Semantic Transliteration of Personal Names
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Kūnqǔ in Practice: a Case Study
KŪNQǓ IN PRACTICE: A CASE STUDY A DISSERTATION SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAI‘I AT MĀNOA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY IN THEATRE OCTOBER 2019 By Ju-Hua Wei Dissertation Committee: Elizabeth A. Wichmann-Walczak, Chairperson Lurana Donnels O’Malley Kirstin A. Pauka Cathryn H. Clayton Shana J. Brown Keywords: kunqu, kunju, opera, performance, text, music, creation, practice, Wei Liangfu © 2019, Ju-Hua Wei ii ACKNOWLEDGEMENTS I wish to express my gratitude to the individuals who helped me in completion of my dissertation and on my journey of exploring the world of theatre and music: Shén Fúqìng 沈福庆 (1933-2013), for being a thoughtful teacher and a father figure. He taught me the spirit of jīngjù and demonstrated the ultimate fine art of jīngjù music and singing. He was an inspiration to all of us who learned from him. And to his spouse, Zhāng Qìnglán 张庆兰, for her motherly love during my jīngjù research in Nánjīng 南京. Sūn Jiàn’ān 孙建安, for being a great mentor to me, bringing me along on all occasions, introducing me to the production team which initiated the project for my dissertation, attending the kūnqǔ performances in which he was involved, meeting his kūnqǔ expert friends, listening to his music lessons, and more; anything which he thought might benefit my understanding of all aspects of kūnqǔ. I am grateful for all his support and his profound knowledge of kūnqǔ music composition. Wichmann-Walczak, Elizabeth, for her years of endeavor producing jīngjù productions in the US. -

SSA1208 / GES1005 – Everyday Life of Chinese Singaporeans: Past and Present
SSA1208 / GES1005 – Everyday Life of Chinese Singaporeans: Past and Present Group Essay Ho Lim Keng Temple Prepared By: Tutorial [D5] Chew Si Hui (A0130382R) Kwek Yee Ying (A0130679Y) Lye Pei Xuan (A0146673X) Soh Rolynn (A0130650W) Submission Date: 31th March 2017 1 Content Page 1. Introduction to Ho Lim Keng Temple 3 2. Exterior & Courtyard 3 3. Second Level 3 4. Interior & Main Hall 4 5. Main Gods 4 6. Secondary Gods 5 7. Our Views 6 8. Experiences Encountered during our Temple Visit 7 9. References 8 10. Appendix 8 2 1. Introduction to Ho Lim Keng Temple Ho Lim Keng Temple is a Taoist temple and is managed by common surname association, Xu (许) Clan. Chinese clan associations are benevolent organizations of popular origin found among overseas Chinese communities for individuals with the same surname. This social practice arose several centuries ago in China. As its old location was acquisited by the government for redevelopment plans, they had moved to a new location on Outram Hill. Under the leadership of 许木泰宗长 and other leaders, along with the clan's enthusiastic response, the clan managed to raise a total of more than $124,000, and attained their fundraising goal for the reconstruction of the temple. Reconstruction works commenced in 1973 and was completed in 1975. Ho Lim Keng Temple was advocated by the Xu Clan in 1961, with a board of directors to manage internal affairs. In 1966, Ho Lim Keng Temple applied to the Registrar of Societies and was approved on February 28, 1967 and then was published in the Government Gazette on March 3. -

The Zhuan Xupeople Were the Founders of Sanxingdui Culture and Earliest Inhabitants of South Asia
E-Leader Bangkok 2018 The Zhuan XuPeople were the Founders of Sanxingdui Culture and Earliest Inhabitants of South Asia Soleilmavis Liu, Author, Board Member and Peace Sponsor Yantai, Shangdong, China Shanhaijing (Classic of Mountains and Seas) records many ancient groups of people (or tribes) in Neolithic China. The five biggest were: Zhuan Xu, Di Jun, Huang Di, Yan Di and Shao Hao.However, the Zhuan Xu People seemed to have disappeared when the Yellow and Chang-jiang river valleys developed into advanced Neolithic cultures. Where had the Zhuan Xu People gone? Abstract: Shanhaijing (Classic of Mountains and Seas) records many ancient groups of people in Neolithic China. The five biggest were: Zhuan Xu, Di Jun, Huang Di, Yan Di and Shao Hao. These were not only the names of individuals, but also the names of groups who regarded them as common male ancestors. These groups used to live in the Pamirs Plateau, later spread to other places of China and built their unique ancient cultures during the Neolithic Age. Shanhaijing reveals Zhuan Xu’s offspring lived near the Tibetan Plateau in their early time. They were the first who entered the Tibetan Plateau, but almost perished due to the great environment changes, later moved to the south. Some of them entered the Sichuan Basin and became the founders of Sanxingdui Culture. Some of them even moved to the south of the Tibetan Plateau, living near the sea. Modern archaeological discoveries have revealed the authenticity of Shanhaijing ’s records. Keywords: Shanhaijing; Neolithic China, Zhuan Xu, Sanxingdui, Ancient Chinese Civilization Introduction Shanhaijing (Classic of Mountains and Seas) records many ancient groups of people in Neolithic China. -

