A Large Multi-Target Dataset of Common Bengali Handwritten Graphemes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Talking Stone: Cherokee Syllabary Inscriptions in Dark Zone Caves
University of Tennessee, Knoxville TRACE: Tennessee Research and Creative Exchange Masters Theses Graduate School 12-2017 Talking Stone: Cherokee Syllabary Inscriptions in Dark Zone Caves Beau Duke Carroll University of Tennessee, [email protected] Follow this and additional works at: https://trace.tennessee.edu/utk_gradthes Recommended Citation Carroll, Beau Duke, "Talking Stone: Cherokee Syllabary Inscriptions in Dark Zone Caves. " Master's Thesis, University of Tennessee, 2017. https://trace.tennessee.edu/utk_gradthes/4985 This Thesis is brought to you for free and open access by the Graduate School at TRACE: Tennessee Research and Creative Exchange. It has been accepted for inclusion in Masters Theses by an authorized administrator of TRACE: Tennessee Research and Creative Exchange. For more information, please contact [email protected]. To the Graduate Council: I am submitting herewith a thesis written by Beau Duke Carroll entitled "Talking Stone: Cherokee Syllabary Inscriptions in Dark Zone Caves." I have examined the final electronic copy of this thesis for form and content and recommend that it be accepted in partial fulfillment of the requirements for the degree of Master of Arts, with a major in Anthropology. Jan Simek, Major Professor We have read this thesis and recommend its acceptance: David G. Anderson, Julie L. Reed Accepted for the Council: Dixie L. Thompson Vice Provost and Dean of the Graduate School (Original signatures are on file with official studentecor r ds.) Talking Stone: Cherokee Syllabary Inscriptions in Dark Zone Caves A Thesis Presented for the Master of Arts Degree The University of Tennessee, Knoxville Beau Duke Carroll December 2017 Copyright © 2017 by Beau Duke Carroll All rights reserved ii ACKNOWLEDGMENTS This thesis would not be possible without the following people who contributed their time and expertise. -

Introduction
INTRODUCTION ’ P”(Bha.t.tikāvya) is one of the boldest “B experiments in classical literature. In the formal genre of “great poem” (mahākāvya) it incorprates two of the most powerful Sanskrit traditions, the “Ramáyana” and Pánini’s grammar, and several other minor themes. In this one rich mix of science and art, Bhatti created both a po- etic retelling of the adventures of Rama and a compendium of examples of grammar, metrics, the Prakrit language and rhetoric. As literature, his composition stands comparison with the best of Sanskrit poetry, in particular cantos , and . “Bhatti’s Poem” provides a comprehensive exem- plification of Sanskrit grammar in use and a good introduc- tion to the science (śāstra) of poetics or rhetoric (alamk. āra, lit. ornament). It also gives a taster of the Prakrit language (a major component in every Sanskrit drama) in an easily ac- cessible form. Finally it tells the compelling story of Prince Rama in simple elegant Sanskrit: this is the “Ramáyana” faithfully retold. e learned Indian curriculum in late classical times had at its heart a system of grammatical study and linguistic analysis. e core text for this study was the notoriously difficult “Eight Books” (A.s.tādhyāyī) of Pánini, the sine qua non of learning composed in the fourth century , and arguably the most remarkable and indeed foundational text in the history of linguistics. Not only is the “Eight Books” a description of a language unmatched in totality for any language until the nineteenth century, but it is also pre- sented in the most compact form possible through the use xix of an elaborate and sophisticated metalanguage, again un- known anywhere else in linguistics before modern times. -

