Acc~Pted ~V~L~~~~~~~
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fall 2012 Florida State Law Magazine
FLORIDA STATE LAW Inside Our First Seminole Chief Justice Annual Report Alumni Recognitions ALUMNI MAGAZINE FALL 2012 Message from the Dean Jobs, Alumni, Students and Admissions Players in the Jobs Market Admissions and Rankings This summer, the Wall Street The national press has highlighted the related phenomena Journal reported that we are the of the tight legal job market and rising student indebtedness. nation’s 25th best law school when it More prospective applicants are asking if a law degree is worth comes to placing our new graduates the cost, and law school applications are down significantly. in jobs that require law degrees. Just Ours have fallen by approximately 30% over the past two years. this month, Law School Transparency Moreover, our “yield” rate has gone down, meaning that fewer ranked us the nation’s 26th best law students are accepting our offers of admission. Our research school in terms of overall placement makes clear: prime competitor schools can offer far more score, and Florida’s best. Our web generous scholarship packages. To attract the top students, page includes more detailed information on our placement we must limit our enrollment and increase scholarship awards. outcomes. In short, we rank very high nationally in terms We are working with our university administration to limit of the number of students successfully placed. Although our our enrollment, which of course has financial implications average starting salary of $58,650 is less than those at the na- both for the law school and for the central university. It is tion’s most elite private law schools, so is our average student also imperative to increase our endowment in a way that will indebtedness, which is $73,113. -

Understanding Music Past and Present
Understanding Music Past and Present N. Alan Clark, PhD Thomas Heflin, DMA Jeffrey Kluball, EdD Elizabeth Kramer, PhD Understanding Music Past and Present N. Alan Clark, PhD Thomas Heflin, DMA Jeffrey Kluball, EdD Elizabeth Kramer, PhD Dahlonega, GA Understanding Music: Past and Present is licensed under a Creative Commons Attribu- tion-ShareAlike 4.0 International License. This license allows you to remix, tweak, and build upon this work, even commercially, as long as you credit this original source for the creation and license the new creation under identical terms. If you reuse this content elsewhere, in order to comply with the attribution requirements of the license please attribute the original source to the University System of Georgia. NOTE: The above copyright license which University System of Georgia uses for their original content does not extend to or include content which was accessed and incorpo- rated, and which is licensed under various other CC Licenses, such as ND licenses. Nor does it extend to or include any Special Permissions which were granted to us by the rightsholders for our use of their content. Image Disclaimer: All images and figures in this book are believed to be (after a rea- sonable investigation) either public domain or carry a compatible Creative Commons license. If you are the copyright owner of images in this book and you have not authorized the use of your work under these terms, please contact the University of North Georgia Press at [email protected] to have the content removed. ISBN: 978-1-940771-33-5 Produced by: University System of Georgia Published by: University of North Georgia Press Dahlonega, Georgia Cover Design and Layout Design: Corey Parson For more information, please visit http://ung.edu/university-press Or email [email protected] TABLE OF C ONTENTS MUSIC FUNDAMENTALS 1 N. -

Letter Was Presented to the Commissioner Signed by the Ceos of 50 Minority Owned AM Radio Licensees, Collectively Owning 140 AM Stations.'