The Guo Boxiong Edition James Mulvenon
So Crooked They Have to Screw Their Pants On Part 3: The Guo Boxiong Edition James Mulvenon On 30 July, the Central Committee announced that General Guo Boxiong, who served as vice-chairman of the Central Military Commission between 2002 and 2012, was expelled from the Chinese Communist Party and handed over to prosecutors for accepting bribes “on his own and through his family . for aiding in the promotion [of officers].” Guo’s expulsion comes one year after similar charges against his fellow CMC vice-chair Xu Caihou, who died of bladder cancer in March 2015. This article examines the charges against Guo, places them in the context of the larger anti-corruption campaign within the PLA, and assesses their implications for Xi Jinping’s relationship with the military and for party-army relations. The Rise and Fall of Guo Boxiong On 30 July, the Central Committee announced that General Guo Boxiong, who served as vice-chairman of the Central Military Commission between 2002 and 2012, was expelled from the Chinese Communist Party and handed over to prosecutors for accepting bribes “on his own and through his family . for aiding in the promotion [of officers].”1 Guo’s explusion comes one year after similar charges against his fellow CMC vice-chair Xu Caihou, who was expelled from the party in June 2014 and died of bladder cancer in March 2015.2 This article examines the charges against Guo, places them in the context of the larger anti-corruption campaign within the PLA, and assesses their implications for Xi Jinping’s relationship with the military and for party-army relations. -

The Case of Wang Wei (Ca
_full_journalsubtitle: International Journal of Chinese Studies/Revue Internationale de Sinologie _full_abbrevjournaltitle: TPAO _full_ppubnumber: ISSN 0082-5433 (print version) _full_epubnumber: ISSN 1568-5322 (online version) _full_issue: 5-6_full_issuetitle: 0 _full_alt_author_running_head (neem stramien J2 voor dit article en vul alleen 0 in hierna): Sufeng Xu _full_alt_articletitle_deel (kopregel rechts, hier invullen): The Courtesan as Famous Scholar _full_is_advance_article: 0 _full_article_language: en indien anders: engelse articletitle: 0 _full_alt_articletitle_toc: 0 T’OUNG PAO The Courtesan as Famous Scholar T’oung Pao 105 (2019) 587-630 www.brill.com/tpao 587 The Courtesan as Famous Scholar: The Case of Wang Wei (ca. 1598-ca. 1647) Sufeng Xu University of Ottawa Recent scholarship has paid special attention to late Ming courtesans as a social and cultural phenomenon. Scholars have rediscovered the many roles that courtesans played and recognized their significance in the creation of a unique cultural atmosphere in the late Ming literati world.1 However, there has been a tendency to situate the flourishing of late Ming courtesan culture within the mainstream Confucian tradition, assuming that “the late Ming courtesan” continued to be “integral to the operation of the civil-service examination, the process that re- produced the empire’s political and cultural elites,” as was the case in earlier dynasties, such as the Tang.2 This assumption has suggested a division between the world of the Chinese courtesan whose primary clientele continued to be constituted by scholar-officials until the eight- eenth century and that of her Japanese counterpart whose rise in the mid- seventeenth century was due to the decline of elitist samurai- 1) For important studies on late Ming high courtesan culture, see Kang-i Sun Chang, The Late Ming Poet Ch’en Tzu-lung: Crises of Love and Loyalism (New Haven: Yale Univ. -

