Epsilon Equitable Partitions Based Approach for Role & Positional
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download 3.94 MB
Environmental Monitoring Report Semiannual Report (March–August 2019) Project Number: 49469-007 Loan Number: 3775 February 2021 India: Mumbai Metro Rail Systems Project Mumbai Metro Rail Line-2B Prepared by Mumbai Metropolitan Development Region, Mumbai for the Government of India and the Asian Development Bank. This environmental monitoring report is a document of the borrower. The views expressed herein do not necessarily represent those of ADB's Board of Directors, Management, or staff, and may be preliminary in nature. In preparing any country program or strategy, financing any project, or by making any designation of or reference to a particular territory or geographic area in this document, the Asian Development Bank does not intend to make any judgments as to the legal or other status of any territory or area. ABBREVATION ADB - Asian Development Bank ADF - Asian Development Fund CSC - construction supervision consultant AIDS - Acquired Immune Deficiency Syndrome EA - execution agency EIA - environmental impact assessment EARF - environmental assessment and review framework EMP - environmental management plan EMR - environmental Monitoring Report ESMS - environmental and social management system GPR - Ground Penetrating Radar GRM - Grievance Redressal Mechanism IEE - initial environmental examination MMRDA - Mumbai Metropolitan Region Development Authority MML - Mumbai Metro Line PAM - project administration manual SHE - Safety Health & Environment Management Plan SPS - Safeguard Policy Statement WEIGHTS AND MEASURES km - Kilometer -

Form 990-PF 2017
l efile GRAPHIC print - DO NOT PROCESS As Filed Data - DLN:93491134045128 OMB No 1545-0052 Form 990-PF Return of Private Foundation Department of the Trea^un or Section 4947(a)(1) Trust Treated as Private Foundation Internal Rev enue Ser ice 2017 ► Do not enter social security numbers on this form as it may be made public. ► Information about Form 990-PF and its instructions is at www.irs.gov/form990pf. For calendar year 2017, or tax year beginning 01 -01-2017 , and ending 12-31-2017 Name of foundation HORTON FAMILY FOUNDATION 77-0496939 Number and street (or P O box number if mail is not delivered to street address) Room/suite B Telephone number (see instructions) 26030 ALTAMONT ROAD City or town, state or province, country, and ZIP or foreign postal code LOS ALTOS HILLS, CA 94022 C If exemption application is pending, check here q G Check all that apply q Initial return q Initial return of a former public charity D 1. Foreign organizations, check here ► q Final return q Amended return 2 Foreign organizations meeting the 85% q test, check here and attach computation ► El Address change El Name change E If private foundation status was terminated H Check typ e of org anization q Section 501(c)(3) exem p t p rivate foundation under section 507(b)(1)(A), check here ► q Section 4947(a)(1) nonexempt charitable trust q Other taxable private foundation I Fair market value of all assets at end J Accounting method 9 Cash q Accrual F If the foundation is in a 60-month termination of year (from Part II, col (c), under section 507(b)(1)(B), check here q ► line 16)101$ 906,110 Other (specify) (Part I, column (d) must be on cash basis ) Analysis of Revenue and Expenses (The total ( a) Revenue and (d) Disbursements (b) Net investment (c) Adjusted net for charitable of amounts n columns (b), (c), and (d) may not necessarily expenses per income income purposes books basis equal the amounts in column (a) (see instructions) ) (cash s only) 1 Contributions, gifts, grants, etc , received (attach 300,000 schedule) 2 Check ► W if the foundation is not required to attach Sch B . -
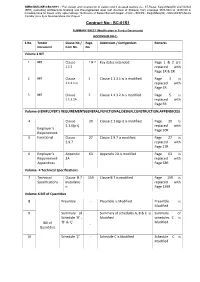
Contract No:- BC-01R1
DMRC/MU/LINE-6/BC/01R1 : “Part design and construction of viaduct and 3 elevated stations viz., IIT-Powai, KanjurMarg(W) and Vikrholi (EEH) (excluding Architectural finishing and Pre-engineered steel roof structure of Stations) from chainage 9586.50m to 14358.00 m including ramp for Depot entry uptochainage 14490.60m of Swami Samarth Nagar –JVLR – SEEPZ - KanjurMarg(W) –Vikhroli(EEH) Metro Corridor (Line 6) of Mumbai Metro Rail Project .” Contract No:- BC-01R1 SUMMARY SHEET (Modification in Tender Documents) (ADDENDUM NO-1) S.No. Tender Clause No./ Page- Addendum / Corrigendum Remarks Document Item No. No. Volume-1 NIT 1 NIT Clause 1 & 2 Key dates extended Page 1 & 2 are 1.1.2 replaced with Page 1R & 2R 2 NIT Clause 3 Clause 1.1.3.1 iv is modified. Page 3 is 1.1.3.1 iv replaced with Page 3R 3 NIT Clause 5 Clause 1.1.3.2 A is modified. Page 5 is 1.1.3.2A replaced with Page 5R Volume-3 EMPLOYER’S REQUIREMENT(GENERAL,FUNCTIONAL,DESIGN,CONSTRUCTION,APPENDICES) 4 Clause 20 Clause 2.1.6(p-i) is modified. Page 20 is 2.1.6(p-i) replaced with Employer’s Page 20R Requirement- 5 Functional Clause 27 Clause 2.9.7 is modified. Page 27 is 2.9.7 replaced with Page 27R 6 Employer’s Appendix 63 Appendix 2A is modified Page 63 is Requirement- 2A replaced with Appendices Page 63R Volume -4 Technical Specifications 7 Technical Clause B.7 159 Clause B.7 is modified Page 159 is Specifications Installatio replaced with n Page 159R Volume-6 Bill of Quantities 8 Preamble - Preamble is Modified Preamble is Modified 9 Summary of Summary of schedules A, B & C is Summary of Schedule ‘Á’ , Modified schedules C is Bill of ‘B’ & ‘Ç’ Modified - Quantities 10 Schedule ‘Ç’ - Schedule C is Modified Schedule C is Modified Contract: DMRC/MU/LINE6/BC/01R1: Part design and construction of viaduct and 3 elevated stations viz. -