NATIONAL ASSOCIATION OF BLACK OWNED BROADCASTERS 1201 Connecticut Avenue, N .W., Sui te 200, W ashington, D.C 20036 (202) 463-8970 • Fax: (2 02) 429-0657 September 2, 2015 BOARD OF DIRECTORS JAMES L. WINSlOI\ President Marlene H. Dortch, Secretary MICHAEL L. CARTER Vice President Federal Communications Commission KAREN E. SLADE 445 12th Street NW Treasurer C. LOIS E. WRIGHT Washington, D. 20554 Counsel 10 the 80ii1td ARTHUR BEN JAMI Re: Notice of Ex Parte Communication, MB Docket 13- CAROL MOORE CUTTING 249, Revitalization of the AM Radio Service ALFRED G. LIGGINS ("Notice") JE RRY LOPES DUJUAN MCCOY STEVEN ROBERTS Review of the Emergency Alert System (EB Docket MELODY SPANN-COOPER No. 04-296); Recommendations of the Independent JAMES E. WOL FE, JR. Panel Reviewing the Impact of Hurricane Katrina on Communications Networks (EB Docket 06-119) Dear Ms. Dortch: On September 1, 2015, the undersigned President of the National Association of Black Owned Broadcasters, Inc. ("NABOB") along with Francisco Montero of Fletcher, Heald & Hildreth, PLC, and David Honig, President Emeritus and Senior Advisor, Multicultural Media, Telecommunications and Internet Council ("MMTC") met with Commissioner Ajit Pai and Alison Nemeth, Legal Advisor, to discuss the most important and effective proposal set forth in the AM Revitalization Notice: opening an application filing window for FM translators that would be limited to AM broadcast licensees. As the Commission recognized in the Notice, the best way to help the largest number of AM stations to quickly and efficiently improve their service is to open such an AM-only window. Any other approach will make it extremely difficult, if not impossible, for AM stations, to obtain the translators they urgently need to remain competitive and provide our communities with the service they deserve. -
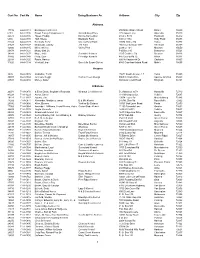
Cert No Name Doing Business As Address City Zip 1 Cust No
Cust No Cert No Name Doing Business As Address City Zip Alabama 17732 64-A-0118 Barking Acres Kennel 250 Naftel Ramer Road Ramer 36069 6181 64-A-0136 Brown Family Enterprises Llc Grandbabies Place 125 Aspen Lane Odenville 35120 22373 64-A-0146 Hayes, Freddy Kanine Konnection 6160 C R 19 Piedmont 36272 6394 64-A-0138 Huff, Shelia Blackjack Farm 630 Cr 1754 Holly Pond 35083 22343 64-A-0128 Kennedy, Terry Creeks Bend Farm 29874 Mckee Rd Toney 35773 21527 64-A-0127 Mcdonald, Johnny J M Farm 166 County Road 1073 Vinemont 35179 42800 64-A-0145 Miller, Shirley Valley Pets 2338 Cr 164 Moulton 35650 20878 64-A-0121 Mossy Oak Llc P O Box 310 Bessemer 35021 34248 64-A-0137 Moye, Anita Sunshine Kennels 1515 Crabtree Rd Brewton 36426 37802 64-A-0140 Portz, Stan Pineridge Kennels 445 County Rd 72 Ariton 36311 22398 64-A-0125 Rawls, Harvey 600 Hollingsworth Dr Gadsden 35905 31826 64-A-0134 Verstuyft, Inge Sweet As Sugar Gliders 4580 Copeland Island Road Mobile 36695 Arizona 3826 86-A-0076 Al-Saihati, Terrill 15672 South Avenue 1 E Yuma 85365 36807 86-A-0082 Johnson, Peggi Cactus Creek Design 5065 N. Main Drive Apache Junction 85220 23591 86-A-0080 Morley, Arden 860 Quail Crest Road Kingman 86401 Arkansas 20074 71-A-0870 & Ellen Davis, Stephanie Reynolds Wharton Creek Kennel 512 Madison 3373 Huntsville 72740 43224 71-A-1229 Aaron, Cheryl 118 Windspeak Ln. Yellville 72687 19128 71-A-1187 Adams, Jim 13034 Laure Rd Mountainburg 72946 14282 71-A-0871 Alexander, Marilyn & James B & M's Kennel 245 Mt. -

A History of English Literature MICHAEL ALEXANDER
A History of English Literature MICHAEL ALEXANDER [p. iv] © Michael Alexander 2000 All rights reserved. No reproduction, copy or transmission of this publication may be made without written permission. No paragraph of this publication may be reproduced, copied or transmitted save with written permission or in accordance with the provisions of the Copyright, Designs and Patents Act 1988, or under the terms of any licence permitting limited copying issued by the Copyright Licensing Agency, 90 Tottenham Court Road, London W 1 P 0LP. Any person who does any unauthorised act in relation to this publication may be liable to criminal prosecution and civil claims for damages. The author has asserted his right to be identified as the author of this work in accordance with the Copyright, Designs and Patents Act 1988. First published 2000 by MACMILLAN PRESS LTD Houndmills, Basingstoke, Hampshire RG21 6XS and London Companies and representatives throughout the world ISBN 0-333-91397-3 hardcover ISBN 0-333-67226-7 paperback A catalogue record for this book is available from the British Library. This book is printed on paper suitable for recycling and made from fully managed and sustained forest sources. 