Using Online Applications to Improve Tone Perception Among L2 Learners of Chinese (网络应用对中文二语学习者声调辨识的有效性研究)
Journal of Technology and Chinese Language Teaching Volume 10 Number 1, June 2019 http://www.tclt.us/journal/2019v10n1/xulili.pdf pp. 26-56 Using Online Applications to Improve Tone Perception among L2 Learners of Chinese (网络应用对中文二语学习者声调辨识的有效性研究) Xu, Hongying Li, Yan Li, Yingjie (徐红英) (李艳) (李颖颉) University of University of University of Colorado- Wisconsin-La Crosse Kansas Boulder (威斯康星大学拉克 (堪萨斯大学) (科罗拉多大学博尔得分 罗校区) [email protected] 校) [email protected] [email protected] Abstract: This study investigated the effectiveness of an online application in helping beginning-level Chinese learners improve their perception of the tones in Mandarin Chinese. Two groups—one experimental and one traditional—of beginning Chinese learners from two universities in the Midwest participated in this study. The experimental group (n=20) used the online application to practice tones for four 15-minute sessions in class. The traditional group (n=11) participated in traditional instructor-led practice in class in lieu of the online practice. Both groups completed a pre-test, an immediately administered post-test, and a delayed post-test designed to assess their perception of the tones of monosyllabic and disyllabic words. No statistically significant difference has been found between the two groups in their tone perception performance in the post-test and in the delayed post-test. However, the experimental group showed a positive trend in improving their perception on those tones which posed more difficulty than others. Their experience with this online application and the pronunciation learning strategies of participants in the experimental group were also examined through a survey. Based on the findings, it is proposed that the use of online tone practice is worthwhile in a Chinese language class, but might fit better into the curriculum as external assignments. -

Gěi ’Give’ in Beijing and Beyond Ekaterina Chirkova
Gěi ’give’ in Beijing and beyond Ekaterina Chirkova To cite this version: Ekaterina Chirkova. Gěi ’give’ in Beijing and beyond. Cahiers de linguistique - Asie Orientale, CRLAO, 2008, 37 (1), pp.3-42. hal-00336148 HAL Id: hal-00336148 https://hal.archives-ouvertes.fr/hal-00336148 Submitted on 2 Nov 2008 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Gěi ‘give’ in Beijing and beyond1 Katia Chirkova (CRLAO, CNRS) This article focuses on the various uses of gěi ‘give’, as attested in a corpus of spoken Beijing Mandarin collected by the author. These uses are compared to those in earlier attestations of Beijing Mandarin and to those in Greater Beijing Mandarin and in Jì-Lǔ Mandarin dialects. The uses of gěi in the corpus are demonstrated to be consistent with the latter pattern, where the primary function of gěi is that of indirect object marking and where, unlike Standard Mandarin, gěi is not additionally used as an agent marker or a direct object marker. Exceptions to this pattern in the corpus are explained as a recent development arisen through reanalysis. Key words : gěi, direct object marker, indirect object marker, agent marker, Beijing Mandarin, Northern Mandarin, typology. -
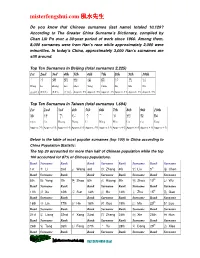
Misterfengshui.Com 風水先生
misterfengshui.com 風水先生 Do you know that Chinese surnames (last name) totaled 10,129? According to The Greater China Surname’s Dictionary, compiled by Chan Lik Pu over a 30-year period of work since 1960. Among them, 8,000 surnames were from Han’s race while approximately 2,000 were minorities. In today’s China, approximately 3,000 Han’s surnames are still around. Top Ten Surnames In Beijing (total surnames 2,225) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 王 李 張 劉 趙 楊 陳 徐 馬 吳 Wang Li Zhang Liu Zhao Yang Chen Xu Ma Wu (10.6% ) (9.6%) (9.6%) (7.7% ) Approx. 5% Approx. 5% Approx. 4% Approx. 4% Approx. 4% Approx. 3% Top Ten Surnames In Taiwan (total surnames 1,694) 1st 2nd 3rd 4th 5th 6th 7th 8th 9th 10th 陳 林 黃 張 李 王 吳 劉 蔡 楊 Chen Lin Huang Zhang Li Wang Wux. Liu Cai Yang Approx .7% Approx 6 % Approx 6 % Approx 6 % Approx. 5% Approx 5 % Approx 4 % Approx 4 % Approx 4 % Approx 4 % Below is the table of most popular surnames (top 100) in China according to China Population Statistic: The top 20 accounted for more than half of Chinese population while the top 100 accounted for 87% of Chinese populations. Rank Surname Rank Rank Surname Rank Surname Rank Surname 1st 李 Li 2nd 王 Wang 3rd 張 Zhang 4th 劉 Liu 5th 陳 Chen Rank Surname Rank Rank Surname Rank Surname Rank Surname 6th 楊 Yang 7th 趙 Zhao 8th 黃 Huang 9th 周 Zhou 10 th 吳 Wu Rank Surname Rank Rank Surname Rank Surname Rank Surname 11th 徐 Xu 12th 孫 Sun 13th 胡 Hu 14th 朱 Zhu 15 th 高 Gao Rank Surname Rank Rank Surname Rank Surname Rank Surname 16th 林 Lin 17th 何 He 18th 郭 Guo 19th 馬 Ma 20 th 羅 Luo Rank -

