4Th Workshop on Sound Change Accepted Abstracts
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Some English Words Illustrating the Great Vowel Shift. Ca. 1400 Ca. 1500 Ca. 1600 Present 'Bite' Bi:Tə Bəit Bəit
Some English words illustrating the Great Vowel Shift. ca. 1400 ca. 1500 ca. 1600 present ‘bite’ bi:tә bәit bәit baIt ‘beet’ be:t bi:t bi:t bi:t ‘beat’ bɛ:tә be:t be:t ~ bi:t bi:t ‘abate’ aba:tә aba:t > abɛ:t әbe:t әbeIt ‘boat’ bɔ:t bo:t bo:t boUt ‘boot’ bo:t bu:t bu:t bu:t ‘about’ abu:tә abәut әbәut әbaUt Note that, while Chaucer’s pronunciation of the long vowels was quite different from ours, Shakespeare’s pronunciation was similar enough to ours that with a little practice we would probably understand his plays even in the original pronuncia- tion—at least no worse than we do in our own pronunciation! This was mostly an unconditioned change; almost all the words that appear to have es- caped it either no longer had long vowels at the time the change occurred or else entered the language later. However, there was one restriction: /u:/ was not diphthongized when followed immedi- ately by a labial consonant. The original pronunciation of the vowel survives without change in coop, cooper, droop, loop, stoop, troop, and tomb; in room it survives in the speech of some, while others have shortened the vowel to /U/; the vowel has been shortened and unrounded in sup, dove (the bird), shove, crumb, plum, scum, and thumb. This multiple split of long u-vowels is the most signifi- cant IRregularity in the phonological development of English; see the handout on Modern English sound changes for further discussion. -

Phonological Domains Within Blackfoot Towards a Family-Wide Comparison
Phonological domains within Blackfoot Towards a family-wide comparison Natalie Weber 52nd algonquian conference yale university October 23, 2020 Outline 1. Background 2. Two phonological domains in Blackfoot verbs 3. Preverbs are not a separate phonological domain 4. Parametric variation 2 / 59 Background 3 / 59 Consonant inventory Labial Coronal Dorsal Glottal Stops p pː t tː k kː ʔ <’> Assibilants ts tːs ks Pre-assibilants ˢt ˢtː Fricatives s sː x <h> Nasals m mː n nː Glides w j <y> (w) Long consonants written with doubled letters. (Derrick and Weber n.d.; Weber 2020) 4 / 59 Predictable mid vowels? (Frantz 2017) Many [ɛː] and [ɔː] arise from coalescence across boundaries ◦ /a+i/ ! [ɛː] ◦ /a+o/ ! [ɔː] Vowel inventory front central back high i iː o oː mid ɛː <ai> ɔː <ao> low a aː (Derrick and Weber n.d.; Weber 2020) 5 / 59 Vowel inventory front central back high i iː o oː mid ɛː <ai> ɔː <ao> low a aː Predictable mid vowels? (Frantz 2017) Many [ɛː] and [ɔː] arise from coalescence across boundaries ◦ /a+i/ ! [ɛː] ◦ ! /a+o/ [ɔː] (Derrick and Weber n.d.; Weber 2020) 5 / 59 Contrastive mid vowels Some [ɛː] and [ɔː] are morpheme-internal, in overlapping environments with other long vowels JɔːníːtK JaːníːtK aoníít aaníít [ao–n/i–i]–t–Ø [aan–ii]–t–Ø [hole–by.needle/ti–ti1]–2sg.imp–imp [say–ai]–2sg.imp–imp ‘pierce it!’ ‘say (s.t.)!’ (Weber 2020) 6 / 59 Syntax within the stem Intransitive (bi-morphemic) vs. syntactically transitive (trimorphemic). Transitive V is object agreement (Quinn 2006; Rhodes 1994) p [ root –v0 –V0 ] Stem type Gloss ikinn –ssi AI ‘he is warm’ ikinn –ii II ‘it is warm’ itap –ip/i –thm TA ‘take him there’ itap –ip/ht –oo TI ‘take it there’ itap –ip/ht –aki AI(+O) ‘take (s.t.) there’ (Déchaine and Weber 2015, 2018; Weber 2020) 7 / 59 Syntax within the verbal complex Template p [ person–(preverb)*– [ –(med)–v–V ] –I0–C0 ] CP vP root vP CP ◦ Minimal verbal complex: stem plus suffixes (I0,C0). -
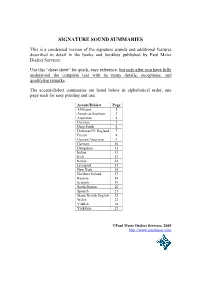
Signature Sound Summaries
SIGNATURE SOUND SUMMARIES This is a condensed version of the signature sounds and additional features described in detail in the books and booklets published by Paul Meier Dialect Services. Use this “cheat sheet” for quick, easy reference, but only after you have fully understood the complete text with its many details, exceptions, and qualifying remarks. The accent/dialect summaries are listed below in alphabetical order, one page each for easy printing and use. Accent/Dialect Page Afrikaans 2 American Southern 3 Australian 4 Cockney 5 Deep South 6 Downeast N. England 7 French 8 General American 9 German 10 Hampshire 11 Indian 12 Irish 13 Italian 14 Liverpool 15 New York 16 Northern Ireland 17 Russian 18 Scottish 19 South Boston 20 Spanish 21 Stand. British English 22 Welsh 23 Yiddish 24 Yorkshire 25 ©Paul Meier Dialect Services, 2009 http://www.paulmeier.com SIGNATURE SOUND SUMMARIES AFRIKAANS SIGNATURE SOUNDS 1. kit [ə] sometimes [i] if [p, t, or k] follows 2. dress [e or ɪ] 3. trap [ɛ] 4. lot/cloth [ɒ̹] 5. foot [u] 6. bath [ɑ̹] 7. non-rhotic; /r/ following vowel is silent 8. nurse [ɞ] 9. face [aɪ] 10. thought [ɔ]̹ 11. goat [ɐɘ] 12. goose [ʉ]; [j] used before the vowel following alveolar consonants 13. /h/ elided 14. pre-vocalic /r/ [ɾ or r] 15. voiced /th/ [d̪]; unvoiced /th/ [f] ADDITIONAL FEATURES a. no aspiration for [p, t, k], esp. initially in word or syllable b. final voiced obstruents devoiced c. unstressed /-et/, /-ed/ endings [ət, əd], e.g. pocketed [ˈpɒ̹kətəd] d. pure vowel, not schwa in initial unstressed syllables. -

