Auditory Interfaces and Compares These with Webtree
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
World Wide Web: Introduzione E Componenti
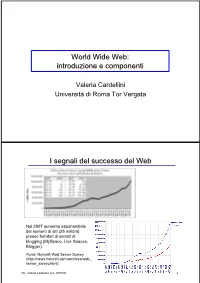
World Wide Web: introduzione e componenti Valeria Cardellini Università di Roma Tor Vergata I segnali del successo del Web Nel 2007 aumento esponenziale del numero di siti (25 milioni) presso fornitori di servizi di blogging (MySpace, Live Spaces, Blogger) Fonte: Netcraft Web Server Survey (http://news.netcraft.com/archives/web_ server_survey.html) IW - Valeria Cardellini, A.A. 2007/08 2 I segnali del successo del Web (2) • Fino all’introduzione dei sistemi P2P, il Web è stata l’applicazione killer di Internet (75% del traffico di Internet nel 1998) Event Period Peak day Peak minute NCSA server (Oct. 1995) - 2 Million - Olympic Summer Games 192 Million 8 Million - (Aug. 1996) (17 days) Nasa Pathfinder 942 Million 40 Million - (July 1997) (14 days) Olympic Winter Games 634.7 Million 55 Million 110,000 (Feb. 1998) (16 days) Wimbledon (July 1998) - - 145,000 FIFA World Cup 1,350 Million 73 Million 209,000 (July 1998) (84 days) Wimbledon (July 1999) - 125 Million 430,000 Wimbledon (July 2000) - 282 Million 964,000 Olympic Summer Games - 875 Million 1,200,000 (Sept. 2000) [Carico misurato in contatti] • Inoltre: google.com, msn.com, yahoo.com (> 200 milioni di contatti al giorno) IW - Valeria Cardellini, A.A. 2007/08 3 I motivi alla base del successo del Web • Digitalizzazione dell’informazione – Qualsiasi informazione rappresentabile in binario come sequenza di 0 e 1 • Diffusione di Internet (dagli anni 1970) – Trasporto dell’informazione ovunque, in tempi rapidissimi e a costi bassissimi • Diffusione dei PC (dagli anni 1980) – Accesso, memorizzazione ed elaborazione dell’informazione da parte di chiunque a costi bassissimi • Semplicità di utilizzo e trasparenza dell’allocazione delle risorse – Semplicità di utilizzo mediante l’uso di interfacce grafiche IW - Valeria Cardellini, A.A. -

MHCC Accessibility Conformance Report
Mt. Hood Community College Website Accessibility Conformance Report WCAG Edition VPAT® Version 2.3 (Revised) – April 2019 Name of Product/Version: www.mhcc.edu Product Description: MHCC Main Website Report Date: August 2, 2019 Contact Information: Tristan Price – [email protected] Notes: Evaluation Methods Used: IAAP WAS Testing Methodology, SiteImprove, Manual Testing __________________________________ “Voluntary Product Accessibility Template” and “VPAT” are registered service marks of the Information Technology Industry Council (ITI) Page 1 of 5 Applicable Standards/Guidelines This report covers the degree of conformance for the following accessibility standard/guidelines: Standard/Guideline Included In Report Web Content Accessibility Guidelines 2.0 Level A (Yes / No ) Level AA (Yes / No ) Level AAA (Yes / No ) Web Content Accessibility Guidelines 2.1 Level A (Yes / No ) Level AA (Yes / No ) Level AAA (Yes / No ) Terms The terms used in the Conformance Level information are defined as follows: • Supports: The functionality of the product has at least one method that meets the criterion without known defects or meets with equivalent facilitation. • Partially Supports: Some functionality of the product does not meet the criterion. • Does Not Support: The majority of product functionality does not meet the criterion. • Not Applicable: The criterion is not relevant to the product. • Not Evaluated: The product has not been evaluated against the criterion. This can be used only in WCAG 2.0 Level AAA. WCAG 2.x Report Note: When reporting on conformance with the WCAG 2.x Success Criteria, they are scoped for full pages, complete processes, and accessibility-supported ways of using technology as documented in the WCAG 2.0 Conformance Requirements. -

