Genetic Engineering and Synthetic Genomics in Yeast to Understand Life and Boost Biotechnology
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

The Transcriptional Landscape of a Rewritten Bacterial Genome Reveals Control Elements and Genome Design Principles ✉ ✉ Mariëlle J
ARTICLE https://doi.org/10.1038/s41467-021-23362-y OPEN The transcriptional landscape of a rewritten bacterial genome reveals control elements and genome design principles ✉ ✉ Mariëlle J. F. M. van Kooten 1 , Clio A. Scheidegger1, Matthias Christen1 & Beat Christen 1 Sequence rewriting enables low-cost genome synthesis and the design of biological systems with orthogonal genetic codes. The error-free, robust rewriting of nucleotide sequences can 1234567890():,; be achieved with a complete annotation of gene regulatory elements. Here, we compare transcription in Caulobacter crescentus to transcription from plasmid-borne segments of the synthesized genome of C. ethensis 2.0. This rewritten derivative contains an extensive amount of supposedly neutral mutations, including 123’562 synonymous codon changes. The tran- scriptional landscape refines 60 promoter annotations, exposes 18 termination elements and links extensive transcription throughout the synthesized genome to the unintentional intro- duction of sigma factor binding motifs. We reveal translational regulation for 20 CDS and uncover an essential translational regulatory element for the expression of ribosomal protein RplS. The annotation of gene regulatory elements allowed us to formulate design principles that improve design schemes for synthesized DNA, en route to a bright future of iteration- free programming of biological systems. 1 Institute of Molecular Systems Biology, Department of Biology, Eidgenössische Technische Hochschule Zürich, Zürich, Switzerland. ✉ email: [email protected]; [email protected] NATURE COMMUNICATIONS | (2021) 12:3053 | https://doi.org/10.1038/s41467-021-23362-y | www.nature.com/naturecommunications 1 ARTICLE NATURE COMMUNICATIONS | https://doi.org/10.1038/s41467-021-23362-y e can program biological systems with DNA that is In previous work, we synthesized and assembled the rewritten Wbased on native nucleotide sequences. -

Cambridge's 92 Nobel Prize Winners Part 2 - 1951 to 1974: from Crick and Watson to Dorothy Hodgkin
Cambridge's 92 Nobel Prize winners part 2 - 1951 to 1974: from Crick and Watson to Dorothy Hodgkin By Cambridge News | Posted: January 18, 2016 By Adam Care The News has been rounding up all of Cambridge's 92 Nobel Laureates, celebrating over 100 years of scientific and social innovation. ADVERTISING In this installment we move from 1951 to 1974, a period which saw a host of dramatic breakthroughs, in biology, atomic science, the discovery of pulsars and theories of global trade. It's also a period which saw The Eagle pub come to national prominence and the appearance of the first female name in Cambridge University's long Nobel history. The Gender Pay Gap Sale! Shop Online to get 13.9% off From 8 - 11 March, get 13.9% off 1,000s of items, it highlights the pay gap between men & women in the UK. Shop the Gender Pay Gap Sale – now. Promoted by Oxfam 1. 1951 Ernest Walton, Trinity College: Nobel Prize in Physics, for using accelerated particles to study atomic nuclei 2. 1951 John Cockcroft, St John's / Churchill Colleges: Nobel Prize in Physics, for using accelerated particles to study atomic nuclei Walton and Cockcroft shared the 1951 physics prize after they famously 'split the atom' in Cambridge 1932, ushering in the nuclear age with their particle accelerator, the Cockcroft-Walton generator. In later years Walton returned to his native Ireland, as a fellow of Trinity College Dublin, while in 1951 Cockcroft became the first master of Churchill College, where he died 16 years later. 3. 1952 Archer Martin, Peterhouse: Nobel Prize in Chemistry, for developing partition chromatography 4. -

