A Connectionist Model of Spatial Learning in the Rat
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A. HM, B. Spa@Al Naviga@On 2. Hippocampus
Outline 1. What does Hippocampus do? A. HM, B. Spaal navigaon 2. Hippocampus anatomy and connec;vity CA1, CA3 diagram etc. Connec;vity to other regions. 3. Place fields in Hippocampus – show examples + the O'Keefe effect 4. Plas;city of place fields + NMDA blocker + Morris water maze 5. Replay of sequences 6. Entorhinal grid cells What does the Hippocampus do? 1. Memory 2. Spaal representaon Henry Gustav Molaison (February 26, 1926 – December 2, 2008), beger known as HM “AYer operaon this young man could no longer recognize the hospital staff nor find his way to the bathroom, and he seemed to recall nothing of the day-to-day events of his hospital life. There was also a par;al retrograde amnesia, inasmuch as he did not remember the death of a favorite uncle three years previously, nor anything of the period in the hospital, yet could recall some trivial events that had occurred just before his admission to the hospital. His early memories were apparently vivid and intact. This paent’s memory defect has persisted without improvement to the present ;me, and numerous illustraons of its severity could be given. Ten months ago the family moved from their old house to a new one a few blocks away on the same street; he s;ll has not learned the new address, though remembering the old one perfectly, nor can he be trusted to find his way home alone.” “Moreover, he does not know where objects in con;nual use are kept; for example, his mother s;ll has to tell him where to find the lawn mower, even though he may have been using it only the day before. -

Retrohippocampal Cortical Neurons During Hippocampal Sharp Waves in the Behaving Rat
The Journal of Neuroscience, October 1994, 74(10): 6160-6170 Selective Activation of Deep Layer (V-VI) Retrohippocampal Cortical Neurons during Hippocampal Sharp Waves in the Behaving Rat J. J. Chrobak and G. Buzsaki Center for Molecular and Behavioral Neuroscience, Rutgers, The State University of New Jersey, Newark, New Jersey 07102 The coordinated activity of hippocampal neurons is reflected feet on their postsynaptic neocortical targets and may rep- by macroscopic patterns, theta and sharp waves (SPW), ev- resent a physiological mechanism for memory trace transfer ident in extracellular field recordings. The importance of these from the hippocampus to the neocortex. patterns is underscored by the ordered relation of specific [Key words: hippocampus, entorhinal cortex, theta, sharp neuronal populations to each pattern as well as the relation waves, oscillations, memory, temporal lobe epilepsy, Ab- of each pattern to distinct behavioral states. During awake heimer’s disease] immobility, consummatory behavior, and slow wave sleep, CA3 and CA1 neurons participate in organized population Retrohippocampal structures [entorhinal cortex (EC), parasub- bursts during SPW. In contrast, during theta-associated ex- iculum, presubiculum, and subiculum] process and transmit ploratory activity, the majority of principle cells are silent. information between the neocortex and the hippocampus. The Considerably less is known about the discharge properties electrophysiology of thesestructures has received scant attention of retrohippocampal neurons during theta, and particularly despite their importance as a substrate for memory (Amaral, during SPW. These retrohippocampal neurons (entorhinal 1987; Zola-Morgan et al., 1989; Squire, 1992)and asfocal point cortical, parasubicular, presubicular, and subicular) process for the pathophysiology of dementia (Hyman et al., 1984; Van and transmit information between the neocortex and the hip- Hoesenet al., 1991) and temporal lobe epilepsy (Rutecki et al., pocampus. -

Creating a Web-Based 3D Interactive Resource to Teach the Anatomy of the Human Hippocampus
Morphology of Memory: Creating a web-based 3D interactive resource to teach the anatomy of the human hippocampus by Alisa M. Brandt A thesis submitted to Johns Hopkins University in conformity with the requirements for the degree of Master of Arts Baltimore, Maryland March, 2019 © 2019 Alisa Brandt All Rights Reserved ABSTRACT The hippocampus is a critical region of the brain involved in memory and learning. It has been widely researched in animals and humans due to its role in consolidating new experiences into long-term declarative memories and its vulnerability in neurodegenerative diseases. The hippocampus is a complex, curved structure containing many interconnected regions that consist of distinct cell types. Despite the importance of understanding the normal state of hippocampal anatomy for studying its functions and the disease processes that affect it, didactic educational resources are severely limited. The literature on the hippocampus is expansive and detailed, but a communication gap exists between researchers presenting hippocampal data and those seeking to improve their understanding of this part of the brain. The hippocampus is typically viewed in a two-dimensional fashion; students and scientists have diffculty visualizing its three-dimensional anatomy and its structural relationships in space. To improve understanding of the hippocampus, an interactive, web-based educational resource was created containing a pre-rendered 3D animation and manipulable 3D models of hippocampal regions. Segmentations of magnetic resonance imaging data were modifed and sculpted to build idealized anatomical models suitable for teaching purposes. These models were animated in combination with illustrations and narration to introduce the viewer to the subject, and the completed animation was uploaded online and embedded into the interactive. -