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -

Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-04-22 Document version: 2.7 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract This document lays down the Label Generation Ruleset for Gurmukhi script. Three main components of the Gurmukhi Script LGR i.e. Code point repertoire, Variants and Whole Label Evaluation Rules have been described in detail here. All these components have been incorporated in a machine-readable format in the accompanying XML file named "proposal-gurmukhi-lgr-22apr19-en.xml". In addition, a document named “gurmukhi-test-labels-22apr19-en.txt” has been provided. It provides a list of labels which can produce variants as laid down in Section 6 of this document and it also provides valid and invalid labels as per the Whole Label Evaluation laid down in Section 7. 2. Script for which the LGR is proposed ISO 15924 Code: Guru ISO 15924 Key N°: 310 ISO 15924 English Name: Gurmukhi Latin transliteration of native script name: gurmukhī Native name of the script: ਗੁਰਮੁਖੀ Maximal Starting Repertoire [MSR] version: 4 1 3. Background on Script and Principal Languages Using It 3.1. The Evolution of the Script Like most of the North Indian writing systems, the Gurmukhi script is a descendant of the Brahmi script. The Proto-Gurmukhi letters evolved through the Gupta script from 4th to 8th century, followed by the Sharda script from 8th century onwards and finally adapted their archaic form in the Devasesha stage of the later Sharda script, dated between the 10th and 14th centuries. -
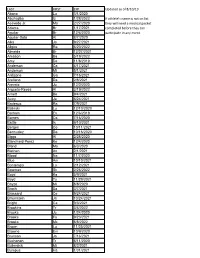
LAST FIRST EXP Updated As of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If Athlete's Name Is Not on List Acevedo Jr
LAST FIRST EXP Updated as of 8/10/19 Abano Lu 3/1/2020 Abuhadba Iz 1/28/2022 If athlete's name is not on list Acevedo Jr. Ma 2/27/2020 they will need a medical packet Adams Br 1/17/2021 completed before they can Aguilar Br 12/6/2020 participate in any event. Aguilar-Soto Al 8/7/2020 Alka Ja 9/27/2021 Allgire Ra 6/20/2022 Almeida Br 12/27/2021 Amason Ba 5/19/2022 Amy De 11/8/2019 Anderson Ca 4/17/2021 Anderson Mi 5/1/2021 Ardizone Ga 7/16/2021 Arellano Da 2/8/2021 Arevalo Ju 12/2/2020 Argueta-Reyes Al 3/19/2022 Arnett Be 9/4/2021 Autry Ja 6/24/2021 Badeaux Ra 7/9/2021 Balinski Lu 12/10/2020 Barham Ev 12/6/2019 Barnes Ca 7/16/2020 Battle Is 9/10/2021 Bergen Co 10/11/2021 Bermudez Da 10/16/2020 Biggs Al 2/28/2020 Blanchard-Perez Ke 12/4/2020 Bland Ma 6/3/2020 Blethen An 2/1/2021 Blood Na 11/7/2020 Blue Am 10/10/2021 Bontempo Lo 2/12/2021 Bowman Sk 2/26/2022 Boyd Ka 5/9/2021 Boyd Ty 11/29/2021 Boyzo Mi 8/8/2020 Brach Sa 3/7/2021 Brassard Ce 9/24/2021 Braunstein Ja 10/24/2021 Bright Ca 9/3/2021 Brookins Tr 3/4/2022 Brooks Ju 1/24/2020 Brooks Fa 9/23/2021 Brooks Mc 8/8/2022 Brown Lu 11/25/2021 Browne Em 10/9/2020 Brunson Jo 7/16/2021 Buchanan Tr 6/11/2020 Bullerdick Mi 8/2/2021 Bumpus Ha 1/31/2021 LAST FIRST EXP Updated as of 8/10/19 Burch Co 11/7/2020 Burch Ma 9/9/2021 Butler Ga 5/14/2022 Byers Je 6/14/2021 Cain Me 6/20/2021 Cao Tr 11/19/2020 Carlson Be 5/29/2021 Cerda Da 3/9/2021 Ceruto Ri 2/14/2022 Chang Ia 2/19/2021 Channapati Di 10/31/2021 Chao Et 8/20/2021 Chase Em 8/26/2020 Chavez Fr 6/13/2020 Chavez Vi 11/14/2021 Chidambaram Ga 10/13/2019 -

Kharosthi Manuscripts: a Window on Gandharan Buddhism*
KHAROSTHI MANUSCRIPTS: A WINDOW ON GANDHARAN BUDDHISM* Andrew GLASS INTRODUCTION In the present article I offer a sketch of Gandharan Buddhism in the centuries around the turn of the common era by looking at various kinds of evidence which speak to us across the centuries. In doing so I hope to shed a little light on an important stage in the transmission of Buddhism as it spread from India, through Gandhara and Central Asia to China, Korea, and ultimately Japan. In particular, I will focus on the several collections of Kharo~thi manuscripts most of which are quite new to scholarship, the vast majority of these having been discovered only in the past ten years. I will also take a detailed look at the contents of one of these manuscripts in order to illustrate connections with other text collections in Pali and Chinese. Gandharan Buddhism is itself a large topic, which cannot be adequately described within the scope of the present article. I will therefore confine my observations to the period in which the Kharo~thi script was used as a literary medium, that is, from the time of Asoka in the middle of the third century B.C. until about the third century A.D., which I refer to as the Kharo~thi Period. In addition to looking at the new manuscript materials, other forms of evidence such as inscriptions, art and architecture will be touched upon, as they provide many complementary insights into the Buddhist culture of Gandhara. The travel accounts of the Chinese pilgrims * This article is based on a paper presented at Nagoya University on April 22nd 2004. -

Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging
ORIGINAL ARTICLE Neuroscience http://dx.doi.org/10.3346/jkms.2014.29.10.1416 • J Korean Med Sci 2014; 29: 1416-1424 Neural Substrates of Hanja (Logogram) and Hangul (Phonogram) Character Readings by Functional Magnetic Resonance Imaging Zang-Hee Cho,1 Nambeom Kim,1 The two basic scripts of the Korean writing system, Hanja (the logography of the traditional Sungbong Bae,2 Je-Geun Chi,1 Korean character) and Hangul (the more newer Korean alphabet), have been used together Chan-Woong Park,1 Seiji Ogawa,1,3 since the 14th century. While Hanja character has its own morphemic base, Hangul being and Young-Bo Kim1 purely phonemic without morphemic base. These two, therefore, have substantially different outcomes as a language as well as different neural responses. Based on these 1Neuroscience Research Institute, Gachon University, Incheon, Korea; 2Department of linguistic differences between Hanja and Hangul, we have launched two studies; first was Psychology, Yeungnam University, Kyongsan, Korea; to find differences in cortical activation when it is stimulated by Hanja and Hangul reading 3Kansei Fukushi Research Institute, Tohoku Fukushi to support the much discussed dual-route hypothesis of logographic and phonological University, Sendai, Japan routes in the brain by fMRI (Experiment 1). The second objective was to evaluate how Received: 14 February 2014 Hanja and Hangul affect comprehension, therefore, recognition memory, specifically the Accepted: 5 July 2014 effects of semantic transparency and morphemic clarity on memory consolidation and then related cortical activations, using functional magnetic resonance imaging (fMRI) Address for Correspondence: (Experiment 2). The first fMRI experiment indicated relatively large areas of the brain are Young-Bo Kim, MD Department of Neuroscience and Neurosurgery, Gachon activated by Hanja reading compared to Hangul reading. -

OSU WPL # 27 (1983) 140- 164. the Elimination of Ergative Patterns Of
OSU WPL # 27 (1983) 140- 164. The Elimination of Ergative Patterns of Case-Marking and Verbal Agreement in Modern Indic Languages Gregory T. Stump Introduction. As is well known, many of the modern Indic languages are partially ergative, showing accusative patterns of case- marking and verbal agreement in nonpast tenses, but ergative patterns in some or all past tenses. This partial ergativity is not at all stable in these languages, however; what I wish to show in the present paper, in fact, is that a large array of factors is contributing to the elimination of partial ergativity in the modern Indic languages. The forces leading to the decay of ergativity are diverse in nature; and any one of these may exert a profound influence on the syntactic development of one language but remain ineffectual in another. Before discussing this erosion of partial ergativity in Modern lndic, 1 would like to review the history of what the I ndian grammar- ians call the prayogas ('constructions') of a past tense verb with its subject and direct object arguments; the decay of Indic ergativity is, I believe, best envisioned as the effect of analogical develop- ments on or within the system of prayogas. There are three prayogas in early Modern lndic. The first of these is the kartariprayoga, or ' active construction' of intransitive verbs. In the kartariprayoga, the verb agrees (in number and p,ender) with its subject, which is in the nominative case--thus, in Vernacular HindOstani: (1) kartariprayoga: 'aurat chali. mard chala. woman (nom.) went (fern. sg.) man (nom.) went (masc. -

Recognition of Online Handwritten Gurmukhi Strokes Using Support Vector Machine a Thesis
Recognition of Online Handwritten Gurmukhi Strokes using Support Vector Machine A Thesis Submitted in partial fulfillment of the requirements for the award of the degree of Master of Technology Submitted by Rahul Agrawal (Roll No. 601003022) Under the supervision of Dr. R. K. Sharma Professor School of Mathematics and Computer Applications Thapar University Patiala School of Mathematics and Computer Applications Thapar University Patiala – 147004 (Punjab), INDIA June 2012 (i) ABSTRACT Pen-based interfaces are becoming more and more popular and play an important role in human-computer interaction. This popularity of such interfaces has created interest of lot of researchers in online handwriting recognition. Online handwriting recognition contains both temporal stroke information and spatial shape information. Online handwriting recognition systems are expected to exhibit better performance than offline handwriting recognition systems. Our research work presented in this thesis is to recognize strokes written in Gurmukhi script using Support Vector Machine (SVM). The system developed here is a writer independent system. First chapter of this thesis report consist of a brief introduction to handwriting recognition system and some basic differences between offline and online handwriting systems. It also includes various issues that one can face during development during online handwriting recognition systems. A brief introduction about Gurmukhi script has also been given in this chapter In the last section detailed literature survey starting from the 1979 has also been given. Second chapter gives detailed information about stroke capturing, preprocessing of stroke and feature extraction. These phases are considered to be backbone of any online handwriting recognition system. Recognition techniques that have been used in this study are discussed in chapter three. -

