Speculative Execution in High Performance Computer Architectures CHAPMAN & HALL/CRC COMPUTER and INFORMATION SCIENCE SERIES Series Editor: Sartaj Sahni
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
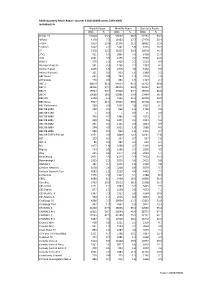
Source: BARB/RSMB BARB Quarterly Reach Report- Quarter 3 2012
BARB Quarterly Reach Report- Quarter 3 2012 (BARB weeks 2293-2305) Individuals 4+ Weekly Reach Monthly Reach Quarterly Reach 000s % 000s % 000s % TOTAL TV 53904 93.9 56667 98.7 57262 99.7 4Music 4170 7.3 10163 17.7 17476 30.4 5 USA 5959 10.4 12106 21.1 18892 32.9 5 USA+1 1227 2.1 3241 5.6 6155 10.7 5* 7178 12.5 16253 28.3 26648 46.4 5*+1 911 1.6 2895 5.0 6338 11.0 Alibi 2061 3.6 4155 7.2 6900 12.0 Alibi+1 579 1.0 1410 2.5 2513 4.4 AlJazeera English 541 0.9 1265 2.2 2354 4.1 Animal Planet 1015 1.8 2775 4.8 5192 9.0 Animal Planet+1 321 0.6 933 1.6 1999 3.5 ARY News 462 0.8 749 1.3 1074 1.9 attheraces 476 0.8 881 1.5 1404 2.4 BBC 1 46870 81.6 54607 95.1 56732 98.8 BBC 2 34306 59.7 48215 84.0 54241 94.5 BBC 3 19324 33.7 37000 64.4 49378 86.0 BBC 4 10686 18.6 22885 39.9 33499 58.3 BBC HD 3104 5.4 7133 12.4 11976 20.9 BBC News 9317 16.2 17001 29.6 24758 43.1 BBC Parliament 539 0.9 1635 2.8 3502 6.1 BBC RB 6780 303 0.5 869 1.5 1720 3.0 BBC RB 6790 1 0.0 5 0.0 15 0.0 BBC RB 6880 396 0.7 1484 2.6 3513 6.1 BBC RB 6881 350 0.6 1304 2.3 3224 5.6 BBC RB 6882 291 0.5 1124 2.0 2823 4.9 BBC RB 6883 264 0.5 1021 1.8 2588 4.5 BBC RB 6886 286 0.5 932 1.6 2151 3.7 BBC RB FREEVIEW 301 2251 3.9 5849 10.2 10231 17.8 BET 129 0.2 394 0.7 927 1.6 BET+1 86 0.2 287 0.5 630 1.1 Bio 1057 1.8 2688 4.7 5103 8.9 Blighty 454 0.8 1396 2.4 2826 4.9 Bliss 465 0.8 1377 2.4 2924 5.1 Boomerang 2001 3.5 4515 7.9 7624 13.3 Boomerang+1 1325 2.3 3204 5.6 5655 9.8 BuzMuzik 381 0.7 1056 1.8 2200 3.8 Cartoon Network 1478 2.6 3238 5.6 5570 9.7 Cartoon Network Too 1092 1.9 2530 4.4 4442 -

Stream Name Category Name Coronavirus (COVID-19) |EU| FRANCE TNTSAT ---TNT-SAT ---|EU| FRANCE TNTSAT TF1 SD |EU|
stream_name category_name Coronavirus (COVID-19) |EU| FRANCE TNTSAT ---------- TNT-SAT ---------- |EU| FRANCE TNTSAT TF1 SD |EU| FRANCE TNTSAT TF1 HD |EU| FRANCE TNTSAT TF1 FULL HD |EU| FRANCE TNTSAT TF1 FULL HD 1 |EU| FRANCE TNTSAT FRANCE 2 SD |EU| FRANCE TNTSAT FRANCE 2 HD |EU| FRANCE TNTSAT FRANCE 2 FULL HD |EU| FRANCE TNTSAT FRANCE 3 SD |EU| FRANCE TNTSAT FRANCE 3 HD |EU| FRANCE TNTSAT FRANCE 3 FULL HD |EU| FRANCE TNTSAT FRANCE 4 SD |EU| FRANCE TNTSAT FRANCE 4 HD |EU| FRANCE TNTSAT FRANCE 4 FULL HD |EU| FRANCE TNTSAT FRANCE 5 SD |EU| FRANCE TNTSAT FRANCE 5 HD |EU| FRANCE TNTSAT FRANCE 5 FULL HD |EU| FRANCE TNTSAT FRANCE O SD |EU| FRANCE TNTSAT FRANCE O HD |EU| FRANCE TNTSAT FRANCE O FULL HD |EU| FRANCE TNTSAT M6 SD |EU| FRANCE TNTSAT M6 HD |EU| FRANCE TNTSAT M6 FHD |EU| FRANCE TNTSAT PARIS PREMIERE |EU| FRANCE TNTSAT PARIS PREMIERE FULL HD |EU| FRANCE TNTSAT TMC SD |EU| FRANCE TNTSAT TMC HD |EU| FRANCE TNTSAT TMC FULL HD |EU| FRANCE TNTSAT TMC 1 FULL HD |EU| FRANCE TNTSAT 6TER SD |EU| FRANCE TNTSAT 6TER HD |EU| FRANCE TNTSAT 6TER FULL HD |EU| FRANCE TNTSAT CHERIE 25 SD |EU| FRANCE TNTSAT CHERIE 25 |EU| FRANCE TNTSAT CHERIE 25 FULL HD |EU| FRANCE TNTSAT ARTE SD |EU| FRANCE TNTSAT ARTE FR |EU| FRANCE TNTSAT RMC STORY |EU| FRANCE TNTSAT RMC STORY SD |EU| FRANCE TNTSAT ---------- Information ---------- |EU| FRANCE TNTSAT TV5 |EU| FRANCE TNTSAT TV5 MONDE FBS HD |EU| FRANCE TNTSAT CNEWS SD |EU| FRANCE TNTSAT CNEWS |EU| FRANCE TNTSAT CNEWS HD |EU| FRANCE TNTSAT France 24 |EU| FRANCE TNTSAT FRANCE INFO SD |EU| FRANCE TNTSAT FRANCE INFO HD -
