Simple Gait Parameterization and 3D Animation for Anonymous Visual Monitoring Based on Augmented Reality
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Motion Enriching Using Humanoide Captured Motions
MASTER THESIS: MOTION ENRICHING USING HUMANOIDE CAPTURED MOTIONS STUDENT: SINAN MUTLU ADVISOR : A NTONIO SUSÌN SÀNCHEZ SEPTEMBER, 8TH 2010 COURSE: MASTER IN COMPUTING LSI DEPERTMANT POLYTECNIC UNIVERSITY OF CATALUNYA 1 Abstract Animated humanoid characters are a delight to watch. Nowadays they are extensively used in simulators. In military applications animated characters are used for training soldiers, in medical they are used for studying to detect the problems in the joints of a patient, moreover they can be used for instructing people for an event(such as weather forecasts or giving a lecture in virtual environment). In addition to these environments computer games and 3D animation movies are taking the benefit of animated characters to be more realistic. For all of these mediums motion capture data has a great impact because of its speed and robustness and the ability to capture various motions. Motion capture method can be reused to blend various motion styles. Furthermore we can generate more motions from a single motion data by processing each joint data individually if a motion is cyclic. If the motion is cyclic it is highly probable that each joint is defined by combinations of different signals. On the other hand, irrespective of method selected, creating animation by hand is a time consuming and costly process for people who are working in the art side. For these reasons we can use the databases which are open to everyone such as Computer Graphics Laboratory of Carnegie Mellon University. Creating a new motion from scratch by hand by using some spatial tools (such as 3DS Max, Maya, Natural Motion Endorphin or Blender) or by reusing motion captured data has some difficulties. -

The University of Chicago Looking at Cartoons
THE UNIVERSITY OF CHICAGO LOOKING AT CARTOONS: THE ART, LABOR, AND TECHNOLOGY OF AMERICAN CEL ANIMATION A DISSERTATION SUBMITTED TO THE FACULTY OF THE DIVISION OF THE HUMANITIES IN CANDIDACY FOR THE DEGREE OF DOCTOR OF PHILOSOPHY DEPARTMENT OF CINEMA AND MEDIA STUDIES BY HANNAH MAITLAND FRANK CHICAGO, ILLINOIS AUGUST 2016 FOR MY FAMILY IN MEMORY OF MY FATHER Apparently he had examined them patiently picture by picture and imagined that they would be screened in the same way, failing at that time to grasp the principle of the cinematograph. —Flann O’Brien CONTENTS LIST OF FIGURES...............................................................................................................................v ABSTRACT.......................................................................................................................................vii ACKNOWLEDGMENTS....................................................................................................................viii INTRODUCTION LOOKING AT LABOR......................................................................................1 CHAPTER 1 ANIMATION AND MONTAGE; or, Photographic Records of Documents...................................................22 CHAPTER 2 A VIEW OF THE WORLD Toward a Photographic Theory of Cel Animation ...................................72 CHAPTER 3 PARS PRO TOTO Character Animation and the Work of the Anonymous Artist................121 CHAPTER 4 THE MULTIPLICATION OF TRACES Xerographic Reproduction and One Hundred and One Dalmatians.......174 -

