Data Modeling Chapter 7
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Using BEAM Software to Simulate the Introduction of On-Demand, Automated, and Electric Shuttles for Last Mile Connectivity in Santa Clara County
San Jose State University SJSU ScholarWorks Mineta Transportation Institute Publications 1-2021 Using BEAM Software to Simulate the Introduction of On-Demand, Automated, and Electric Shuttles for Last Mile Connectivity in Santa Clara County Gary Hsueh Mineta Transportation Institute David Czerwinski San Jose State University Cristian Poliziani Mineta Transportation Institute Terris Becker San Jose State University Alexandre Hughes San Jose State University See next page for additional authors Follow this and additional works at: https://scholarworks.sjsu.edu/mti_publications Part of the Sustainability Commons, and the Transportation Commons Recommended Citation Gary Hsueh, David Czerwinski, Cristian Poliziani, Terris Becker, Alexandre Hughes, Peter Chen, and Melissa Benn. "Using BEAM Software to Simulate the Introduction of On-Demand, Automated, and Electric Shuttles for Last Mile Connectivity in Santa Clara County" Mineta Transportation Institute Publications (2021). https://doi.org/10.31979/mti.2021.1822 This Report is brought to you for free and open access by SJSU ScholarWorks. It has been accepted for inclusion in Mineta Transportation Institute Publications by an authorized administrator of SJSU ScholarWorks. For more information, please contact [email protected]. Authors Gary Hsueh, David Czerwinski, Cristian Poliziani, Terris Becker, Alexandre Hughes, Peter Chen, and Melissa Benn This report is available at SJSU ScholarWorks: https://scholarworks.sjsu.edu/mti_publications/343 Project 1822 January 2021 Using BEAM Software to -

MAKING DATA MODELS READABLE David C
MAKING DATA MODELS READABLE David C. Hay Essential Strategies, Inc. “Confusion and clutter are failures of [drawing] design, not attributes of information. And so the point is to find design strategies that reveal detail and complexity ¾ rather than to fault the data for an excess of complication. Or, worse, to fault viewers for a lack of understanding.” ¾ Edward R. Tufte1 Entity/relationship models (or simply “data models”) are powerful tools for analyzing and representing the structure of an organization. Properly used, they can reveal subtle relationships between elements of a business. They can also form the basis for robust and reliable data base design. Data models have gotten a bad reputation in recent years, however, as many people have found them to be more trouble to produce and less beneficial than promised. Discouraged, people have gone on to other approaches to developing systems ¾ often abandoning modeling altogether, in favor of simply starting with system design. Requirements analysis remains important, however, if systems are ultimately to do something useful for the company. And modeling ¾ especially data modeling ¾ is an essential component of requirements analysis. It is important, therefore, to try to understand why data models have been getting such a “bad rap”. Your author believes, along with Tufte, that the fault lies in the way most people design the models, not in the underlying complexity of what is being represented. An entity/relationship model has two primary objectives: First it represents the analyst’s public understanding of an enterprise, so that the ultimate consumer of a prospective computer system can be sure that the analyst got it right. -

Value Mapping – Critical Business Architecture Viewpoint
Download this and other resources @ http://www.aprocessgroup.com/myapg Value Mapping – Critical Business Architecture Viewpoint AEA Webinar Series “Enterprise Business Intelligence” Armstrong Process Group, Inc. www.aprocessgroup.com Copyright © 1998-2017, Armstrong Process Group, Inc., All rights reserved 2 About APG APG’s mission is to “Align information technology and systems engineering capabilities with business strategy using proven, practical processes delivering world-class results.” Industry thought leader in enterprise architecture, business modeling, process improvement, systems and software engineering, requirements management, and agile methods Member and contributor to UML ®, SysML ®, SPEM, UPDM ™ at the Object Management Group ® (OMG ®) TOGAF ®, ArchiMate ®, and IT4IT ™ at The Open Group BIZBOK ® Guide and UML Profile at the Business Architecture Guild Business partners with Sparx, HPE, and IBM Guild Accredited Training Partner ™ (GATP ™) and IIBA ® Endorsed Education Provider (EEP ™) AEA Webinar Series – “Enterprise Business Intelligence” – Value Mapping Copyright © 1998-2017, Armstrong Process Group, Inc., All rights reserved 3 Business Architecture Framework Business Architecture Knowledgebase Blueprints provide views into knowledgebase, based on stakeholder concerns Scenarios contextualize expected outcomes of business architecture work Also inform initial selections of key stakeholders and likely concerns AEA Webinar Series – “Enterprise Business Intelligence” – Value Mapping BIZBOK Guide Copyright © 1998-2017, -

