String Functions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UTF-8-Plan9-Paper
Hello World or Kαληµε´ρα κο´σµε or Rob Pike Ken Thompson AT&T Bell Laboratories Murray Hill, New Jersey 07974 ABSTRACT Plan 9 from Bell Labs has recently been converted from ASCII to an ASCII- compatible variant of Unicode, a 16-bit character set. In this paper we explain the rea- sons for the change, describe the character set and representation we chose, and present the programming models and software changes that support the new text format. Although we stopped short of full internationalizationÐfor example, system error mes- sages are in Unixese, not JapaneseÐwe believe Plan 9 is the first system to treat the rep- resentation of all major languages on a uniform, equal footing throughout all its software. Introduction The world is multilingual but most computer systems are based on English and ASCII. The release of Plan 9 [Pike90], a new distributed operating system from Bell Laboratories, seemed a good occasion to correct this chauvinism. It is easier to make such deep changes when building new systems than by refit- ting old ones. The ANSI C standard [ANSIC] contains some guidance on the matter of ‘wide’ and ‘multi-byte’ characters but falls far short of solving the myriad associated problems. We could find no literature on how to convert a system to larger character sets, although some individual programs had been converted. This paper reports what we discovered as we explored the problem of representing multilingual text at all levels of an operating system, from the file system and kernel through the applications and up to the window sys- tem and display. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

Detection of Suspicious IDN Homograph Domains Using Active DNS Measurements
A Case of Identity: Detection of Suspicious IDN Homograph Domains Using Active DNS Measurements Ramin Yazdani Olivier van der Toorn Anna Sperotto University of Twente University of Twente University of Twente Enschede, The Netherlands Enschede, The Netherlands Enschede, The Netherlands [email protected] [email protected] [email protected] Abstract—The possibility to include Unicode characters in problem in the case of Unicode – ASCII homograph domain names allows users to deal with domains in their domains. We propose a low-cost method for proactively regional languages. This is done by introducing Internation- detecting suspicious IDNs. Since our proactive approach alized Domain Names (IDN). However, the visual similarity is based not on use, but on characteristics of the domain between different Unicode characters - called homoglyphs name itself and its associated DNS records, we are able to - is a potential security threat, as visually similar domain provide an early alert for both domain owners as well as names are often used in phishing attacks. Timely detection security researchers to further investigate these domains of suspicious homograph domain names is an important before they are involved in malicious activities. The main step towards preventing sophisticated attacks, since this can contributions of this paper are that we: prevent unaware users to access those homograph domains • propose an improved Unicode Confusion table able that actually carry malicious content. We therefore propose to detect 2.97 times homograph domains compared a structured approach to identify suspicious homograph to the state-of-the-art confusion tables; domain names based not on use, but on characteristics • combine active DNS measurements and Unicode of the domain name itself and its associated DNS records. -

Phonemes Visit the Dyslexia Reading Well
For More Information on Phonemes Visit the Dyslexia Reading Well. www.dyslexia-reading-well.com The 44 Sounds (Phonemes) of English A phoneme is a speech sound. It’s the smallest unit of sound that distinguishes one word from another. Since sounds cannot be written, we use letters to represent or stand for the sounds. A grapheme is the written representation (a letter or cluster of letters) of one sound. It is generally agreed that there are approximately 44 sounds in English, with some variation dependent on accent and articulation. The 44 English phonemes are represented by the 26 letters of the alphabet individually and in combination. Phonics instruction involves teaching the relationship between sounds and the letters used to represent them. There are hundreds of spelling alternatives that can be used to represent the 44 English phonemes. Only the most common sound / letter relationships need to be taught explicitly. The 44 English sounds can be divided into two major categories – consonants and vowels. A consonant sound is one in which the air flow is cut off, either partially or completely, when the sound is produced. In contrast, a vowel sound is one in which the air flow is unobstructed when the sound is made. The vowel sounds are the music, or movement, of our language. The 44 phonemes represented below are in line with the International Phonetic Alphabet. Consonants Sound Common Spelling alternatives spelling /b/ b bb ball ribbon /d/ d dd ed dog add filled /f/ f ff ph gh lf ft fan cliff phone laugh calf often /g/ g gg gh gu -