S P R I N T" the Professional Word Processor
• • • • • • • • • • • • • • • • • • • • S P R I N T" THE PROFESSIONAL WORD PROCESSOR ALTERNATIVE USER INTERFACES INTERNATIONAl SPRINT@ The Professional Word Processor Alternative User Interfaces Copyright ~1988 All rights reserved Borland International 1800 Green Hills Road P.O. Box 660001 Scotts Valley, CA 95066-0001 Copyright @1988 Borland International. All rights reserved. Sprint is a registered trademark of Borland International. The names of the various alternative user interfaces (AUIs) refer to the command procedures and methods of operation implemented in the AUI files on the distribution disks contained in this package. Sprint's AUIs are compatible with the command procedures implemented in the corresponding word processing programs, but not all command procedures are implemented. The names of the corresponding word processing programs of other companies are used here only to explain the nature of the compatibility of the related AUI. These names are trademarks or registered trademarks of their respective holders. Sprint's AUIs were developed by Borland, which is solely responsible for their content. Printed in the U.S.A. 1098765432 This booklet was produced with Sprint:- The Professional Word Processor Table of Contents Introduction 1 Choosing an Alternative UI 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2 Accessing Sprint Menus within Alternative UIs 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 The X-Sprint Menus 0 0 0 0 0 0 0 0 0 0 0 0 0 • 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 The MSWord UI's X-Sprint Menu 0 0 0 0 0 0 0 • 0 0 •• 0 0 0 0 •• 0 0 0 •• 0 0 0 •• 0 0 0 3 The WordPerfect UI's X-Sprint Menu 0 0 0 0 0 0 0 0 0 0 0 0 0 •• 0 0 •• 0 0 0 • 0 • 0 0 0 4 Reminder 00.00000000000000000000000000. -

Emacspeak — the Complete Audio Desktop User Manual
Emacspeak | The Complete Audio Desktop User Manual T. V. Raman Last Updated: 19 November 2016 Copyright c 1994{2016 T. V. Raman. All Rights Reserved. Permission is granted to make and distribute verbatim copies of this manual without charge provided the copyright notice and this permission notice are preserved on all copies. Short Contents Emacspeak :::::::::::::::::::::::::::::::::::::::::::::: 1 1 Copyright ::::::::::::::::::::::::::::::::::::::::::: 2 2 Announcing Emacspeak Manual 2nd Edition As An Open Source Project ::::::::::::::::::::::::::::::::::::::::::::: 3 3 Background :::::::::::::::::::::::::::::::::::::::::: 4 4 Introduction ::::::::::::::::::::::::::::::::::::::::: 6 5 Installation Instructions :::::::::::::::::::::::::::::::: 7 6 Basic Usage. ::::::::::::::::::::::::::::::::::::::::: 9 7 The Emacspeak Audio Desktop. :::::::::::::::::::::::: 19 8 Voice Lock :::::::::::::::::::::::::::::::::::::::::: 22 9 Using Online Help With Emacspeak. :::::::::::::::::::: 24 10 Emacs Packages. ::::::::::::::::::::::::::::::::::::: 26 11 Running Terminal Based Applications. ::::::::::::::::::: 45 12 Emacspeak Commands And Options::::::::::::::::::::: 49 13 Emacspeak Keyboard Commands. :::::::::::::::::::::: 361 14 TTS Servers ::::::::::::::::::::::::::::::::::::::: 362 15 Acknowledgments.::::::::::::::::::::::::::::::::::: 366 16 Concept Index :::::::::::::::::::::::::::::::::::::: 367 17 Key Index ::::::::::::::::::::::::::::::::::::::::: 368 Table of Contents Emacspeak :::::::::::::::::::::::::::::::::::::::::: 1 1 Copyright ::::::::::::::::::::::::::::::::::::::: -