CROSS SECTIONAL STUDY of AGILE SOFTWARE DEVELOPMENT METHODS and PROJECT PERFORMANCE Tracy Lambert Nova Southeastern University, [email protected]
Nova Southeastern University NSUWorks H. Wayne Huizenga College of Business and HCBE Theses and Dissertations Entrepreneurship 2011 CROSS SECTIONAL STUDY OF AGILE SOFTWARE DEVELOPMENT METHODS AND PROJECT PERFORMANCE Tracy Lambert Nova Southeastern University, [email protected] This document is a product of extensive research conducted at the Nova Southeastern University H. Wayne Huizenga College of Business and Entrepreneurship. For more information on research and degree programs at the NSU H. Wayne Huizenga College of Business and Entrepreneurship, please click here. Follow this and additional works at: https://nsuworks.nova.edu/hsbe_etd Part of the Business Commons Share Feedback About This Item NSUWorks Citation Tracy Lambert. 2011. CROSS SECTIONAL STUDY OF AGILE SOFTWARE DEVELOPMENT METHODS AND PROJECT PERFORMANCE. Doctoral dissertation. Nova Southeastern University. Retrieved from NSUWorks, H. Wayne Huizenga School of Business and Entrepreneurship. (56) https://nsuworks.nova.edu/hsbe_etd/56. This Dissertation is brought to you by the H. Wayne Huizenga College of Business and Entrepreneurship at NSUWorks. It has been accepted for inclusion in HCBE Theses and Dissertations by an authorized administrator of NSUWorks. For more information, please contact [email protected]. CROSS SECTIONAL STUDY OF AGILE SOFTWARE DEVELOPMENT METHODS AND PROJECT PERFORMANCE By Tracy Lambert A DISSERTATION Submitted to H. Wayne Huizenga School of Business and Entrepreneurship Nova Southeastern University in partial fulfillment of the requirements For the degree of DOCTOR OF BUSINESS ADMINISTRATION 2011 ABSTRACT CROSS SECTIONAL STUDY OF AGILE SOFTWARE DEVELOPMENT METHODS AND PROJECT PERFORMANCE by Tracy Lambert Agile software development methods, characterized by delivering customer value via incremental and iterative time-boxed development processes, have moved into the mainstream of the Information Technology (IT) industry. -

A3: Assisting Android API Migrations Using Code Examples
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2018 1 A3: Assisting Android API Migrations Using Code Examples Maxime Lamothe, Member, IEEE, Weiyi Shang, Member, IEEE, Tse-Hsun (Peter) Chen Abstract—The fast-paced evolution of Android APIs has posed a challenging task for Android app developers. To leverage Androids frequently released APIs, developers must often spend considerable effort on API migrations. Prior research and Android official documentation typically provide enough information to guide developers in identifying the API calls that must be migrated and the corresponding API calls in an updated version of Android (what to migrate). However, API migration remains a challenging task since developers lack the knowledge of how to migrate the API calls. There exist code examples, such as Google Samples, that illustrate the usage of APIs. We posit that by analyzing the changes of API usage in code examples, we can learn API migration patterns to assist developers with API Migrations. In this paper, we propose an approach that learns API migration patterns from code examples, applies these patterns to the source code of Android apps for API migration, and presents the results to users as potential migration solutions. To evaluate our approach, we migrate API calls in open source Android apps by learning API migration patterns from code examples. We find that our approach can successfully learn API migration patterns and provide API migration assistance in 71 out of 80 cases. Our approach can either migrate API calls with little to no extra modifications needed or provide guidance to assist with the migrations. -

Chapter 1: Introduction
Just Enough Structured Analysis Chapter 1: Introduction “The beginnings and endings of all human undertakings are untidy, the building of a house, the writing of a novel, the demolition of a bridge, and, eminently, the finish of a voyage.” — John Galsworthy Over the River, 1933 www.yourdon.com ©2006 Ed Yourdon - rev. 051406 In this chapter, you will learn: 1. Why systems analysis is interesting; 2. Why systems analysis is more difficult than programming; and 3. Why it is important to be familiar with systems analysis. Chances are that you groaned when you first picked up this book, seeing how heavy and thick it was. The prospect of reading such a long, technical book is enough to make anyone gloomy; fortunately, just as long journeys take place one day at a time, and ultimately one step at a time, so long books get read one chapter at a time, and ultimately one sentence at a time. 1.1 Why is systems analysis interesting? Long books are often dull; fortunately, the subject matter of this book — systems analysis — is interesting. In fact, systems analysis is more interesting than anything I know, with the possible exception of sex and some rare vintages of Australian wine. Without a doubt, it is more interesting than computer programming (not that programming is dull) because it involves studying the interactions of people, and disparate groups of people, and computers and organizations. As Tom DeMarco said in his delightful book, Structured Analysis and Systems Specification (DeMarco, 1978), [systems] analysis is frustrating, full of complex interpersonal relationships, indefinite, and difficult. -