10 9 8 7 6 5 4 3 2 1 09 08 07 06 05 04 03 02 O1 00 Typeset by Footnote Graphics, Warminster, Wilts Printed in Great Britain by Antony Rowe Ltd, Chippenham, Wilts [p. v] Contents Acknowledgements The harvest of literacy Preface Further reading Abbreviations 2 Middle English Literature: 1066-1500 Introduction The new writing Literary history Handwriting -

Association of Educational Therapists, Inc. Last Updated 7044 S
Page 1 Association of Educational Therapists, Inc. Last Updated 7044 S. 13th St. 09/27/2021 02:30:03 Oak Creek, WI 53154 (414) 908-4949 Membership Directory To search within this pdf press (COMMAND-F) or (Ctrl+ F) depending upon your operating system. Australia ALLIED Brumfitt, Anne Telephone 400036240 Email [email protected] FAX Australia ASSOCIATE Wilson, Kerri MSpEd,BEd,BTeach LRW Pre-School Elementary Learning Ladders Australia PP 3 The Grove Telephone 0415837718 EdC Email [email protected] Thornlands Australia FAX Canada AB ASSOCIATE Ewen, Shauna M.Ed. +30, B.Ed LRW TEST ESL Adolescent Pre-School Adult Elementary Literacy For Life Reading Clinic, Inc. PP 304 Windermere Road Telephone +1 587 858 5700 PS Email [email protected] EdC Edmonton AB T6W 2P2 Canada FAX Canada BC ASSOCIATE Crescenzo, Tina M.Ed. LRW STSK ADV Adolescent Elementary Cobblestone Educational Therapy 2147 Knightswood Place Telephone 604-562-6202 Email [email protected] Burnaby BC V5A4B9 Canada FAX Last Updated 09/27/2021 02:30:05 Page 2 Association of Educational Therapists, Inc. Last Updated 7044 S. 13th St. 09/27/2021 02:30:05 Oak Creek, WI 53154 (414) 908-4949 Membership Directory To search within this pdf press (COMMAND-F) or (Ctrl+ F) depending upon your operating system. Canada ON ASSOCIATE Bajurny, Claire LRW STSK MATH ESL Adolescent Adult Elementary Telephone 6476172174 Email [email protected] The Hague 2555ME Netherlands FAX Leeder, Sheri B.A., B.Ed., M.Ed. LRW MATH TEST Adolescent Pre-School Elementary Ability Therapy Services RSP 50 Bournemouth Ave Telephone 519-404-9735 EdC Email [email protected] PP Kitchener ON N2B 1M7 Canada FAX France PROFESSIONAL Adibi, Denielle Education, M.A. -

Paper Number: 130 April 2017 Looking Through Headliner – Can RTHK Become “Hong Kong's BBC”? Hei Ting WONG University Of
Paper Number: 130 April 2017 Looking Through Headliner – Can RTHK Become “Hong Kong’s BBC”? Hei Ting WONG University of Pittsburgh Wong Hei Ting is a Scholar-in-Residence at the David C. Lam Institute for East-West Studies, Hong Kong Baptist University and a Ph.D. student in Ethnomusicology at the University of Pittsburgh. She received her bachelor’s degrees in Sociology and Applied Mathematics from the Chinese University of Hong Kong and the University of Oregon respectively, as well as an M.A. in Ethnomusicology from the University of Pittsburgh. Her research interests include: Chinese popular music in relation to identity construction, media and new media development, and political influences in post-colonial Hong Kong; Mandarin popular and rock music in Taiwan; and music-related educational issues. David C. Lam Institute for East-West Studies (LEWI) Hong Kong Baptist University (HKBU) LEWI Working Paper Series is an endeavour of David C. Lam Institute for East-West Studies (LEWI), a consortium with 28 member universities, to foster dialogue among scholars in the field of East-West studies. Globalisation has multiplied and accelerated inter-cultural, inter-ethnic, and inter-religious encounters, intentionally or not. In a world where time and place are increasingly compressed and interaction between East and West grows in density, numbers, and spread, East-West studies has gained a renewed mandate. LEWI’s Working Paper Series provides a forum for the speedy and informal exchange of ideas, as scholars and academic institutions attempt to grapple with issues of an inter-cultural and global nature. Circulation of this series is free of charge. -

