Intelligent Support for Exploration of Data Graphs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The KNIGHT REVISION of HORNBOSTEL-SACHS: a New Look at Musical Instrument Classification
The KNIGHT REVISION of HORNBOSTEL-SACHS: a new look at musical instrument classification by Roderic C. Knight, Professor of Ethnomusicology Oberlin College Conservatory of Music, © 2015, Rev. 2017 Introduction The year 2015 marks the beginning of the second century for Hornbostel-Sachs, the venerable classification system for musical instruments, created by Erich M. von Hornbostel and Curt Sachs as Systematik der Musikinstrumente in 1914. In addition to pursuing their own interest in the subject, the authors were answering a need for museum scientists and musicologists to accurately identify musical instruments that were being brought to museums from around the globe. As a guiding principle for their classification, they focused on the mechanism by which an instrument sets the air in motion. The idea was not new. The Indian sage Bharata, working nearly 2000 years earlier, in compiling the knowledge of his era on dance, drama and music in the treatise Natyashastra, (ca. 200 C.E.) grouped musical instruments into four great classes, or vadya, based on this very idea: sushira, instruments you blow into; tata, instruments with strings to set the air in motion; avanaddha, instruments with membranes (i.e. drums), and ghana, instruments, usually of metal, that you strike. (This itemization and Bharata’s further discussion of the instruments is in Chapter 28 of the Natyashastra, first translated into English in 1961 by Manomohan Ghosh (Calcutta: The Asiatic Society, v.2). The immediate predecessor of the Systematik was a catalog for a newly-acquired collection at the Royal Conservatory of Music in Brussels. The collection included a large number of instruments from India, and the curator, Victor-Charles Mahillon, familiar with the Indian four-part system, decided to apply it in preparing his catalog, published in 1880 (this is best documented by Nazir Jairazbhoy in Selected Reports in Ethnomusicology – see 1990 in the timeline below). -

Knee-Fiddles in Poland: Multidimensional Bridging of Paradigms
Knee-Fiddles in Poland: Multidimensional Bridging of Paradigms Ewa Dahlig-Turek Abstract: Knee-fiddles, i.e., bowed chordophones played in the vertical position, are an extinct group of musical instruments existing in the past in the Polish territory, known only from the few iconographic sources from the 17th and 19th century. Their peculiarity lies in the technique of shortening the strings – with the fingernails, and not with the fingertips. Modern attempts to reactivate the extinct tradition by introducing knee-fiddles to musical practice required several steps, from the reconstruction of the instruments to proposing a performance technique and repertoire. The process of reconstructing knee-fiddles and their respective performance practice turned out to be a multi-dimensional fusion of paradigms leading to the bridging of seemingly unconnected phenomena of different times (instrument), cultures (performance technique) or genres (repertoire): (1) historical fiddle-making paradigms have been converted into present-day folk fiddle construction for more effective playing (in terms of ergonomy and sound), (2) playing technique has been based on paradigms borrowed from distant cultures (in the absence of the local ones), (3) the repertoire has been created by overlapping paradigms of folk music and popular music in order to produce a repertoire acceptable for today’s listeners. Key words: chordophones, knee-fiddles, Polish folk music, fingernail technique. For more than a decade, we have been witnessing in Poland a strong activity of the “folky”1 music scene. By this term I understand music located at the intersection of folk music (usually Polish or from neighboring countries) and various genres of popular music. -

SILK ROAD: the Silk Road
SILK ROAD: The Silk Road (or Silk Routes) is an extensive interconnected network of trade routes across the Asian continent connecting East, South, and Western Asia with the Mediterranean world, as well as North and Northeast Africa and Europe. FIDDLE/VIOLIN: Turkic and Mongolian horsemen from Inner Asia were probably the world’s earliest fiddlers (see below). Their two-stringed upright fiddles called morin khuur were strung with horsehair strings, played with horsehair bows, and often feature a carved horse’s head at the end of the neck. The morin khuur produces a sound that is poetically described as “expansive and unrestrained”, like a wild horse neighing, or like a breeze in the grasslands. It is believed that these instruments eventually spread to China, India, the Byzantine Empire and the Middle East, where they developed into instruments such as the Erhu, the Chinese violin or 2-stringed fiddle, was introduced to China over a thousand years ago and probably came to China from Asia to the west along the silk road. The sound box of the Ehru is covered with python skin. The erhu is almost always tuned to the interval of a fifth. The inside string (nearest to player) is generally tuned to D4 and the outside string to A4. This is the same as the two middle strings of the violin. The violin in its present form emerged in early 16th-Century Northern Italy, where the port towns of Venice and Genoa maintained extensive ties to central Asia through the trade routes of the silk road. The violin family developed during the Renaissance period in Europe (16th century) when all arts flourished. -