Peptide Chemistry up to Its Present State
Appendix In this Appendix biographical sketches are compiled of many scientists who have made notable contributions to the development of peptide chemistry up to its present state. We have tried to consider names mainly connected with important events during the earlier periods of peptide history, but could not include all authors mentioned in the text of this book. This is particularly true for the more recent decades when the number of peptide chemists and biologists increased to such an extent that their enumeration would have gone beyond the scope of this Appendix. 250 Appendix Plate 8. Emil Abderhalden (1877-1950), Photo Plate 9. S. Akabori Leopoldina, Halle J Plate 10. Ernst Bayer Plate 11. Karel Blaha (1926-1988) Appendix 251 Plate 12. Max Brenner Plate 13. Hans Brockmann (1903-1988) Plate 14. Victor Bruckner (1900- 1980) Plate 15. Pehr V. Edman (1916- 1977) 252 Appendix Plate 16. Lyman C. Craig (1906-1974) Plate 17. Vittorio Erspamer Plate 18. Joseph S. Fruton, Biochemist and Historian Appendix 253 Plate 19. Rolf Geiger (1923-1988) Plate 20. Wolfgang Konig Plate 21. Dorothy Hodgkins Plate. 22. Franz Hofmeister (1850-1922), (Fischer, biograph. Lexikon) 254 Appendix Plate 23. The picture shows the late Professor 1.E. Jorpes (r.j and Professor V. Mutt during their favorite pastime in the archipelago on the Baltic near Stockholm Plate 24. Ephraim Katchalski (Katzir) Plate 25. Abraham Patchornik Appendix 255 Plate 26. P.G. Katsoyannis Plate 27. George W. Kenner (1922-1978) Plate 28. Edger Lederer (1908- 1988) Plate 29. Hennann Leuchs (1879-1945) 256 Appendix Plate 30. Choh Hao Li (1913-1987) Plate 31. -

Horizontal Gene Flow Into Geobacillus Is Constrained by the Chromosomal Organization of Growth and Sporulation
bioRxiv preprint doi: https://doi.org/10.1101/381442; this version posted August 2, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Horizontal gene flow into Geobacillus is constrained by the chromosomal organization of growth and sporulation Alexander Esin1,2, Tom Ellis3,4, Tobias Warnecke1,2* 1Molecular Systems Group, Medical Research Council London Institute of Medical Sciences, London, United Kingdom 2Institute of Clinical Sciences, Faculty of Medicine, Imperial College London, London, United Kingdom 3Imperial College Centre for Synthetic Biology, Imperial College London, London, United Kingdom 4Department of Bioengineering, Imperial College London, London, United Kingdom *corresponding author ([email protected]) 1 bioRxiv preprint doi: https://doi.org/10.1101/381442; this version posted August 2, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Abstract Horizontal gene transfer (HGT) in bacteria occurs in the context of adaptive genome architecture. As a consequence, some chromosomal neighbourhoods are likely more permissive to HGT than others. Here, we investigate the chromosomal topology of horizontal gene flow into a clade of Bacillaceae that includes Geobacillus spp. Reconstructing HGT patterns using a phylogenetic approach coupled to model-based reconciliation, we discover three large contiguous chromosomal zones of HGT enrichment. -

Section 4. Guidance Document on Horizontal Gene Transfer Between Bacteria
306 - PART 2. DOCUMENTS ON MICRO-ORGANISMS Section 4. Guidance document on horizontal gene transfer between bacteria 1. Introduction Horizontal gene transfer (HGT) 1 refers to the stable transfer of genetic material from one organism to another without reproduction. The significance of horizontal gene transfer was first recognised when evidence was found for ‘infectious heredity’ of multiple antibiotic resistance to pathogens (Watanabe, 1963). The assumed importance of HGT has changed several times (Doolittle et al., 2003) but there is general agreement now that HGT is a major, if not the dominant, force in bacterial evolution. Massive gene exchanges in completely sequenced genomes were discovered by deviant composition, anomalous phylogenetic distribution, great similarity of genes from distantly related species, and incongruent phylogenetic trees (Ochman et al., 2000; Koonin et al., 2001; Jain et al., 2002; Doolittle et al., 2003; Kurland et al., 2003; Philippe and Douady, 2003). There is also much evidence now for HGT by mobile genetic elements (MGEs) being an ongoing process that plays a primary role in the ecological adaptation of prokaryotes. Well documented is the example of the dissemination of antibiotic resistance genes by HGT that allowed bacterial populations to rapidly adapt to a strong selective pressure by agronomically and medically used antibiotics (Tschäpe, 1994; Witte, 1998; Mazel and Davies, 1999). MGEs shape bacterial genomes, promote intra-species variability and distribute genes between distantly related bacterial genera. Horizontal gene transfer (HGT) between bacteria is driven by three major processes: transformation (the uptake of free DNA), transduction (gene transfer mediated by bacteriophages) and conjugation (gene transfer by means of plasmids or conjugative and integrated elements). -

