Using Machine Learning for Detection of Hate Speech and Offensive Code-Mixed Social Media Text
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Dravidian Languages
THE DRAVIDIAN LANGUAGES BHADRIRAJU KRISHNAMURTI The Pitt Building, Trumpington Street, Cambridge, United Kingdom The Edinburgh Building, Cambridge CB2 2RU, UK 40 West 20th Street, New York, NY 10011–4211, USA 477 Williamstown Road, Port Melbourne, VIC 3207, Australia Ruiz de Alarc´on 13, 28014 Madrid, Spain Dock House, The Waterfront, Cape Town 8001, South Africa http://www.cambridge.org C Bhadriraju Krishnamurti 2003 This book is in copyright. Subject to statutory exception and to the provisions of relevant collective licensing agreements, no reproduction of any part may take place without the written permission of Cambridge University Press. First published 2003 Printed in the United Kingdom at the University Press, Cambridge Typeface Times New Roman 9/13 pt System LATEX2ε [TB] A catalogue record for this book is available from the British Library ISBN 0521 77111 0hardback CONTENTS List of illustrations page xi List of tables xii Preface xv Acknowledgements xviii Note on transliteration and symbols xx List of abbreviations xxiii 1 Introduction 1.1 The name Dravidian 1 1.2 Dravidians: prehistory and culture 2 1.3 The Dravidian languages as a family 16 1.4 Names of languages, geographical distribution and demographic details 19 1.5 Typological features of the Dravidian languages 27 1.6 Dravidian studies, past and present 30 1.7 Dravidian and Indo-Aryan 35 1.8 Affinity between Dravidian and languages outside India 43 2 Phonology: descriptive 2.1 Introduction 48 2.2 Vowels 49 2.3 Consonants 52 2.4 Suprasegmental features 58 2.5 Sandhi or morphophonemics 60 Appendix. Phonemic inventories of individual languages 61 3 The writing systems of the major literary languages 3.1 Origins 78 3.2 Telugu–Kannada. -

Identity and Language of Tamil Community in Malaysia: Issues and Challenges
DOI: 10.7763/IPEDR. 2012. V48. 17 Identity and Language of Tamil Community in Malaysia: Issues and Challenges + + + M. Rajantheran1 , Balakrishnan Muniapan2 and G. Manickam Govindaraju3 1Indian Studies Department, University of Malaya, Kuala Lumpur, Malaysia 2Swinburne University of Technology, Sarawak, Malaysia 3School of Communication, Taylor’s University, Subang Jaya, Malaysia Abstract. Malaysia’s ruling party came under scrutiny in the 2008 general election for the inability to resolve pressing issues confronted by the minority Malaysian Indian community. Some of the issues include unequal distribution of income, religion, education as well as unequal job opportunity. The ruling party’s affirmation came under critical situation again when the ruling government decided against recognising Tamil language as a subject for the major examination (SPM) in Malaysia. This move drew dissatisfaction among Indians, especially the Tamil community because it is considered as a move to destroy the identity of Tamils. Utilising social theory, this paper looks into the fundamentals of the language and the repercussion of this move by Malaysian government and the effect to the Malaysian Indians identity. Keywords: Identity, Tamil, Education, Marginalisation. 1. Introduction Concepts of identity and community had been long debated in the arena of sociology, anthropology and social philosophy. Every community has distinctive identities that are based upon values, attitudes, beliefs and norms. All identities emerge within a system of social relations and representations (Guibernau, 2007). Identity of a community is largely related to the race it represents. Race matters because it is one of the ways to distinguish and segregate people besides being a heated political matter (Higginbotham, 2006). -