Traumatic Early Life Stress in the Developing Hippocampus: a Meta-Analysis of MRI Studies
Walden University ScholarWorks Walden Dissertations and Doctoral Studies Walden Dissertations and Doctoral Studies Collection 2020 Traumatic Early Life Stress in the Developing Hippocampus: A Meta-Analysis of MRI Studies Sharon Johnson Walden University Follow this and additional works at: https://scholarworks.waldenu.edu/dissertations Part of the Psychology Commons This Dissertation is brought to you for free and open access by the Walden Dissertations and Doctoral Studies Collection at ScholarWorks. It has been accepted for inclusion in Walden Dissertations and Doctoral Studies by an authorized administrator of ScholarWorks. For more information, please contact [email protected]. Walden University College of Social and Behavioral Sciences This is to certify that the doctoral dissertation by Sharon Lee Johnson has been found to be complete and satisfactory in all respects, and that any and all revisions required by the review committee have been made. Review Committee Dr. Scott Wowra, Committee Chairperson, Psychology Faculty Dr. Patricia Costello, Committee Member, Psychology Faculty Dr. Kimberley Cox, University Reviewer, Psychology Faculty Chief Academic Officer and Provost Sue Subocz, Ph.D. Walden University 2020 Abstract Traumatic Early Life Stress in the Developing Hippocampus: A Meta-Analysis of MRI Studies by Sharon Lee Johnson MPhil, Walden University, 2019 M.Ed., Youngstown State University, 1994 BA, Kent State University, 1979 Dissertation Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy Health Psychology Walden University August 2020 Abstract Advancements in neuroimaging techniques afford researchers the opportunity to examine the actual brains of living persons, which exponentially contributes to new insights regarding brain and behavior phenomena. However, empirical studies investigating stress and the hippocampus attend primarily to adult populations - less on children and adolescents. -
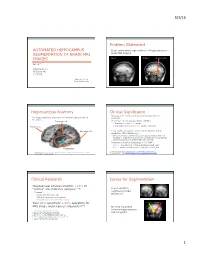
5/3/16 1 Automated Hippocampus Segmentation of Brain
5/3/16 Problem Statement AUTOMATED HIPPOCAMPUS • Goal: automated segmentation of hippocampus in SEGMENTATION OF BRAIN MRI brain MRI images Input Output hippocampus IMAGES Group 7 Yingchuan Hu Chunyan Wu Li Zhong May 1st, 2014 Cornell University Hippocampus Anatomy Clinical Significance • Epilepsy is the most common serious brain disorder The hippocampus is located in the medial temporal lobe of worldwide. the brain. 1 Temporal lobe • Prevalence of epilepsy worldwide (WHO ) • 7 sufferers in every 1,000 people • 3 new sufferers in every 10,000 people each year Frontal lobe Occipital lobe • People with epilepsy are at increased risks for status epilepticus (life-threatening) • One continuous, unremitting seizure lasting longer than five minutes or recurrent seizures without regaining consciousness between seizures for greater than five minutes. • Prevalence of status epilepticus in US (NIH2) • 195,000 new patients of status epilepticus each year • 42,000 deaths caused by status epilepticus each year 1. World Health Organization http://www.who.int/mental_health/neurology/epilepsy/en/ *Modified from a scan of a plate of “Posterior and inferior cornua of left lateral ventricle exposed 2. National institute of Health http://www.ninds.nih.gov/disorders/epilepsy/detail_epilepsy.htm from the side” in Gary’s Anatomy Clinical Research Issues for Segmentation • Hippocampal volume reduction >10% of “normal” size indicates epilepsy.[1-4] • Low contrast to neighboring brain • “normal”: structures • People with the same age • Bilateral hippocampus comparison • Personal changes in more than 1 year • Over 90% sensitivity + 98% specificity for amgydala hippocampus [5-7] MRI image measurement diagnosis. • No clear boundary between hippocampus 1. Cook MJ, et al. -