The Phonology, Phonetics, and Diachrony of Sturtevant's
Indo-European Linguistics 7 (2019) 241–307 brill.com/ieul The phonology, phonetics, and diachrony of Sturtevant’s Law Anthony D. Yates University of California, Los Angeles [email protected] Abstract This paper presents a systematic reassessment of Sturtevant’s Law (Sturtevant 1932), which governs the differing outcomes of Proto-Indo-European voiced and voice- less obstruents in Hittite (Anatolian). I argue that Sturtevant’s Law was a con- ditioned pre-Hittite sound change whereby (i) contrastively voiceless word-medial obstruents regularly underwent gemination (cf. Melchert 1994), but gemination was blocked for stops in pre-stop position; and (ii) the inherited [±voice] contrast was then lost, replaced by the [±long] opposition observed in Hittite (cf. Blevins 2004). I pro- vide empirical and typological support for this novel restriction, which is shown not only to account straightforwardly for data that is problematic under previous analy- ses, but also to be phonetically motivated, a natural consequence of the poorly cued durational contrast between voiceless and voiced stops in pre-stop environments. I develop an optimality-theoretic analysis of this gemination pattern in pre-Hittite, and discuss how this grammar gave rise to synchronic Hittite via “transphonologization” (Hyman 1976, 2013). Finally, it is argued that this analysis supports deriving the Hittite stop system from the Proto-Indo-European system as traditionally reconstructed with an opposition between voiceless, voiced, and breathy voiced stops (contra Kloekhorst 2016, Jäntti 2017). Keywords Hittite – Indo-European – diachronic phonology – language change – phonological typology © anthony d. yates, 2019 | doi:10.1163/22125892-00701006 This is an open access article distributed under the terms of the CC-BY-NCDownloaded4.0 License. -