A Channel Guide
Intelsat is the First MEDIA Choice In Africa Are you ready to provide top media services and deliver optimal video experience to your growing audiences? With 552 channels, including 50 in HD and approximately 192 free to air (FTA) channels, Intelsat 20 (IS-20), Africa’s leading direct-to- home (DTH) video neighborhood, can empower you to: Connect with Expand Stay agile with nearly 40 million your digital ever-evolving households broadcasting reach technologies From sub-Saharan Africa to Western Europe, millions of households have been enjoying the superior video distribution from the IS-20 Ku-band video neighborhood situated at 68.5°E orbital location. Intelsat 20 is the enabler for your TV future. Get on board today. IS-20 Channel Guide 2 CHANNEL ENC FR P CHANNEL ENC FR P 947 Irdeto 11170 H Bonang TV FTA 12562 H 1 Magic South Africa Irdeto 11514 H Boomerang EMEA Irdeto 11634 V 1 Magic South Africa Irdeto 11674 H Botswana TV FTA 12634 V 1485 Radio Today Irdeto 11474 H Botswana TV FTA 12657 V 1KZN TV FTA 11474 V Botswana TV Irdeto 11474 H 1KZN TV Irdeto 11594 H Bride TV FTA 12682 H Nagravi- Brother Fire TV FTA 12562 H 1KZN TV sion 11514 V Brother Fire TV FTA 12602 V 5 FM FTA 11514 V Builders Radio FTA 11514 V 5 FM Irdeto 11594 H BusinessDay TV Irdeto 11634 V ABN FTA 12562 H BVN Europa Irdeto 11010 H Access TV FTA 12634 V Canal CVV International FTA 12682 H Ackermans Stores FTA 11514 V Cape Town TV Irdeto 11634 V ACNN FTA 12562 H CapeTalk Irdeto 11474 H Africa Magic Epic Irdeto 11474 H Capricorn FM Irdeto 11170 H Africa Magic Family Irdeto -

Foreign Satellite & Satellite Systems Europe Africa & Middle East Asia
Foreign Satellite & Satellite Systems Europe Africa & Middle East Albania, Austria, Belarus, Belgium, Bosnia & Algeria, Angola, Benin, Burkina Faso, Cameroon, Herzegonia, Bulgaria, Croatia, Czech Republic, Congo Brazzaville, Congo Kinshasa, Egypt, France, Germany, Gibraltar, Greece, Hungary, Ethiopia, Gabon, Ghana, Ivory Coast, Kenya, Iceland, Ireland, Italy, Luxembourg, Macedonia, Libya, Mali, Mauritania, Mauritius, Morocco, Moldova, Montenegro, The Netherlands, Norway, Mozambique, Namibia, Niger, Nigeria, Senegal, Poland, Portugal, Romania, Russia, Serbia, Somalia, South Africa, Sudan, Tanzania, Tunisia, Slovakia, Slovenia, Spain, Sweden, Switzerland, Uganda, Western Sahara, Zambia. Armenia, Ukraine, United Kingdom. Azerbaijan, Bahrain, Cyprus, Georgia, Iran, Iraq, Israel, Jordan, Kuwait, Lebanon, Oman, Palestine, Qatar, Saudi Arabia, Syria, Turkey, United Arab Emirates, Yemen. Asia & Pacific North & South America Afghanistan, Bangladesh, Bhutan, Cambodia, Canada, Costa Rica, Cuba, Dominican Republic, China, Hong Kong, India, Japan, Kazakhstan, Honduras, Jamaica, Mexico, Puerto Rico, United Kyrgyzstan, Laos, Macau, Maldives, Myanmar, States of America. Argentina, Bolivia, Brazil, Nepal, Pakistan, Phillipines, South Korea, Chile, Columbia, Ecuador, Paraguay, Peru, Sri Lanka, Taiwan, Tajikistan, Thailand, Uruguay, Venezuela. Uzbekistan, Vietnam. Australia, French Polynesia, New Zealand. EUROPE Albania Austria Belarus Belgium Bosnia & Herzegovina Bulgaria Croatia Czech Republic France Germany Gibraltar Greece Hungary Iceland Ireland Italy -

The Cable Network in an Era of Digital Media: Bravo and the Constraints of Consumer Citizenship