Authoring Motion Cycles
Authoring Motion Cycles Loïc Ciccone Martin Guay ETH Zurich Disney Research Zurich Maurizio Nitti Robert W. Sumner Disney Research Zurich ETH Zurich, Disney Research Zurich Figure 1: Left: To specify a motion cycle, the user acts out several loops of the motion using a variety of capture devices. Middle: A looping motion cycle is automatically extracted from the noisy performance. Right: A custom motion representation tool, called MoCurves, allows controlling and coordinating spatial and temporal transformations from a single viewport. ABSTRACT CCS CONCEPTS Motion cycles play an important role in animation production • Computing methodologies → Animation; Graphics systems and game development. However, creating motion cycles relies and interfaces; on general-purpose animation packages with complex interfaces that require expert training. Our work explores the specic chal- KEYWORDS lenges of motion cycle authoring and provides a system simple Motion cycles, Animation interface, Performance, Motion curves enough for novice animators while maintaining the exibility of control demanded by experts. Due to their cyclic nature, we show ACM Reference format: that performance animation provides a natural interface for mo- Loïc Ciccone, Martin Guay, Maurizio Nitti, and Robert W. Sumner. 2017. tion cycle specication. Our system allows the user to act several Authoring Motion Cycles. In Proceedings of ACM SIGGRAPH / Eurographics loops of motion using a variety of capture devices and automat- Symposium on Computer Animation, Los Angeles, California USA, July 2017 (SCA’17), 9 pages. ically extracts a looping cycle from this potentially noisy input. DOI: 10.475/123_4 Motion cycles for dierent character components can be authored in a layered fashion, or our method supports cycle extraction from higher-dimensional data for capture devices that deliver many de- 1 INTRODUCTION grees of freedom. -
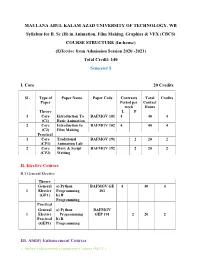
MAULANA ABUL KALAM AZAD UNIVERSITY of TECHNOLOGY, WB Syllabus for B. Sc (H) in Animation, Film Making, Graphics & VFX (CBCS)
MAULANA ABUL KALAM AZAD UNIVERSITY OF TECHNOLOGY, WB Syllabus for B. Sc (H) in Animation, Film Making, Graphics & VFX (CBCS) COURSE STRUCTURE (In-house) (Effective from Admission Session 2020 -2021) Total Credit: 140 Semester I I. Core 20 Credits SL Type of Paper Name Paper Code Contracts Total Credits Paper Period per Contact week Hours Theory L P 1 Core Introduction To BAFMGV 101 4 40 4 (C1) Basic Animation 2 Core Introduction to BAFMGV 102 4 40 4 (C2) Film Making Practical 1 Core Traditional BAFMGV 191 2 20 2 (CP1) Animation Lab 2 Core Story & Script BAFMGV 192 2 20 2 (CP2) Writing II. Elective Courses B.1 General Elective Theory General a) Python BAFMGV GE 4 40 4 1 Elective Programming 101 (GE1) b) R Programming Practical General a) Python BAFMGV 1 Elective Programming GEP 191 2 20 2 Practical b) R (GEP1) Programming III. Ability Enhancement Courses 1. Ability Enhancement Compulsory Courses (AECC) Theory Ability Communicative BAFMGV AECC 1 Enhance English I 101 2 20 2 ment Compuls ory Courses (AECC1) Semester II I. Core 20 Credits SL Type of Paper Name Paper Code Contracts Total Credits Paper Period per Contact week Hours L P Theory Introduction to BAFMGV 201 1 Core (C3) Graphic Design 4 40 4 & Visual Art Introduction to BAFMGV 202 2 Core (C4) 2D Animation 4 40 4 Practical Digital Design, 1 Core Info graphics & BAFMGV 291 2 20 2 (CP3) Branding (Adobe Photoshop, illustrator, Corel Draw) 2 Core 2D animation lab BAFMGV 292 2 20 2 (CP4) (Flash) II. Elective Courses B.1 General Elective Theory General a) Web Design BAFMGV 1 Elective b)Computer GE201 4 40 4 (GE2) Networks Practical General a) Webpage BAFMGV 1 Elective Design GEP291 2 20 2 Practical (GEP2) b)Networking Lab III. -

Multiple Dynamic Pivots Rig for 3D Biped Character Designed Along Human-Computer Interaction Principles
Multiple Dynamic Pivots Rig for 3D Biped Character Designed along Human-Computer Interaction Principles by Mihaela D. Petriu A thesis submitted to the Faculty of Graduate and Postdoctoral Affairs in partial fulfillment of the requirements for the degree of Master of Computer Science in Human-Computer Interaction Carleton University Ottawa, Ontario © 2020, Mihaela D. Petriu Abstract This thesis is addressing the design, implementation and usability testing of a modular extensible animator-centric authoring tool-independent 3D Multiple Dynamic Pivots (MDP) biped character rig. An objective of the thesis is to show that the design of the character rig must be independent of its platform, cater to the needs of the animation workflow based on HCI principles (particularly that of Direct Manipulation) and be modular and extensible in order to build and grow as needed within the production pipeline. In the thesis, the proposed rig design is implemented in Maya, the most widely used and taught commercial 3D animation authoring tool. Another thesis objective is to perform usability testing of the MDP rig with animation students and professionals, in order to gauge the new design’s intuitiveness for those relatively new to the trade and those already steeped in its decades of accumulated technical idiosyncrasies. ii Acknowledgements My deepest gratitude goes to my supervisor Dr. Chris Joslin for his constant guidance and support. I would also like to thank my family for their continuous help and encouragement. Finally, I thank my friend Sandra E. Hobbs for her constructive chaos that shed light on my design's weaknesses. iii Table of Contents Abstract ............................................................................................................................. -