Mctsbug: Generating Adversarial Text
Under review as a conference paper at ICLR 2019 MCTSBUG:GENERATING ADVERSARIAL TEXT SE- QUENCES VIA MONTE CARLO TREE SEARCH AND HO- MOGLYPH ATTACK Anonymous authors Paper under double-blind review ABSTRACT Crafting adversarial examples on discrete inputs like text sequences is fundamen- tally different from generating such examples for continuous inputs like images. This paper tries to answer the question: under a black-box setting, can we create adversarial examples automatically to effectively fool deep learning classifiers on texts by making imperceptible changes? Our answer is a firm yes. Previous ef- forts mostly replied on using gradient evidence, and they are less effective either due to finding the nearest neighbor word (wrt meaning) automatically is difficult or relying heavily on hand-crafted linguistic rules. We, instead, use Monte Carlo tree search (MCTS) for finding the most important few words to perturb and per- form homoglyph attack by replacing one character in each selected word with a symbol of identical shape. Our novel algorithm, we call MCTSBug, is black-box and extremely effective at the same time. Our experimental results indicate that MCTSBug can fool deep learning classifiers at the success rates of 95% on seven large-scale benchmark datasets, by perturbing only a few characters. Surprisingly, MCTSBug, without relying on gradient information at all, is more effective than the gradient-based white-box baseline. Thanks to the nature of homoglyph attack, the generated adversarial perturbations are almost imperceptible to human eyes. 1 INTRODUCTION Recent studies have shown that adding small modifications to continuous inputs can fool state-of- the-art deep classifiers, resulting in incorrect classifications (Szegedy et al., 2014; Goodfellow et al., 2014). -

Information, Characters, Unicode
Information, Characters, Unicode Unicode © 24 August 2021 1 / 107 Hidden Moral Small mistakes can be catastrophic! Style Care about every character of your program. Tip: printf Care about every character in the program’s output. (Be reasonably tolerant and defensive about the input. “Fail early” and clearly.) Unicode © 24 August 2021 2 / 107 Imperative Thou shalt care about every Ěaracter in your program. Unicode © 24 August 2021 3 / 107 Imperative Thou shalt know every Ěaracter in the input. Thou shalt care about every Ěaracter in your output. Unicode © 24 August 2021 4 / 107 Information – Characters In modern computing, natural-language text is very important information. (“number-crunching” is less important.) Characters of text are represented in several different ways and a known character encoding is necessary to exchange text information. For many years an important encoding standard for characters has been US ASCII–a 7-bit encoding. Since 7 does not divide 32, the ubiquitous word size of computers, 8-bit encodings are more common. Very common is ISO 8859-1 aka “Latin-1,” and other 8-bit encodings of characters sets for languages other than English. Currently, a very large multi-lingual character repertoire known as Unicode is gaining importance. Unicode © 24 August 2021 5 / 107 US ASCII (7-bit), or bottom half of Latin1 NUL SOH STX ETX EOT ENQ ACK BEL BS HT LF VT FF CR SS SI DLE DC1 DC2 DC3 DC4 NAK SYN ETP CAN EM SUB ESC FS GS RS US !"#$%&’()*+,-./ 0123456789:;<=>? @ABCDEFGHIJKLMNO PQRSTUVWXYZ[\]^_ `abcdefghijklmno pqrstuvwxyz{|}~ DEL Unicode Character Sets © 24 August 2021 6 / 107 Control Characters Notice that the first twos rows are filled with so-called control characters. -