Annual Report 2018
ANNUAL REPORT 2017-2018 Table of Contents 2 Director’s Letter 3 History and Mission 4 Faculty 8 Faculty News 12 Faculty Research Programs 22 Scientific Advancements 34 Collaborations 46 Academic and Community Activities 51 Faculty Publications FY 2018 59 Teaching 62 Postdoctoral Trainees 64 Visiting Scientists 65 Graduate Students 69 Grants and Contracts 77 Events 77 Zilkha Seminar Series 80 8th Annual Zach Hall Lecture 82 Los Angeles Brain Bee 84 Soprano and Musical Ambassador Renée Fleming visits Zilkha 85 Music to Remember – LA Opera/Alzheimer’s Greater Los Angeles 86 Searching for Solutions: 5th Annual AD Symposia Held at Zilkha Institute 87 Administration and Operating Budget 88 Development 1 Director’s Letter Dear Friends, The year 2018 began with a strong start when the department of Physiology & Neuroscience was ranked number 3 in the nation according to the Blue Ridge Institute. I am proud of the work we have done to achieve this great honor and in awe of our faculty who have made this accomplishment possible, by receiving a large number of federal awards for their research. Of course, as much as we love to have well-funded research programs, it is the science that really matters, and as you will see across the following pages, we have made great strides in so many different areas, from neural circuits and genomics, to imaging and Alzheimer’s. I am proud of the work we are doing and happy to be recognized for it. In addition to awards received, we welcomed a number of visitors and speakers who came to the Zilkha Neurogenetic Institute, some to share their cutting-edge research, others to learn of the advances we have made. -

Hippocampus and Shape Analysis Claire Cury
Hippocampus and shape analysis Claire Cury To cite this version: Claire Cury. Hippocampus and shape analysis. TIG Symposium for Epilepsy, Mar 2017, London, United Kingdom. hal-02080594 HAL Id: hal-02080594 https://hal.inria.fr/hal-02080594 Submitted on 26 Mar 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Hippocampus and shape analysis TIG symposium for epilepsy Claire Cury Introduction • Position: Position of the object in its environment. • Shape: 3D edge of an object. Ridge transformation invariant. • Statistical shape analysis of anatomical structures – Modelisation of normal and pathological variability. – Prediction of clinical and biological parameters. Hippocampus Anatomy Images: Duvernoy et al, 2005 Incomplete Hippocampal Inversion (IHI) Mainly described in epileptic patients (Barsi et al. 2000; Bajic et al. 2009;…) ~ 50% In healthy population (Bernasconi et al. 2005; Bajic et al. 2008; Gamss et al. 2009) ~ 20% Criteria ill-defined Mix of healthy and controls (non epileptics) (Gamss et al. 2009) Not enough subjects (Bajic et al. 2008) IHI : Criteria • C1: roundness and verticality • C2: collateral sulci • C3: position • C4: subiculum • C5: T4 sulci • C0, IHI global appraisal: – 0 : normal aspect – 1 : Partial IHI – 2 : Total IHI Cury et al. -

Hippocampus – Why Is It Studied So Frequently? Hipokampus – Zašto Se Toliko Prouþava?
Vojnosanit Pregl 2014; 71(2): 195–201. VOJNOSANITETSKI PREGLED Strana 195 UDC: 611.813:612.825 GENERAL REVIEW DOI: 10.2298/VSP130222043R Hippocampus – Why is it studied so frequently? Hipokampus – zašto se toliko prouþava? Veselin Radonjiü*, Slobodan Malobabiü†, Vidosava Radonjiü†, Laslo Puškaš†, Lazar Stijak†, Milan Aksiü†, Branislav Filipoviü† *Institute for Biocides and Medical Ecology, Belgrade, Serbia; †Institute of Anatomy, Faculty of Medicine, University of Belgrade, Belgrade, Serbia Key words: Kljuÿne reÿi: hippocampus; anatomy; neurophysiology; memory. hipokampus; anatomija; neurofiziologija; pamýenje. Introduction the medial wall of the temporal horn of the lateral ventricle. The name hippocampus to this structure was given by the From the very beginnings of brain research, the hippo- Bolognese anatomist Giulio Cesare Aranzio-Arantius in campus has been the focus of attention for anatomists. Nowa- 1564 which crossectional appearance resembled a seahorse 1 days, its complexity and clinical importance have attracted the to him. Winslow in 1732, used the term cornu arietis (ram`s interest of a vast number of researchers of different profiles. horn) for the appearance of the hippocampal section, which Work on hippocampal tissue facilitated some important De Garengeot in 1742 turned to cornu Ammonis after the neurophysiological discoveries: identification of excitatory Egyptian god Ammon who was depicted with a human body and inhibitory synapses, transmitters and receptors, discov- and the head of a ram with the horn7. The hippocampus ery of long-term potentiation and long-term depression, role proper is the more commonly used name for Ammon’s horn. of oscillations in neuronal networks, underlying mechanisms The name cornu Ammonis survived as the acronim CA for of epileptogenesis and of memory disorders 1. -