Himalayan Linguistics Segmental and Suprasegmental Features of Brokpa
Himalayan Linguistics Segmental and suprasegmental features of Brokpa Pema Wangdi James Cook University ABSTRACT This paper analyzes segmental and suprasegmental features of Brokpa, a Trans-Himalayan (Tibeto- Burman) language belonging to the Central Bodish (Tibetic) subgroup. Segmental phonology includes segments of speech including consonants and vowels and how they make up syllables. Suprasegmental features include register tone system and stress. We examine how syllable weight or moraicity plays a determining role in the placement of stress, a major criterion for phonological word in Brokpa; we also look at some other evidence for phonological words in this language. We argue that synchronic segmental and suprasegmental features of Brokpa provide evidence in favour of a number of innovative processes in this archaic Bodish language. We conclude that Brokpa, a language historically rich in consonant clusters with a simple vowel system and a relatively simple prosodic system, is losing its consonant clusters and developing additional complexities including lexical tones. KEYWORDS Parallelism in drift, pitch harmony, register tone, stress, suprasegmental This is a contribution from Himalayan Linguistics, Vol. 19(1): 393-422 ISSN 1544-7502 © 2020. All rights reserved. This Portable Document Format (PDF) file may not be altered in any way. Tables of contents, abstracts, and submission guidelines are available at escholarship.org/uc/himalayanlinguistics Himalayan Linguistics, Vol. 19(1). © Himalayan Linguistics 2020 ISSN 1544-7502 Segmental and suprasegmental features of Brokpa Pema Wangdi James Cook University 1 Introduction Brokpa, a Central Bodish language, has a complicated phonological system. This paper aims at analysing its segmental and suprasegmental features. We begin with a brief background information and basic typological features of Brokpa in §1. -

Variation in Form and Function in Jewish English Intonation
Variation in Form and Function in Jewish English Intonation Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Rachel Steindel Burdin ∼6 6 Graduate Program in Linguistics The Ohio State University 2016 Dissertation Committee: Professor Brian D. Joseph, Advisor Professor Cynthia G. Clopper Professor Donald Winford c Rachel Steindel Burdin, 2016 Abstract Intonation has long been noted as a salient feature of American Jewish English speech (Weinreich, 1956); however, there has not been much systematic study of how, exactly Jewish English intonation is distinct, and to what extent Yiddish has played a role in this distinctness. This dissertation examines the impact of Yiddish on Jewish English intonation in the Jewish community of Dayton, Ohio, and how features of Yiddish intonation are used in Jewish English. 20 participants were interviewed for a production study. The participants were balanced for gender, age, religion (Jewish or not), and language background (whether or not they spoke Yiddish in addition to English). In addition, recordings were made of a local Yiddish club. The production study revealed differences in both the form and function in Jewish English, and that Yiddish was the likely source for that difference. The Yiddish-speaking participants were found to both have distinctive productions of rise-falls, including higher peaks, and a wider pitch range, in their Yiddish, as well as in their English produced during the Yiddish club meetings. The younger Jewish English participants also showed a wider pitch range in some situations during the interviews. -

UC Berkeley Proceedings of the Annual Meeting of the Berkeley Linguistics Society
UC Berkeley Proceedings of the Annual Meeting of the Berkeley Linguistics Society Title Perception of Illegal Contrasts: Japanese Adaptations of Korean Coda Obstruents Permalink https://escholarship.org/uc/item/6x34v499 Journal Proceedings of the Annual Meeting of the Berkeley Linguistics Society, 36(36) ISSN 2377-1666 Author Whang, James D. Y. Publication Date 2016 Peer reviewed eScholarship.org Powered by the California Digital Library University of California PROCEEDINGS OF THE THIRTY SIXTH ANNUAL MEETING OF THE BERKELEY LINGUISTICS SOCIETY February 6-7, 2010 General Session Special Session Language Isolates and Orphans Parasession Writing Systems and Orthography Editors Nicholas Rolle Jeremy Steffman John Sylak-Glassman Berkeley Linguistics Society Berkeley, CA, USA Berkeley Linguistics Society University of California, Berkeley Department of Linguistics 1203 Dwinelle Hall Berkeley, CA 94720-2650 USA All papers copyright c 2016 by the Berkeley Linguistics Society, Inc. All rights reserved. ISSN: 0363-2946 LCCN: 76-640143 Contents Acknowledgments v Foreword vii Basque Genitive Case and Multiple Checking Xabier Artiagoitia . 1 Language Isolates and Their History, or, What's Weird, Anyway? Lyle Campbell . 16 Putting and Taking Events in Mandarin Chinese Jidong Chen . 32 Orthography Shapes Semantic and Phonological Activation in Reading Hui-Wen Cheng and Catherine L. Caldwell-Harris . 46 Writing in the World and Linguistics Peter T. Daniels . 61 When is Orthography Not Just Orthography? The Case of the Novgorod Birchbark Letters Andrew Dombrowski . 91 Gesture-to-Speech Mismatch in the Construction of Problem Solving Insight J.T.E. Elms . 101 Semantically-Oriented Vowel Reduction in an Amazonian Language Caleb Everett . 116 Universals in the Visual-Kinesthetic Modality: Politeness Marking Features in Japanese Sign Language (JSL) Johnny George . -