Review of Research
Review Of ReseaRch impact factOR : 5.7631(Uif) UGc appROved JOURnal nO. 48514 issn: 2249-894X vOlUme - 8 | issUe - 7 | apRil - 2019 __________________________________________________________________________________________________________________________ AN ANALYSIS OF CURRENT TRENDS FOR SANSKRIT AS A COMPUTER PROGRAMMING LANGUAGE Manish Tiwari1 and S. Snehlata2 1Department of Computer Science and Application, St. Aloysius College, Jabalpur. 2Student, Deparment of Computer Science and Application, St. Aloysius College, Jabalpur. ABSTRACT : Sanskrit is said to be one of the systematic language with few exception and clear rules discretion.The discussion is continued from last thirtythat language could be one of best option for computers.Sanskrit is logical and clear about its grammatical and phonetically laws, which are not amended from thousands of years. Entire Sanskrit grammar is based on only fourteen sutras called Maheshwar (Siva) sutra, Trimuni (Panini, Katyayan and Patanjali) are responsible for creation,explainable and exploration of these grammar laws.Computer as machine,requires such language to perform better and faster with less programming.Sanskrit can play important role make computer programming language flexible, logical and compact. This paper is focused on analysis of current status of research done on Sanskrit as a programming languagefor .These will the help us to knowopportunity, scope and challenges. KEYWORDS : Artificial intelligence, Natural language processing, Sanskrit, Computer, Vibhakti, Programming language. -

The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes
Portland State University PDXScholar Mathematics and Statistics Faculty Fariborz Maseeh Department of Mathematics Publications and Presentations and Statistics 3-2018 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hu Sun University of Macau Christine Chambris Université de Cergy-Pontoise Judy Sayers Stockholm University Man Keung Siu University of Hong Kong Jason Cooper Weizmann Institute of Science SeeFollow next this page and for additional additional works authors at: https:/ /pdxscholar.library.pdx.edu/mth_fac Part of the Science and Mathematics Education Commons Let us know how access to this document benefits ou.y Citation Details Sun X.H. et al. (2018) The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes. In: Bartolini Bussi M., Sun X. (eds) Building the Foundation: Whole Numbers in the Primary Grades. New ICMI Study Series. Springer, Cham This Book Chapter is brought to you for free and open access. It has been accepted for inclusion in Mathematics and Statistics Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Authors Xu Hu Sun, Christine Chambris, Judy Sayers, Man Keung Siu, Jason Cooper, Jean-Luc Dorier, Sarah Inés González de Lora Sued, Eva Thanheiser, Nadia Azrou, Lynn McGarvey, Catherine Houdement, and Lisser Rye Ejersbo This book chapter is available at PDXScholar: https://pdxscholar.library.pdx.edu/mth_fac/253 Chapter 5 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hua Sun , Christine Chambris Judy Sayers, Man Keung Siu, Jason Cooper , Jean-Luc Dorier , Sarah Inés González de Lora Sued , Eva Thanheiser , Nadia Azrou , Lynn McGarvey , Catherine Houdement , and Lisser Rye Ejersbo 5.1 Introduction Mathematics learning and teaching are deeply embedded in history, language and culture (e.g. -

Writing Systems Reading and Spelling
Writing systems Reading and spelling Writing systems LING 200: Introduction to the Study of Language Hadas Kotek February 2016 Hadas Kotek Writing systems Writing systems Reading and spelling Outline 1 Writing systems 2 Reading and spelling Spelling How we read Slides credit: David Pesetsky, Richard Sproat, Janice Fon Hadas Kotek Writing systems Writing systems Reading and spelling Writing systems What is writing? Writing is not language, but merely a way of recording language by visible marks. –Leonard Bloomfield, Language (1933) Hadas Kotek Writing systems Writing systems Reading and spelling Writing systems Writing and speech Until the 1800s, writing, not spoken language, was what linguists studied. Speech was often ignored. However, writing is secondary to spoken language in at least 3 ways: Children naturally acquire language without being taught, independently of intelligence or education levels. µ Many people struggle to learn to read. All human groups ever encountered possess spoken language. All are equal; no language is more “sophisticated” or “expressive” than others. µ Many languages have no written form. Humans have probably been speaking for as long as there have been anatomically modern Homo Sapiens in the world. µ Writing is a much younger phenomenon. Hadas Kotek Writing systems Writing systems Reading and spelling Writing systems (Possibly) Independent Inventions of Writing Sumeria: ca. 3,200 BC Egypt: ca. 3,200 BC Indus Valley: ca. 2,500 BC China: ca. 1,500 BC Central America: ca. 250 BC (Olmecs, Mayans, Zapotecs) Hadas Kotek Writing systems Writing systems Reading and spelling Writing systems Writing and pictures Let’s define the distinction between pictures and true writing.