Epididymal V-Atpase-Rich Cell Proteome Database
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
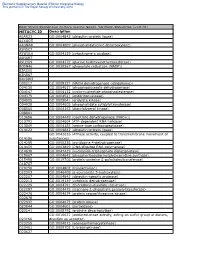
METACYC ID Description A0AR23 GO:0004842 (Ubiquitin-Protein Ligase
Electronic Supplementary Material (ESI) for Integrative Biology This journal is © The Royal Society of Chemistry 2012 Heat Stress Responsive Zostera marina Genes, Southern Population (α=0. -

要約) Doctoral Dissertation Antibiotics Shapes Population-Level Diversity In
) Doctoral Dissertation Antibiotics shapes population-level diversity in the human gut microbiome ( ) Nishijima Suguru Acknowledgments I would like to express my sincere gratitude to my supervisor, Prof. Masahira Hattori, whose expertise, knowledge and continuous encouragement throughout my research. My sincere thanks also go to Assoc. Prof. Kenshiro Oshima (The University of Tokyo), Dr. Wataru Suda and Dr. Seok-Won Kim for their motivation, immense support and encouragement throughout my work. I am also grateful to all my collaborators, Prof. Hidetoshi Morita (Okayama University) for his fecal sample collection, DNA isolation and sincere encouragement, Prof. Kenya Honda and Dr. Koji Atarashi (Keio University) for mice experiments, Assoc. Prof. Masahiro Umezaki (the University of Tokyo) for support for dietary data analysis, Dr. Todd D. Taylor (RIKEN) for support for writing manuscript and Dr. Yuu Hirose (Toyohashi University of technology) for DNA sequencing. I also would like to thank all past and present members of our laboratory, Erica Iioka, Misa Takagi, Emi Omori, Hiromi Kuroyamagi, Naoko Yamashita, Keiko Komiya, Rina Kurokawa, Chie Shindo, Yukiko Takayama and Yasue Hattori for their great technical support and kind assistance. i Antibiotics shapes population-level diversity in the human gut microbiome () Abstract The human gut microbiome has profound influences on the host’s physiology through its interference with various intestinal functions. The development of next-generation sequencing (NGS) technologies enabled us to comprehensively explore ecological and functional features of the gut microbiomes. Recent studies using the NGS-based metagenomic approaches have suggested high ecological diversity of the microbiome across countries. However, little is known about the structure and feature of the Japanese gut microbiome, and the factor that shapes the population-level diversity in the human gut microbiome. -

A Yeast Phenomic Model for the Gene Interaction Network Modulating
Louie et al. Genome Medicine 2012, 4:103 http://genomemedicine.com/content/4/12/103 RESEARCH Open Access A yeast phenomic model for the gene interaction network modulating CFTR-ΔF508 protein biogenesis Raymond J Louie3†, Jingyu Guo1,2†, John W Rodgers1, Rick White4, Najaf A Shah1, Silvere Pagant3, Peter Kim3, Michael Livstone5, Kara Dolinski5, Brett A McKinney6, Jeong Hong2, Eric J Sorscher2, Jennifer Bryan4, Elizabeth A Miller3* and John L Hartman IV1,2* Abstract Background: The overall influence of gene interaction in human disease is unknown. In cystic fibrosis (CF) a single allele of the cystic fibrosis transmembrane conductance regulator (CFTR-ΔF508) accounts for most of the disease. In cell models, CFTR-ΔF508 exhibits defective protein biogenesis and degradation rather than proper trafficking to the plasma membrane where CFTR