HTTP Cookie - Wikipedia, the Free Encyclopedia 14/05/2014
HTTP cookie - Wikipedia, the free encyclopedia 14/05/2014 Create account Log in Article Talk Read Edit View history Search HTTP cookie From Wikipedia, the free encyclopedia Navigation A cookie, also known as an HTTP cookie, web cookie, or browser HTTP Main page cookie, is a small piece of data sent from a website and stored in a Persistence · Compression · HTTPS · Contents user's web browser while the user is browsing that website. Every time Request methods Featured content the user loads the website, the browser sends the cookie back to the OPTIONS · GET · HEAD · POST · PUT · Current events server to notify the website of the user's previous activity.[1] Cookies DELETE · TRACE · CONNECT · PATCH · Random article Donate to Wikipedia were designed to be a reliable mechanism for websites to remember Header fields Wikimedia Shop stateful information (such as items in a shopping cart) or to record the Cookie · ETag · Location · HTTP referer · DNT user's browsing activity (including clicking particular buttons, logging in, · X-Forwarded-For · Interaction or recording which pages were visited by the user as far back as months Status codes or years ago). 301 Moved Permanently · 302 Found · Help 303 See Other · 403 Forbidden · About Wikipedia Although cookies cannot carry viruses, and cannot install malware on 404 Not Found · [2] Community portal the host computer, tracking cookies and especially third-party v · t · e · Recent changes tracking cookies are commonly used as ways to compile long-term Contact page records of individuals' browsing histories—a potential privacy concern that prompted European[3] and U.S. -

Emacspeak User's Guide
Emacspeak User's Guide Jennifer Jobst Revision History Revision 1.3 July 24,2002 Revised by: SDS Updated the maintainer of this document to Sharon Snider, corrected links, and converted to HTML Revision 1.2 December 3, 2001 Revised by: JEJ Changed license to GFDL Revision 1.1 November 12, 2001 Revised by: JEJ Revision 1.0 DRAFT October 19, 2001 Revised by: JEJ This document helps Emacspeak users become familiar with Emacs as an audio desktop and provides tutorials on many common tasks and the Emacs applications available to perform those tasks. Emacspeak User's Guide Table of Contents 1. Legal Notice.....................................................................................................................................................1 2. Introduction.....................................................................................................................................................2 2.1. What is Emacspeak?.........................................................................................................................2 2.2. About this tutorial.............................................................................................................................2 3. Before you begin..............................................................................................................................................3 3.1. Getting started with Emacs and Emacspeak.....................................................................................3 3.2. Emacs Command Conventions.........................................................................................................3 -

Tecnologias Da Informação E Comunicação Vs Exclusão Social
Instituto Superior de Engenharia do Porto Departamento de Engenharia Informática Ramo de Computadores e Sistemas Projecto 5º Ano Tecnologias da Informação e Comunicação vs Exclusão Social Autor/Número Sérgio Francisco dos Santos Morais / 990348 Orientador Dr. Constantino Martins Porto, Setembro de 2004 Agradecimentos “Não há no mundo exagero mais belo que a gratidão” La Bruyère (escritor francês 1645-1695) Aproveito este espaço para agradecer a todas as pessoas que directamente ou indirectamente contribuíram e me ajudaram na elaboração deste projecto, pelo seu apoio e incentivo, com um agradecimento especial: ü Ao meu orientador Dr. Constantino Martins, pelo interesse, ajuda e apoio que me prestou. Pela disponibilidade que teve para esclarecimento de dúvidas que foram surgindo e para a revisão das diversas versões do projecto; ü Ao Eng.º Paulo Ferreira pela ajuda que me deu na parte final do projecto; ü Ao Eng.º Carlos Vaz de Carvalho pela autorização concedida para a entrega dos inquéritos aos alunos. Pela revisão do inquérito e pelas suas sugestões; ü À Eng.ª Bertil Marques e ao Eng.º António Costa pela entrega e recolha dos inquéritos aos seus alunos; ü Aos alunos que preencheram os inquéritos; ü À minha família e amigos pela motivação e incentivo que me deram e pela paciência que tiveram para suportar dias e noites sem a minha atenção. A todos o meu muito obrigado. I Resumo Vivemos numa sociedade cada vez mais tecnológica, em que as Tecnologias de Informação e Comunicação (TIC) tem um papel importante e decisivo. As TIC fazem parte integrante do nosso quotidiano ao ponto de ser quase impossível viver sem elas. -