A Study on Divergence in Malayalam and Tamil Language in Machine Translation Perceptive
A Study on Divergence in Malayalam and Tamil Language in Machine Translation Perceptive Jisha P Jayan Elizabeth Sherly Virtual Resource Centre for Virtual Resource Centre for Language Computing Language Computing IIITM-K,Trivandrum IIITM-K,Trivandrum [email protected] [email protected] Abstract others are specific with respect to the language pair (Lavanya et al., 2005; Saboor and Khan, Machine Translation has made significant 2010). Hence, the divergence in the translation achievements for the past decades. How- need to be studied both perspectives that is across ever, in many languages, the complex- the languages and language specific pair (Sinha, ity with its rich inflection and agglutina- 2005).The most problematic area in translation is tion poses many challenges, that forced the lexicon and the role it plays in the act of creat- for manual translation to make the cor- ing deviations in sense and reference based on the pus available. The divergence in lexi- context of its occurrence in texts (Dash, 2013). cal, syntactic and semantic in any pair Indian languages come under Indo-Aryan or of languages makes machine translation Dravidian scripts. Though there are similarities more difficult. And many systems still de- in scripts, there are many issues and challenges pend on rules heavily, that deteriates sys- in translation between languages such as lexical tem performance. In this paper, a study divergences, ambiguities, lexical mismatches, re- on divergence in Malayalam-Tamil lan- ordering, syntactic and semantic issues, structural guages is attempted at source language changes etc. Human translators try to choose the analysis to make translation process easy. -
Introduction to Brahui
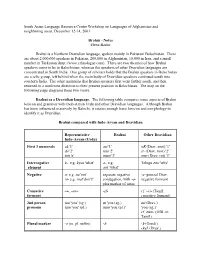
South Asian Language Resource Center Workshop on Languages of Afghanistan and neighboring areas, December 12-14, 2003 Brahui - Notes Elena Bashir Brahui is a Northern Dravidian language, spoken mainly in Pakistani Balochistan. There are about 2,000,000 speakers in Pakistan, 200,000 in Afghanistan, 10,000 in Iran, and a small number in Turkestan (http://www.ethnologue.com). There are two theories of how Brahui speakers come to be in Balochistan, whereas the speakers of other Dravidian languages are concentrated in South India. One group of scholars holds that the Brahui speakers in Balochistan are a relic group, left behind when the main body of Dravidian speakers continued south into southern India. The other maintains that Brahui speakers first went farther south, and then returned in a northwest direction to their present position in Balochistan. The map on the following page diagrams these two views. Brahui as a Dravidian language. The following table compares some aspects of Brahui lexicon and grammar with Indo-Aryan Urdu and other Dravidian languages. Although Brahui has been influenced massively by Balochi, it retains enough basic lexicon and morphology to identify it as Dravidian. Brahui compared with Indo-Aryan and Dravidian Representative Brahui Other Dravidian Indo-Aryan (Urdu) First 3 numerals ek '1' asi '1' oR (Drav. root) '1' do '2' iraa '2' ir- (Drav. root) '2' tiin 'e' musi '3' mur (Drav. rot) '3' Interrogative k-, e.g. kyaa 'what' a-, e.g. Telugu emi 'why' element ant 'what' Negative n- e.g. na 'not' separate negative -a- general Drav. m- e.g. -

Neo-Vernacularization of South Asian Languages
LLanguageanguage EEndangermentndangerment andand PPreservationreservation inin SSouthouth AAsiasia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 Language Endangerment and Preservation in South Asia ed. by Hugo C. Cardoso Language Documentation & Conservation Special Publication No. 7 PUBLISHED AS A SPECIAL PUBLICATION OF LANGUAGE DOCUMENTATION & CONSERVATION LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA Special Publication No. 7 (January 2014) ed. by Hugo C. Cardoso LANGUAGE DOCUMENTATION & CONSERVATION Department of Linguistics, UHM Moore Hall 569 1890 East-West Road Honolulu, Hawai’i 96822 USA http:/nflrc.hawaii.edu/ldc UNIVERSITY OF HAWAI’I PRESS 2840 Kolowalu Street Honolulu, Hawai’i 96822-1888 USA © All text and images are copyright to the authors, 2014 Licensed under Creative Commons Attribution Non-Commercial No Derivatives License ISBN 978-0-9856211-4-8 http://hdl.handle.net/10125/4607 Contents Contributors iii Foreword 1 Hugo C. Cardoso 1 Death by other means: Neo-vernacularization of South Asian 3 languages E. Annamalai 2 Majority language death 19 Liudmila V. Khokhlova 3 Ahom and Tangsa: Case studies of language maintenance and 46 loss in North East India Stephen Morey 4 Script as a potential demarcator and stabilizer of languages in 78 South Asia Carmen Brandt 5 The lifecycle of Sri Lanka Malay 100 Umberto Ansaldo & Lisa Lim LANGUAGE ENDANGERMENT AND PRESERVATION IN SOUTH ASIA iii CONTRIBUTORS E. ANNAMALAI ([email protected]) is director emeritus of the Central Institute of Indian Languages, Mysore (India). He was chair of Terralingua, a non-profit organization to promote bi-cultural diversity and a panel member of the Endangered Languages Documentation Project, London. -