normally functions. Numerous genes function in the biogenesis of CFTR and influence the fate of CFTR-ΔF508. However it is not known whether genetic variation in such genes contributes to disease severity in patients. Nor is there an easy way to study how numerous gene interactions involving CFTR-ΔF would manifest phenotypically. Methods: To gain insight into the function and evolutionary conservation of a gene interaction network that regulates biogenesis of a misfolded ABC transporter, we employed yeast genetics to develop a ‘phenomic’ model, in which the CFTR-ΔF508-equivalent residue of a yeast homolog is mutated (Yor1-ΔF670), and where the genome is scanned quantitatively for interaction. We first confirmed that Yor1-ΔF undergoes protein misfolding and has reduced half-life, analogous to CFTR-ΔF. Gene interaction was then assessed quantitatively by growth curves for approximately 5,000 double mutants, based on alteration in the dose response to growth inhibition by oligomycin, a toxin extruded from the cell at the plasma membrane by Yor1. -

Enzymatic Encoding Methods for Efficient Synthesis Of
(19) TZZ__T (11) EP 1 957 644 B1 (12) EUROPEAN PATENT SPECIFICATION (45) Date of publication and mention (51) Int Cl.: of the grant of the patent: C12N 15/10 (2006.01) C12Q 1/68 (2006.01) 01.12.2010 Bulletin 2010/48 C40B 40/06 (2006.01) C40B 50/06 (2006.01) (21) Application number: 06818144.5 (86) International application number: PCT/DK2006/000685 (22) Date of filing: 01.12.2006 (87) International publication number: WO 2007/062664 (07.06.2007 Gazette 2007/23) (54) ENZYMATIC ENCODING METHODS FOR EFFICIENT SYNTHESIS OF LARGE LIBRARIES ENZYMVERMITTELNDE KODIERUNGSMETHODEN FÜR EINE EFFIZIENTE SYNTHESE VON GROSSEN BIBLIOTHEKEN PROCEDES DE CODAGE ENZYMATIQUE DESTINES A LA SYNTHESE EFFICACE DE BIBLIOTHEQUES IMPORTANTES (84) Designated Contracting States: • GOLDBECH, Anne AT BE BG CH CY CZ DE DK EE ES FI FR GB GR DK-2200 Copenhagen N (DK) HU IE IS IT LI LT LU LV MC NL PL PT RO SE SI • DE LEON, Daen SK TR DK-2300 Copenhagen S (DK) Designated Extension States: • KALDOR, Ditte Kievsmose AL BA HR MK RS DK-2880 Bagsvaerd (DK) • SLØK, Frank Abilgaard (30) Priority: 01.12.2005 DK 200501704 DK-3450 Allerød (DK) 02.12.2005 US 741490 P • HUSEMOEN, Birgitte Nystrup DK-2500 Valby (DK) (43) Date of publication of application: • DOLBERG, Johannes 20.08.2008 Bulletin 2008/34 DK-1674 Copenhagen V (DK) • JENSEN, Kim Birkebæk (73) Proprietor: Nuevolution A/S DK-2610 Rødovre (DK) 2100 Copenhagen 0 (DK) • PETERSEN, Lene DK-2100 Copenhagen Ø (DK) (72) Inventors: • NØRREGAARD-MADSEN, Mads • FRANCH, Thomas DK-3460 Birkerød (DK) DK-3070 Snekkersten (DK) • GODSKESEN, -

Progressive Encephalopathy and Central Hypoventilation Related to Homozygosity of NDUFV1 Nuclear Gene, a Rare Mitochondrial Disease
Avens Publishing Group Inviting Innovations Open Access Case Report J Pediatr Child Care August 2019 Volume:5, Issue:1 © All rights are reserved by AL-Buali MJ, et al. AvensJournal Publishing of Group Inviting Innovations Progressive Encephalopathy Pediatrics & and Central Hypoventilation Child Care AL-Buali MJ*, Al Ramadhan S, Al Buali H, Al-Faraj J and Related to Homozygosity of Al Mohanna M Pediatric Department , Maternity Children Hospital , Saudi Arabia *Address for Correspondence: NDUFV1 Nuclear Gene, a Rare