The Science of String Instruments
The Science of String Instruments Thomas D. Rossing Editor The Science of String Instruments Editor Thomas D. Rossing Stanford University Center for Computer Research in Music and Acoustics (CCRMA) Stanford, CA 94302-8180, USA [email protected] ISBN 978-1-4419-7109-8 e-ISBN 978-1-4419-7110-4 DOI 10.1007/978-1-4419-7110-4 Springer New York Dordrecht Heidelberg London # Springer Science+Business Media, LLC 2010 All rights reserved. This work may not be translated or copied in whole or in part without the written permission of the publisher (Springer Science+Business Media, LLC, 233 Spring Street, New York, NY 10013, USA), except for brief excerpts in connection with reviews or scholarly analysis. Use in connection with any form of information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed is forbidden. The use in this publication of trade names, trademarks, service marks, and similar terms, even if they are not identified as such, is not to be taken as an expression of opinion as to whether or not they are subject to proprietary rights. Printed on acid-free paper Springer is part of Springer ScienceþBusiness Media (www.springer.com) Contents 1 Introduction............................................................... 1 Thomas D. Rossing 2 Plucked Strings ........................................................... 11 Thomas D. Rossing 3 Guitars and Lutes ........................................................ 19 Thomas D. Rossing and Graham Caldersmith 4 Portuguese Guitar ........................................................ 47 Octavio Inacio 5 Banjo ...................................................................... 59 James Rae 6 Mandolin Family Instruments........................................... 77 David J. Cohen and Thomas D. Rossing 7 Psalteries and Zithers .................................................... 99 Andres Peekna and Thomas D. -

Francesco Mancini Solos for a Flute
FRANCESCO MANCINI Solos for a Flute Gwyn Roberts recorder • flauto traverso CHANDOS early music Dedication of the first edition of ‘XII Solos for a Flute’ Francesco Mancini (1672 – 1737) Solos for a Flute with a Thorough Bass for the Harpsichord or for the Bass Violin (1724) Sonata VI 8:17 in B flat major • in B-Dur • en si bémol majeur alto recorder, theorbo, harpsichord, and cello 1 Largo 2:01 2 Allegro 2:23 3 Largo 2:07 4 Allegro 1:37 Sonata IV 8:40 in A minor • in a-Moll • en la mineur alto recorder, archlute, and cello 5 Spiritoso – Largo 2:01 6 Allegro 2:35 7 Largo 2:07 8 Allegro spiccato 1:48 3 Sonata X 8:05 in B minor • in h-Moll • en si mineur voice flute and harpsichord 9 Largo 1:54 10 Allegro 2:19 11 Largo 2:01 12 Allegro 1:43 Sonata XII 8:29 in G major • in G-Dur • en sol majeur flauto traverso, theorbo, harpsichord, and cello 13 Allegro – Largo 2:09 14 Allegro 2:56 15 Andante 1:53 16 Allegro 1:23 4 Sonata XI 9:37 in G minor • in g-Moll • en sol mineur alto recorder, theorbo, and organ 17 Un poco andante 2:42 18 Allegro 2:07 19 Largo 2:22 20 Allegro 2:18 Sonata I 8:49 in D minor • in d-Moll • en ré mineur alto recorder and archlute 21 Amoroso 2:03 22 Allegro 2:15 23 Largo 2:04 24 Allegro 2:18 5 Sonata II 8:16 in E minor • in e-Moll • en mi mineur flauto traverso, harpsichord, and cello 25 Andante 1:29 26 Allegro 2:29 27 Largo 1:45 28 Allegro 2:25 Sonata V 7:31 in D major • in D-Dur • en ré majeur voice flute, guitar, harpsichord, and cello 29 Allegro – Largo 1:59 30 Allegro 2:16 31 Largo 1:33 32 Allegro 1:35 TT 68:01 Tempesta -