Germanic Standardizations: Past to Present (Impact: Studies in Language and Society)
<DOCINFO AUTHOR ""TITLE "Germanic Standardizations: Past to Present"SUBJECT "Impact 18"KEYWORDS ""SIZE HEIGHT "220"WIDTH "150"VOFFSET "4"> Germanic Standardizations Impact: Studies in language and society impact publishes monographs, collective volumes, and text books on topics in sociolinguistics. The scope of the series is broad, with special emphasis on areas such as language planning and language policies; language conflict and language death; language standards and language change; dialectology; diglossia; discourse studies; language and social identity (gender, ethnicity, class, ideology); and history and methods of sociolinguistics. General Editor Associate Editor Annick De Houwer Elizabeth Lanza University of Antwerp University of Oslo Advisory Board Ulrich Ammon William Labov Gerhard Mercator University University of Pennsylvania Jan Blommaert Joseph Lo Bianco Ghent University The Australian National University Paul Drew Peter Nelde University of York Catholic University Brussels Anna Escobar Dennis Preston University of Illinois at Urbana Michigan State University Guus Extra Jeanine Treffers-Daller Tilburg University University of the West of England Margarita Hidalgo Vic Webb San Diego State University University of Pretoria Richard A. Hudson University College London Volume 18 Germanic Standardizations: Past to Present Edited by Ana Deumert and Wim Vandenbussche Germanic Standardizations Past to Present Edited by Ana Deumert Monash University Wim Vandenbussche Vrije Universiteit Brussel/FWO-Vlaanderen John Benjamins Publishing Company Amsterdam/Philadelphia TM The paper used in this publication meets the minimum requirements 8 of American National Standard for Information Sciences – Permanence of Paper for Printed Library Materials, ansi z39.48-1984. Library of Congress Cataloging-in-Publication Data Germanic standardizations : past to present / edited by Ana Deumert, Wim Vandenbussche. -

Is Phonological Consonant Epenthesis Possible? a Series of Artificial Grammar Learning Experiments
Is Phonological Consonant Epenthesis Possible? A Series of Artificial Grammar Learning Experiments Rebecca L. Morley Abstract Consonant epenthesis is typically assumed to be part of the basic repertoire of phonological gram- mars. This implies that there exists some set of linguistic data that entails epenthesis as the best analy- sis. However, a series of artificial grammar learning experiments found no evidence that learners ever selected an epenthesis analysis. Instead, phonetic and morphological biases were revealed, along with individual variation in how learners generalized and regularized their input. These results, in combi- nation with previous work, suggest that synchronic consonant epenthesis may only emerge very rarely, from a gradual accumulation of changes over time. It is argued that the theoretical status of epenthesis must be reconsidered in light of these results, and that investigation of the sufficient learning conditions, and the diachronic developments necessary to produce those conditions, are of central importance to synchronic theory generally. 1 Introduction Epenthesis is defined as insertion of a segment that has no correspondent in the relevant lexical, or un- derlying, form. There are various types of epenthesis that can be defined in terms of either the insertion environment, the features of the epenthesized segment, or both. The focus of this paper is on consonant epenthesis and, more specifically, default consonant epenthesis that results in markedness reduction (e.g. Prince and Smolensky (1993/2004)). Consonant -

Downloaded an Applet That Would Allow the Recordings to Be Collected Remotely
UC Berkeley UC Berkeley PhonLab Annual Report Title A Survey of English Vowel Spaces of Asian American Californians Permalink https://escholarship.org/uc/item/4w84m8k4 Journal UC Berkeley PhonLab Annual Report, 12(1) ISSN 2768-5047 Author Cheng, Andrew Publication Date 2016 DOI 10.5070/P7121040736 Peer reviewed eScholarship.org Powered by the California Digital Library University of California UC Berkeley Phonetics and Phonology Lab Annual Report (2016) A Survey of English Vowel Spaces of Asian American Californians Andrew Cheng∗ May 2016 Abstract A phonetic study of the vowel spaces of 535 young speakers of Californian English showed that participation in the California Vowel Shift, a sound change unique to the West Coast region of the United States, varied depending on the speaker's self- identified ethnicity. For example, the fronting of the pre-nasal hand vowel varied by ethnicity, with White speakers participating the most and Chinese and South Asian speakers participating less. In another example, Korean and South Asian speakers of Californian English had a more fronted foot vowel than the White speakers. Overall, the study confirms that CVS is present in almost all young speakers of Californian English, although the degree of participation for any individual speaker is variable on account of several interdependent social factors. 1 Introduction This is a study on the English spoken by Americans of Asian descent living in California. Specifically, it will look at differences in vowel qualities between English speakers of various ethnic -