Ideology and Performance in Public Organizations∗
Ideology and Performance in Public Organizations∗ J¨orgL. Spenkuch Edoardo Teso Guo Xu Northwestern Kellogg Northwestern Kellogg Berkeley Haas April 3, 2021 Abstract We combine personnel records of the United States federal bureaucracy from 1997{ 2019 with administrative voter registration data to study how ideological alignment between politicians and bureaucrats affects the personnel policies and performance of public organizations. We present four results. (i) Consistent with the use of the spoils system to align ideology at the highest levels of government, we document sig- nificant partisan cycles and substantial turnover among political appointees. (ii) By contrast, we find virtually no political cycles in the civil service. The lower levels of the federal government resemble a \Weberian" bureaucracy that appears to be largely protected from political interference. (iii) Democrats make up the plurality of civil servants. Overrepresentation of Democrats increases with seniority, with the difference in career progression being largely explained by positive selection on observables. (iv) Political misalignment carries a sizeable performance penalty. Exploiting presidential transitions as a source of \within-bureaucrat" variation in the political alignment of procurement officers over time, we find that contracts overseen by a misaligned officer exhibit cost overruns that are, on average, 8% higher than the mean overrun. We provide evidence that is consistent with a general \morale effect,” whereby misaligned bureaucrats are less motivated. Our -

Names of Chinese People in Singapore
101 Lodz Papers in Pragmatics 7.1 (2011): 101-133 DOI: 10.2478/v10016-011-0005-6 Lee Cher Leng Department of Chinese Studies, National University of Singapore ETHNOGRAPHY OF SINGAPORE CHINESE NAMES: RACE, RELIGION, AND REPRESENTATION Abstract Singapore Chinese is part of the Chinese Diaspora.This research shows how Singapore Chinese names reflect the Chinese naming tradition of surnames and generation names, as well as Straits Chinese influence. The names also reflect the beliefs and religion of Singapore Chinese. More significantly, a change of identity and representation is reflected in the names of earlier settlers and Singapore Chinese today. This paper aims to show the general naming traditions of Chinese in Singapore as well as a change in ideology and trends due to globalization. Keywords Singapore, Chinese, names, identity, beliefs, globalization. 1. Introduction When parents choose a name for a child, the name necessarily reflects their thoughts and aspirations with regards to the child. These thoughts and aspirations are shaped by the historical, social, cultural or spiritual setting of the time and place they are living in whether or not they are aware of them. Thus, the study of names is an important window through which one could view how these parents prefer their children to be perceived by society at large, according to the identities, roles, values, hierarchies or expectations constructed within a social space. Goodenough explains this culturally driven context of names and naming practices: Department of Chinese Studies, National University of Singapore The Shaw Foundation Building, Block AS7, Level 5 5 Arts Link, Singapore 117570 e-mail: [email protected] 102 Lee Cher Leng Ethnography of Singapore Chinese Names: Race, Religion, and Representation Different naming and address customs necessarily select different things about the self for communication and consequent emphasis. -