Kodrah Kristang: the Initiative to Revitalize the Kristang Language in Singapore
Language Documentation & Conservation Special Publication No. 19 Documentation and Maintenance of Contact Languages from South Asia to East Asia ed. by Mário Pinharanda-Nunes & Hugo C. Cardoso, pp.35–121 http:/nflrc.hawaii.edu/ldc/sp19 2 http://hdl.handle.net/10125/24906 Kodrah Kristang: The initiative to revitalize the Kristang language in Singapore Kevin Martens Wong National University of Singapore Abstract Kristang is the critically endangered heritage language of the Portuguese-Eurasian community in Singapore and the wider Malayan region, and is spoken by an estimated less than 100 fluent speakers in Singapore. In Singapore, especially, up to 2015, there was almost no known documentation of Kristang, and a declining awareness of its existence, even among the Portuguese-Eurasian community. However, efforts to revitalize Kristang in Singapore under the auspices of the community-based non-profit, multiracial and intergenerational Kodrah Kristang (‘Awaken, Kristang’) initiative since March 2016 appear to have successfully reinvigorated community and public interest in the language; more than 400 individuals, including heritage speakers, children and many people outside the Portuguese-Eurasian community, have joined ongoing free Kodrah Kristang classes, while another 1,400 participated in the inaugural Kristang Language Festival in May 2017, including Singapore’s Deputy Prime Minister and the Portuguese Ambassador to Singapore. Unique features of the initiative include the initiative and its associated Portuguese-Eurasian community being situated in the highly urbanized setting of Singapore, a relatively low reliance on financial support, visible, if cautious positive interest from the Singapore state, a multiracial orientation and set of aims that embrace and move beyond the language’s original community of mainly Portuguese-Eurasian speakers, and, by design, a multiracial youth-led core team. -

La in Simple Sentences Among Indian Ethnic Group in Malaysia
ISSN 2039-2117 (online) Mediterranean Journal of Social Sciences Vol 6 No 6 S2 ISSN 2039-9340 (print) MCSER Publishing, Rome-Italy November 2015 Use of –la in Simple Sentences among Indian Ethnic group in Malaysia Dr. Franklin Thambi Jose. S Senior Lecturer, Faculty of Languages and Communication, Sultan Idris Education University, Malaysia [email protected] Doi:10.5901/mjss.2015.v6n6s2p122 Abstract Language is the ability of expressing ideas or thoughts of one’s own. It varies according to the social structure of a local speech community. Moreover it expresses a group identity. The group can be a community, ethnicity, class or caste. A group of people who live in Malaysia speak Tamil and they are called as Indian ethnic group. This group includes Hindi, Telugu and Malayalam speakers. They form 7.1% (National Census, 2000) of the total population. In Indian ethnic group, Tamil forms the largest subgroup (5.7%). Although other language speakers are included in Indian ethnic group, it represents Tamil speakers. This group (subgroup) use –la when they speak Tamil language. Its literary meaning is ‘dear’ in English. According to Baron (1986) the minority language in a larger social group differs in pronunciation, usage, etc. Since Tamil group is living with Malay language speaking people, the usage of –la came to exit and is unavoidable. –la is used in simple sentences in different contexts. The different contexts are identified such as usage of simple sentences between friends, students, husband and wife, parents and children and immigrants. For example: vaa-la naaam poovoom. ‘come dear, we shall go’ (used between friends) The major objective of this paper is to analyse the usage of –la linguistically in simple sentences. -