Sprache Der Gegenwart
SPRACHE DER GEGENWART Schriften des Instituts für deutsche Sprache Gemeinsam mit Hans Eggers, Johannes Erben, Odo Leys und Hans Neumann herausgegeben von Hugo Moser Schriftleitung: Ursula Hoberg BAND XXXVII Heinz Kloss DIE ENTWICKLUNG NEUER GERMANISCHER KULTURSPRACHEN SEIT 1800 2., erweiterte Auflage PÄDAGOGISCHER VERLAG SCHWANN DÜSSELDORF CIP-Kurztitelaufnahme der Deutschen Bibliothek Kloss, Heinz: Die Entwicklung neuer germanischer Kultursprachen seit 1800 [achtzehnhundert]. - 2., erw. Aufl. - Düsseldorf: Pädagogischer Verlag Schwann, 1978. (Sprache der Gegenwart; Bd. 37) ISBN 3-590-15637-6 © 1978 Pädagogischer Verlag Schwann Düsseldorf Alle Rechte Vorbehalten ■ 2. Auflage 1978 Umschlaggestaltung Paul Effert Herstellung Lengericher Handelsdruckerei Lengerich (Westf.) ISBN 3-590-15637-6 INHALTSVERZEICHNIS 0. Vorbemerkungen 9 0.1. Aus der Geschichte des Buches 9 0.2. Zum Titel des Buches 10 0.3. Einstimmung: Spracherneuerung und Nationalismus 13 1. Der linguistische und der soziologische Sprachbegriff 23 1.1. Über einige sprachsoziologische Grundbegriffe 23 1.1. 1. Ausbau und Abstand 23 1.1.2. Weiteres von den Einzelsprachen 30 1.2. Ausbaufragen 37 1.2.1. Ausbauweisen 37 1.2.2. Sachprosa 40 1.2.3. Ausbauphasen 46 1.2.4. Ausbaudialekte 55 1.2.5. Dachlose Außenmundarten 60 1.3. Abstandfragen 63 1.3.1. Wie m ißt man den Abstand? 63 1.3.2. Plurizentrische Hochsprachen 66 1.3.3. Scheindialektisierte Abstandsprachen 67 1.3.4. Kreolsprachen: ein von der Forschung neu er schlossener Typ von Abstandsprachen 70 1.4. Zusammenfassung und Vorausschau 79 1.4.1. Zusammenfassung des bisher Gesagten 79 1.4.2. Zur Gliederung der im 2. Kapitel näher behandelten Ausbausprachen und Ausbaudialekte 82 1.4.3. -

The Role of Morphology in Generative Phonology, Autosegmental Phonology and Prosodic Morphology
Chapter 20: The role of morphology in Generative Phonology, Autosegmental Phonology and Prosodic Morphology 1 Introduction The role of morphology in the rule-based phonology of the 1970’s and 1980’s, from classic GENERATIVE PHONOLOGY (Chomsky and Halle 1968) through AUTOSEGMENTAL PHONOLOGY (e.g., Goldsmith 1976) and PROSODIC MORPHOLOGY (e.g., McCarthy & Prince 1999, Steriade 1988), is that it produces the inputs on which phonology operates. Classic Generative, Autosegmental, and Prosodic Morphology approaches to phonology differ in the nature of the phonological rules and representations they posit, but converge in one key assumption: all implicitly or explicitly assume an item-based morphological approach to word formation, in which root and affix morphemes exist as lexical entries with underlying phonological representations. The morphological component of grammar selects the morphemes whose underlying phonological representations constitute the inputs on which phonological rules operate. On this view of morphology, the phonologist is assigned the task of identifying a set of general rules for a given language that operate correctly on the inputs provided by the morphology of that language to produce grammatical outputs. This assignment is challenging for a variety of reasons, sketched below; as a group, these reasons helped prompt the evolution from classic Generative Phonology to its Autosegmental and Prosodic descendants, and have since led to even more dramatic modifications in the way that morphology and phonology interact (see Chapter XXX). First, not all phonological rules apply uniformly across all morphological contexts. For example, Turkish palatal vowel harmony requires suffix vowels to agree with the preceding stem vowels (paşa ‘pasha’, paşa-lar ‘pasha-PL’; meze ‘appetizer’, meze-ler ‘appetizer-PL’) but does not apply within roots (elma ‘apple’, anne ‘mother’).