Edward Yourdon
EDWARD YOURDON EDWARD YOURDON is an internationally-recognized computer consultant, as well as the author of more than two dozen books, including Byte Wars, Managing High-Intensity Internet Projects, Death March, Rise and Resurrection of the American Programmer, and Decline and Fall of the American Programmer. His latest book, Outsource: competing in the global productivity race, discusses both current and future trends in offshore outsourcing, and provides practical strategies for individuals, small businesses, and the nation to cope with this unstoppable tidal wave. According to the December 1999 issue of Crosstalk: The Journal of Defense Software Engineering, Ed Yourdon is one of the ten most influential men and women in the software field. In June 1997, he was inducted into the Computer Hall of Fame, along with such notables as Charles Babbage, Seymour Cray, James Martin, Grace Hopper, Gerald Weinberg, and Bill Gates. Ed is widely known as the lead developer of the structured analysis/design methods of the 1970s, as well as a co-developer of the Yourdon/Whitehead method of object-oriented analysis/design and the Coad/Yourdon OO methodology in the late 1980s and 1990s. He was awarded a Certificate of Merit by the Second International Workshop on Computer-Aided Software Engineering in 1988, for his contributions to the promotion of Structured Methods for the improvement of Information Systems Development, leading to the CASE field. He was selected as an Honored Member of Who’s Who in the Computer Industry in 1989. And he was given the Productivity Award in 1992 by Computer Language magazine, for his book Decline and Fall of the American Programmer. -

A Brief History of Devops by Alek Sharma Introduction: History in Progress
A Brief History of DevOps by Alek Sharma Introduction: History in Progress Software engineers spend most of their waking hours wading George Santayana wrote that “those who cannot remember the through the mud of their predecessors. Only a few are lucky past are condemned to repeat it.” He was definitely not thinking enough to see green fields before conflict transforms the about software when he wrote this, but he’s dead now, which terrain; the rest are shipped to the front (end). There, they means he can be quoted out of context. Oh, the joys of public languish in trenches as shells of outages explode around them. domain! Progress is usually glacial, though ground can be covered This ebook will be about the history of software development through heroic sprints. methodologies — especially where they intersect with traditional best practices. Think of it as The Silmarillion of Silicon Valley, But veterans do emerge, scarred and battle-hardened. They except shorter and with more pictures. Before plunging into this revel in relating their most daring exploits and bug fixes to new rushing river of time, please note that the presented chronology recruits. And just as individuals have learned individual lessons is both theoretically complete and practically in progress. In other about writing code, our industry has learned collective lessons words, even though a term or process might have been coined, it about software development at scale. It’s not always easy to always takes more time for Best Practices to trickle down to Real see these larger trends when you’re on the ground — buried in Products. -
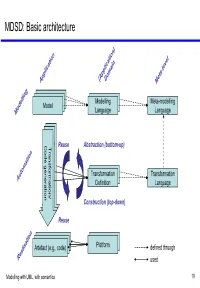
MDSD: Basic Architecture
MDSD: Basic architecture Model Modelling Meta-modelling ModelModel Model Language Language Codegeneration Transformation/ Codegeneration Transformation/ Code generation Transformation/ Reuse Abstraction (bottom-up) TransformationModel Transformation Definition Language Construction (top-down) Reuse Model Model Artefact Model(e.g., code) Platform defined through used Modelling with UML, with semantics 19 MDSD: A bird’s view Implementation Model Transformer J2EE Implementation .Net Transformation Knowledge Implementation . Modelling with UML, with semantics 20 How is MDSD realised? • Developer develops model(s), Model ModelModel Meta-model expressed using a DSL, based on certain meta-model(s). Transformation Using code generation templates, the Transformer • Rules model is transformed into executable code. • Alternative: Interpretation Model Meta-model optional, can be repeated • Optionally, the generated code is merged with manually written code. Code Transformer Generation Templates • One or more model-to-model transformation steps may precede code generation. Manually Generated Code Written Code optional Modelling with UML, with semantics 21 (Meta-)Model hierarchy conformsTo Meta-meta-model meta Meta-meta-model MOF element M3 meta conformsTo Meta-model element Relational UML … meta-model meta-model M2 Meta-model meta conformsTo repOf Model element System … … M1 Model Modelling with UML, with semantics 22 (Meta-)Model hierarchy: Example conformsTo MOF Meta-meta-model source Association destination Class conformsTo Relational Meta-model -

