All of the People, All of the Time: an Analysis of Public Reaction to the Use of Deception by Political Elites
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Donald J Trump: Nh Ững Điều C Ần Bi Ết Vĩnh T Ường
Th ời s ự Chính tr ị Mỹ Sưu t ầm - về Ông “Đô-la-Trâm” Donald J Trump: Nh ững Điều C ần Bi ết Vĩnh T ường Đúng v ậy! Có nhi ều ng ười b ảo r ằng tôi là th ường dân; tôi không c ần chính “ch ị” chính em gì c ả; tôi ch ỉ bầu cho b ất k ỳ ai trong đảng mà lâu nay tôi tin. Th ế có ngh ĩa là không c ần phán đoán, ch ọn lựa gì c ả vì đã có ng ười ch ọn s ẵn cho r ồi. Và b ầu c ử còn có ý ngh ĩa gì vì nó ch ẳng khác ở Vi ệt nam sau 1975 đến gi ờ! L ại có ng ười tin r ằng “th ường dân không làm chính tr ị”. Có đúng không n ếu nói r ằng ng ười dân không bao gi ờ ra kh ỏi xã h ội, không bao gi ờ ra kh ỏi sự chi phối sinh ho ạt hàng ngày trong khung c ảnh xã h ội d ưới th ể ch ế chính tr ị nh ất định mà họ đang s ống? N ếu câu tr ả lời là “Đúng” thì đã rõ m ỗi ng ười chúng ta không th ể không quan tâm đến v ấn đề chính tr ị, xã h ội chung quanh ta, tr ừ khi chúng ta t ừ bỏ hết nh ững gì thu ộc v ề chúng ta, đó chính là quy ền s ống an bình, th ịnh vượng và h ạnh phúc mà b ất k ỳ ai trong chúng ta c ũng đều hàng gi ờ đeo đuổi. -

Into Aspohyxiated
1! INTO ASPHYXIATED AIR Part 1: My Empathy Trek with The Trump Voter Vincent Greenwood, Ph.D., Executive Director “I hoped something would be gained by spilling my soul in the calamity’s immediate after- math, in the roil and torment of the moment… it hasn’t, of course.” -Jon Krakauer from Into Thin Air In 1996, 630 climbers attempted to reach the summit of Mt. Everest and 155 died. On May 10 of that year alone, 9 died, marking it as the deadliest day in the history of mountaineer- ing. On that day at 1pm, Jon Krakauer, a climber and journalist, stood on the summit, one foot in 2! China, one in Nepal. He had been hired by Outsider magazine to write a story about a growing trend: the development of commercial climbing expeditions, which many in the serious climbing community derisively termed the “monetization” of Everest. There is no question that the rivalry between such for-profit enterprises opened the door to amateurism, compromised safety procedures, and encouraged greed, hubris and poor judg- ment, borne of the need to deliver the goods (securing the summit) because the price was so steep: 65 grand back then, mostly ponied up by wealthy Western clients, some with scant climb- ing experience. On that ill-fated day, five such expeditions were zeroing in on the summit. Bot- tlenecks were created which exacerbated organizational and communication problems, certainly a key factor in the disaster that developed that day. Krakauer gazed at the vista below, the Tibetan Plateau, and beyond, where one can dis- cern the curvature of the Earth. -

Trump's New Face of Power in America
Trump’s New Face of Power in America (updated and revised June 2021) Bob Hanke1 York University, Toronto, Canada Abstract: This article proposes that the advent of Trumpism was an historical moment of danger that compels us to analyze the micropolitics of the present. In the first part, I describe the constellation that gave rise to Trumpism. In the second part, I recall Goffman’s concept of face-work and discuss how it remains relevant for describing Trump’s aggressive face-work. In the third part, I take Deleuze and Guattari’s concept of faciality as a point of departure for understanding micro- fascism. As an abstract machine, Trump’s faciality engendered and diffused fascisizing micropolitics around a messenger/disrupter in chief. It worked in connection with a landscape and relative to a collective assemblage of enunciation that extracted a territory of perception and affect. In the micropolitics of the present, the defining feature of Trumpism was how the corrupt abuse of power and the counterforces limiting his potency collided on an ominous, convulsive political reality TV show that threatened US democracy. Keywords: Trumpism, face-work, faciality, assemblage, micropolitics, impeachment, coronavirus pandemic We are all sufferers from history, but the paranoid is a double sufferer, since he is afflicted not only by the real world, with the rest of us, but by his fantasies as well. – Richard Hofstadter (1964) When a man unprincipled in private life desperate in his fortune, bold in his temper, possessed of considerable talents, -