Integrated Ticketing System for Mumbai Metropolitan Region
Leadership in Urban Transport Project on Integrated Ticketing System for Mumbai Metropolitan Region Urban Mobility India Conference Presented by: 1. Smt.K Vijaya Lakshmi, Chief, Transport & Communications Division, MMRDA 2. Shri. Raju Bhadke, Dy. Chief Engineer, Indian Railways 3. Shri. Goraksha V.Jagtap, Dy Chief Personnel Officer, Central Railway Mumbai Metropolitan Region (MMR) Particulars India Maharashtra MMR MCGM Population 2011 Census (in 1,210 112 23 12 millions) (1.21 billion) 0.112 (billion) (0.023 billion) (0.012 billion) Area Sq. km 3,287,240 307,713 4,253 438 382 370 5,361 28,310 Density - Persons per sq. km Urban Pop in % 32% 45.23% 94% 100% GDP Per Capita (USD/annum) $1,626.62 $1,963.33 $2,120.18 $2,570.73 2 Public transport system in Mumbai Metropolitan Region (MMR)… Rail Metro Bus 5 modes of public transport system + IPTs Monorail Ferry 3 Operated by 14+ Public Transport Operators (PTOs) Mix of Central, State & Local Governments as well as Private operators Bus Railways Metro Monorail Others Brihanmumbai Electric Western Railways Mumbai Metro One Mumbai Mumbai Supply and Transport Private Limited Monorail Maritime (BEST) (MMPOL) (MMRDA) Board Navi Mumbai Municipal Central Railways Mumbai Metro Rail Transport (NMMT) Corporation (MMRC) Thane Municipal Transport Mumbai Rail Vikas (TMT) Corporation (MRVC) Navi Mumbai Metro Vasai Virar Municipal MMRDA Metro Transport (VVMT) Kalyan Dombivali Municipal Transport (KDMT) Mira Bhayandar Municipal Transport (MBMT) Ulhasnagar Municipal Transport (UMT) 4 Railways- Key Statistics 7.5 -