O Software Livre Como Alternativa Para a Inclusão Digital Do Deficiente Visual
Universidade Estadual de Campinas Faculdade de Engenharia Elétrica e de Computação O Software Livre como Alternativa para a Inclusão Digital do Deficiente Visual Autor: Samer Eberlin Orientador: Prof. Dr. Luiz César Martini Dissertação de Mestrado apresentada à Facul- dade de Engenharia Elétrica e de Computação da Universidade Estadual de Campinas como parte dos requisitos para obtenção do título de Mestre em Engenharia Elétrica. Banca Examinadora José Raimundo de Oliveira, Dr. DCA/FEEC/Unicamp Luiz César Martini, Dr. DECOM/FEEC/Unicamp Rita de Cassia Ietto Montilha, Dra. CEPRE/FCM/Unicamp Yuzo Iano, Dr. DECOM/FEEC/Unicamp Campinas, SP – Brasil Abril/2006 FICHA CATALOGRÁFICA ELABORADA PELA BIBLIOTECA DA ÁREA DE ENGENHARIA E ARQUITETURA - BAE - UNICAMP Eberlin, Samer Eb37s O software livre como alternativa para a inclusão digital do deficiente visual / Samer Eberlin. −−Campinas, SP: [s.n.], 2006. Orientador: Luiz César Martini. Dissertação (mestrado) - Universidade Estadual de Campinas, Faculdade de Engenharia Elétrica e de Computação. 1. Acessibilidade. 2. Tecnologia educacional. 3. Inclusão digital. 4. Software livre. 5. Software de comunicação. 6. Síntese da voz. I. Martini, Luiz César. II. Universidade Estadual de Campinas. Faculdade de Engenharia Elétrica e de Computação. III. Título. Titulo em Inglês: The free software as an alternative for digital cohesion of visually impaired people Palavras-chave em Inglês: Accessibility, Assistive technology, Digital cohesion, Free software, Screen reader, Voice synthesizer Área de concentração: Telecomunicações e Telemática Titulação: Mestre em Engenharia Elétrica Banca examinadora: José Raimundo de Oliveira, Rita de Cássia Ietto Montilha e Yuzo Iano Data da defesa: 19/04/2006 ii Resumo A acelerada difusão do software “livre”, tanto no Brasil como no exterior, vem se mos- trando cada vez mais evidente nos mais diversos âmbitos (governo, empresas, escolas, etc.). -

Installing Emacspeak HOWTO
Installing Emacspeak HOWTO Jennifer Jobst James Van Zandt <[email protected]> Revision History Revision 1.1 July 23, 2002 SDS Updated the maintainer of this document to Sharon Snider, corrected links, and converted to XML. Revision 1.0 December 4, 2001 JEJ First release Revision 1.0 DRAFT November 9, 2001 JEJ DRAFT Revision Emacspeak HOWTO 1996-2001 JVZ Previously, this document was known as the Emacspeak HOW- TO, and was written and maintained by Mr. James Van Zandt. Abstract This document contains the installation instructions for the Emacspeak audio desktop application for Linux. Please send any comments, or contributions via e-mail to Sharon Snider [mailto:[email protected]]. This docu- ment will be updated regularly with new contributions and suggestions. Table of Contents Legal Notice ...................................................................................................................... 2 Introduction ........................................................................................................................ 2 Documentation Conventions .................................................................................................. 2 Requirements ...................................................................................................................... 2 Linux Distributions ...................................................................................................... 2 Emacs ...................................................................................................................... -

