Soohueyyap Capstone.Pdf (6.846Mb)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

W . Howard Avenue
19 MONDAY THRU FRIDAY - DE LUNES A VIERNES l Times given for each bus trip from beginning to end of route. Read down for times at specific locations. Horarios para cada viaje de autobús desde el principio hasta el fin del trayecto. Lea los horarios para localidades específicas de arriba hacia a bajo. ño a 19 p s E n itsmarta.com / 404-848-5000 E 2104 Leave: - Salida: East Lake Station Decatur Station V. A. Hospital V. Arrive: - Llegada: Chamblee Station V. A. Hospital V. Clairmont Rd. & Rd. LaVista Clairmont Rd. & Hwy. Buford Leave: - Salida: Chamblee Station Clairmont Rd. & Hwy. Buford Clairmont Rd. & Rd. LaVista Decatur Station Arrive: - Llegada: East Lake Station 2021 - 1 2 3 4 5 6 6 5 4 3 2 1 24 WHEELCHAIR ACCESSIBLE Accesible para silla de ruedas NORTHBOUND - DIRECCION NORTE SOUTHBOUND - DIRECCION SUR METROPOLITAN ATLANTA RAPID TRANSIT AUTHORITY Rail Stations Served: Clairmont Road/ Howard Avenue W. Chamblee Decatur East Lake Effective as of: 04- 5:45 5:53 6:02 6:09 6:20 6:27 5:50 5:57 6:06 6:13 6:24 6:31 6:15 6:23 6:34 6:41 6:52 6:59 6:20 6:28 6:38 6:45 6:56 7:03 6:45 6:53 7:04 7:14 7:27 7:34 6:50 6:58 7:08 7:15 7:29 7:36 7:15 7:24 7:39 7:49 8:02 8:09 7:20 7:28 7:39 7:46 8:00 8:07 7:45 7:54 8:09 8:19 8:30 8:37 + 7:50 7:59 8:10 8:17 8:31 8:38 8:15 8:24 8:39 8:49 9:00 9:07 + 8:20 8:29 8:40 8:47 9:01 9:07 8:45 8:54 9:09 9:18 9:29 9:36 + 8:50 8:59 9:10 9:15 9:29 9:35 9:15 9:24 9:36 9:45 9:56 10:03 + 9:25 9:34 9:44 9:49 10:03 10:09 9:45 9:54 10:06 10:15 10:26 10:33 + 10:05 10:14 10:24 10:29 10:43 10:49 10:25 10:34 10:46 10:55 11:06 11:13 -

BANKHEAD STATION Transit Oriented Development
BANKHEAD STATION Transit Oriented Development AREA PROFILE Area Demographics at 1/2 Mile Population 2012 1,902 % Population Change 2000-2012 -38% % Generation Y (18-34) 28% % Singles 83% Photo: Transformation Alliance 1335 Donald Lee Hollowell Parkway Housing Units 752 Daily Entries: 1,902 Atlanta, GA 30318 Housing Density/ Acre 1.5 Parking Capacity: 11 Spaces Bankhead Station is a heavy rail transit station facility locat- % Renters 74% ed near the geographic center of the City of Atlanta, several Parking % Multifamily Housing 49% Utilization:* N/A miles west of Midtown Atlanta on MARTA’s Green Line. Bankhead provides rapid rail service to major destinations Median Household Income $22,232 Station Type: Elevated including the Buckhead shopping and business district (23 % Use Public Transit 31% minutes), Midtown (11 minutes), Downtown (7 minutes) and Business Demographics Total Land Area +/- 3 acres Hartsfield-Jackson International Airport (23 minutes). Employees 234 Weekly Daily Entries MARTA’s adopted Transit Oriented Development Guidelines Avg. Office Rent Per SF $9.51 1,902 1,907 classify Bankhead as a Town Center station. This classifica- Avg. Retail Rent Per SF N/A tion system reflects both a station’s location and its primary Avg. Apartment Rent (1-mile) $520 function. The Guidelines define two types of Town Center 1,834 stations, one in “…historic town centers, such as Decatur or East Point”, the other as “…focal points for new town center- Sources: Bleakly Advisory Group, 2012. TOD nodes planned and built from the ground up in re- FY13 FY14 FY15 sponse to twenty-first century transit opportunities”. Bank- head station will likely be the latter, particularly with its proximity to the Atlanta BeltLine and the Bellwood Quarry MARTA Research & Analysis 2016 which is planned to be developed into the Westside Reser- *Data is not gathered if below 100 voir Park. -