Video Puppetry: a Performative Interface for Cutout Animation
Video Puppetry: A Performative Interface for Cutout Animation Connelly Barnes1 David E. Jacobs2 Jason Sanders2 Dan B Goldman3 Szymon Rusinkiewicz1 Adam Finkelstein1 Maneesh Agrawala2 1Princeton University 2University of California, Berkeley 3Adobe Systems Figure 1: A puppeteer (left) manipulates cutout paper puppets tracked in real time (above) to control an animation (below). Abstract 1 Introduction Creating animated content is difficult. While traditional hand- We present a video-based interface that allows users of all skill drawn or stop-motion animation allows broad expressive freedom, levels to quickly create cutout-style animations by performing the creating such animation requires expertise in composition and tim- character motions. The puppeteer first creates a cast of physical ing, as the animator must laboriously craft a sequence of frames puppets using paper, markers and scissors. He then physically to convey motion. Computer-based animation tools such as Flash, moves these puppets to tell a story. Using an inexpensive overhead Toon Boom and Maya provide sophisticated interfaces that allow camera our system tracks the motions of the puppets and renders precise and flexible control over the motion. Yet, the cost of pro- them on a new background while removing the puppeteer’s hands. viding such control is a complicated interface that is difficult to Our system runs in real-time (at 30 fps) so that the puppeteer and learn. Thus, traditional animation and computer-based animation the audience can immediately see the animation that is created. Our tools are accessible only to experts. system also supports a variety of constraints and effects including Puppetry, in contrast, is a form of dynamic storytelling that per- articulated characters, multi-track animation, scene changes, cam- 1 formers of all ages and skill levels can readily engage in. -

Animation of a High-Definition 2D Fighting Game Character
Tuula Rantala ANIMATION OF A HIGH-DEFINITION 2D FIGHTING GAME CHARACTER Thesis Kajaani University of Applied Sciences School of Business Business Information Technology Spring 2013 OPINNÄYTETYÖ TIIVISTELMÄ Koulutusala Koulutusohjelma Luonnontieteiden ala Tietojenkäsittely Tekijä(t) Tuula Rantala Työn nimi Teräväpiirtoisen 2d-taistelupelihahmon animointi Vaihtoehtoisetvaihtoehtiset ammattiopinnot Ohjaaja(t) Peligrafiikka Nick Sweetman Toimeksiantaja - Aika Sivumäärä ja liitteet Kevät 2013 56 Tämä opinnäytetyö pyrkii erittelemään hyvän pelihahmoanimaation periaatteita ja tarkastelee eri lähestymistapoja 2d-animaation luomiseen. Perinteisen animaation periaatteet, kuten ajoitus ja liikkeen välistys, pätevät pelianimaa- tiossa samalla tavalla kuin elokuva-animaatiossakin. Pelien tekniset rajoitukset ja interaktiivisuus asettavat kuiten- kin lisähaasteita animaatioiden toteuttamiseen tavalla, joka sekä tukee pelimekaniikkaa että on visuaalisesti kiin- nostava. Vetoava hahmoanimaatio on erityisen tärkeää taistelupeligenressä. Varhaiset taistelupelit 1990–luvun alusta käyt- tivät matalaresoluutioista bittikarttagrafiikkaa ja niissä oli alhainen määrä animaatiokehyksiä, mutta nykyään pelien standardit grafiikan ja animaation suhteen ovat korkealla. Viime vuosina monet pelinkehittäjät ovat siirtyneet käyttämään 2d-grafiikan sijasta 3d-grafiikkaa, koska 3d-animaation tuottaminen on monella tavalla joustavampaa. Perinteiselle 2d-grafiikalle on kuitenkin edelleen kysyntää, sillä käsin piirretyn animaation ainutlaatuista ulkoasua ei voi täysin korvata -