Is Manipulation Within the Construct of Reality Television Ethical? Cheryl-Anne Whitlock University of Wollongong
University of Wollongong Research Online University of Wollongong Thesis Collection University of Wollongong Thesis Collections 2012 Is manipulation within the construct of reality television ethical? Cheryl-Anne Whitlock University of Wollongong Recommended Citation Whitlock, Cheryl-Anne, Is manipulation within the construct of reality television ethical?, Master of Arts - Research (Journalism) thesis, School of Creative Arts, University of Wollongong, 2012. http://ro.uow.edu.au/theses/3967 Research Online is the open access institutional repository for the University of Wollongong. For further information contact the UOW Library: [email protected] Is Manipulation within the Construct of Reality Television Ethical? A thesis submitted in fulfilment of the requirements for the award of the degree Master of Arts by Research (Journalism) from University of Wollongong by Cheryl-Anne Whitlock School of Creative Arts 2012 i Certification I, Cheryl-Anne Whitlock, declare that this thesis, submitted in partial fulfilment of the requirements for the award of Master of Arts by Research (Journalism), in the Faculty of Law, Humanities and The Arts, University of Wollongong, is wholly my own work unless otherwise referenced or acknowledged. The document has not been submitted for qualifications at any other academic institution. Cheryl-Anne Whitlock 16 February 2012 ii Abstract The main purpose of the thesis is to determine to what extent duty of care is extended to reality television participants, to what extent elements of reality television programming are manipulated and whether those manipulations are ethical. Program participants are encouraged to be their ‘real’ and authentic selves, yet reality programming itself is often so extensively manipulated that the genre renders its own output inauthentic, thus compromising participants’ contributions and casting their performance in the same false light. -

The Presidential Performance
THE PRESIDENTIAL PERFORMANCE: SECURITIZATION THEORY, AESTHETIC TURN, AND OUTSIDER LEGITIMACY By Matěj Voda Submitted to Central European University Department of International Relations In partial fulfillment of the requirements for the degree of Master of Arts Supervisor: Professor Paul Roe Word Count: 11,844 CEU eTD Collection Budapest, Hungary 2020 Abstract Since its original formulation by the Copenhagen School, the securitization theory received significant attention as an innovative way to analyze issues of security. As it was originally formulated, securitization scholars highlighted how our understanding of security is socially constructed and analyzed various speech acts through which securitizing actors try to acquire the assent of a relevant audience for the adoption of extraordinary measures. Yet, it has been argued that this specific framework has its limitations. In this thesis, I focus on three blind spots, which are embedded in the theory’s focus on speech, the politics of exception, and the under-developed concept of the audience. In contrast, this thesis seeks to put forward an understanding of securitization that draws on the insights from the so-called aesthetic turn in international relations. First, instead of speech, I focus on politics as multisensory. Second, instead of the language of urgency and extraordinary measures, I focus on popular culture seen as part of the politics of the everyday. Third, instead of assuming securitizing actors and audiences as established categories, I analyze how they were performed into being. Instead of asking: how do security problems emerge? I elaborate on the question: how do securitizing actors emerge? I argue that once securitizing actors acquire the legitimacy to speak on security issues, they have already gained a privileged position in the intersubjective field of power. -