NYRO 2004 Booklet.Pub
Society of Recorder Players Charity no 282751 Helen Hooker Information booklet Designed by Helen Beare Price £2 activities workshops serious study music & residential courses instruments Recorder recorder orchestras www.srp.org.uk This page is blank www.srp.org.uk President Sir Peter Maxwell Davies CBE Chairmain Andrew Short, 12 Woodburn Terrace, Edinburgh, EH10 4SJ [email protected] Secretary Alistair Read, 6 Upton Court, 56 East Dulwich Grove, London SE2 8PS The SRP is a registered charity, no 282751 The first version of this booklet was compiled for the National Youth Recorder Orchestra 2003 so that young players could learn more about what is happening in the recorder world in the UK, contribute to and extend it. NYRO 2003 was funded by Youth Music as part of their outreach programme. The SRP committee decided in 2003 that it would be useful for further copies to be produced for general use. In 2004 a copy, free of charge, is being supplied to each member of the SRP funded by the Arthur Ingram legacy to the Society. The booket’s information will also be on the SRP website. Every effor has been made to include suppliers, courses and other information, and omissions are unintended. One-day workshops and playdays are not included in the booklet. Readers should check the SRP website, the Recorder Magazine and SRP branch Secretaries for up-to-date information and workshops. With thanks to Davide Beare, Andrew Short, Ashley Allerton, David Scruby and Jeremy Burbridge for their help, SRP Branch Secretaries for their involvement, Harry Routledge for illustrations, and above all to the Arthur Ingram legacy. -

Instrument Descriptions
RENAISSANCE INSTRUMENTS Shawm and Bagpipes The shawm is a member of a double reed tradition traceable back to ancient Egypt and prominent in many cultures (the Turkish zurna, Chinese so- na, Javanese sruni, Hindu shehnai). In Europe it was combined with brass instruments to form the principal ensemble of the wind band in the 15th and 16th centuries and gave rise in the 1660’s to the Baroque oboe. The reed of the shawm is manipulated directly by the player’s lips, allowing an extended range. The concept of inserting a reed into an airtight bag above a simple pipe is an old one, used in ancient Sumeria and Greece, and found in almost every culture. The bag acts as a reservoir for air, allowing for continuous sound. Many civic and court wind bands of the 15th and early 16th centuries include listings for bagpipes, but later they became the provenance of peasants, used for dances and festivities. Dulcian The dulcian, or bajón, as it was known in Spain, was developed somewhere in the second quarter of the 16th century, an attempt to create a bass reed instrument with a wide range but without the length of a bass shawm. This was accomplished by drilling a bore that doubled back on itself in the same piece of wood, producing an instrument effectively twice as long as the piece of wood that housed it and resulting in a sweeter and softer sound with greater dynamic flexibility. The dulcian provided the bass for brass and reed ensembles throughout its existence. During the 17th century, it became an important solo and continuo instrument and was played into the early 18th century, alongside the jointed bassoon which eventually displaced it. -

The Nonlinear Physics of Musical Instruments
Rep. Prog. Phys. 62 (1999) 723–764. Printed in the UK PII: S0034-4885(99)65724-4 The nonlinear physics of musical instruments N H Fletcher Research School of Physical Sciences and Engineering, Australian National University, Canberra 0200, Australia Received 20 October 1998 Abstract Musical instruments are often thought of as linear harmonic systems, and a first-order description of their operation can indeed be given on this basis, once we recognise a few inharmonic exceptions such as drums and bells. A closer examination, however, shows that the reality is very different from this. Sustained-tone instruments, such as violins, flutes and trumpets, have resonators that are only approximately harmonic, and their operation and harmonic sound spectrum both rely upon the extreme nonlinearity of their driving mechanisms. Such instruments might be described as ‘essentially nonlinear’. In impulsively excited instruments, such as pianos, guitars, gongs and cymbals, however, the nonlinearity is ‘incidental’, although it may produce striking aural results, including transitions to chaotic behaviour. This paper reviews the basic physics of a wide variety of musical instruments and investigates the role of nonlinearity in their operation. 0034-4885/99/050723+42$59.50 © 1999 IOP Publishing Ltd 723 724 N H Fletcher Contents Page 1. Introduction 725 2. Sustained-tone instruments 726 3. Inharmonicity, nonlinearity and mode-locking 727 4. Bowed-string instruments 731 4.1. Linear harmonic theory 731 4.2. Nonlinear bowed-string generators 733 5. Wind instruments 735 6. Woodwind reed generators 736 7. Brass instruments 741 8. Flutes and organ flue pipes 745 9. Impulsively excited instruments 750 10. -