Nobel Lectures™ 2001-2005
World Scientific Connecting Great Minds 逾10 0 种 诺贝尔奖得主著作 及 诺贝尔奖相关图书 我们非常荣幸得以出版超过100种诺贝尔奖得主著作 以及诺贝尔奖相关图书。 我们自1980年代开始与诺贝尔奖得主合作出版高品质 畅销书。一些得主担任我们的编辑顾问、丛书编辑, 并于我们期刊发表综述文章与学术论文。 世界科技与帝国理工学院出版社还邀得其中多位作了公 开演讲。 Philip W Anderson Sir Derek H R Barton Aage Niels Bohr Subrahmanyan Chandrasekhar Murray Gell-Mann Georges Charpak Nicolaas Bloembergen Baruch S Blumberg Hans A Bethe Aaron J Ciechanover Claude Steven Chu Cohen-Tannoudji Leon N Cooper Pierre-Gilles de Gennes Niels K Jerne Richard Feynman Kenichi Fukui Lawrence R Klein Herbert Kroemer Vitaly L Ginzburg David Gross H Gobind Khorana Rita Levi-Montalcini Harry M Markowitz Karl Alex Müller Sir Nevill F Mott Ben Roy Mottelson 诺贝尔奖相关图书 THE PERIODIC TABLE AND A MISSED NOBEL PRIZES THAT CHANGED MEDICINE NOBEL PRIZE edited by Gilbert Thompson (Imperial College London) by Ulf Lagerkvist & edited by Erling Norrby (The Royal Swedish Academy of Sciences) This book brings together in one volume fifteen Nobel Prize- winning discoveries that have had the greatest impact upon medical science and the practice of medicine during the 20th “This is a fascinating account of how century and up to the present time. Its overall aim is to groundbreaking scientists think and enlighten, entertain and stimulate. work. This is the insider’s view of the process and demands made on the Contents: The Discovery of Insulin (Robert Tattersall) • The experts of the Nobel Foundation who Discovery of the Cure for Pernicious Anaemia, Vitamin B12 assess the originality and significance (A Victor Hoffbrand) • The Discovery of -
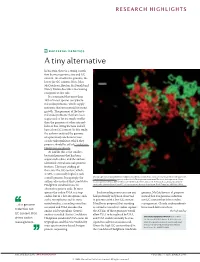
Bacterial Genetics a Tiny Alternative
RESEARCH HIGHLIGHTS BACTERIAL GENETICS A tiny alternative In bacteria, there is a strong correla- tion between genome size and GC content: the smaller the genome, the lower the GC content. Now, John McCutcheon, Bradon McDonald and Nancy Moran describe a fascinating exception to this rule. It is estimated that more than 10% of insect species carry bacte- rial endosymbionts, which supply nutrients that are essential for insect growth. The genomes of the bacte- rial endosymbionts that have been sequenced so far are much smaller than the genomes of other intracel- lular or free-living bacteria and all have a low GC content. In this study, the authors analysed the genome of a previously uncharacterized cicada endosymbiont, which they propose should be called Candidatus Hodgkinia cicadicola. At 144 kb, this is the smallest bacterial genome that has been sequenced to date, and the authors identified several unusual genomic features. The most striking of these was the GC content, which, at 58%, is unusually high for such Micrograph showing Candidatus Hodgkinia cicadicola (red) in close association with another endosymbiont, a small genome. Intriguingly, the Candidatus Sulcia muelleri (green) in the cicada Diceroprocta semicincta. The scale bar represents 10 µm. authors also noticed that Candidatus Image reproduced from McCutcheon, J. P., McDonald, B. R. & Moran, N. P. Origin of an alternative genetic Hodgkinia cicadicola uses an code in the extremely small and GC-rich genome of a bacterial symbiont. PLoS Genet. 5, e1000565 (2009). alternative genetic code. In most species the codon UGA is a stop Such recoding events are rare and genome, McCutcheon et al. -