University of Massachusetts Amherst ScholarWorks@UMass Amherst Doctoral Dissertations Dissertations and Theses Fall August 2014 The Cable Network in an Era of Digital Media: Bravo and the Constraints of Consumer Citizenship Alison D. Brzenchek University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/dissertations_2 Part of the Communication Technology and New Media Commons, Critical and Cultural Studies Commons, Cultural History Commons, Feminist, Gender, and Sexuality Studies Commons, Film and Media Studies Commons, History of Science, Technology, and Medicine Commons, and the Political Economy Commons Recommended Citation Brzenchek, Alison D., "The Cable Network in an Era of Digital Media: Bravo and the Constraints of Consumer Citizenship" (2014). Doctoral Dissertations. 55. https://doi.org/10.7275/bjgn-vg94 https://scholarworks.umass.edu/dissertations_2/55 This Open Access Dissertation is brought to you for free and open access by the Dissertations and Theses at ScholarWorks@UMass Amherst. It has been accepted for inclusion in Doctoral Dissertations by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. THE CABLE NETWORK IN AN ERA OF DIGITAL MEDIA: BRAVO AND THE CONSTRAINTS OF CONSUMER CITIZENSHIP A Dissertation Presented by ALISON D. BRZENCHEK Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY May 2014 Department -

995 Final COMMISSION STAFF WORKING DOCUMENT
EUROPEAN COMMISSION Brussels,23.9.2010 SEC(2010)995final COMMISSIONSTAFFWORKINGDOCUMENT Accompanyingdocumenttothe COMMUNICATIONFROMTHECOMMISSIONTOTHE EUROPEAN PARLIAMENT,THECOUNCIL,THEEUROPEANECONOMIC ANDSOCIAL COMMITTEEANDTHECOMMITTEEOFTHEREGIONS NinthCommunication ontheapplicationofArticles4and5ofDirective89/552/EECas amendedbyDirective97/36/ECandDirective2007/65/EC,fortheperiod2007-2008 (PromotionofEuropeanandindependentaudiovisual works) COM(2010)450final EN EN COMMISSIONSTAFFWORKINGDOCUMENT Accompanyingdocumenttothe COMMUNICATIONFROMTHECOMMISSIONTOTHE EUROPEAN PARLIAMENT,THECOUNCIL,THEEUROPEANECONOMIC ANDSOCIAL COMMITTEEANDTHECOMMITTEEOFTHEREGIONS NinthCommunication ontheapplicationofArticles4and5ofDirective89/552/EECas amendedbyDirective97/36/ECandDirective2007/65/EC,fortheperiod20072008 (PromotionofEuropeanandindependentaudiovisual works) EN 2 EN TABLE OF CONTENTS ApplicationofArticles 4and5ineachMemberState ..........................................................5 Introduction ................................................................................................................................5 1. ApplicationofArticles 4and5:generalremarks ...................................................5 1.1. MonitoringmethodsintheMemberStates ..................................................................6 1.2. Reasonsfornon-compliance ........................................................................................7 1.3. Measures plannedor adoptedtoremedycasesofnoncompliance .............................8 1.4. Conclusions -

Notes from the Underground: a Cultural, Political, and Aesthetic Mapping of Underground Music