DBE Participation Commitment(S)
Attachment A Attachment B Pre-Proposal Conference for RFP 8-2039 Operations & Maintenance Services for the OC Streetcar Project Orange County Transportation Authority Agenda • Introductions • Safety/Emergency Evacuation • Online Business and Networking Tools • Key Procurement Information & Dates • Review of RFP Documents • Disadvantaged Business Enterprise (DBE) Requirements • Scope of Work • Questions and Answer 2 CAMM NET Registration Why register on CAMM NET? https://cammnet.octa.net/ • To receive e-mail notifications of Solicitations, Addenda and Awards • View and update your vendor profile • Required for Award 3 Online Business & Networking Tools • CAMM NET Connect • https://www.facebook.com/CammnetConnect • Working with OCTA • https://cammnet.octa.net/about-us/working/ • Planholder’s List • https://cammnet.octa.net/procurements/planholders-list-selection/ • Disadvantaged Business Enterprise (DBE) Program • https://cammnet.octa.net/dbe/ 4 Key Procurement Dates Written Questions Due: January 3, 2019 OCTA Responds: January 17, 2019 Proposals Due: February 12, 2019 2:00 PM Interviews: April 23, 2019 Board of Directors Award: November 25, 2019 5 Key Procurement Information • All questions/contact with Authority staff should be directed to the assigned Senior Contract Administrator, Irene Green. • Next Addendum will contain a copy of the Pre-Proposal sign-in sheet and today’s presentation • Award based on prime-sub relationship, not joint ventures • Contract term is for approximately 7 years; with 2, 2-year options • Funded with Federal Transit Administration (FTA) funds • DBE participation goal is 4% 6 Guidelines for Written Questions • Questions must be submitted directly to Irene Green, Senior Contract Administrator, in writing, by: January 3, 2019, 5:00 p.m. • E-mail recommended: [email protected] • Any changes Authority makes to procurement documents will be by written Addenda only • Addenda will be issued via CAMM NET • Today’s Verbal discussions today are non-binding 7 Next… Proposal Instructions Followed by …. -