Synthetic Biology Projects in Vitro
Downloaded from genome.cshlp.org on September 25, 2021 - Published by Cold Spring Harbor Laboratory Press Review Synthetic biology projects in vitro Anthony C. Forster1,3 and George M. Church2,3 1Department of Pharmacology and Vanderbilt Institute of Chemical Biology, Vanderbilt University Medical Center, Nashville, Tennessee 37232, USA; 2Department of Genetics, Harvard Medical School, Boston, Massachusetts 02115, USA Advances in the in vitro synthesis and evolution of DNA, RNA, and polypeptides are accelerating the construction of biopolymers, pathways, and organisms with novel functions. Known functions are being integrated and debugged with the aim of synthesizing life-like systems. The goals are knowledge, tools, smart materials, and therapies. Synthetic biology projects (SBPs) an action plan to regulate world suppliers of DNA synthesizers, DNA precursors, and oligos (Church 2004). Ethical and safety The basic elements of chemistry and biology are few, but the issues have been, and must continue to be, regulated (Cho et al. synthetic combinations are unlimited and awe inspiring. The 1999). first international conference on synthetic biology charted its Several groups have proposed to create bacteria with chro- goals as understanding and utilizing life’s diverse solutions to mosomes synthesized entirely from synthetic oligos. This might process information, materials, and energy (Silver and Way 2004) be done stepwise (Posfai et al. 2006) or by inactivating the en- (http://syntheticbiology.org). As a bonus, genetic systems are dogenous bacterial chromosome and then somehow transform- biocompatible, renewable, and can be optimized by Darwinian ing and rebooting the bacterium with an entire in vitro- selections. SBPs entail the complex manipulation of replicating synthesized genome. -

Assessment of the Bimodality in the Distribution of Bacterial Genome Sizes
The ISME Journal (2017) 11, 821–824 © 2017 International Society for Microbial Ecology All rights reserved 1751-7362/17 www.nature.com/ismej SHORT COMMUNICATION Assessment of the bimodality in the distribution of bacterial genome sizes Hyun S Gweon, Mark J Bailey and Daniel S Read Centre for Ecology & Hydrology, Wallingford, UK Bacterial genome sizes have previously been shown to exhibit a bimodal distribution. This phenomenon has prompted discussion regarding the evolutionary forces driving genome size in bacteria and its ecological significance. We investigated the level of inherent redundancy in the public database and the effect it has on the shape of the apparent bimodal distribution. Our study reveals that there is a significant bias in the genome sequencing efforts towards a certain group of species, and that correcting the bias using species nomenclature and clustering of the 16S rRNA gene, results in a unimodal rather than the previously published bimodal distribution. The true genome size distribution and its wider ecological implications will soon emerge as we are currently witnessing rapid growth in the number of sequenced genomes from diverse environmental niches across a range of habitats at an unprecedented rate. The ISME Journal (2017) 11, 821–824; doi:10.1038/ismej.2016.142; published online 11 November 2016 Significant progress has been made in understanding Wolf in 2008, where it was reported that bacterial interactions between ecology and genome evolution genome sizes show a bimodal distribution (Koonin in prokaryotes. -