This Re-Route Will Start at the Biginning of Revenue Service Untill B.C.C
THIS RE-ROUTE WILL START AT THE BIGINNING OF REVENUE SERVICE UNTILL B.C.C. GIVES THE ALL CLEAR. REROUTE ADVISORY: Route #2 Ponce De Leon, #3 Auburn Ave, #6 Emory, #9 Boulevard/Tilson Road, #21 Memorial Drive, #26 Marietta Street, #36 Virginia Highland, #40 Downtown, #42 Pryor Road, #49 McDonough Blvd, #50 D.L. Hollowell Pkwy, #51 J.E. Boone, #55 Jonesboro Road, #94 Northside Drive, #102 Little Five Points, #107 Glenwood, #186 Rainbow Drive, #809 Monroe Drive, #813 Atlanta Student Movement, #816 North Highland Ave, #832 Grant Park, and #899 Old Fourth Ward. WHAT: 2020 Publix Atlanta Marathon & 5k WHERE: The Marathon will start at Marietta Street and Centennial Olympic Park Drive. The Route/Course will travel through various streets in the City of Atlanta and Dekalb County. WHEN: Sunday, March 1, 2020 TIMES: 7:00 a.m. – 2:00 p.m. or Until the All clear is given by B.C.C. Buses in and around the Marathon will be rerouted during the Marathon/5k. Bus routes intersecting with Race/Runners will be delayed. Atlanta Police will allow traffic to flow between gaps in the Race. Reroute as follows: OUTBOUND: Route #2 from North Avenue Station to East Lake Station (South Loop) Regular route Expect Delays crossing North Highland Avenue. INBOUND: Route #2 from East Lake Station to North Avenue Station Regular route Expect Delays crossing North Highland Avenue. Regular route Page 1 of 20 OUTBOUND: Route #3 from H.E. Holmes Station to West End Station Continue M.L.K. Jr. Drive Right – Joseph E. Lowery Blvd. -
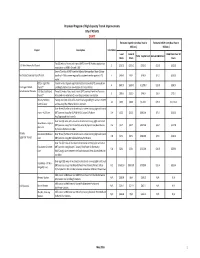
Proposed Program of High Capacity Transit Improvements City of Atlanta DRAFT
Proposed Program of High Capacity Transit Improvements City of Atlanta DRAFT Estimated Capital Cost (Base Year in Estimated O&M Cost (Base Year in Millions) Millions) Project Description Total Miles Local Federal O&M Cost Over 20 Total Capital Cost Annual O&M Cost Share Share Years Two (2) miles of heavy rail transit (HRT) from HE Holmes station to a I‐20 West Heavy Rail Transit 2 $250.0 $250.0 $500.0 $13.0 $312.0 new station at MLK Jr Dr and I‐285 Seven (7) miles of BRT from the Atlanta Metropolitan State College Northside Drive Bus Rapid Transit (south of I‐20) to a new regional bus system transfer point at I‐75 7 $40.0 N/A $40.0 $7.0 $168.0 north Clifton Light Rail Four (4) miles of grade separated light rail transit (LRT) service from 4 $600.0 $600.0 $1,200.0 $10.0 $240.0 Contingent Multi‐ Transit* Lindbergh station to a new station at Emory Rollins Jurisdicitional Projects I‐20 East Bus Rapid Three (3) miles of bus rapid transit (BRT) service from Five Points to 3 $28.0 $12.0 $40.0 $3.0 $72.0 Transit* Moreland Ave with two (2) new stops and one new station Atlanta BeltLine Twenty‐two (22) miles of bi‐directional at‐grade light rail transit (LRT) 22 $830 $830 $1,660 $44.0 $1,056.0 Central Loop service along the Atlanta BeltLine corridor Over three (3) miles of bi‐directional in‐street running light rail transit Irwin – AUC Line (LRT) service along Fair St/MLK Jr Dr/Luckie St/Auburn 3.4 $153 $153 $306.00 $7.0 $168.0 Ave/Edgewood Ave/Irwin St Over two (2) miles of in‐street bi‐directional running light rail transit Downtown – Capitol -