Al-buali MJ, Pediatric Consultant and Consultant of Medical Genetics, Deputy Chairman of Medical Genetic Unite, Pediatrics Department , Maternity Children Hospital, Al-hassa, Hofuf city, Mitochondrial Disease Saudi Arabia; E-mail: [email protected] Submission: 15 July 2019 Accepted: 5 August 2019 Keywords: Progressive encephalopathy; Central hypoventilation; Published: 9 August 2019 Nuclear mitochondrial disease; NDUFV1 gene Copyright: © 2019 AL-Buali MJ, et al. This is an open access article distributed under the Creative Commons Attribution License, which Abstract permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Background: Mitochondrial diseases are a group of disorders caused by dysfunctional organelles that generate energy for our body. Mitochondria small double-membrane organelles found in of the most common groups of genetic diseases with a minimum every cell of the human body except red blood cells. Mitochondrial diseases are sometimes caused by mutations in the mitochondrial DNA prevalence of greater than 1 in 5000 in adults. Mitochondrial diseases that affect mitochondrial function. Other mitochondrial diseases are can be present at birth but can be manifested also at any age [2]. -

Table S1 the Four Gene Sets Derived from Gene Expression Profiles of Escs and Differentiated Cells
Table S1 The four gene sets derived from gene expression profiles of ESCs and differentiated cells Uniform High Uniform Low ES Up ES Down EntrezID GeneSymbol EntrezID GeneSymbol EntrezID GeneSymbol EntrezID GeneSymbol 269261 Rpl12 11354 Abpa 68239 Krt42 15132 Hbb-bh1 67891 Rpl4 11537 Cfd 26380 Esrrb 15126 Hba-x 55949 Eef1b2 11698 Ambn 73703 Dppa2 15111 Hand2 18148 Npm1 11730 Ang3 67374 Jam2 65255 Asb4 67427 Rps20 11731 Ang2 22702 Zfp42 17292 Mesp1 15481 Hspa8 11807 Apoa2 58865 Tdh 19737 Rgs5 100041686 LOC100041686 11814 Apoc3 26388 Ifi202b 225518 Prdm6 11983 Atpif1 11945 Atp4b 11614 Nr0b1 20378 Frzb 19241 Tmsb4x 12007 Azgp1 76815 Calcoco2 12767 Cxcr4 20116 Rps8 12044 Bcl2a1a 219132 D14Ertd668e 103889 Hoxb2 20103 Rps5 12047 Bcl2a1d 381411 Gm1967 17701 Msx1 14694 Gnb2l1 12049 Bcl2l10 20899 Stra8 23796 Aplnr 19941 Rpl26 12096 Bglap1 78625 1700061G19Rik 12627 Cfc1 12070 Ngfrap1 12097 Bglap2 21816 Tgm1 12622 Cer1 19989 Rpl7 12267 C3ar1 67405 Nts 21385 Tbx2 19896 Rpl10a 12279 C9 435337 EG435337 56720 Tdo2 20044 Rps14 12391 Cav3 545913 Zscan4d 16869 Lhx1 19175 Psmb6 12409 Cbr2 244448 Triml1 22253 Unc5c 22627 Ywhae 12477 Ctla4 69134 2200001I15Rik 14174 Fgf3 19951 Rpl32 12523 Cd84 66065 Hsd17b14 16542 Kdr 66152 1110020P15Rik 12524 Cd86 81879 Tcfcp2l1 15122 Hba-a1 66489 Rpl35 12640 Cga 17907 Mylpf 15414 Hoxb6 15519 Hsp90aa1 12642 Ch25h 26424 Nr5a2 210530 Leprel1 66483 Rpl36al 12655 Chi3l3 83560 Tex14 12338 Capn6 27370 Rps26 12796 Camp 17450 Morc1 20671 Sox17 66576 Uqcrh 12869 Cox8b 79455 Pdcl2 20613 Snai1 22154 Tubb5 12959 Cryba4 231821 Centa1 17897 -

Supplemental Material