Notes From The Underground: A Cultural, Political, and Aesthetic Mapping of Underground Music. Stephen Graham Goldsmiths College, University of London PhD 1 I declare that the work presented in this thesis is my own. Signed: …………………………………………………. Date:…………………………………………………….. 2 Abstract The term ‗underground music‘, in my account, connects various forms of music-making that exist largely outside ‗mainstream‘ cultural discourse, such as Drone Metal, Free Improvisation, Power Electronics, and DIY Noise, amongst others. Its connotations of concealment and obscurity indicate what I argue to be the music‘s central tenets of cultural reclusion, political independence, and aesthetic experiment. In response to a lack of scholarly discussion of this music, my thesis provides a cultural, political, and aesthetic mapping of the underground, whose existence as a coherent entity is being both argued for and ‗mapped‘ here. Outlining the historical context, but focusing on the underground in the digital age, I use a wide range of interdisciplinary research methodologies , including primary interviews, musical analysis, and a critical engagement with various pertinent theoretical sources. In my account, the underground emerges as a marginal, ‗antermediated‘ cultural ‗scene‘ based both on the web and in large urban centres, the latter of whose concentration of resources facilitates the growth of various localised underground scenes. I explore the radical anti-capitalist politics of many underground figures, whilst also examining their financial ties to big business and the state(s). This contradiction is critically explored, with three conclusions being drawn. First, the underground is shown in Part II to be so marginal as to escape, in effect, post- Fordist capitalist subsumption. -

Quake III Arena This Page Intentionally Left Blank Focus on Mod Programming for Quake III Arena
Focus on Mod Programming for Quake III Arena This page intentionally left blank Focus on Mod Programming for Quake III Arena Shawn Holmes © 2002 by Premier Press, a division of Course Technology. All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, elec- tronic or mechanical, including photocopying, recording, or by any information stor- age or retrieval system without written permission from Premier Press, except for the inclusion of brief quotations in a review. The Premier Press logo, top edge printing, and related trade dress are trade- marks of Premier Press, Inc. and may not be used without written permis- sion. All other trademarks are the property of their respective owners. Publisher: Stacy L. Hiquet Marketing Manager: Heather Hurley Managing Editor: Sandy Doell Acquisitions Editor: Emi Smith Series Editor: André LaMothe Project Editor: Estelle Manticas Editorial Assistant: Margaret Bauer Technical Reviewer: Robi Sen Technical Consultant: Jared Larson Copy Editor: Kate Welsh Interior Layout: Marian Hartsough Cover Design: Mike Tanamachi Indexer: Katherine Stimson Proofreader: Jennifer Davidson All trademarks are the property of their respective owners. Important: Premier Press cannot provide software support. Please contact the appro- priate software manufacturer’s technical support line or Web site for assistance. Premier Press and the author have attempted throughout this book to distinguish proprietary trademarks from descriptive terms by following the capitalization style used by the manufacturer. Information contained in this book has been obtained by Premier Press from sources believed to be reliable. However, because of the possibility of human or mechanical error by our sources, Premier Press, or others, the Publisher does not guarantee the accuracy, adequacy, or completeness of any information and is not responsible for any errors or omissions or the results obtained from use of such information. -