Cerebral Blood Flow Alterations As Assessed by 3D ASL in Cognitive
ORIGINAL RESEARCH published: 31 August 2016 doi: 10.3389/fnagi.2016.00211 Cerebral Blood Flow Alterations as Assessed by 3D ASL in Cognitive Impairment in Patients with Subcortical Vascular Cognitive Impairment: A Marker for Disease Severity Yawen Sun 1†, Wenwei Cao 2†, Weina Ding 1, Yao Wang 1, Xu Han 1, Yan Zhou 1* †, Qun Xu 2* †, Yong Zhang 3 and Jianrong Xu 1 1 Department of Radiology, Ren Ji Hospital, School of Medicine, Shanghai Jiao Tong University, Shanghai, China, 2 Department of Neurology, Ren Ji Hospital, School of Medicine, Shanghai Jiao Tong University, Shanghai, China, 3 GE Applied Science Laboratory, GE Healthcare, Shanghai, China Abnormal reductions in cortical cerebral blood flow (CBF) have been identified in subcortical vascular cognitive impairment (SVCI). However, little is known about the Edited by: pattern of CBF reduction in relation with the degree of cognitive impairment. CBF Orly Lazarov, measured with three-dimensional (3D) Arterial Spin Labeling (ASL) perfusion magnetic University of Illinois at Chicago, USA resonance imaging (MRI) helps detect functional changes in subjects with SVCI. We Reviewed by: Victor Manuel Pulgar, aimed to compare CBF maps in subcortical ischemic vascular disease (SIVD) subjects Wake Forest School of Medicine, with and without cognitive impairment and to detect the relationship of the regions USA Nicolau Beckmann, of CBF reduction in the brain with the degree of cognitive impairment according to Novartis Institutes for BioMedical the z-score. A total of 53 subjects with SVCI and 23 matched SIVD subjects without Research, Switzerland cognitive impairment (controls), underwent a whole-brain 3D ASL MRI in the resting *Correspondence: Yan Zhou state. -

Hippocampal Neuronal Morphology and Spine Density in a Seasonally Reproducing Rodent, Richardson’S Ground Squirrel (Urocitellus Richardsonii)
HIPPOCAMPAL NEURONAL MORPHOLOGY AND SPINE DENSITY IN A SEASONALLY REPRODUCING RODENT, RICHARDSON’S GROUND SQUIRREL (UROCITELLUS RICHARDSONII) BENJAMIN EDWARD BRINKMAN Bachelor of Science, University of Lethbridge, 2017 A thesis submitted in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE in NEUROSCIENCE Department of Neuroscience University of Lethbridge LETHBRIDGE, ALBERTA, CANADA © Ben Brinkman, 2019 HIPPOCAMPAL NEURONAL MORPHOLOGY AND SPINE DENSITY IN A SEASONALLY REPRODUCING RODENT, RICHARDSON’S GROUND SQUIRREL (UROCITELLUS RICHARDSONII) BENJAMIN EDWARD BRINKMAN Date of Defence: December 9, 2019 Dr. A. Iwaniuk Associate Professor Ph.D. Supervisor Dr. R. Sutherland Professor Ph.D. Thesis Examination Committee Member Dr. D. Logue Associate Professor Ph.D. Thesis Examination Committee Member Dr. M. Antle Professor Ph.D. External Examiner University of Calgary Calgary, Alberta Dr. R. Gibb Professor Ph.D. Chair, Thesis Examination Committee ABSTRACT Both sex and reproductive status can alter the anatomy of brain regions within individuals. In mammals, these changes can be large in seasonally breeding species, but the extent to which fluctuations in brain region sizes are driven by neuron morphology has remained untested. I tested the hypothesis that sex-seasonal differences in hippocampus size are due, in part, to changes in neuronal morphology and spine density. Through analyzing Golgi-stained tissue from wild caught Richardson’s ground squirrels (Urocitellus richardsonii), I found that season affects spine density in hippocampal neurons. In pyramidal cells, non-breeding squirrels had higher spine densities, but in granule cells non-breeding squirrels had lower spine densities. These seasonal effects on neuronal spine density likely reflect photoperiod, seasonal changes in stress, and activity levels in similar ways to studies of lab rodents. -