Mumbai Infrastructure: What Is and What Will Be?
MUMBAI INFRASTRUCTURE: WHAT IS AND WHAT WILL BE? Infrastructure development acts as a cornerstone for any city in order to determine the growth trajectory and to become an economic and real estate powerhouse. While Mumbai is the financial capital of India, its infrastructure has not been able to keep pace with the sharp rise in its demographic and economic profile. The city’s road and rail infrastructure is under tremendous pressure from serving a population of more than 25 million people. This report outlines major upcoming infrastructure projects and analyses their impact on the Mumbai real estate market. This report is interactive CBRE RESEARCH DECEMBER 2018 Bhiwandi Dahisar Towards Nasik What is Mumbai’s Virar Towards Sanjay Borivali Gandhi Thane Dombivli National current infrastructure Park framework like? Andheri Mumbai not only has a thriving commercial segment, but the residential real estate development has spread rapidly to the peripheral areas of Thane, Navi Mumbai, Vasai-Virar, Dombivli, Kalyan, Versova Ghatkopar etc. due to their affordability quotient. Commuting is an inevitable pain for most Mumbai citizens and on an average, a Mumbai resident Vashi spends at least 4 hours a day in commuting. As a result, a physical Chembur infrastructure upgrade has become the top priority for the citizens and the government. Bandra Mankhurd Panvel Bandra Worli Monorail Metro Western Suburban Central Rail Sea Link Phase 1 Line 1 Rail Network Network Wadala P D’Mello Road Harbour Rail Thane – Vashi – Mumbai Major Metro Major Railway WESTERN -

A Better Relationship Between Transit-Oriented Development and Pedestrian Connectivity" (2019)
Iowa State University Capstones, Theses and Creative Components Dissertations Summer 2019 Connecting the Nodes: A better relationship between Transit- Oriented Development and Pedestrian Connectivity Tanvi Halde [email protected] Follow this and additional works at: https://lib.dr.iastate.edu/creativecomponents Part of the Urban, Community and Regional Planning Commons Recommended Citation Halde, Tanvi, "Connecting the Nodes: A better relationship between Transit-Oriented Development and Pedestrian Connectivity" (2019). Creative Components. 312. https://lib.dr.iastate.edu/creativecomponents/312 This Creative Component is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Creative Components by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. CONNECTING THE NODES A better Relationship between TOD and Pedestrian Connectivity By Tanvi Sharad Halde A creative component submitted to the graduate faculty in Partial fulfillment of the requirements for the degree of MASTER OF COMMUNITY AND REGIONAL PLANNING MASTER OF URBAN DESIGN Major: Community and regional planning and Urban Design Program of Study Committee: Professor Carlton Basmajian, Major Professor Professor Sungduck Lee, Major Professor Professor Biswa Das, Committee Member Iowa State University Ames Iowa 2019 Copyright Tanvi Sharad Halde, 2019. All rights reserved. -

Reseteveryday in the Future of Urban Connectivity Stock Image for Representation Purpose Only
#ResetEveryday in the future of urban connectivity Stock image for representation purpose only. IN PARTNERSHIP WITH The Project registered as “Godrej Emerald Thane” with MahaRERA No. P51700000120 available at: http://maharera.mahaonline.gov.in The Sale is subject to terms of Application Form and Agreement for Sale. All specifications of the unit shall be as per the final agreement between the Parties. Recipients are advised to apprise themselves of the necessary and relevant information of the project prior to making any purchase decisions. The upcoming infrastructure facility(ies) mentioned in this document are proposed to be developed by the Government and other authorities and we cannot predict the timing or the actual provisioning of these facility(ies), as the same is beyond our control. We shall not be responsible or liable for any delay or non-provisioning of the same. The official website of Godrej Properties Limited is www.godrejproperties.com. Please do not rely on the information provided on any other website. Situated in the lap of nature, Godrej Emerald lets you bask in the serenity of the beautiful Yeoor hills. Break free and unwind, every day with mesmerizing views and surreal surroundings. The designs, dimensions, facilities, images, specifications, items, electronic goods, additional fittings/fixtures, shades, sizes and colour of the tile and other details shown in the image are only indicative in nature and are only for the purpose of indicating a possible layout and do not form part of standard specification/amenities to be provided in the project. Artist’s impression. Not an actual site photograph. Towards Vasai-Virar RESET EVERYDAY AT A HOME METRO LINE 10 Towards GAIMUKH JUNCTION THAT IS WELL-CONNECTED Western Suburbs STATION MIRA ROAD 14 min drive time from Godrej Emerald$ METRO LINE 4A Highway METRO LINE 10 A SERENE NEIGHBOURHOOD GODREJ Express EMERALD Kasarvadavali Surround yourself with the effervescence of nature. -

