Cupriavidus Basilensis Type Strain, a 2,6-Dichlorophenol-Degrading Bacterium Downloaded From
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
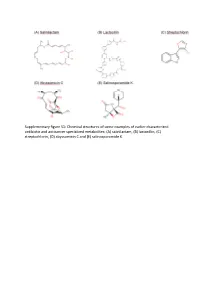
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

Identification of Genes Responsible for Ochratoxin-A Biodegradation By
Szent István University PhD School of Environmental Sciences Identification of genes responsible for ochratoxin-A biodegradation by Cupriavidus basilensis ŐR16 and valuation of Cupriavidus genus for mycotoxins biodegradation potential Thesis of Doctoral Dissertation (PhD) Mohammed Talib Jasim AL-Nussairawi Gödöllő, Hungary 2020 I. DECLARATION I declare that this thesis is a record of original work and contains no material that has been accepted for the award of any other degree or diploma in any university. To the best of my knowledge and belief, this thesis contains no material previously published or written by another person, except where due reference is made in the text. Name: Ph.D. School of Environmental Sciences Discipline: Environmental Sciences / Biotechnology Leader of Doctoral School: Csákiné Dr. Erika Michéli, Ph.D. professor, head of department Department of Soil science and Agrochemistry Faculty of Agricultural and Environmental Sciences Institute of Environmental Sciences Szent István University Supervisor: Matyas Cserhati, Ph.D. associate professor Department of Environmental Protection and Ecotoxicology Faculty of Agricultural and Environmental Sciences Institute of Aquaculture and Environmental Protection Szent István University ........................................................... ................................................... Approval of School Leader Approval of Supervisor 2 Table of Contents I. DECLARATION ................................................................................................................... -

Mapping the Diversity of Microbial Lignin Catabolism: Experiences from the Elignin Database
Applied Microbiology and Biotechnology (2019) 103:3979–4002 https://doi.org/10.1007/s00253-019-09692-4 MINI-REVIEW Mapping the diversity of microbial lignin catabolism: experiences from the eLignin database Daniel P. Brink1 & Krithika Ravi2 & Gunnar Lidén2 & Marie F Gorwa-Grauslund1 Received: 22 December 2018 /Revised: 6 February 2019 /Accepted: 9 February 2019 /Published online: 8 April 2019 # The Author(s) 2019 Abstract Lignin is a heterogeneous aromatic biopolymer and a major constituent of lignocellulosic biomass, such as wood and agricultural residues. Despite the high amount of aromatic carbon present, the severe recalcitrance of the lignin macromolecule makes it difficult to convert into value-added products. In nature, lignin and lignin-derived aromatic compounds are catabolized by a consortia of microbes specialized at breaking down the natural lignin and its constituents. In an attempt to bridge the gap between the fundamental knowledge on microbial lignin catabolism, and the recently emerging field of applied biotechnology for lignin biovalorization, we have developed the eLignin Microbial Database (www.elignindatabase.com), an openly available database that indexes data from the lignin bibliome, such as microorganisms, aromatic substrates, and metabolic pathways. In the present contribution, we introduce the eLignin database, use its dataset to map the reported ecological and biochemical diversity of the lignin microbial niches, and discuss the findings. Keywords Lignin . Database . Aromatic metabolism . Catabolic pathways -

Cupriavidus Cauae Sp. Nov., Isolated from Blood of an Immunocompromised Patient