Ailing Zeng Í
SHB 1026, CUHK Shatin, Hong Kong SAR, China H +86 13005414090 B [email protected] Ailing Zeng Í https://ailingzeng.site Research Interest 3D Human Pose Estimation in images/videos, Human Action Recognition/Analysis, Motion Prediction Education 2017-Present Year-Four Ph.D. Student, Department of Computer Science & Engineering, The Chinese University of Hong Kong, Hong Kong SAR Full Postgraduate Studentship, Supervisor: Qiang Xu 2013-2017 B.Eng., Electronic Engineering / Finance mathematics, Xiamen University, Xiamen, China School Ranking: 1/95 Publication 2021 Learning Skeletal Graph Neural Networks for Hard 3D Pose Estimation, Ailing Zeng, Xiao Sun, Lei Yang, Nanxuan Zhao, Minhao Liu, Qiang Xu, The International Conference on Computer Vision (ICCV’21) 2021 SmoothNet: A Universal Plug-and-Play Network for Robust Human Pose and Body Reconstruction in Videos Ailing Zeng, Lei Yang, Jianyi Wang, Jiefeng Li, Qiang Xu (under review) 2021 Hop-Aware Dimension Optimization for Graph Neural Networks Ailing Zeng, Minhao Liu, Zhiwei Liu, Ruiyuan Gao, Qiang Xu (under review) 2021 Human Pose Regression with Residual Log-likelihood Estimation, Jiefeng Li, Siyuan Bian, Ailing Zeng, Can Wang, Bo Pang and Cewu Lu, The International Conference on Computer Vision (ICCV’21, Oral) 2021 Skimming and Scanning for Untrimmed Video Action Recognition, Yunyan Hong*, Ailing Zeng*, Min Li, Cewu Lu, Li Jiang, Qiang Xu The International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI’21) 2021 Time Series is a Special Sequence: -

527 Títulos De Livros Antigos De Medicina Chinesa. Lista Organizada Pela People's Medical Publishing House - China
527 Títulos de Livros Antigos de Medicina Chinesa. Lista organizada pela People's Medical Publishing House - China www.medicinaclassicachinesa.org Vários desses livros podem ser encontrados em versão gratuita no site http://www.zysj.com.cn/lilunshuji/5index.html 中文名 作者名(字号) 出书年代 Titulo em 拼音 英文名 Nome Real ou Literário Data em que escrito Chinês Pin Yin Titulo em Inglês do Autor ou publicado. Zhang Zhong‐hua 张仲 华 (Style 号 Zhang Ai‐lu 1. 爱庐医案 Ài Lú Yī Àn [Zhang] Ai‐lu’s Case Records 张爱庐) 2. 敖氏伤寒金镜 Ao’s Golden Mirror Records for Cold 录 Áo Shì Shāng Hán Jīn Jìng Lù Damage Du Qing‐bi 杜清碧 1341 3. 百草镜 Băi Căo Jìng Mirror of the Hundred Herbs Zhao Xue‐kai 赵学楷 Qing 4. 白喉条辨 Bái Hóu Tiáo Biàn Systematic Analysis of Diphtheria Chen Bao‐shan 陈宝善 1887 5. 百一选方 Băi Yī Xuăn Fāng Selected Formulas Wang Qiu 王璆 1196 Wan Quan 万全 (Style: 6. 保命歌诀 Băo Mìng Gē Jué Verses for Survival Wan Mi 万密) 7. 保婴撮要 Băo Yīng Cuō Yào Essentials of Infant Care Xue Kai 薛凯 1555 Ge Hong 葛洪 (Styles: Ge Zhi‐chuan 葛稚川, 8. 抱朴子内外篇 Bào Pŭ Zĭ Nèi Wài Piān The Inner and Outer Chapters of Bao Pu‐zi Bao Pu‐zi 抱朴子) Wen Ren Qi Nian 闻人耆 9. 备急灸法 Bèi Jí Jiŭ Fă Moxibustion Techniques for Emergency 年 1226 Important Formulas Worth a Thousand 7th century; 652 10. 备急千金要方 Bèi Jí Qiān Jīn Yào Fāng Gold Pieces for Emergency Sun Si‐miao 孙思邈 (Tang) Wang Ang 汪昂 (Style: 11. 本草备要 Bĕn Căo Bèi Yào Essentials of Materia Medica Wang Ren‐an) 1664 (Qing) Zhang Bing‐cheng 张秉 12.