Fireworks FIREWORKS
THURSDAY, JULY S, 1947 ^iTAGE FOURTEEN ^anrtfPBtrr lEuruins Airraid Avbnct Dally Clrtolatlon T k d W M tb c r For the Moirth of tase. 1917 FOroeaot of C. B. Weather Barvaa , At Oie ratular Monday meeUnf of the Kiwanla Club of Mani heater Troth .\nnounrcfl Ex|mm1 Change Brrolurh Affianml Ei<i;lit Appeals . 9 ^ 5 5 Mentty riossdy cB b abnwvrs aod About Town j to be held at the Manrh-«t-r Mesobor of ttw Aodlt ranttgaad rolbrr warns aad booMt Conntrv rliih a sound niotn n pic Announcement itUunrjjYBi^ir siBirsiu ture will he «h >-n entitled ' N- I I I Vrl Plans j Before Boanl Bareem of dm slolleee AH «B«Baber« of Uie A; r Help Wanted" If i» on the Manchester—^A City of f illage Charm UnloB w « roque*tf .1 . > ^ 1 amralirn to «er-.ire the r*-'iTipl'* <•- M the hUMletacd at MeftioaUI t wl<l THE J. W. HALE CORPORATION ment o' returned han<lt<apped vet Mu'! .\uw*iiil PrfiHoti /oiling Boanl Mrrliiig Satween 7 and ":30 tomorrow eran* a"d other* The iiK - tma v d1 VOL. LX V l„ NO. 233 fClaaaiece Ae*er«Mag oo tmge If) M A N C H E S T E R . C O N N ., M O N D A Y . J U L Y 7. 1947 (TWELVE PA0E8) PRICE FOUR CENTH ai|bt. be held at n.» n nr u> *1 Kr -nk Krm illy Siilmiillrfl to It* Srhriliilpfl for Nrxl * A N D PImon I* •'herlulrd to f irn 'i H- erotd A*new of 51 Branford attendance price. -

National Languages and Teacher Training in Africa: Methodological Guide No. 3; Practical Training Documents for Those Responsibl
National languages and teacher training in Africa i al studie UNESCO Publishing __ _,__.. “..-=l __^.d, ” List of titles* 1. Education in the Arab region viewed from the 1970 35. Non-formal education and education policy in Ghana Marrakesh Conference (E,F) and Senegal (E,F) 2. Agriculture and general education (E,F) 36. Education in the Arab States in the light of the Abu 3. Teachers and educational policy (E,F) Dhabi Conference 1977 (E,F,A) 4. Comparative study of secondary school building costs 37. The child’s first learning environment - selected (E,F,S) readings in home economics (E,F,S) 5. Literacy for working: functional literacy in rural 38. Education in Asia and Oceania: a challenge for the Tanzania (EJ?) 1980s (E,F,R) 6. Rights and responsibilities of youth (E,F,S,R) 39. Self-management in educational systems (E,F,S) 7. Growth and change: perspectives of education in Asia 40. Impact of educational television on young children GW) (E.F.S) 8. Sports facilities for schools in developing countries 41. World.problems in the classroom (E,F,S) (E,F) 42. Literacy and illiteracy (E,F,S,A) 9. Possibilities and limitations of functional literacy: the 43. The training of teacher educators (E,F,S,A) Iranian experiment (E,F) 44. Recognition of studies and competence: implementation 10. Functional literacy in Mali: training for development of conventions drawn up under the aegis of UNESCO; (E,W nature and role of national bodies (E,F) 11. Anthropology and language science in educational 45. -

Primary & Secondary Sources
Primary & Secondary Sources Brands & Products Agencies & Clients Media & Content Influencers & Licensees Organizations & Associations Government & Education Research & Data Multicultural Media Forecast 2019: Primary & Secondary Sources COPYRIGHT U.S. Multicultural Media Forecast 2019 Exclusive market research & strategic intelligence from PQ Media – Intelligent data for smarter business decisions In partnership with the Alliance for Inclusive and Multicultural Marketing at the Association of National Advertisers Co-authored at PQM by: Patrick Quinn – President & CEO Leo Kivijarv, PhD – EVP & Research Director Editorial Support at AIMM by: Bill Duggan – Group Executive Vice President, ANA Claudine Waite – Director, Content Marketing, Committees & Conferences, ANA Carlos Santiago – President & Chief Strategist, Santiago Solutions Group Except by express prior written permission from PQ Media LLC or the Association of National Advertisers, no part of this work may be copied or publicly distributed, displayed or disseminated by any means of publication or communication now known or developed hereafter, including in or by any: (i) directory or compilation or other printed publication; (ii) information storage or retrieval system; (iii) electronic device, including any analog or digital visual or audiovisual device or product. PQ Media and the Alliance for Inclusive and Multicultural Marketing at the Association of National Advertisers will protect and defend their copyright and all their other rights in this publication, including under the laws of copyright, misappropriation, trade secrets and unfair competition. All information and data contained in this report is obtained by PQ Media from sources that PQ Media believes to be accurate and reliable. However, errors and omissions in this report may result from human error and malfunctions in electronic conversion and transmission of textual and numeric data. -