TAXONOMIC DESCRIPTION Kweon et al., Int. J. Syst. Evol. Microbiol. 2021;71:004759 DOI 10.1099/ijsem.0.004759 Cupriavidus cauae sp. nov., isolated from blood of an immunocompromised patient Oh Joo Kweon1†, Wenting Ruan2†, Shehzad Abid Khan2, Yong Kwan Lim1, Hye Ryoun Kim1, Che Ok Jeon2,* and Mi- Kyung Lee1,* Abstract A novel Gram- stain- negative, facultative aerobic and rod- shaped bacterium, designated as MKL-01T and isolated from the blood of immunocompromised patient, was genotypically and phenotypically characterized. The colonies were found to be creamy yellow and convex. Phylogenetic analysis based on 16S rRNA gene and whole-genome sequences revealed that strain MKL-01T was most closely related to Cupriavidus gilardii LMG 5886T, present within a large cluster in the genus Cupriavidus. The genome sequence of strain MKL-01T showed the highest average nucleotide identity value of 92.1 % and digital DNA–DNA hybridization value of 44.8 % with the closely related species C. gilardii LMG 5886T. The genome size of the isolate was 5 750 268 bp, with a G+C content of 67.87 mol%. The strain could grow at 10–45 °C (optimum, 37–40 °C), in the presence of 0–10 % (w/v) NaCl (optimum, 0.5%) and at pH 6.0–10.0 (optimum, pH 7.0). Strain MKL-01T was positive for catalase and negative for oxidase. The major fatty acids were C16 : 0, summed feature 3 (C16 : 1 ω7c/C16 : 1 ω6c and/or C16 : 1 ω6c/C16 : 1 ω7c) and summed feature 8 (C18 : 1 ω7c and/or C18 : 1 ω6c). -

Choice of Carbon Source for 1 Microcosm Enrichment
bioRxiv preprint doi: https://doi.org/10.1101/517854; this version posted January 13, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 1 Capturing the Diversity of Subsurface Microbiota – Choice of Carbon Source for 2 Microcosm Enrichment and Isolation of Groundwater Bacteria 3 4 Xiaoqin Wu1, Sarah Spencer2, Eric J. Alm2, Jana Voriskova1, Romy Chakraborty1* 5 6 7 1Department of Ecology, Earth and Environmental Sciences Area, Lawrence Berkeley 8 National Laboratory, Berkeley, California 94720, USA 9 2 Department of Biological Engineering, Massachusetts Institute of Technology, 10 Cambridge, Massachusetts 02139, USA 11 12 13 14 15 16 17 *Corresponding author: 18 Romy Chakraborty 19 Address: 70A-3317F, 1 Cyclotron Rd., Berkeley, CA 94720 20 Tel: (510) 486-4091 21 Email: [email protected] 22 1 bioRxiv preprint doi: https://doi.org/10.1101/517854; this version posted January 13, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. 23 Abstract 24 Improved and innovative enrichment/isolation techniques that yield to relevant 25 isolates representing the true diversity of environmental microbial communities would 26 significantly advance exploring the physiology of ecologically important taxa in 27 ecosystems. Traditionally, either simple organic carbon (C) or yeast extract is used as C 28 source in culture medium for microbial enrichment/isolation in laboratory. In natural 29 environment, however, microbial population and evolution are greatly influenced by the 30 property and composition of natural organic C. -

Genome of Ca. Pandoraea Novymonadis, an Endosymbiotic Bacterium of the Trypanosomatid Novymonas Esmeraldas
fmicb-08-01940 September 30, 2017 Time: 16:0 # 1 ORIGINAL RESEARCH published: 04 October 2017 doi: 10.3389/fmicb.2017.01940 Genome of Ca. Pandoraea novymonadis, an Endosymbiotic Bacterium of the Trypanosomatid Novymonas esmeraldas Alexei Y. Kostygov1,2†, Anzhelika Butenko1,3†, Anna Nenarokova3,4, Daria Tashyreva3, Pavel Flegontov1,3,5, Julius Lukeš3,4 and Vyacheslav Yurchenko1,3,6* 1 Life Science Research Centre, Faculty of Science, University of Ostrava, Ostrava, Czechia, 2 Zoological Institute of the Russian Academy of Sciences, St. Petersburg, Russia, 3 Biology Centre, Institute of Parasitology, Czech Academy of Sciences, Ceskéˇ Budejovice,ˇ Czechia, 4 Faculty of Sciences, University of South Bohemia, Ceskéˇ Budejovice,ˇ Czechia, 5 Institute for Information Transmission Problems, Russian Academy of Sciences, Moscow, Russia, 6 Institute of Environmental Technologies, Faculty of