Resolving Pronouns for a Resource-Poor Language, Malayalam Using Resource-Rich Language, Tamil
Resolving Pronouns for a Resource-Poor Language, Malayalam Using Resource-Rich Language, Tamil Sobha Lalitha Devi AU-KBC Research Centre, Anna University, Chennai [email protected] Abstract features. If the resources available in one language (henceforth referred to as source) can be used to In this paper we give in detail how a re- facilitate the resolution, such as anaphora, for all source rich language can be used for resolv- the languages related to the language in question ing pronouns for a less resource language. (target), the problem of unavailability of resources The source language, which is resource rich would be alleviated. language in this study, is Tamil and the re- There exists a recent research paradigm, in which source poor language is Malayalam, both the researchers work on algorithms that can rap- belonging to the same language family, idly develop machine translation and other tools Dravidian. The Pronominal resolution de- for an obscure language. This work falls into this veloped for Tamil uses CRFs. Our approach paradigm, under the assumption that the language is to leverage the Tamil language model to test Malayalam data and the processing re- in question has a less obscure sibling. Moreover, quired for Malayalam data is detailed. The the problem is intellectually interesting. While similarity at the syntactic level between the there has been significant research in using re- languages is exploited in identifying the sources from another language to build, for exam- features for developing the Tamil language ple, parsers, there have been very little work on model. The word form or the lexical item is utilizing the close relationship between the lan- not considered as a feature for training the guages to produce high quality tools such as CRFs. -

Coining Words Language and Politics in Late Colonial Tamilnadu
CHAPTER 8 Coining Words Language and Politics in Late Colonial Tamilnadu Forming words with Sanskrit roots will certainly ruin the beauty and growth of the Tamil language and disfigure it; and is sure to inflame communal hatred. —E. M. Subramania Pillai to Government of Madras, Memorandum, 5 September 1941. Though a common terminology may be possible in Northern India where Hindustani and Sanskrit have mingled together very much and local lan- guages have been greatly modified by them, such a terminology would be unsuited to the Tamil area where Tamils have preserved the purity of their language. Words coined must have Tamil roots and suffixes to make them intelligible to the Tamils. —Memorandum submitted by the Committee of Educationists to the Government of Madras, 22 August 1941. Some months ago, there raged in the academic world, a controversy regard- ing the coining of technical terms. While some said that there should be no bar on borrowing terms from other languages to express new scientific disciplines, others argued that only pure Tamil terms should be used.... [This] has raged since the beginnings of the Tamil language. But, in earlier days, it was not conducted by opposite camps; there were no acrimonious polemics; there was nobody to say 'Our language is ruined by the admix- ture of other languages; we should have a Protection Brigade to safeguard our language' and so on. —S. Vaiyapuri Pillai, Sorkalai Virundu, Madras, 1956, p. 31 (originally published in Dinamani, 10 May 1947). Drawing on Raymond Williams' formulation in his classic Key- words, that 'important social and historical processes occur within language',1 this chapter seeks to explore the cultural politics 144 In Those Days There Was tio Coffee Coining Words 145 surrounding the coining of technical and scientific terms for Bharati's views are typical of the nationalist perspective, which pedagogic purposes in late colonial Tamilnadu. -