Piedmont Area Trans Study.Indd
piedmont area transportation study final report Several portions of the corridor, such as near the northern and southern activity centers, do have more consistent and attractive streetscape environments. However, other portions existing of the corridor have not received improvements during recent years. This creates a disconnected corridor and provides unattractive and difficult conditions for individuals wishing to walk between the areas with nicer aesthetics and well-kept conditions streetscapes. This discontinuity between areas is even more noticeable to motorists who drive along the corridor. Zoning Structure Portions of the corridor lie within Special Public Interest (SPI) districts which provide an additional layer of zoning. These areas are located on the east side of Piedmont Road north of Peachtree Road as well as on both sides of Above: Recently completed Phase I Peachtree Road Piedmont Road in the Lindbergh Center Complete Streets streetsape area. These overlay districts allow for Right: Lindbergh Center as common goals pertaining to aesthetics, a model of good streetscape attractiveness to all user groups, and unity of appearance in these locations as development occurs. Several areas that are prime for redevelopment are currently not within overlay districts (along the west side of Piedmont Road south and north of Peachtree Road), making them vulnerable to development that does not support the common goals of the corridor. “ … We have worked with the City of Atlanta very closely throughout this process so that our recom- mendations can be put directly into the plan they create for the entire city. That gives Buckhead a fast start on making vital transportation improvements.” 22 23 piedmont piedmont area area transportation transportation study final report study final report 3.0 Existing Conditions The current state of Piedmont Road is the result of decades of substantial use without requisite investment in maintenance and improvement to the transit, pedestrian, bicycle, and roadway infrastructure along the corridor. -

MARTA Tunnel Construction in Decatur, Georgia
. 4 I lit. 18.5 . a37 no UOT- f SC- UM TM UMTA-MA-06-002 5-77-1 7 7 -2 4 T NO MARTA TUNNEL CONSTRUCTION IN DECATUR GEORGIA— A Case Study of Impacts Peter C. Wolff and Peter H. Scholnick Abt Associates Inc. 55 Wheeler Street Cambridge MA 02138 of TR4 A( JULY 1977 FINAL REPORT DOCUMENT IS AVAILABLE TO THE U.S. PUBLIC THROUGH THE NATIONAL TECHNICAL INFORMATION SERVICE, SPRINGFIELD, VIRGINIA 22161 Prepared for U.S, DEPARTMENT OF TRANSPORTATION URBAN MASS TRANSPORTATION ADMINISTRATION Office of Technology Development and Deployment Office of Rail Technology Washi ngton DC 20591 . NOTICE This document is disseminated under the sponsorship of the Department of Transportation in the interest of information exchange. The United States Govern- ment assumes no liability for its contents or use thereof NOTICE The United States Government does not endorse pro- ducts or manufacturers. Trade or manufacturers' names appear herein solely because they are con- sidered essential to the object of this report. Technical Report Documentation Page 1 . Report No. 2. Government Accession No. 3. Recipient's Catalog No. UMTA-MA-06-0025- 77-14 4. Title and Subti tie 5. Report Date July 1977 iJfYlTfl- MARTA TUNNEL CONSTRUCTION IN DECATUR GEORGIA— A Case Study of Impacts 6. Performing Organization Code 8. Performing, Organi zation Report No. 7. Authors) DOT-TSC-UMTA-77-24 AAI 77-18 Peter Co Wolff and Peter H. Scholnick 9. Performing Organization Name and Address 10. Work Unit No. (TRAIS) Abt Associates Inc. UM704/R7706 55 Wheeler Street 11. Contract or Grant No. -