Science, University of Ostrava, Ostrava, Czechia We have sequenced, annotated, and analyzed the genome of Ca. Pandoraea novymonadis, a recently described bacterial endosymbiont of the trypanosomatid Novymonas esmeraldas. When compared with genomes of its free-living relatives, it Edited by: has all the hallmarks of the endosymbionts’ genomes, such as significantly reduced João Marcelo Pereira Alves, University of São Paulo, Brazil size, extensive gene loss, low GC content, numerous gene rearrangements, and Reviewed by: low codon usage bias. In addition, Ca. P. novymonadis lacks mobile elements, Zhao-Rong Lun, has a strikingly low number of pseudogenes, and almost all genes are single Sun Yat-sen University, China Vera Tai, copied. This suggests that it already passed the intensive period of host adaptation, University of Western Ontario, Canada which still can be observed in the genome of Polynucleobacter necessarius, a *Correspondence: certainly recent endosymbiont. -

Appendix 1. Validly Published Names, Conserved and Rejected Names, And
Appendix 1. Validly published names, conserved and rejected names, and taxonomic opinions cited in the International Journal of Systematic and Evolutionary Microbiology since publication of Volume 2 of the Second Edition of the Systematics* JEAN P. EUZÉBY New phyla Alteromonadales Bowman and McMeekin 2005, 2235VP – Valid publication: Validation List no. 106 – Effective publication: Names above the rank of class are not covered by the Rules of Bowman and McMeekin (2005) the Bacteriological Code (1990 Revision), and the names of phyla are not to be regarded as having been validly published. These Anaerolineales Yamada et al. 2006, 1338VP names are listed for completeness. Bdellovibrionales Garrity et al. 2006, 1VP – Valid publication: Lentisphaerae Cho et al. 2004 – Valid publication: Validation List Validation List no. 107 – Effective publication: Garrity et al. no. 98 – Effective publication: J.C. Cho et al. (2004) (2005xxxvi) Proteobacteria Garrity et al. 2005 – Valid publication: Validation Burkholderiales Garrity et al. 2006, 1VP – Valid publication: Vali- List no. 106 – Effective publication: Garrity et al. (2005i) dation List no. 107 – Effective publication: Garrity et al. (2005xxiii) New classes Caldilineales Yamada et al. 2006, 1339VP VP Alphaproteobacteria Garrity et al. 2006, 1 – Valid publication: Campylobacterales Garrity et al. 2006, 1VP – Valid publication: Validation List no. 107 – Effective publication: Garrity et al. Validation List no. 107 – Effective publication: Garrity et al. (2005xv) (2005xxxixi) VP Anaerolineae Yamada et al. 2006, 1336 Cardiobacteriales Garrity et al. 2005, 2235VP – Valid publica- Betaproteobacteria Garrity et al. 2006, 1VP – Valid publication: tion: Validation List no. 106 – Effective publication: Garrity Validation List no. 107 – Effective publication: Garrity et al. -

Lawrence Berkeley National Laboratory Recent Work
Lawrence Berkeley National Laboratory Recent Work Title Mutant phenotypes for thousands of bacterial genes of unknown function. Permalink https://escholarship.org/uc/item/7c96t04w Journal Nature, 557(7706) ISSN 0028-0836 Authors Price, Morgan N Wetmore, Kelly M Waters, R Jordan et al. Publication Date 2018-05-16 DOI 10.1038/s41586-018-0124-0 Peer reviewed eScholarship.org Powered by the California Digital Library University of California 1 2 3 4 5 6 7 8 9 10 11 Mutant Phenotypes for Thousands of Bacterial Genes of Unknown Function 12 13 Morgan N. Price1, Kelly M. Wetmore1, R. Jordan Waters2, Mark Callaghan1, Jayashree Ray1, 14 Hualan Liu1, Jennifer V. Kuehl1, Ryan A. Melnyk1, Jacob S. Lamson1, Yumi Suh1, Hans K. 15 Carlson1, Zuelma Esquivel1, Harini Sadeeshkumar1, Romy Chakraborty3, Grant M. Zane4, 16 Benjamin E. Rubin5, Judy D. Wall4, Axel Visel2,6, James Bristow2, Matthew J. Blow2,*, Adam P. 