Payday Loans
Trends in Advertising Activity - Payday Loans December 2013 Contents • Key Facts • Viewing Trends • Advertising Activity • Annex 1 – Methodology 1 Key Facts Source: BARB/Infosys+/Nielsen Media Note: Figures have been rounded for illustrative purposes – please refer to the ‘Advertising Activity’ section for detailed analyses 2 Key Facts - Viewing 2012 Total TV Comm.TV Comm: Non-comm 2008 2012 Adults 4.3 2.8 Adults 66:34 66:34 commercial ABC1 Adults 3.5 2.2 - ABC1 Adults 63:37 61:39 C2DE Adults 5.2 3.6 C2DE Adults 68:32 70:30 4-15 2.4 1.7 4-15 74:26 73:27 Hours of viewing/day Hours 10-15 2.4 1.8 10-15 75:25 75:25 Commercial: Non Viewing by daypart Commercial channel viewing by channel group • Around two-thirds of commercial channel viewing takes place pre- • Terrestrial channels account for almost two-fifths of adult viewing - 2100 across the adults demographic groups – this has remained this has been in decline as viewing to Portfolio channels has stable over time. ABC1 Adult viewing tends to be higher later in the increased to around a quarter of viewing. evening than Adults/C2DE Adults. • Among children, the share of viewing represented by the Terrestrial • Around four-fifths of Children’s viewing takes place pre-2100, falling channels falls to around a quarter and viewing to the Portfolio to around three-quarters among older children – this has also channels accounts for around 15% of viewing. Children’s channels remained stable over the analysis period account for almost a third of viewing amongst 4-15 year olds and a • In 2012, viewing to commercial channels peaked between 2100- fifth of viewing among 10-15 year olds. -

Razorcake Issue #84 As A
RIP THIS PAGE OUT WHO WE ARE... Razorcake exists because of you. Whether you contributed If you wish to donate through the mail, any content that was printed in this issue, placed an ad, or are a reader: without your involvement, this magazine would not exist. We are a please rip this page out and send it to: community that defi es geographical boundaries or easy answers. Much Razorcake/Gorsky Press, Inc. of what you will fi nd here is open to interpretation, and that’s how we PO Box 42129 like it. Los Angeles, CA 90042 In mainstream culture the bottom line is profi t. In DIY punk the NAME: bottom line is a personal decision. We operate in an economy of favors amongst ethical, life-long enthusiasts. And we’re fucking serious about it. Profi tless and proud. ADDRESS: Th ere’s nothing more laughable than the general public’s perception of punk. Endlessly misrepresented and misunderstood. Exploited and patronized. Let the squares worry about “fi tting in.” We know who we are. Within these pages you’ll fi nd unwavering beliefs rooted in a EMAIL: culture that values growth and exploration over tired predictability. Th ere is a rumbling dissonance reverberating within the inner DONATION walls of our collective skull. Th ank you for contributing to it. AMOUNT: Razorcake/Gorsky Press, Inc., a California non-profit corporation, is registered as a charitable organization with the State of California’s COMPUTER STUFF: Secretary of State, and has been granted official tax exempt status (section 501(c)(3) of the Internal Revenue Code) from the United razorcake.org/donate States IRS. -

Vmax TV Channel List