Homoglyph a Avancé Des Attaques Par Phishing
Homoglyph a avancé des attaques par phishing Contenu Introduction Homoglyph a avancé des attaques par phishing Cisco relatif prennent en charge des discussions de la Communauté Introduction Ce document décrit l'utilisation des caractères de homoglyph dans des attaques par phishing avancées et comment se rendre compte de ces derniers en utilisant le message et le contenu filtre sur l'appliance de sécurité du courrier électronique de Cisco (ESA). Homoglyph a avancé des attaques par phishing Dans des attaques par phishing avancées aujourd'hui, les emails de phishing peuvent contenir des caractères de homogyph. Un homoglyph est un caractère des textes avec les formes qui sont près d'identique ou de semblable entre eux. Il peut y avoir d'URLs encastré dans les emails phising qui ne seront pas bloqués par des filtres de message ou de contenu configurés sur l'ESA. Un exemple de scénario peut être comme suit : Le client veut bloquer un email qui a eu contient l'URL de www.pɑypal.com. Afin de faire ainsi, on écrit un filtre satisfait d'arrivée qui recherchant l'URL contenant www.paypal.com. L'action de ce filtre satisfait serait configurée pour chuter et annoncer. Le client a reçu l'exemple de contenir d'email : www.pɑypal.com Le filtre satisfait en tant que configuré contient : www.paypal.com Si vous prenez à un regarder l'URL d'effectif par l'intermédiaire des DN vous noterez qu'ils les résolvent différemment : $ dig www.pypal.com ; <<>> DiG 9.8.3-P1 <<>> www.pypal.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 37851 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 1, ADDITIONAL: 0 ;; QUESTION SECTION: ;www.p\201\145ypal.com. -
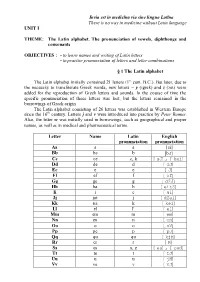
Invia Est in Medicīna Via Sine Linguа Latīna There Is No Way in Medicine Without Latin Language UNIT I
Invia est in medicīna via sine linguа Latīna There is no way in medicine without Latin language UNIT I THEME: The Latin alphabet. The pronunciation of vowels, diphthongs and consonants OBJECTIVES : - to learn names and writing of Latin letters - to practise pronunciation of letters and letter combinations § 1 The Latin alphabet The Latin alphabet initially contained 21 letters (1st cent. B.C.). But later, due to the necessity to transliterate Greek words, new letters – y (igrek) and z (zet) were added for the reproduction of Greek letters and sounds. In the course of time the specific pronunciation of these letters was lost, but the letters remained in the borrowings of Greek origin. The Latin alphabet consisting of 26 letters was established in Western Europe since the 16th century. Letters j and v were introduced into practice by Peter Ramus. Also, the letter w was initially used in borrowings, such as geographical and proper names, as well as in medical and pharmaceutical terms. Letter Name Latin English pronunciation pronunciation Aa a a [ei] Bb be b [bJ] Cc ce c, k [sJ], [kei] Dd de d [dJ] Ee е е [J] Ff ef f [ef] Gg ge g [dZJ] Hh ha h [eitS] Ii і e [ai] Jj jоt j [dZei] Kk ка k [kei] Ll el l’ [el] Mm em m [em] Nn еn n [en] Oo о о [oV] Pp pe p [pJ] Qq qu qu [kjH] Rr er r [R] Ss еs s, z [es], [zed] Tt tе t [tJ] Uu u u [jH] Vv vе v [vJ] Ww w v ['dAbl'jH] Xx ex ks, kz [eks] Yy igrek e [wai] Zz zet z, c [zed] § 2 The pronunciation of vowels There are six vowels in Latin: а, е, і, о, u, у. -

The 44 Sounds (Phonemes) of English
The 44 Sounds (Phonemes) of English A phoneme is a speech sound. It’s the smallest unit of sound that distinguishes one word from another. Since sounds cannot be written, we use letters to represent or stand for the sounds. A grapheme is the written representation (a letter or cluster of letters) of one sound. It is generally agreed that there are approximately 44 sounds in English, with some variation dependent on accent and articulation. The 44 English phonemes are represented by the 26 letters of the alphabet individually and in combination. Phonics instruction involves teaching the relationship between sounds and the letters used to represent them. There are hundreds of spelling alternatives that can be used to represent the 44 English phonemes. Only the most common sound / letter relationships need to be taught explicitly. The 44 English sounds can be divided into two major categories – consonants and vowels. A consonant sound is one in which the air flow is cut off, either partially or completely, when the sound is produced. In contrast, a vowel sound is one in which the air flow is unobstructed when the sound is made. The vowel sounds are the music, or movement, of our language. The 44 phonemes represented below are in line with the International Phonetic Alphabet. Consonants Sound Common Spelling alternatives spelling /b/ b bb ball ribbon /d/ d dd ed dog add filled /f/ f ff ph gh lf ft fan cliff phone laugh calf often /g/ g gg gh gu gue grapes egg ghost guest catalogue /h/ h wh hat who /j/ j ge g dge di gg jellyfish cage giraffe -