17 Arkin1,7,*, Adam M. Deutschbauer1,8,* 18 19 20 1Environmental Genomics and Systems Biology Division, Lawrence Berkeley National 21 Laboratory 22 2Joint Genome Institute, Lawrence Berkeley National Laboratory 23 3Climate and Ecosystem Sciences Division, Lawrence Berkeley National Laboratory 24 4Department of Biochemistry, University of Missouri 25 5Division of Biological Sciences, University of California, San Diego 26 6School of Natural Sciences, University of California, Merced 27 7Department of Bioengineering, University of California, Berkeley 28 8Department of Plant and Microbial Biology, University of California, Berkeley 29 *To whom correspondence should be addressed: 30 MJB ([email protected]) 31 APA ([email protected]) 32 AMD ([email protected]) 33 34 Website for interactive analysis of mutant fitness data: 35 http://fit.genomics.lbl.gov/ 36 37 Website with supplementary information and bulk data downloads: 38 http://genomics.lbl.gov/supplemental/bigfit/ 39 40 41 42 1 43 44 45 Summary 46 One third of all protein-coding genes from bacterial genomes cannot be annotated with a 47 function. -
Microorganisms
microorganisms Article Potential PGPR Properties of Cellulolytic, Nitrogen-Fixing, Phosphate-Solubilizing Bacteria in Rehabilitated Tropical Forest Soil Amelia Tang 1, Ahmed Osumanu Haruna 1,2,3,*, Nik Muhamad Ab. Majid 3 and Mohamadu Boyie Jalloh 4 1 Faculty of Agriculture and Food Sciences, Universiti Putra Malaysia Bintulu Campus, Bintulu 97008, Sarawak, Malaysia; [email protected] 2 Institute of Tropical Agriculture and Food Security (ITAFoS), Universiti Putra Malaysia, Serdang 43400, Selangor, Malaysia 3 Institute of Tropical Forestry and Forest Products (INTROP), Universiti Putra Malaysia, Serdang 43400, Selangor, Malaysia; [email protected] 4 Faculty of Sustainable Agriculture, Universiti Malaysia Sabah, Sandakan Branch, Locked Bag No. 3, Sandakan 90509, Sabah, Malaysia; [email protected] * Correspondence: [email protected] Received: 26 January 2020; Accepted: 20 February 2020; Published: 20 March 2020 Abstract: In the midst of the major soil degradation and erosion faced by tropical ecosystems, rehabilitated forests are being established to avoid the further deterioration of forest lands. In this context, cellulolytic, nitrogen-fixing (N-fixing), phosphate-solubilizing bacteria are very important functional groups in regulating the elemental cycle and plant nutrition, hence replenishing the nutrient content in forest soils. As is the case for other potential plant growth-promoting (PGP) rhizobacteria, these functional bacteria could have cross-functional abilities or beneficial traits that are essential for plants and can -
Cupriavidus Metallidurans Strains with Different Mobilomes and from Distinct Environments Have Comparable Phenomes
G C A T T A C G G C A T genes Article Cupriavidus metallidurans Strains with Different Mobilomes and from Distinct Environments Have Comparable Phenomes Rob Van Houdt 1,* , Ann Provoost 1, Ado Van Assche 2, Natalie Leys 1 , Bart Lievens 2, Kristel Mijnendonckx 1 and Pieter Monsieurs 1 1 Microbiology Unit, Belgian Nuclear Research Centre (SCK•CEN), B-2400 Mol, Belgium; [email protected] (A.P.); [email protected] (N.L.); [email protected] (K.M.); [email protected] (P.M.) 2 Laboratory for Process Microbial Ecology and Bioinspirational Management, KU Leuven, B-2860 Sint-Katelijne-Waver, Belgium; [email protected] (A.V.A.); [email protected] (B.L.) * Correspondence: [email protected] Received: 21 September 2018; Accepted: 15 October 2018; Published: 18 October 2018 Abstract: Cupriavidus metallidurans has been mostly studied because of its resistance to numerous heavy metals and is increasingly being recovered from other environments not typified by metal contamination. They host a large and diverse mobile gene pool, next to their native