can be. To that end, Figure 5.1 shows a redrawing of one of the most famous data visualisations of all time. This is John Snow’s 1854 map of cholera deaths. The map is elegant in its simplicity. In the background we have a street map which helps orient the viewer. Over the top we see a large number of small dots, each one representing the location of a cholera case. The larger symbols show the location of water pumps, labelled by name. Even the most casual inspection of the graph makes it very clear that the source of the outbreak is almost certainly the Broad Street pump. -

Detection of Outliers in Pollutant Emissions from the Soto De Ribera Coal-Fired Plant Using Functional Data Analysis: a Case Study in Northern Spain †
Proceedings Detection of Outliers in Pollutant Emissions from the Soto de Ribera Coal-Fired Plant Using Functional Data Analysis: A Case Study in Northern Spain † Fernando Sánchez Lasheras 1,*, Celestino Ordóñez Galán 2, Paulino José García Nieto 1 and Esperanza García-Gonzalo 1 1 Department of Mathematics, University of Oviedo, 33007 Oviedo, Spain; [email protected] (P.J.G.N.), [email protected] (E.G.-G.) 2 Department of Prospection and Mining Exploitation, University of Oviedo, 3004 Oviedo, Spain; [email protected] * Correspondence: [email protected]; Tel.: +34-985-10-3338 † Presented at the 2nd International Research Conference on Sustainable Energy, Engineering, Materials and Environment (IRCSEEME), Mieres, Spain, 25–27 July 2018. Published: 5 November 2018 Abstract: The present research uses two different functional data analysis methods called functional high-density region (HDR) boxplot and functional bagplot. Both methodologies were applied for the outlier detection in the time pollutant emissions curves that were built using as inputs the discrete information available from an air quality monitoring data record station. Although the record of pollutant emissions is made in a discrete way, these methodologies consider pollutant emissions over time as curves, with outliers obtained by a comparison of curves instead of vectors. Then the concept of outlier passes from been a point to a curve that employed the functional depth as the indicator of curve distances. In this study, the referred methodologies are applied to the detection of outliers in pollutant emissions from the Soto de Ribera coal-fired plant which is in the nearby of the city of Oviedo, located in the Principality of Asturias, Spain.