Vmax TV Channel List Vmax TV for Android https://japannettv.com/wpshop/index.php/vmaxtv/ Vmax TV m3u Code for VLC Player https://japannettv.com/wpshop/index.php/vmaxtv-m3u-code/ 1 Afghanistan (FG) 14 2 Africa (AF) 105 3 Albania (AL) 72 4 Arabic (AR) 459 5 Armenia (AM) 4 6 Austria (AU) 2 7 Azerbaijan (AZ) 2 8 Belgium (BE) 15 9 Brazil (BR) 236 10 Bulgaria (BG) 95 11 Canada (CA) 5 12 Cypress (CY) 10 13 Farsi (FS) 58 14 Former Yugoslavia (EXYU) 58 15 France (FR) 80 16 Germany (DE) 82 17 Greece (GR) 39 18 Hungary (HR) 11 19 India (IN) 205 20 Italy (IT) 135 21 Kurdistan (KU) 30 22 Latvia (LV) 5 23 Macedonia (MK) 14 24 Malta (MT) 4 25 Netherlands (NL) 60 26 Norway (NO) 101 27 Pakistan (PK) 38 28 Poland (PL) 70 29 Portugal (PT) 77 30 Romania (RO) 42 31 Russia (RU) 193 32 Serbia (SR) 5 33 Spain (ES) 72 34 Switzerland (CH) 6 35 Turkey (TR) 112 36 Türkmenistan (TM) 1 37 Ukraine (UA) 3 38 United Kingdom (UK) 238 39 United States (US) 62 39 Countries / Languages 2820 Channels Updated 2018 04 17 1 Afghanistan (FG) 14 AMC TV Arezo TV ATN ATN News Hewad TV Jahan Numa TV Khurshid TV Maiwand TV Mitra Noor TV Rah-e-Farda TV Shamshad TV Tamadon TV Zhwandoon TV 2 Africa (AF) 105 2sTV Senegal A2i Senegal ABN NIGERIA ACBN NIGERIA Adom TV Ghana Africa 24 Africa News EN Africa News FR Africa TV 1 Africa TV 4 AFRICABLE TV Mali Afrique Media Cameroon Ait Inter Nigeria ANN 7 South Africa Ben TV Ghana Benie TV Cote d'Ivoire BICHRI Senegal Botswana Television Channels 24 Nigeria Channels TV Nigeria Citizen TV Kenya CNBC South Africa CRTV Cameroon DBS Cameroon DIASPORA -

Trends in Advertising Activity – Gambling
Trends in Advertising Activity - Gambling November 2013 Contents • Key Facts • Viewing Trends • Advertising Activity • Gambling • Lottery & Scratch Cards • Gambling excluding Lottery & Scratch cards • Bingo • Gambling Sports • Online Casino & Poker • Comparative analysis: ABC1 Adults & C2DE Adults • Annex 1 – Methodology 1 Key Facts Source: BARB/Infosys+/Nielsen Media Note: Figures have been rounded for illustrative purposes – please refer to the ‘Advertising Activity’ section for detailed analyses 2 Viewing 2012 Total TV Comm.TV Comm: Non-comm 2005 2012 Adults 4.3 2.8 Adults 64:36 66:34 commercial ABC1 Adults 3.5 2.2 - ABC1 Adults 62:38 61:39 C2DE Adults 5.2 3.6 C2DE Adults 66:34 70:30 4-15 2.4 1.7 4-15 72:28 73:27 Hours ofviewing/day Hours 10-15 2.4 1.8 10-15 73:27 75:25 Commercial: Non Commercial: Viewing by daypart Commercial channel viewing by channel group • Around two-thirds of total and commercial channel viewing takes • Terrestrial channels account for almost two-fifths of adult viewing - place pre-2100 across the adult demographic groups – this has this has been in decline, as viewing to both Portfolio and ‘Other’ remained stable over time. ABC1 Adult viewing tends to be higher channels has increased, to around a quarter of viewing. later in the evening than Adults/C2DE Adults. • Among children, the share of viewing represented by the Terrestrial • Around four-fifths of Children’s viewing takes place pre-2100, falling channels falls to around a quarter and viewing to the Portfolio to around three-quarters among older children – this has also channels accounts for a fifth of viewing – Music channels and remained stable over the analysis period ‘Other’ channels account for a greater share of children’s viewing • In 2012, viewing to commercial channels peaked between 2100- than Adults.