megaplasmids. Here, we used comparative genomics and global metabolic comparison to assess the impact of the mobilome on growth capabilities, nutrient utilization, and sensitivity to chemicals of type strain CH34 and three isolates (NA1, NA4 and H1130). The latter were isolated from water sources aboard the International Space Station (NA1 and NA4) and from an invasive human infection (H1130). The mobilome was expanded as prophages were predicted in NA4 and H1130, and a genomic island putatively involved in abietane diterpenoids metabolism was identified in H1130. An active CRISPR-Cas system was identified in strain NA4, providing immunity to a plasmid that integrated in CH34 and NA1. -
Aerobic and Oxygen-Limited Naphthalene-Amended Enrichments Induced the Dominance of Pseudomonas Spp
Aerobic and oxygen-limited naphthalene-amended enrichments induced the dominance of Pseudomonas spp. from a groundwater bacterial biofilm Tibor Benedek, Flóra Szentgyörgyi, Istvan Szabo, Milán Farkas, Robert Duran, Balázs Kriszt, András Táncsics To cite this version: Tibor Benedek, Flóra Szentgyörgyi, Istvan Szabo, Milán Farkas, Robert Duran, et al.. Aerobic and oxygen-limited naphthalene-amended enrichments induced the dominance of Pseudomonas spp. from a groundwater bacterial biofilm. Applied Microbiology and Biotechnology, Springer Verlag, 2020, 104 (13), pp.6023-6043. 10.1007/s00253-020-10668-y. hal-02734344 HAL Id: hal-02734344 https://hal.archives-ouvertes.fr/hal-02734344 Submitted on 2 Jun 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Applied Microbiology and Biotechnology https://doi.org/10.1007/s00253-020-10668-y ENVIRONMENTAL BIOTECHNOLOGY Aerobic and oxygen-limited naphthalene-amended enrichments induced the dominance of Pseudomonas spp. from a groundwater bacterial biofilm Tibor Benedek1 & Flóra Szentgyörgyi2 & István Szabó2 & Milán Farkas2 & Robert Duran3 & Balázs Kriszt2 & András Táncsics1 Received: 19 February 2020 /Revised: 29 April 2020 /Accepted: 4 May 2020 # The Author(s) 2020 Abstract In this study, we aimed at determining the impact of naphthalene and different oxygen levels on a biofilm bacterial community originated from a petroleum hydrocarbon–contaminated groundwater. -

New Phytologist Supporting Information Article Title: Species
New Phytologist Supporting Information Article title: Species-specific Root Microbiota Dynamics in Response to Plant-Available Phosphorus Authors: Natacha Bodenhausen, Vincent Somerville, Alessandro Desirò, Jean-Claude Walser, Lorenzo Borghi, Marcel G.A. van der Heijden and Klaus Schlaeppi Article acceptance date: Click here to enter a date. The following Supporting Information is available for this article: Figure S1 | Analysis steps Figure S2 | Comparison of ITS PCR approaches for plant root samples Figure S3 | Rarefaction curves for bacterial anD fungal OTU richness Figure S4 | Effects of plant species anD P-levels on microbial richness, diversity anD evenness Figure S5 | Beta-diversity analysis including the soil samples Figure S6 | IDentification of enDobacteria by phylogenetic placement Table S1 | Effects of plant species anD P treatment on alpha Diversity (ANOVA) Table S2 | Effects of plant species anD P treatment on community composition (PERMANOVA) Table S3 | Effects P treatment on species-specific community compositions (PERMANOVA) Table S4 | Statistics from iDentifying phosphate sensitive microbes Table S5 | Network characteristics MethoDs S1 | Microbiota profiling anD analysis Notes S1 | Comparison of PCR approaches Notes S2 | Bioinformatic scripts Notes S3 | Data analysis in R Notes S4 | Mapping enDobacteria Notes S5 | Comparison of ITS profiling approaches Alpha diversity all samples Rarefaction analysis Figure S3 (vegan) Raw counts plant samples Rarefication (500x) to Figure S4 ANOVA 15’000 seq/sample Table S1 Filter: OTUs