The Magic of Donald Trump by Mark Danner | the New York Review of Books
5/11/2016 The Magic of Donald Trump by Mark Danner | The New York Review of Books The Magic of Donald Trump Mark Danner MAY 26, 2016 ISSUE Crippled America: How to Make America Great Again by Donald J. Trump Threshold, 193 pp., $25.00 Like Hercules, Donald Trump is a work of fiction.1 Primed for miracles and wonders, Trumpsters in their thousands tilt their heads up toward the blueblack Florida sky. Behind the approaching thwackthwackthwack the electronic fanfare soars and above it now we hear the booming carnival barker’s comeon: “Now arriving out of the northwest sky, DONALD…J… TRUMP!” Thousands of upturned mouths gape as the three floating lights, turning slowly, majestically resolve themselves into the shape of the big helicopter, the inevitable TRUMP in signature AkzidenzGrotesk font just visible on its tail. Six thousand roaring voices—or is it seven thousand, or eight, or nine?—crash in a wave of sound against the raucous electrobrass salute. The earsplitting blare is the theme to Air Force One, a cheesy late1990s hit starring Harrison Ford as MedalofHonorwinning President James Marshall, whose Boeing is seized by terrorists. (President Marshall growling to an abouttobedefenestrated terrorist: “Get off my plane!”) Can one imagine any other candidate using this as theme music? For Ted Cruz or John Kasich or any of the fourteen others who have wandered on and then off the stage, the irony—the lack of self Donald Trump; drawing by James Ferguson seriousness—would be unendurable. -

Never Has Trump Ever … 1
NEVER HAS TRUMP EVER … 1. Misspelled “unprecedented” as “unpresidented.” • ANSWER: GUILTY • SOURCE: “Donald Trump accuses China of ‘unpresidented’ act over US navy drone” (The Guardian) 2. Said he is a “self-made millionaire.” • ANSWER: NOT GUILTY • SOURCE: “Donald Trump describes father’s ‘small loan’: $1 million” (CNN) 3. Tweeted over 100 times in a day. • ANSWER: GUILTY • SOURCE: “Trump appears to set personal record for tweets in a day” (The Hill) 4. Written a Time Magazine tribute to Hillary Clinton. • ANSWER: NOT GUILTY (Senator Lindsey Graham wrote Hilary Clinton a Time Magazine tribute in 2006!) • SOURCE: Hilary Clinton on Lindsey Graham: ‘It’s like he had a brain snatch” (Politico) 5. Tweeted “READ THE TRANSCRIPTS.” • ANSWER: GUILTY • SOURCE: @realDonaldTrump’s tweet on January 21st, 2020 (Twitter) 6. Cyber-bullied a teen, environmental activist. • ANSWER: GUILTY • SOURCE: @realDonaldTrump’s tweet on December, 19th, 2020 (Twitter) 7. Tweeted Justice Kavanaugh should sue people for “liable” rather than “libel.” • ANSWER: GUILTY • SOURCE: “Trump stands up for Brett Kavanaugh over ‘liable’” (Politico) 8. Been the only president to not release their tax returns. • ANSWER: GUILTY • SOURCE: “Presidential tax returns: It started with Nixon. Will it end with Trump?” (CNN) 9. Started a sentence with “I’m not a doctor, but…” • ANSWER: GUILTY • SOURCE: “Trump promotes use of drug for coronavirus: ‘I’m not a doctor. But I have common sense’” (The Hill) 10. Said climate change is “fake news.” • ANSWER: GUILTY • SOURCE: “Trump tweets climate change skeptic in latest denial of science” (CNN) 11. Said global warming was created by the Chinese. • ANSWER: GUILTY • SOURCE: “Trump didn’t delete his tweet calling global warming a Chinese hoax” (The Washington Post) 12. -
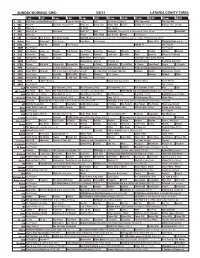
Sunday Morning Grid 5/6/12 Latimes.Com/Tv Times
SUNDAY MORNING GRID 5/6/12 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Morning (N) Å Face the Nation (N) Paid The Players Club (N) AMA Supercross PGA Tour Golf 4 NBC News Å Meet the Press (N) Å News (N) Babar (TVY) Willa’s Wild Pearlie Cycling Giro d’Italia. Hockey: Blues at Kings 5 CW News (N) Å In Touch Paid Program 7 ABC News (N) Å This Week News (N) NBA Basketball Chicago Bulls at Philadelphia 76ers. (N) Å Basketball 9 KCAL News (N) Prince Mike Webb Joel Osteen Shook Paid Program 11 FOX D. Jeremiah Joel Osteen Fox News Sunday NASCAR Racing Sprint Cup: Aaron’s 499. From Talladega Superspeedway in Talladega, Ala. (N) Å 13 MyNet Paid Tomorrow’s Paid Program Best Buys Paid Program Hates Chris Changing Lanes ››› 18 KSCI Paid Hope Hr. Church Paid Program Iranian TV Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Sid Science Curios -ity Thomas Bob Builder Joy of Paint Paint This Dewberry Wyland’s Sara’s Kitchen Kitchen Mexican 28 KCET Hands On Raggs Busytown Peep Pancakes Pufnstuf Land/Lost Hey Kids Taste Journeys Moyers & Company 30 ION Turning Pnt. Discovery In Touch Mark Jeske Paid Program Inspiration Today Camp Meeting 34 KMEX Paid Program Muchachitas Como Tú Al Punto (N) Vidas Paralelas República Deportiva 40 KTBN Rhema Win Walk Miracle-You Redemption Love In Touch PowerPoint It Is Written B. -