Alstom Wins €220 Million Contract to Design and Manufacture 234 Metro Cars for Mumbai Metro Lines 4 & 4A First Major Order for Company’S Extended Indian Portfolio
PRESS RELEASE Alstom wins €220 million contract to design and manufacture 234 metro cars for Mumbai Metro Lines 4 & 4A First major order for company’s extended Indian portfolio 30 March 2021 – Alstom has been awarded by Mumbai Metropolitan Region KEY FIGURES Development Authority (MMRDA) the contract to design, manufacture, supply, test and commission 234 metro cars, including personnel training for Line 4 and the extension corridor (Wadala-Kasarvardavali-Gaimukh). The order is valued at €220 234 Metro cars million (INR 1854 Crores). 220 Million euros New products have been added to Alstom’s portfolio as part of the acquisition of 32 Metro stations Bombardier Transportation (BT) on January 29, 2021. The combined portfolio of products, signalling, engineering and services allows a significantly increased offering for customers across India and the Asia Pacific Region. “These are exciting times, and this first order, following our merger with Bombardier Transportation demonstrates our continued commitment towards partnering in the country’s Make-in-India mission. We are glad to have been awarded this prestigious project by MMRDA and look forward to commencing work on this. Alstom is proud to play a part in strengthening the country’s infrastructure and providing world-class mobility solutions to the commercial capital of India,” said Ling Fang, Region President, Alstom Asia Pacific. The Line is a 35.3-kilometre-long elevated corridor with 32 stations. It will provide interconnectivity among the existing Eastern Express Roadway, Mono Rail, the ongoing Metro Line 2B (D N Nagar - Mandale), and the proposed Metro Line 5 (Thane - Kalyan), Metro Line 6 (Swami Samarth Nagar - Vikhroli). -

A Better Relationship Between Transit-Oriented Development and Pedestrian Connectivity" (2019)
Iowa State University Capstones, Theses and Creative Components Dissertations Summer 2019 Connecting the Nodes: A better relationship between Transit- Oriented Development and Pedestrian Connectivity Tanvi Halde Follow this and additional works at: https://lib.dr.iastate.edu/creativecomponents Part of the Urban, Community and Regional Planning Commons Recommended Citation Halde, Tanvi, "Connecting the Nodes: A better relationship between Transit-Oriented Development and Pedestrian Connectivity" (2019). Creative Components. 312. https://lib.dr.iastate.edu/creativecomponents/312 This Creative Component is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Creative Components by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. CONNECTING THE NODES A better Relationship between TOD and Pedestrian Connectivity By Tanvi Sharad Halde A creative component submitted to the graduate faculty in Partial fulfillment of the requirements for the degree of MASTER OF COMMUNITY AND REGIONAL PLANNING MASTER OF URBAN DESIGN Major: Community and regional planning and Urban Design Program of Study Committee: Professor Carlton Basmajian, Major Professor Professor Sungduck Lee, Major Professor Professor Biswa Das, Committee Member Iowa State University Ames Iowa 2019 Copyright Tanvi Sharad Halde, 2019. All rights reserved. TABLE OF CONTENTS LIST -

Godrej Urban Park Mini Docket
T T E E R B by Stock image for representation purpose only. Stock image for representation The project is registered as Godrej Urban Park under MahaRERA No. P51800028364 available at http://maharera.mahaonline.gov.in. A legacy 124 years in the making. The Godrej story began in 1897, with the manufacturing of locks. Since then, we have set several benchmarks. From a state-of-the-art manufacturing facility in a suburb of Mumbai, we’ve reached homes, offices, industries and the hearts of millions of people in India and around the world. With a proud tradition of many firsts, we find ourselves at work every day, building on the foundation of trust that was laid 124 years ago. Actual photograph. The grey, the green and everything in between. Chandivali - It's a great place to be. While being close to all the comforts of a city yet surrounded by greenery, Chandivali has become one of the preferred destinations to live in. And what's more, Chandivali enjoys great connectivity to different parts of the city and very soon it will get even better. Chandivali – A destination that’s growing, year after year. Over the past 6 years, Chandivali has s een a growth of 33% in its saleable area. Chandivali as a micromarket has seen a 140% appreciation as compared to Powai making it a more viable option. Stock image for representation purpose only. https://mmrda.maharashtra.gov.in/metro-line-1 https://mmrda.maharashtra.gov.in/documents/10180/9283015/Metro+Line+6+DPR/17c5ed14-e9fb-4920-9521-02eebb25c4a9 Source: Liases Foras Chandivali a better neighbourhood, a better life. -