Anatomy of the Hippocampus and Its Emerging Roles in Modulating Emotion-Dependent Autonomic Activities
IJAE Vol. 124, n. 3: 337-352, 2019 ITALIAN JOURNAL OF ANATOMY AND EMBRYOLOGY Review - Histology and Cell Biology Anatomy of the hippocampus and its emerging roles in modulating emotion-dependent autonomic activities Itopa E. Ajayi Department of Veterinary Anatomy, University of Abuja, Main campus, Nigeria, and School of Biomedical Sciences, The University of Queensland, St. Lucia campus, Queensland, Australia Abstract The hippocampus is popularly known to be involved in learning and memory. However, emerging evidence indicates that the hippocampus also mediates emotions in a process that involves modulating motor and autonomic outflow. The parts of the hippocampus involved in modulating autonomic activities are distinct and thus support the argument of inherent structural and functional segregation. It is suggested that the ability to modulate emotion- dependent autonomic rhythm results from descending synaptic interactions with nuclei in the hypothalamus and brainstem where the rhythm of motor and autonomic activities is gener- ated and maintained. However, there is little knowledge of the anatomical pathways and cir- cuit physiology that support the modulation of such autonomic activities. Also, in coordinat- ing physiologic responses, forebrain structures operate through functional networks, but the neural pathways and mechanisms involved in such complex interactions are not clear. Thus, the current review aims at elucidating the anatomy of the hippocampus with emphasis on the intra and inter structural circuits responsible for modulating emotion-dependent autonomic activities. Keywords Hippocampus, anatomy, emotion processing, autonomic nervous system, descending pathways. Introduction Emotional behaviours are processed, formed and expressed by a complex network of brain structures known as the limbic system, which relies upon sensory perception of the external environment. -

82223934.Pdf
CORE Metadata, citation and similar papers at core.ac.uk Provided by Elsevier - Publisher Connector Journal of the Neurological Sciences 307 (2011) 60–68 Contents lists available at ScienceDirect Journal of the Neurological Sciences journal homepage: www.elsevier.com/locate/jns Shape analysis of subcortical nuclei in Huntington's disease, global versus local atrophy — Results from the TRACK-HD study S.J.A. van den Bogaard a,⁎, E.M. Dumas a, L. Ferrarini b, J. Milles b, M.A. van Buchem c, J. van der Grond c, R.A.C. Roos a a Department of Neurology, Leiden University Medical Center, Leiden, The Netherlands b Division of Image Processing (LKEB), Department of Radiology, Leiden University Medical Center, Leiden, The Netherlands c Department of Radiology, Leiden University Medical Center, Leiden, The Netherlands article info abstract Article history: Huntington's disease (HD) is characterized by brain atrophy. Localized atrophy of a specific structure could Received 30 August 2010 potentially be a more sensitive biomarker reflecting neuropathologic changes rather than global volume Received in revised form 5 May 2011 variation. We examined 90 TRACK-HD participants of which 30 were premanifest HD, 30 were manifest HD Accepted 11 May 2011 and 30 were controls. Using FMRIB's Integrated Registration and Segmentation Tool, segmentations were Available online 31 May 2011 obtained for the pallidum, caudate nucleus, putamen, thalamus, accumbens nucleus, amygdala, and Keywords: hippocampus and overall volumes were calculated. A point distribution model of each structure was Huntington's disease obtained using Growing and Adaptive Meshes. Permutation testing between groups was performed to detect Atrophy local displacement in shape between groups.