Peachtree Road/ Buckhead
110 MONDAY THRU FRIDAY - DE LUNES A VIERNES l Times given for each bus trip from beginning to end of route. Read down for times at specific locations. Horarios para cada viaje de autobús desde el principio hasta el fin del trayecto. Lea los horarios para localidades específicas de arriba hacia a bajo. ño a p 110 s E n itsmarta.com / 404-848-5000 E Leave: - Salida: Arts Center Station Peachtree Rd. & Peachtree Hills Ave. Peachtree Buckhead Station Arrive: - Llegada: Brookhaven/ Oglethorpe Station Leave: - Salida: Brookhaven/ Oglethorpe Station Buckhead Station Rd. & Peachtree Hills Ave. Peachtree Arrive: - Llegada: Arts Center Station 2104 2021 - 4 3 2 1 1 2 3 4 24 WHEELCHAIR ACCESSIBLE Accesible para silla de ruedas NORTHBOUND - DIRECCION NORTE SOUTHBOUND - DIRECCION SUR METROPOLITAN ATLANTA RAPID TRANSIT AUTHORITY Rail Stations Served: Peachtree Road/ Buckhead Effective as of: 04- Arts Center Buckhead Brookhaven/Oglethorpe 5:15 5:27 5:38 5:45 4:20 4:31 4:41 4:51 5:35 5:47 5:58 6:05 4:40 4:51 5:01 5:11 5:55 6:07 6:22 6:31 5:00 5:11 5:21 5:31 6:10 6:23 6:38 6:47 5:20 5:31 5:41 5:51 6:25 6:38 6:53 7:02 5:40 5:51 6:01 6:12 6:40 6:53 7:08 7:18 6:00 6:12 6:25 6:36 6:55 7:08 7:23 7:33 6:20 6:32 6:45 6:56 7:10 7:24 7:39 7:49 6:35 6:47 7:00 7:14 7:25 7:39 7:54 8:04 6:50 7:02 7:16 7:30 7:40 7:54 8:09 8:19 7:05 7:18 7:32 7:46 7:55 8:09 8:26 8:36 7:20 7:33 7:47 8:01 8:10 8:24 8:41 8:51 7:35 7:48 8:02 8:17 8:25 8:39 8:56 9:06 7:50 8:03 8:17 8:32 8:40 8:54 9:09 9:19 8:05 8:19 8:33 8:48 8:55 9:09 9:24 9:34 8:20 8:34 8:48 9:03 9:15 9:29 9:44 9:54 8:35 -

Decatur's Transportation Network, 2007
3 • Decatur’s Transportation Network, 2007 CHAPTER • 3 Decatur’s Transportation Network, 2007 othing speaks louder of a city’s transportation system than how its residents use it. A public survey conducted as part of the CTP revealed that sixty-seven N percent of commuters drive alone to get to work or school. Over 20 percent of commuters in Decatur either walk, bike or take transit. Even more interesting, 79 percent of residents reported having walked or ridden a bike to downtown Decatur. Additionally, the majority of residents feel that it is easy to get around the City. These results indicate a system that already provides a lot of choice for travelers. The following sections detail the extent of these choices, i.e. the facilities that make up the existing Decatur transportation network. The CTP uses this snapshot of how Decatur gets around in 2007 to recommend how the City can build upon its existing strengths to realize its vision of a healthy and well-connected community. Existing Street Network Streets are where it all comes together for travel in and through Decatur. The streets and their edges provide places for people to walk, bicycle and travel in buses and other vehicles. Compared with the MARTA rail system and off-road paths and greenways, the street system in Decatur accommodates the majority of travel and is detailed below. Roadway Classification in Decatur In 1974, the Federal Highway Administration (FHWA) published the manual Highway Functional Classification - Concepts, Criteria and Procedures. The manual was revised in 1989 and forms the basis of this roadway classification inventory. -

2020 Comprehensive Transportation Plan Update
2020 Comprehensive Transportation Plan Update FINAL REPORT | SEPTEMBER 2020 This document is the final report as approved and adopted by the City of Brookhaven Mayor and City Council on October 13, 2020. 2020 Comprehensive Transportation Plan Update Prepared by Prepared for The City of Brookhaven John Arthur Ernst, Jr. – Mayor Linley Jones – City Council District 1 John Park – City Council District 2 Madeleine Simmons – City Council District 3 Joe Gebbia – City Council District 4 Christian Sigman – City Manager Public Works Department Hari Karikaran – Director September 2020 2020 Comprehensive Transportation Plan Update Table of Contents TABLE OF CONTENTS ...................................................................................................................................................................................I LIST OF FIGURES .......................................................................................................................................................................................... II LIST OF TABLES ............................................................................................................................................................................................ II CHAPTER 1: INTRODUCTION ..................................................................................................................................................................... 1 REPORT ORGANIZATION ..................................................................................................................................................................... -