Cover June 2011
z NOBEL LAUREATES IN Qui DNA RESEARCH n u SANGRAM KESHARI LENKA & CHINMOYEE MAHARANA F 1. Who got the Nobel Prize in Physiology or Medicine 1933) for discovering the famous concept that says chromosomes carry genes? a. Gregor Johann Mendel b. Thomas Hunt Morgan c. Aristotle d. Charles Darwin 5. Name the Nobel laureate (1959) for his discovery of the mechanisms in the biological 2. The concept of Mutations synthesis of ribonucleic acid and are changes in genetic deoxyribonucleic acid? information” awarded him a. Arthur Kornberg b. Har Gobind Khorana the Nobel Prize in 1946: c. Roger D. Kornberg d. James D. Watson a. Hermann Muller b. M.F. Perutz c. James D. Watson 6. Discovery of the DNA double helix fetched them d. Har Gobind Khorana the Nobel Prize in Physiology or Medicine (1962). a. Francis Crick, James Watson, Rosalind Elsie Franklin b. Francis Crick, James Watson and Maurice Willkins c. James Watson, Maurice Willkins, Rosalind Elsie Franklin 3. Identify the discoverer and d. Maurice Willkins, Rosalind Elsie Franklin and Francis Crick Nobel laureate of 1958 who found DNA in bacteria and viruses. a. Louis Pasteur b. Alexander Fleming c. Joshua Lederberg d. Roger D. Kornberg 4. A direct link between genes and enzymatic reactions, known as the famous “one gene, one enzyme” hypothesis, was put forth by these 7. They developed the theory of genetic regulatory scientists who shared the Nobel Prize in mechanisms, showing how, on a molecular level, Physiology or Medicine, 1958. certain genes are activated and suppressed. Name a. George Wells Beadle and Edward Lawrie Tatum these famous Nobel laureates of 1965. -

Notes and News
Notes and News Sir Aaron Klug, NL, The Discoverer of his Ph.D. degree in Physics in 1953 from the Trinity Crystallographic Electron Microscopy, College, Cambridge. Passes Away In late 1953, he moved to the Birkbeck College, University of London where he started collaborating with ubbed ‘one of the mildest, most broad-minded and the X-ray crystallographer Rosalind Franklin on her studies Dmost cultured of scientists’, Aaron Klug, who was on tobacco mosaic virus. The combined commendable awarded the Nobel Prize in Chemistry in 1982 for “his technical skill of Franklin in producing X-ray diffraction development of crystallographic electron microscopy and images and deep theoretical understanding of matter by his structural elucidation of biologically important nucleic Klug led to the determination of the general outline of the acid-protein complexes,” died on November 20, 2018 at structure of this virus just before the untimely demise of the age of 92 years. Franklin from cancer in 1958. Klug always acknowledged Klug was born on 11th August, 1926 in •elva, the help that he received from Rosalind in this domain of Lithuania to Jewish parents Lazar Klug, a cattleman, and research. Bella (née Silin) Klug. His family moved to South Africa In 1962, Klug joined the newly founded MRC when he was two years old. He had his early education in Laboratory of Molecular Biology (LMB) in Cambridge Durban High School. He received his B.Sc. degree with a where he used X-ray diffraction methods, microscopy and first class Honours from the University of the structural modelling to develop ‘crystallographic electron Witwaterstrand and his M.Sc. -

PA00XCSB.Pdf
Leidos Proprietary 1. EXECUTIVE SUMMARY A summary of efforts for the planned, ongoing, and completed projects for the Malaria Vaccine Development Program (MVDP) contract for this reporting period are herein detailed. A compiled Gantt chart including activities associated with each of the projects has been created and included as an attachment to this report. Ongoing projects that will continue through FY2019 include two vaccine development projects, the CSP vaccine development project (CSP Vaccine) and liver stage vaccine development project (Liver Stage Vaccine), as well as the clinical study with RH5 (RH5.1 Clinical Study), the latter to assess long-term immunogenicity in RH5.1/AS01 vaccinees. Of note is that while both the CSP and the liver stage vaccine development projects were initiated as epitope-based projects, these have since been realigned to target whole proteins; therefore, the project names have also been realigned to remove “epitope-based.” Expansion of work on the RCR complex into a vaccine development project (RCR Complex) occurred in early FY2019 and this project will continue until the end date of the contract. Lastly, a new project, the RH5.1 human monoclonal antibody identification and development project (RH5.1 Human mAb), was initiated in early FY2019 and will continue until the end date of the contract. Two projects were completed in FY2019, the blood stage epitope-based vaccine development project and the PD1 blockade inhibitor project (PD1 Block Inh). Leidos continues to seek collaborators for information exchange under NDA, reagent exchange under MTA, and collaboration under CRADA, to expand our body of knowledge and access to reagents with minimal cost to the program.