Hispanics and Spanish in the Trump Presidency
ARI 36/2018 9 March 2018 Towers and walls against multiculturalism: Hispanics and Spanish in the Trump Presidency Ángel Badillo Matos | Senior Analyst, Real Instituto Elcano | @angelbadillo Theme The election of Donald Trump has generated new tensions around the public use of Spanish in the US and, above all, over multiculturalism. Summary The arrival of Donald Trump to the White House has generated new tensions around the public use of Spanish in the US, but also over multiculturalism as a paradigm for public policies in the country. Spanish has been used by President Trump to visualise the supposed risks posed by a language and a community –Spanish and Hispanics– for whom cultural assimilation does not appear, for diverse reasons, to be as profound as among other language communities. This analysis reviews the delicate relationship between Hispanics, Spanish, the rise of ‘paleoconservatism’ and Donald Trump during the last 12 months, beginning with his oath of office as the 45th US President. Analysis ‘Does not the irrational have as much value as the rational?’ (Alfred Jarry, Ubu Roi, 1896) Twelve months still seems to have been an insufficient period of time for the large part of US society (and the international community) to assimilate the electoral victory of the Republican Party candidate, Donald Trump. In 2016, Trump stepped into a profoundly fractured political and social scenario in which the GOP had been suffering from tensions generated by the rise of populism within its own ranks ever since the choice of the Governor of Alaska, Sarah Palin, as the Vice-Presidential candidate of John McCain in the 2008 presidential election. -

Donald Trump: a Critical Theory-Perspective on Authoritarian Capitalism
tripleC 15(1): 1-72, 2017 http://www.triple-c.at Donald Trump: A Critical Theory-Perspective on Authoritarian Capitalism Christian Fuchs University of Westminster, London, UK, [email protected], @fuchschristian Abstract: This paper analyses economic power, state power and ideological power in the age of Donald Trump with the help of critical theory. It applies the critical theory approaches of thinkers such as Franz Neumann, Theodor W. Adorno and Erich Fromm. It analyses changes of US capitalism that have together with political anxiety and demagoguery brought about the rise of Donald Trump. This article draws attention to the importance of state theory for understanding Trump and the changes of politics that his rule may bring about. It is in this context important to see the complexity of the state, including the dynamic relationship be- tween the state and the economy, the state and citizens, intra-state relations, inter-state rela- tions, semiotic representations of and by the state, and ideology. Trumpism and its potential impacts are theorised along these dimensions. The ideology of Trump (Trumpology) has played an important role not just in his business and brand strategies, but also in his political rise. The (pseudo-)critical mainstream media have helped making Trump and Trumpology by providing platforms for populist spectacles that sell as news and attract audiences. By Trump making news in the media, the media make Trump. An empirical analysis of Trump’s rhetoric and the elimination discourses in his NBC show The Apprentice underpins the analysis of Trumpology. The combination of Trump’s actual power and Trump as spectacle, showman and brand makes his government’s concrete policies fairly unpredictable. -