The Transformation Alliance
The TransFormation Alliance Strengthening Communities Through Transit The TransFormation Alliance is a diverse collaboration of organizations including, community advocates, policy experts, transit providers, and government agencies working toward a common goal to change how transit and community development investments shape the future, to offer all residents the opportunities for a high quality of life, linked by our region’s critically important transit system. Issues Driven People and Creative Placemaking Housing Choice and Transit Innovative Capital Equitable TOD Climate and Job Access Health Why It Matters Housing Cost Jobs Access 48% The percentage of income paid in 3.4% rent by City of Atlanta HH of jobs are accessible by a earning the lowest 20th 45 minute trip on transit. percentile. - Brookings Institute, 2016 Income Mobility 4% A child raised in the bottom fifth income bracket in Atlanta has just 4% chance of reaching the top fifth - Brookings Institute, 2016 MARTA links disparate communities The five highest median The five lowest median household incomes by MARTA household incomes by MARTA stop stop 1) Buckhead Station: 1) West End Station: $19,447 $104,518 2) Ashby Station: $21,895 2) Brookhaven-Oglethorpe 3) Oakland City Station: Station: $104,168 $23,000 3) East Lake Station: $97,037 4) Lakewood-Ft. McPherson 4) Lenox Station: $90, 766 Station: $25,236 5) Medical Center Station: 5) Bankhead Station: $26,168 $89,281 Station Area Typology Type A: • In/near major job centers • Improve job access Low Vulnerability + • Affluent -

MARTA Jurisdictional Briefing City of Atlanta
MARTA Jurisdictional Briefing City of Atlanta October 10, 2018 Jeffrey A. Parker | General Manager/CEO PRESENTATION OVERVIEW • More MARTA Atlanta Program / Approved Plan • State of Service • Ongoing Coordination Issues • Q & A 2 MORE MARTA ATLANTA PROGRAM / APPROVED PLAN MORE MARTA ATLANTA PROGRAM • Unanimous Approval by MARTA Board of Directors • $2.7 billion in sales tax over 40 years • Additional public/private funding to be sought • Targeted Investments: 22 Miles - Light Rail Transit (LRT) 14 Miles - Bus Rapid Transit (BRT) 26 Miles - Arterial Rapid Transit (ART) 2 New Transit Centers Additional Fixed-Route Bus Service Upgrades to existing Rail Stations • Two Years of Comprehensive Planning and Outreach • Nine Guiding Principles • Opportunities for more transit 4 THE PEOPLE’S PRIORITIES Based on public feedback, MARTA and City leaders refined the program, with emphasis on: Atlanta BeltLine Southeast/Southwest Station Enhancements $570M $600M+ $200M Plan builds out 61% of City‐adopted Includes LRT on Campbellton & SW Includes better access, amenities Atlanta BeltLine Streetcar Plan BeltLine and BRT link to downtown and ADA enhancements Clifton Corridor Downtown/Streetcar Bus System $250M $553M $238M Plus additional $100M contingent Connects BeltLine with downtown Includes more frequent bus on securing other local funding destinations and existing Streetcar service and new circulator routes 5 APPROVED PROGRAM 6 MORE MARTA Program MORE MARTA IMPLEMENTATION TO DATE • MARTA has already responded to public feedback. Since 2017, the -

Dekalb County Transit Master Plan Final Report - August 2019
DeKalb County Transit Master Plan Final Report - August 2019 Prepared for Prepared by 1355 Peachtree St. NE Suite 100 Atlanta, GA 30309 What is DeKalb County’s Transit Master Plan? The Transit Master Plan’s purpose is to address DeKalb County’s mobility challenges, help to enhance future development opportunities, and improve the quality of life within each of DeKalb County’s cities and unincorporated communities, both north and south. The plan identifies transit service enhancements for today and expansion opportunities for tomorrow to create a 30-year, cost-feasible vision for transit investments in DeKalb County Table of Contents Table of Contents Chapter 1 Introduction ...................................................................................................................... 1-1 Background ............................................................................................................................. 1-1 Project Goals ........................................................................................................................... 1-1 Chapter 2 State of DeKalb Transit ................................................................................................. 2-1 History of DeKalb Transit ................................................................................................... 2-1 DeKalb Transit Today .......................................................................................................... 2-2 Current Unmet Rider Needs ............................................................................................