Metro Rail Corridors in MMR & M B Im T Li 3 Mumbai Metro Line 3
Metro Rail Corridors in MMR & MbiMumbai MtMetro Line 3 Sanjay Sethi, MD, MMRC Mumbai Metro Rail Corporation Limited 1 CTS Study for MMR & Transportation Scenario • CTS called “TransForm” –with World Bank assistance Objectives: Determine travel Pattern Asses Transport Infra needs Phased Investment Programme 52% 26% 22% • 11 m travel daily by Public Transport (PT share is 78%) • Many areas are not served by rail based system • 5,000 pax /train against capacity of 1,750 ‐ resulting in severe overcrowding • Increase in pvt vehicles resulting in severe congestion & pollution 2 Summary of Preliminary Cost Estimates Proposed Transport Networks Horizon Years 2031, 2021 and 2016 2008- 2031 2008- 2021 2008- 2016 Component Length Cost Length Cost Length Cost km Rs Crores km Rs Crores km Rs Crores Metro System 450 1,10,095 316 82,707 204 59,623 Sub-Urban Railway System 241 30,978 231 28,670 231 27,920 Highway System 1660 57,412 1114 44,844 836 31,173 Highway Corridors with 77 1,670 111 2,000 147 11,079 EBL Bus System 4,280 2,150 1,104 Passenger Water Transport 480 480 480 Truck Terminals, Inter-Bus 3,040 2,038 1,126 and Rail Terminals 2,,,07,956 1,,,62,890 1,,,32,504 Total 2,429 1,772 1,418 US $ 50.72 Billion US $ 39.73 Billion US $ 32.32 Billion Note: 1. The cost estimates are @ 2005-06 prices 2. The metro syygstem cost includes the cost of rolling stock 3. The sub-urban railway system cost includes the cost of rolling stock for new lines, capacity enhancement of the to the existing sub-urban railway system Metro Master plan 1. -

Belleza E Brochure
YOUR FLIGHT OF FANCY ENDS AT THIS OF Site Address: Dosti Belleza, Adjacent to JBCN International School, G. D. Ambekar Marg, Parel, Mumbai - 400 012 • T: +91 22 4132 2222 Corporate Office: Dosti Realty Ltd., Lawrence & Mayo House, 1st Floor, 276, Dr. D. N. Road, Fort, Mumbai - 400 001. www.dostirealty.com The project has been registered via MAHARERA registration number: P51900015989 and is available on website - https://maharerait.mahaonline.gov.in under registered projects. Disclosures: (1) The artist’s impressions and stock images are used for representation purpose only. (2) Furniture, fittings and fixtures as shown/displayed in the image of flat are for the purpose of showcasing only and do not form part of actual standard amenities to be provided in the flat. The flats offered for sale are unfurnished and all the amenities proposed to be provided in the flat shall be incorporated in the Agreement for Sale. (3) The sale of all the flats in the Dosti Belleza shall be governed by terms and conditions incorporated in the Agreement for Sale. (4) The project is mortgaged to ICICI Bank Ltd. NOC from the mortgagee bank will be provided, if required. IF YOU EVER BELIEVED IN THE Beauty OF YOUR Dreams... Actual North Side View From Site HERE’S A Reality MORE THAN YOURBeautiful DREAMS. Dreams are fragile. Dreams are fleeting. Dreams are unreal. But if your dreams are beautiful, and if you have a steadfast belief in the beauty of your dreams; a beautiful reality is never far away. Presenting Dosti Belleza. Indeed a refined manifestation of your delightful dreams, this stunning work of art fulfils your aspirations which you thought were ever so elusive.