The Dravidian Languages
This page intentionally left blank THE DRAVIDIAN LANGUAGES The Dravidian languages are spoken by over 200 million people in South Asia and in diaspora communities around the world, and constitute the world’s fifth largest language family. It consists of about twenty-six lan- guages in total including Tamil, Malay¯alam,. Kannada. and Telugu,as well as over twenty non-literary languages. In this book, Bhadriraju Krishnamurti, one of the most eminent Dravidianists of our time and an Honorary Member of the Linguistic Society of America, provides a comprehensive study of the phonological and grammatical structure of the whole Dravidian family from different aspects. He describes its history and writing system, dis- cusses its structure and typology, and considers its lexicon. Distant and more recent contacts between Dravidian and other language groups are also discussed. With its comprehensive coverage this book will be welcomed by all students of Dravidian languages and will be of interest to linguists in various branches of the discipline as well as Indologists. is a leading linguist in India and one of the world’s renowned historical and comparative linguists, specializing in the Dravidian family of languages. He has published over twenty books in English and Telugu and over a hundred research papers. His books include Telugu Verbal Bases: a Comparative and Descriptive Study (1961), Kon. da. or K¯ubi, a Dravidian Language (1969), A Grammar of Modern Telugu (with J. P. L. Gwynn, 1985), Language, Education and Society (1998) and Comparative Dravidian Linguistics: Current Perspectives (2001). CAMBRIDGE LANGUAGE SURVEYS General editors P. Austin (University of Melbourne) J. -

Karnataka Bypolls Deferred
Follow us on: RNI No. TELENG/2018/76469 @TheDailyPioneer facebook.com/dailypioneer Established 1864 Published From ANALYSIS 9 CELEB TALKS 14 SPORTS 16 HYDERABAD DELHI LUCKNOW DARK DAYS ARE CHARLIE'S ANGELS RAHANE BACKS ROHIT BHOPAL RAIPUR CHANDIGARH AHEAD FOR INDIA READY FOR INDIA FOR NEW ROLE BHUBANESWAR RANCHI DEHRADUN VIJAYAWADA *LATE CITY VOL. 1 ISSUE 354 HYDERABAD, FRIDAY SEPTEMBER 27, 2019; PAGES 16 `3 *Air Surcharge Extra if Applicable NAG TO INTRODUCE ANOTHER DIRECTOR { Page 13 } www.dailypioneer.com BRKR BHAVAN NO PLUG AND PLAY OFFICE Karnataka bypolls deferred Ad hoc ‘Secretariat' l Till top court decides on disqualified MLAs l Cong says unprecedented PNS n NEW DELHI Both parties had expelled the rebels. There were also reports conditions insanely bad By-elections to 15 assembly that the MLAs were offered seats in Karnataka -- where ministerial berths by the BJP. NAVEENA GHANATE the MLAs were disqualified Earlier this year, 13 MLAs n HYDERABAD Plethora of work in progress leaves ambience messy earlier this year for rebelling from the Congress and three Gen Rawat to and bringing down the earli- from the JDS had resigned, Long queues at elevators, masks er Congress-JDS government and two Independent law- on the nose and old furniture head Chiefs - will be deferred. The makers who were supporting lying all around are what visi- Election Commission today the government switched tors see as they enter Burgula told the Supreme Court that sides, bringing down the num- Ramakrishna Rao (BRKR) of Staff panel it has decided to postpone the bers of the government. After Bhavan premises. -

Indian Entertainment and Media Outlook
pwc.com/india Indian entertainment and media outlook Indian entertainment and media outlook 2009 2009 © 2009 PricewaterhouseCoopers. All rights reserved. “PricewaterhouseCoopers”, a registered trademark, refers to PricewaterhouseCoopers Private Limited (a limited company in India) or, as the context requires, other member firms of PricewaterhouseCoopers International Limited, each of which is a separate and independent legal entity. About PricewaterhouseCoopers PricewaterhouseCoopers Pvt. Ltd. (www.pwc.com/india) provides industry - focused tax and advisory services to build public trust and enhance value for its clients and their stakeholders. PwC professionals work collaboratively using connected thinking to develop fresh perspectives and practical advice. Complementing our depth of industry expertise and breadth of skills is our sound knowledge of the local business environment in India. PricewaterhouseCoopers is committed to working with our clients to deliver the solutions that help them take on the challenges of the ever-changing business environment. PwC has offices in Ahmedabad, Bangalore, Bhubaneshwar, Chennai, Delhi NCR, Hyderabad, Kolkata, Mumbai and Pune. Contents Introduction................................................................................................................................... 4 Executive Summary ..................................................................................................................... 5 Television ..................................................................................................................................