The Art of Animation
UNIVERSITY OF CALIFORNIA College of Engineering Department of Electrical Engineering and Computer Sciences Computer Science Division CS 294-7 The Art Of Animation Professor Brian A. Barsky and Laurence Arcadias Fall 2002 Overview Class time and place The class is on Mondays, from 3 pm to 6 pm, in 380 Soda Hall. The first class is August 26 and the last class is December 2. There will be no class on Sept. 2 (Labor Day) nor on Nov.11 (Veterans Day). Computer lab The computer lab is located in 111 Cory. It is open from 7:30 am to 6:30 pm and is accessible by cardkey outside those hours. This multimedia instructional lab comprises: six Apple PowerMac G4 computers (each with 1.5 GB RAM, SuperDrive, 867 MHz CPU, NVIDIA GeForce2 MX graphics card, 80 GB hard drive, and a 250-MB ZIP drive, running MacOSX 10.1) eight Windows 2000 computers (each with Pentium III 931 MHz CPU and 256 MB RAM) Instructors Prof. Brian A. Barsky Office: 785 Soda Hall Phone: (510) 642-9838 E-mail: [email protected] Office hours: Monday 1 pm to 3 pm Laurence Arcadias Office: 329 Soda Hall Phone: (510) 642-9827; 643-4207 E-mail: E-mail: [email protected] Office hours: Monday 1 pm to 3 pm Course Summary This hands-on animation course is intended for students with a computer science background who would like to improve their sense of observation, timing, and motion through the real art of animation to create strong believable animation pieces. A good understanding of motion is an important foundation for using computers and technology to their full potential for the creation of animation. -

Nutzung Der Game Engine Unity Als Charakter-Animationstool Für Filmproduktion
Nutzung der Game Engine Unity als Charakter-Animationstool für Filmproduktion Eva-Maria Hobl MASTERARBEIT eingereicht am Fachhochschul-Masterstudiengang Digital Arts in Hagenberg im Januar 2020 Betreuung: Designer FH Alexander Wilhelm ii © Copyright 2020 Eva-Maria Hobl Diese Arbeit wird unter den Bedingungen der Creative Commons Lizenz Attribution- NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) veröffentlicht – siehe https://creativecommons.org/licenses/by-nc-nd/4.0/. iii Erklärung Ich erkläre eidesstattlich, dass ich die vorliegende Arbeit selbstständig und ohne fremde Hilfe verfasst, andere als die angegebenen Quellen nicht benutzt und die den benutzten Quellen entnommenen Stellen als solche gekennzeichnet habe. Die Arbeit wurde bisher in gleicher oder ähnlicher Form keiner anderen Prüfungsbehörde vorgelegt. Hagenberg, am 22. Januar 2020 Eva-Maria Hobl iv Gender Erklärung Aus Gründen der besseren Lesbarkeit wird in dieser Arbeit die Sprachform des ge- nerischen Maskulinums angewendet. Es wird an dieser Stelle darauf hingewiesen, dass die ausschließliche Verwendung der männlichen Form geschlechtsunabhängig verstanden werden soll. v Inhaltsverzeichnis Erklärung iv Gender Erklärung v Kurzfassung viii Abstract ix 1 Einleitung 1 1.1 Fragestellung . .2 1.2 Methodik . .2 2 Grundlagen von Rigging und Animation 3 2.1 Rigging . .3 2.2 Keyframe Animation . .4 2.3 Motion Capture . .6 3 Machinima 7 3.1 Videospiel Machinima . .8 3.2 Software Machinima . .9 3.3 Source Filmmaker ..............................9 4 Animation in Videospielen 11 4.1 Dialog Szenen in The Witcher 3: Wild Hunt ................ 12 4.2 Cinematics in World of Warcraft ...................... 14 4.3 Meet the Team: Teaser für Team Fortress 2 ................ 16 5 Charakter-Animation in Unity 19 5.1 Rigs . -

18-Animation.Pdf
Advertisement Computer Animation Adam Finkelstein Princeton University COS 426, Spring 2003 Computer Animation 3-D and 2-D animation • What is animation? o Make objects change over time according to scripted actions • What is simulation? Pixar o Predict how objects change over time according to physical laws Homer 3-D Homer 2-D University of Illinois Outline Principles of Traditional Animation • Principles of animation • Squash and stretch • Keyframe animation • Slow In and out • Anticipation • Articulated figures • Exaggeration • Kinematics • Follow through and overlapping action • Timing •Dynamics • Staging • Straight ahead action and pose-to-pose action •Arcs • Secondary action • Appeal Angel Plate 1 Disney 1 Principles of Traditional Animation Principles of Traditional Animation • Squash and stretch • Slow In and Out Lasseter `87 Watt Figure 13.5 Principles of Traditional Animation Principles of Traditional Animation • Anticipation (and squash & stretch) • Squash and stretch • Slow In and out • Anticipation • Exaggeration • Follow through and overlapping action • Timing • Staging • Straight ahead action and pose-to-pose action •Arcs • Secondary action • Appeal Lasseter `87 Disney Computer Animation Keyframe Animation Animation pipeline • Define character poses at specific time steps o 3D modeling called “keyframes” o Articulation o Motion specification o Motion simulation o Shading o Lighting o Rendering o Postprocessing » Compositing Pixar Lasseter `87 2 Keyframe Animation Keyframe Animation • Interpolate variables describing keyframes -