Learning Technology Supplement Support
Welcome to this special issue of the Learning Technol- ogy supplement. This issue highlights new legislation Learning coming into force in September which has major impli- cations for any staff who publish information on the Web. Staff from many departments and teams have contributed to this issue and thanks are extended to all Technology of them for their contributions, comments, advice and BITs Learning Technology Supplement support. Number Eight: June 2002 8 Why do you want a website anyway? New legislation (see page 2) has major implications for any staff involved in producing Web pages. All staff involved in Web publishing should review their pages in the light of this legislation. Information seminars (see back page) are to be held on 12th June. Although this supplement focuses on making your website as accessible as possible, there is no point having a fully accessible, attractive website if it has no real purpose and if your students or target users don’t ever visit it. Before you go to the bother and effort of building a website, stop for a moment and ask yourself a couple of questions: “Who is this website for?” and “What is the user supposed to gain from using this site?” Websites can have many purposes, from attracting potential students to your course to publicising your excellent research activities. They can be used to provide up-to-date information or to act as a resource base or to give the students a self study centre, or… Whatever your reason, it has to be clear and appropriate for your users. -

RTML 101: the Unofficial Guide to Yahoo! Store® Templates
RTML 101: The Unofficial Guide ® to Yahoo! Store Templates 2nd Edition – Updated for the New Editor By István Siposs Copyright and Important Legal Information Your use of this book means that you have read, understand, and agree to the following terms. The terms are legally binding upon you. Every reasonable effort has been made to ensure the accuracy of the information pre- sented in this book at the time of its publication. Note, however, that neither the author nor publisher is in charge of your web services provider, nor are they in charge of Yahoo!® stores generally, nor can they control your Yahoo!® store in particular. Consequently, this book may contain passages that are, or that later become, inaccurate. The book probably contains some passages that are not the best solution for your particular needs, too. Therefore, all information presented in this book is provided on an “as is” basis. Neither the publisher nor the author of this book makes any representations or warranties with respect to the accuracy or completeness of the contents of this book. On the contrary, the author and publisher specifically disclaim any implied warranties of merchantability or fitness for a particular purpose. No warranty may be created or extended by sales representatives or written sales materials. The accuracy and completeness of the information provided in this book is not guaranteed or warranted to produce any particular result. Neither the author nor the publisher shall be liable for any loss of profit, money damages, or any other form of relief for problems arising from your use of this book. -

W W Orking with XHTML
Tutorial 9 1 E-- ww orking with XHTML Creating a Well-Formed, Valid Document I Case I Wizard Works Fireworks I Wizard Works is one of the largest sellers of brand-name and customized fire- works in the central states. Its Web site produces the bulk of the company's sales. Tom Blaska, the head of advertising for Wizard Works, helps develop the content and design of the company's Web site. Because the Web site has been around for many years, some of the code dates back to the earliest versions of HTML. Tom would like the Web site code to be updated to reflect current stan- dards and practices. Specifically, he wants you to look into rewriting the Web site code in XHTML rather than HTML. He also would like you to find ways ta verify that the code used by Wizard Works meets XHTML standards. rlReview dtd-list.txt dtd-list.txt breaktxt.htm dtd-list.txt casttxt.htm address.txt workstxt.htm founttxt.htm dinnrtxt.htm gargtxt.htm dtd-list.txt astro.txt wwtxt.css + 2 graphic dtd-list.txt + 5 graphic + 6 graphic chem.txt + 4 graphic files lunchtxt.htm files files dtd-list.txt files + 4 graphic hebdtxt.htm + 1 graphic files hightxt-htm file laketxt.htm elect.txt scottxt. htm eng.txt + 4 HTML physics.txt files HTML 51 HTML and XHTML I Tutorial 9 Working with XHTA I Introducing XHTML he suggests that puupgrade the hame page file Icr XHTML standards MreCD ta the rest the Web site, ww.css, respectively, in the same folder.