The Latin Alphabet Page 1 of 58 the Latin Alphabet
The Latin Alphabet Page 1 of 58 The Latin Alphabet The Latin alphabet of 23 letters was derived in the 600's BC from the Etruscan alphabet of 26 letters, which was in turn derived from the archaic Greek alphabet, which came from the Phoenician. The letters J, U, and W of the modern alphabet were added in medieval times, and did not appear in the classical alphabet, except that J and U could be alternative forms for I and V. A comparison of the Greek and Latin alphabets shows the close relation between the two. Green letters are those introduced later, after the alphabets had been adopted, and red letters are those that were eliminated from the archaic alphabet. The digamma, which represented a 'w' sound in Greek was adopted for the different Latin sound 'f' that did not occur in Greek. The gamma was written C in Etruscan, and represented both the hard 'g' and 'k' sounds in Latin, which was confusing. Latin also used the K for the 'k' sound at that time, but the C spelling became popular. Z was a sound not used in Latin, so it was thrown out of the alphabet and replaced by a modified C, a C with a tail, for the 'g' sound. Eventually, K became vestigial in Latin, used only for a few words like Kalendae and Kaeso (a name). Gaius was also spelled Caius, and its abbreviation was always C. Koppa became the model for Q, which in Latin was always used in the combination QV, pronounced 'kw,' a sound that does not occur in Greek. -

Package 'Unicode'
Package ‘Unicode’ September 21, 2021 Version 14.0.0-1 Encoding UTF-8 Title Unicode Data and Utilities Description Data from Unicode 14.0.0 and related utilities. Depends R (>= 3.5.0) Imports utils License GPL-2 NeedsCompilation no Author Kurt Hornik [aut, cre] (<https://orcid.org/0000-0003-4198-9911>) Maintainer Kurt Hornik <[email protected]> Repository CRAN Date/Publication 2021-09-21 07:11:33 UTC R topics documented: casefuns . .2 n_of_u_chars . .3 tokenizers . .4 u_blocks . .4 u_char_basics . .5 u_char_inspect . .6 u_char_match . .7 u_char_names . .8 u_char_properties . .9 u_named_sequences . 10 u_scripts . 10 Index 12 1 2 casefuns casefuns Unicode Case Conversions Description Default Unicode algorithms for case conversion. Usage u_to_lower_case(x) u_to_upper_case(x) u_to_title_case(x) u_case_fold(x) Arguments x R objects (see Details). Details These functions are generic functions, with methods for the Unicode character classes (u_char, u_char_range, and u_char_seq) which suitably apply the case mappings to the Unicode characters given by x, and a default method which treats x as a vector of “Unicode strings”, and returns a vector of UTF-8 encoded character strings with the results of the case conversion of the elements of x. Currently, only the unconditional case maps are available for conversion to lower, upper or title case: other variants may be added eventually. Currently, conversion to title case is only available for u_char objects. Other methods will be added eventually (once the Unicode text segmentation algorithm is implemented for detecting word boundaries). Currently, u_case_fold only performs full case folding using the Unicode case mappings with status “C” and “F”: other variants will be added eventually. -

The Spectral Dynamics of Voiceless Sibilant Fricatives in English and Japanese
The spectral dynamics of voiceless sibilant fricatives in English and Japanese Dissertation Presented in Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in the Graduate School of The Ohio State University By Patrick F. Reidy ∼6 6 Graduate Program in Linguistics The Ohio State University 2015 Dissertation Committee: Professor Mary E. Beckman, Advisor Professor Micha Elsner Professor Eric Fosler-Lussier Professor Eric Healy c Patrick F. Reidy, 2015 Abstract Voiceless sibilant fricatives, such as the consonant sounds at the beginning of the English words sea and she, are articulated by forming a narrow constriction between the tongue and the palate, which directs a turbulent jet of air toward the incisors downstream. Thus, the production of these sounds involves the movement of a number of articulators, including the tongue, jaw, and lips; however, the principal method for analyzing the acoustics of sibilant fricatives has been to extract a single \steady state" interval from near its temporal midpoint, and estimate spectral properties of this interval. Consequently, temporal variation in the spectral properties of sibilant fricatives has not been systematically studied. This dissertation investigated the temporal variation of a single spectral property, re- ferred to as peak ERBN -number, that denotes the most prominent psychoacoustic frequency. The dynamic aspects of peak ERBN -number trajectories were analyzed with fifth-order polynomial time growth curve models. A series of analyses revealed a number of novel findings. First, a comparison of English- and Japanese-speaking adults indicated that the language- internal contrast between English /s/ and /S/ and between Japanese /s/ and /C/ is indi- cated by dynamic properties of peak ERBN -number across the time course of the sibilants.