Supplemental Table B ARGs in alphabetical order Symbol Title 3 months 6 months 9 months 12 months 23 months ANOVA Direction Category 38597 septin 2 1557 ± 44 1555 ± 44 1579 ± 56 1655 ± 26 1691 ± 31 0.05219 up Intermediate 0610031j06rik kidney predominant protein NCU-G1 491 ± 6 504 ± 14 503 ± 11 527 ± 13 534 ± 12 0.04747 up Early Adult 1G5 vesicle-associated calmodulin-binding protein 662 ± 23 675 ± 17 629 ± 16 617 ± 20 583 ± 26 0.03129 down Intermediate A2m alpha-2-macroglobulin 262 ± 7 272 ± 8 244 ± 6 290 ± 7 353 ± 16 0.00000 up Midlife Aadat aminoadipate aminotransferase (synonym Kat2) 180 ± 5 201 ± 12 223 ± 7 244 ± 14 275 ± 7 0.00000 up Early Adult Abca2 ATP-binding cassette, sub-family A (ABC1), member 2 958 ± 28 1052 ± 58 1086 ± 36 1071 ± 44 1141 ± 41 0.05371 up Early Adult Abcb1a ATP-binding cassette, sub-family B (MDR/TAP), member 1A 136 ± 8 147 ± 6 147 ± 13 155 ± 9 185 ± 13 0.01272 up Midlife Acadl acetyl-Coenzyme A dehydrogenase, long-chain 423 ± 7 456 ± 11 478 ± 14 486 ± 13 512 ± 11 0.00003 up Early Adult Acadvl acyl-Coenzyme A dehydrogenase, very long chain 426 ± 14 414 ± 10 404 ± 13 411 ± 15 461 ± 10 0.01017 up Late Accn1 amiloride-sensitive cation channel 1, neuronal (degenerin) 242 ± 10 250 ± 9 237 ± 11 247 ± 14 212 ± 8 0.04972 down Late Actb actin, beta 12965 ± 310 13382 ± 170 13145 ± 273 13739 ± 303 14187 ± 269 0.01195 up Midlife Acvrinp1 activin receptor interacting protein 1 304 ± 18 285 ± 21 274 ± 13 297 ± 21 341 ± 14 0.03610 up Late Adk adenosine kinase 1828 ± 43 1920 ± 38 1922 ± 22 2048 ± 30 1949 ± 44 0.00797 up Early -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Suppl 1.1 All Data Dimethyl Labled
Fasta headers Protein names Gene names Uniprot Ratio H/L normalized exp01 Ratio H/L normalized exp02 Ratio H/L normalized exp03 Ratio H/L normalized exp04 Ratio H/L normalized exp05 Ratio H/L normalized exp06 Ratio H/L normalized exp07 Ratio H/L normalized exp08 Ratio H/L normalized exp09 Ratio H/L normalized exp10 Ratio H/L normalized exp11b Ratio H/L normalized exp12b Peptides exp01 Peptides exp02 Peptides exp03 Peptides exp04 Peptides exp05 Peptides exp06 Peptides exp07 Peptides exp08 Peptides exp09 Peptides exp10 Peptides exp11b Peptides exp12b Unique peptides exp01 Unique peptides exp02 Unique peptides exp03 Unique peptides exp04 Unique peptides exp05 Unique peptides exp06 Unique peptides exp07 Unique peptides exp08 >sp|P01876|IGHA1_HUMAN Ig alpha-1 chain C region OS=Homo sapiens GN=IGHA1 PE=1 SV=2Ig alpha-1 chain C region IGHA1 P01876 1,90 0,62 2,03 12,53 11,35 0,80 1,87 0,60 0,88 1,60 1,33 1,34 7 6 11 8 10 6 8 8 4 3 7 7 3 3 5 4 5 3 4 3 >sp|P02647|APOA1_HUMAN Apolipoprotein A-I OS=Homo sapiens GN=APOA1 PE=1 SV=1;>tr|F8W696|F8W696_HUMAN Truncated apolipoprotein A-I OS=Homo sapiens GN=APOA1 PE=1 SV=1Apolipoprotein A-I;Truncated apolipoprotein A-I APOA1 P02647 1,71 1,13 0,77 1,73 0,89 1,12 0,61 0,84 1,53 1,46 1,16 0,86 17 16 17 18 16 14 13 16 17 13 14 17 17 16 17 18 16 14 13 16 >sp|P01024|CO3_HUMAN Complement C3 OS=Homo sapiens GN=C3 PE=1 SV=2Complement C3;Complement C3 beta chain;Complement C3 alpha chain;C3a anaphylatoxin;Acylation stimulating protein;Complement C3b alpha chain;Complement C3c alpha chain fragment 1;Complement C3dg -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Iron–Sulfur Clusters: from Metals Through Mitochondria Biogenesis to Disease