S4nena Exercises Emphasize Melody, Pitch, Chords, Intervalsand Scales
DOCUMENT RESUME ED 205 315 RC 012 B28 AUTHOR Ott, Mary Lou, Comp. TITLE Small Schools Mnsic Turriculum, K-3: Scope, Objectives, Activities, Resources, Monitoring Procedures. The Comprehensive Arts in Education Program. INSTITUTION Educational Service District 121, Seattle, Wash.: washincton Office of the State Superintendent of Public Instruction, Olympia. PUB DATE Ang 77 NOTE' 631p.: For related documents, see RC 012 825-827 and PC 012 829-851. EDPS PPICE MF03/PC26 Plus Postage. DES' RTPTOPS *Behavioral Objectives: Educational Objectives: *instructional Materials: LearningActivities: *Music Activities: Music Appreciation: *Music Education: Music Theory: Primary Education: *Resource Materials: *Small Schools: State Curriculum Guides: Student Evaluation ABSTRACT By following the Washington Small Schools Zurriculum format of listing learning objectives with recommendedgrade olacement levels and suggested activities, monitoringprocedures, and resources used in teaching, this music curriculum for grades K-3 encourages teacher involvement and decisior making. Goals for the proaram focus on the student, encouragina each to value the study of muslc and recognize its usefulness, to participate in theperformance of music, to create musical expression and to listento music. Moving (rhythm) ,singing (melody), playina, sharing, creating and listening are the maior concepts around which the curriculum is bUilt. Rhythm activities stress beat, duration, accent, meter, tempo andresponse. S4nena exercises emphasize melody, pitch, chords, intervalsand scales. Playing instruction includes introductionsto the science of sound, instruments and environmental sounds. Sharing involves acquiring appropriate performance behavior and valuingthe personal satisfaction resulting from musical performance. Creatingfocuses on- structure and composition. Listening explores appreciation,mood and express4on and careers. Included ir a final sectionare song samples, patterns, devised notation, song and listerina lists,a bibliography a-d a discography. -
About This Report
Reporting Principles and Framework the material matters for our value creation journey. This Integrated Annual Report complies with the Bursa Our holistic response to these material matters is addressed Malaysia Securities Berhad Main Market Listing Requirements through Astro’s five Strategic Drivers namely Content, ABOUT THIS (“MMLR”) and is guided by the International Integrated Customer, Experience & Technology, Talent as well as Reporting Framework issued by the International Integrated Community & Environment, with business strategies Reporting Council (“IIRC”). The provisions of the Malaysian developed centering around these Strategic Drivers. REPORT Code on Corporate Governance 2017 (“MCCG”) are also applied, unless otherwise stated in our Corporate Governance Approval by Board Astro Malaysia Holdings Berhad’s (“AMH”) Report. Our Board has collectively reviewed this report as guided by the IIRC’s International Integrated Reporting Framework AMH’s audited financial statements for FY21 have been and acknowledges its responsibility in ensuring the integrity Integrated Annual Report 2021 prepared in accordance with the Malaysian Financial of this IAR2021, through good governance practices and Reporting Standards (MFRS), the International Financial internal reporting procedures. (“IAR2021”) provides a holistic, balanced overview Reporting Standards (IFRS) and the Companies Act 2016 (“Act”). FTSE4GOOD Bursa Malaysia Index AMH is a founding constituent of the FTSE4GOOD Bursa of strategies in place Our sustainability disclosures encompassing