The Apprentice, Twitter, and the Summer of Trump
THE APPRENTICE, TWITTER, AND THE SUMMER OF TRUMP Since Trump’s national celebrity derived in part from his role in the reality-TV series The Apprentice,7 we need to interrogate this popular TV phenomenon to help explain the Trump phenomenon. The opening theme music “For the Love of Money”, a 1973 R&B song by The O’Jays, established the capitalist ethos of the competition for the winning contestant to get a job with the Trump organization, and obviously money is the key to Trump’s business and celebrity success, although there is much controversy over how rich Trump is, and, so far, he has not released his tax returns to quell rumors that he isn’t as rich as he claims, that he does not contribute as much to charity as he has stated, and that many years he pays little or no taxes. In the original format to The Apprentice, several contestants formed teams to carry out a task dictated by Trump, and each “contest” resulted with a winner and Trump barking “you’re fired” to the loser. Ironically, some commentators believe that in the 2012 presidential election Barack Obama beat Mitt Romney handily because he early on characterized Romney as a billionaire who liked to fire people, which is ironic since this is Trump’s signature personality trait in his business, reality-TV, and now political career, which has seen him fire two campaign managers and more advisors by August 2016. The Apprentice premiered in January 2004, and after six seasons, a new format was introduced: The Celebrity Apprentice. -

Nathan J. Robinson Anatomy of a Monstrosity
“[Robinson] perfectly predicted what would happen in a Clinton-Trump race... He was one of the few pundits who did.” — FORTUNE TRUMP ANATOMY OF A MONSTROSITY NATHAN J. ROBINSON ANATOMY OF A MONSTROSITY TRUMP ANATOMY OF A MONSTROSITY By NATHAN J. ROBINSON Published by: Current Affairs Press P.O. Box 441394 W. Somerville, MA 02144 currentafairs.org Copyright © 2017 by Nathan J. Robinson All Rights Reserved First U.S. Edition Distributed on the West Coast by Waters & Smith, Ltd Monster City, CA ISBN 978-0997844771 No portion of this text may be reprinted without the express permission of Current Afairs, LLC. Cover photo copyright © Getty Images, reprinted with permission. Library of Congress Catalog-in-Publication Data Robinson, Nathan J. Trump: Anatomy of a Monstrosity / Nathan J. Robinson p. cm Includes bibliographical references and index ISBN 978-0997844771 1. Trump, Donald J. 2. Political science 3. Elections 4. Social Philosophy 1. Title To all those who have had the misfortune of sharing a planet with Donald J. Trump, and to those who shall someday get rid of him and everything for which he stands. “We are here to help each other through this thing, whatever it is.” —Kurt Vonnegut “What kind of son have I created?” —Mary Trump, mother of Donald Trump1 CONTENTS Preface 13 Introduction: Trump U 19 I. Who He Is Te Life of Trump 37 Trump & Women 54 What Trump Stands For 69 Who Made Trump 97 II. How It Happened Trump the Candidate 111 Clinton v. Trump 127 What Caused It To Happen? 141 III. What It Means Despair Lingers 177 Orthodox Liberalism Has Been Repudiated 183 Te Press is Discredited Forever 199 Calamity Looms, or Possibly Doesn’t 211 Why Trump Must Be Defeated 217 IV.