JBIC Journal of Biological Inorganic Chemistry https://doi.org/10.1007/s00775-018-1548-6 MINIREVIEW Iron–sulfur clusters: from metals through mitochondria biogenesis to disease Mauricio Cardenas‑Rodriguez1 · Afroditi Chatzi1 · Kostas Tokatlidis1 Received: 13 November 2017 / Accepted: 22 February 2018 © The Author(s) 2018. This article is an open access publication Abstract Iron–sulfur clusters are ubiquitous inorganic co-factors that contribute to a wide range of cell pathways including the main- tenance of DNA integrity, regulation of gene expression and protein translation, energy production, and antiviral response. Specifcally, the iron–sulfur cluster biogenesis pathways include several proteins dedicated to the maturation of apoproteins in diferent cell compartments. Given the complexity of the biogenesis process itself, the iron–sulfur research area consti- tutes a very challenging and interesting feld with still many unaddressed questions. Mutations or malfunctions afecting the iron–sulfur biogenesis machinery have been linked with an increasing amount of disorders such as Friedreich’s ataxia and various cardiomyopathies. This review aims to recap the recent discoveries both in the yeast and human iron–sulfur cluster arena, covering recent discoveries from chemistry to disease. Keywords Metal · Cysteine · Iron–sulfur · Mitochondrial disease · Iron regulation Abbreviations Rad3 TFIIH/NER complex ATP-dependent Aft Activator of ferrous transport 5′–3′ DNA helicase subunit RAD3 Atm1 ATP-binding cassette (ABC) transporter Ssq1 Stress-seventy sub-family Q 1 Cfd1 Complement factor D SUF Sulfur mobilization system CIA Cytosolic iron–sulfur cluster assembly XPD Xeroderma pigmentosum group D Erv1 Essential for respiration and vegetative helicase growth 1 Yap5 Yeast AP-5 GFER Growth factor, augmenter of liver regeneration Grx/GLRX Glutaredoxin Introduction GSH Reduced glutathione GSSG Oxidised glutathione Iron–sulfur clusters are metal prosthetic groups, synthesized HSP9 Heat shock protein 9 and utilised in diferent cell compartments. -

Discovery and the Genic Map of the Human Genome
Downloaded from genome.cshlp.org on October 6, 2021 - Published by Cold Spring Harbor Laboratory Press RESEARCH The Genexpress Index: A Resource for Gene Discovery and the Genic Map of the Human Genome R6mi Houlgatte, 1'2'3' R6gine Mariage-Samson, 1'2'3 Simone Duprat, 2 Anne Tessier, 2 Simone Bentolila, 1'2 Bernard Lamy, 2 and Charles Auffray 1'2'4 1Genexpress, Centre National de la Recherche Scientifique (CNRS) UPR420, 94801 Villejuif CEDEX, France; 2Genexpress, G4n6thon, 91002 Evry CEDEX, France Detailed analysis of a set of 18,698 sequences derived from both ends of 10,979 human skeletal muscle and brain cDNA clones defined 6676 functional families, characterized by their sequence signatures over 5750 distinct human gene transcripts. About half of these genes have been assigned to specific chromosomes utilizing 2733 eSTS markers, the polymerase chain reaction, and DNA from human-rodent somatic cell hybrids. Sequence and clone clustering and a functional classification together with comprehensive data base searches and annotations made it possible to develop extensive sequence and map cross-indexes, define electronic expression profiles, identify a new set of overlapping genes, and provide numerous new candidate genes for human pathologies. During the last 20 years, since the first descrip- 1993; Park et al. 1993; Takeda et al. 1993; Affara tions of eucaryotic cDNA cloning (Rougeon et al. et al. 1994; Davies et al. 1994; Kerr et al. 1994; 1975; Efstratiadis et al. 1976), cDNA studies have Konishi et al. 1994; Kurata et al. 1994; Liew et al. played a central role in molecular genetics. Early 1994; Murakawa et al.