Animation-Insiders-Ebook-Web.Pdf
ANIMATION INSIDERS W orkflow e dition ACKNOWLEDGEMENT/ 5 INTRODUCTION/ 7 MIKE NGUYEN 8 EMILE GHORAYEB 12 PABLO NAVARRO 16 JASON RYAN 40 JASON MORTINSEN 46 ANA MARIA ALVARADO 50 RENO ARMANET 54 JASON SCHLEIFER 70 PEDRO BLUMENBAUM 76 ANTHEA KEROU 88 GABRIELE PENNACCHIOLI 92 MATT STRANGIO 94 VICTOR NAVONE 102 CONCLUSION/ 107 LIST OF CONTENT SPECIAL THANKS/ 109 ACKNOWLEDGEMENT/ 5 INTRODUCTION/ 7 MIKE NGUYEN 8 EMILE GHORAYEB 12 PABLO NAVARRO 16 JASON RYAN 40 JASON MORTINSEN 46 ANA MARIA ALVARADO 50 RENO ARMANET 54 JASON SCHLEIFER 70 PEDRO BLUMENBAUM 76 ANTHEA KEROU 88 GABRIELE PENNACCHIOLI 92 MATT STRANGIO 94 VICTOR NAVONE 102 CONCLUSION/ 107 LIST OF CONTENT SPECIAL THANKS/ 109 I would like to extend our most sincere thanks to the extraordinary ani- mators who were involved with this book. You generously shared with us your knowledge and vision about animation. Your passion for what you do easily shows, and without you, Animation Insiders would never have seen the light of day. Thank you PATRICK BEAULIEU ACKNOWLEDGEMENTS ANIMATION INSIDERS / ANIMATION LEDGEMENTS ACKNOW- 4 5 I would like to extend our most sincere thanks to the extraordinary ani- mators who were involved with this book. You generously shared with us your knowledge and vision about animation. Your passion for what you do easily shows, and without you, Animation Insiders would never have seen the light of day. Thank you ACKNOWLEDGEMENTS PATRICK BEAULIEU ACKNOWLEDGEMENTS ANIMATION INSIDERS / ANIMATION LEDGEMENTS ACKNOW- LEDGEMENTS 4 5 When I was in school, it was very difficult to get valuable learning mate- It is still incumbent on you to formulate good ideas for your shots. -

Physics-Based Character Locomotion Control with Large Simulation Time Steps
Physics-based Character Locomotion Control with Large Simulation Time Steps David Andrew Greer October, 2015 Bournemouth University A dissertation submitted in partial fulfillment of the requirements for the degree of Engineering Doctorate 2 This copy of the thesis has been supplied on condition that anyone who consults it is understood to recognise that its copyright rests with its author and due acknowledgement must always be made of the use of any material contained in, or derived from, this thesis. 2 Abstract Physical simulated locomotion allows rich and varied interactions with environments and other characters. However, control is difficult due to factors such as a typical character's numerous degrees of freedom and small stability region, discontinuous ground contacts, and indirect control over the centre of mass. Previous academic work has made significant progress in addressing these problems, but typically uses simulation time steps much smaller than those suitable for games. This project deals with developing control strategies using larger time steps. After describing some introductory work showing the difficulties of implementing a handcrafted controller with large physics time steps, three major areas of work are discussed. The first area uses trajectory optimization to minimally alter reference motions to ensure physical validity, in order to improve simulated tracking. The approach builds on previous work which allows ground contacts to be modified as part of the optimization process, extending it to 3D problems. Incorporating contacts introduces difficult complementarity constraints, and an exact penalty method is shown here to improve solver robustness and performance compared to previous relaxation methods. Trajectory optimization is also used to modify reference motions to alter characteristics such as timing, stride length and heading direction, whilst maintaining physical validity, and to generate short transitions between existing motions.