SOUND EDUCATION Secondary Ensemble
SOUND EDUCATION Secondary Ensemble INTEGRAL MUSIC EDUCATION The explorations, free play and concentrated practices with sound and music should find their dedicated place and space in every educational The experience of recent decades in Music Education worldwide has environment to enhance the individual, group and social development and shown that culturally sensitized and integrative new approaches work ex- competency. traordinary well in imparting to the young generation the sense of wonder for music, the principles of harmony and the possibilities for a creative and SECONDARY INSTRUMENTS fulfilled life. This prepared ensemble of instruments is based on a careful selection We work toward a synthesis of innovative and traditional practices to devel - representing the different categories and types of instruments. Through it op an integral approach to curriculum development, learning materials and a full exposure of an original instrument circle with its diverse opportunities methodologies including a selected range of World Music Instruments. Based for free play and improvisation can be offered to the growing youth. on the qualities of different materials (stone, clay, wood, bamboo, reed, metal, glass) and the diverse ways of sound production (flutes, solids, strings, skins The instruments are ordered according to standard classification of aero- and voice) with a correlation with the elements (air, fire, water, earth and phones (winds), chordophones (strings), idiophones (percussion), mem- ether) a variable framework is set for creative encounter with and deepening branophones (skins), and nature sounds/atmospherics to encompass all research into the uniquely human faculty of musical expression. elements and parts of the being in an integration of head, heart and hara, mental cognition, vital emotion and physical perception and movement. -
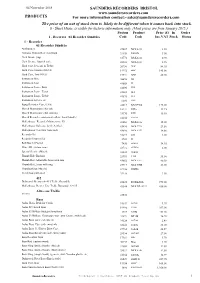
Old Stock List
04 November 2018 SAUNDERS RECORDERS BRISTOL www.saundersrecorders.com PRODUCTS For more information contact:- [email protected] The price of an out of stock item is likely to be different when it comes back into stock. 8 - Sheet Music, is visible for historic information, only. (Most prices are from January 2015.) System Product Price (£) In Order 1 - Recorder 01 Recorder Sundries Code Code Inc.VAT Stock Status 1 - Recorder 01 Recorder Sundries Antikondens 25027 MOL6138 2.50 Coolsma Thumb Rest. pearwood 34159 E005D 5.00 Cork Grease (cup) 31776 MOL6130 0.90 Cork Grease, lipstick style. 26185 MOL6131 2.25 Hard Case, Descant & Treble. 20930 2HC 84.95 Hard Case, Quartet (NSAT) 19972 4HC 145.00 Hard Case, Trio (NSA) 19941 3HC 80.00 Instrument Hire 36658 IH Instrument Loan 41669 IL Instrument Loan - Bass 41690 ILB Instrument Loan - Tenor 41683 ILT Instrument Loan - Treble 41676 ILA Instrument Service etc. 6606 JNE Kung Recorder Case, 6 Slot. 42017 KNG9964 175.00 Moeck Maintenance Kit (alt) 18241 KITa 19.95 Moeck Maintenance Kit (sopran) 31370 KITs 19.99 Moeck Recorder catalogues/leaflets. Small bundle! 41102 41102 Mollenhauer Recorder Maintenance Kit 43663 MOL6132 15.00 Mollenhauer Soft case for S+A, black 43496 MOL7710 21.50 Mollenhauer Teaching Aids pack 43090 MOL6233 14.60 Recorder Oil 31493 OIL 1.00 Recorder Unspecified 2783 R Roll Bag 12 Pocket 7450 86801 54.95 Sling, SR custom spare. 43731 SLING 6.00 Special Service (Moeck) 38430 38430 Thumb Hole Bushing 23993 THB 35.00 Thumb Rest Adjustable brass with ring. 43052 MOL6211 40.38 Thumb Rest, brass with ring. -

David-Murphy-An-African-Brecht.Pdf
Change of Focus—4 david murphy AN AFRICAN BRECHT The Cinema of Ousmane Sembene usmane Sembene, unruly progenitor of the new African cinema, was born in 1923 in the sleepy provincial port Oof Ziguinchor, Casamance, the southernmost province of French-run Senegal. His background was Muslim, Wolof- speaking, proletarian—his father a fisherman, who had left his ancestral village near Dakar for the south; prone to seasickness, Ousmane showed little aptitude for the family trade. It was a turbulent childhood. His par- ents split up early, and the boy—strong-minded and full of energy—was bundled from one set of relatives to another, ending up with his moth- er’s brother, Abdou Ramane Diop. A devout rural schoolteacher, Diop was an important influence, introducing Ousmane to the world of books and encouraging his questions. This favourite uncle died when Sembene was just thirteen. He moved to Dakar, staying with other relations, and enrolled for the certificat d’études, passport for clerical jobs open to Africans. But wilful and irreverent, Sembene was never the sort for the colonial administration. He was expelled from school, allegedly for raising his hand against a teacher, and ran through a series of manual jobs—mechanic, stonemason. His spare time was spent at the movies, or hanging out with friends in the central marketplace in Dakar, where the griots or gewels, the storytellers, spun their tales. Gewels ranked low in the Wolof caste hierarchy, but had traditional licence to depict and comment on all ranks, from king to beggar; the best had mastered the insights of xamxam, historical and new left review 16 july aug 2002 115 116 nlr 16 social knowledge—a formative influence in Sembene’s later work, as were the structuring tensions of African trickster stories: the narrative quest, the reversal of fortunes, the springing traps of power relations.1 Sembene was seventeen when Senegal’s colonial masters capitulated to Hitler, and was witness to the seamless reincarnation of Governor- General Boisson’s administration as an outpost of Vichy.