A Dictionary of DBMS Terms
A Dictionary of DBMS Terms Access Plan Access plans are generated by the optimization component to implement queries submitted by users. ACID Properties ACID properties are transaction properties supported by DBMSs. ACID is an acronym for atomic, consistent, isolated, and durable. Address A location in memory where data are stored and can be retrieved. Aggregation Aggregation is the process of compiling information on an object, thereby abstracting a higher-level object. Aggregate Function A function that produces a single result based on the contents of an entire set of table rows. Alias Alias refers to the process of renaming a record. It is alternative name used for an attribute. 700 A Dictionary of DBMS Terms Anomaly The inconsistency that may result when a user attempts to update a table that contains redundant data. ANSI American National Standards Institute, one of the groups responsible for SQL standards. Application Program Interface (API) A set of functions in a particular programming language is used by a client that interfaces to a software system. ARIES ARIES is a recovery algorithm used by the recovery manager which is invoked after a crash. Armstrong’s Axioms Set of inference rules based on set of axioms that permit the algebraic mani- pulation of dependencies. Armstrong’s axioms enable the discovery of minimal cover of a set of functional dependencies. Associative Entity Type A weak entity type that depends on two or more entity types for its primary key. Attribute The differing data items within a relation. An attribute is a named column of a relation. Authorization The operation that verifies the permissions and access rights granted to a user. -

Continuing Madness: Methods Behind System Architecting Challenged
Continuing Madness: Methods Behind System Architecting Challenged Robert (Bob) Scheurer Associate Technical Fellow | Systems Engineering Defense, Space and Security Robert P. Scheurer 10/18/2019, Continuing Madness – Copyright © 2019 Boeing. All rights reserved. Methods Behind System Architecting Challenged 1 Topics 1. System Architectures/Models: An Evolution 2. Modeling Frameworks and Methods: Today’s Reality 3. Toward Better Architectures, More Useful Methods, and Best Outcomes: The Challenges 4. Summary and Conclusions Robert P. Scheurer 10/18/2019, Continuing Madness – Copyright © 2019 Boeing. All rights reserved. Methods Behind System Architecting Challenged 2 Architecting/Modeling: Recipe for Success . 1993 Paper: “Method Behind the Madness in System Modeling” . Premises for Successful Modeling: Disciplined Methodology Automation via Computer-Based Tools Proper Training in Method and Tool . Conclusion: Modeling Method is Needed in Order to Avoid Right Solution to the Wrong Problem Wrong Solution to the Right Problem No Solution to any Practical Problem Robert P. Scheurer 10/18/2019, Continuing Madness – Copyright © 2019 Boeing. All rights reserved. Methods Behind System Architecting Challenged 3 Architecting/Modeling: Then to Now Lessons Learned from Modern History: Genesis of Formal SE: 1943 Army Field Manual Modeling Language 1960’s: Process Relationships Frameworks Evolution (Late 1960’s – Structured Analysis & Design Technique DoD-5000 Defense Acquisition Life Cycle Evolution Today 1943: Basic Structure 2019: Tailored Processes Robert P. Scheurer 10/18/2019, Continuing Madness – Copyright © 2019 Boeing. All rights reserved. Methods Behind System Architecting Challenged 44 Today’s Condition with Architectures 1 . Higher Fidelity and Functional Diversity: Experience in Multiple Technical Fields Necessary . Extended Objectives: Digital Twin, Economy, Enduring Relevance . Constraining Objectives: Modular Open Systems Approach; Cybersecurity; Affordability; Hardware / Software Re-Use . -

Ontology for Information Systems (O4IS) Design Methodology Conceptualizing, Designing and Representing Domain Ontologies
Ontology for Information Systems (O4IS) Design Methodology Conceptualizing, Designing and Representing Domain Ontologies Vandana Kabilan October 2007. A Dissertation submitted to The Royal Institute of Technology in partial fullfillment of the requirements for the degree of Doctor of Technology . The Royal Institute of Technology School of Information and Communication Technology Department of Computer and Systems Sciences IV DSV Report Series No. 07–013 ISBN 978–91–7178–752–1 ISSN 1101–8526 ISRN SU–KTH/DSV/R– –07/13– –SE V All knowledge that the world has ever received comes from the mind; the infinite library of the universe is in our own mind. – Swami Vivekananda. (1863 – 1902) Indian spiritual philosopher. The whole of science is nothing more than a refinement of everyday thinking. – Albert Einstein (1879 – 1955) German-Swiss-U.S. scientist. Science is a mechanism, a way of trying to improve your knowledge of na- ture. It’s a system for testing your thoughts against the universe, and seeing whether they match. – Isaac Asimov. (1920 – 1992) Russian-U.S. science-fiction author. VII Dedicated to the three KAs of my life: Kabilan, Rithika and Kavin. IX Abstract. Globalization has opened new frontiers for business enterprises and human com- munication. There is an information explosion that necessitates huge amounts of informa- tion to be speedily processed and acted upon. Information Systems aim to facilitate human decision-making by retrieving context-sensitive information, making implicit knowledge ex- plicit and to reuse the knowledge that has already been discovered. A possible answer to meet these goals is the use of Ontology.