The Quest for High-Quality Video Game Text Corpora
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Planning for Non-Player Characters by Learning from Demonstration
University of Pennsylvania ScholarlyCommons Publicly Accessible Penn Dissertations 2018 Planning For Non-Player Characters By Learning From Demonstration John Drake University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/edissertations Part of the Computer Sciences Commons Recommended Citation Drake, John, "Planning For Non-Player Characters By Learning From Demonstration" (2018). Publicly Accessible Penn Dissertations. 2756. https://repository.upenn.edu/edissertations/2756 This paper is posted at ScholarlyCommons. https://repository.upenn.edu/edissertations/2756 For more information, please contact [email protected]. Planning For Non-Player Characters By Learning From Demonstration Abstract In video games, state of the art non-player character (NPC) behavior generation typically depends on hard-coding NPC actions. In many game situations however, it is hard to foresee how an NPC should behave to appear intelligent or to accommodate human preferences for NPC behavior. We advocate the creation of a more flexible method ot allow players (and developers) to train NPCs to execute novel behaviors which are not hard-coded. In particular, we investigate search-based planning approaches using demonstration to guide the search through high-dimensional spaces that represent the full state of the game. To this end, we developed the Training Graph heuristic, an extension of the Experience Graph heuristic, that guides a search smoothly and effectively even when a demonstration is unreachable in the search space, and ensures that more of the demonstrations are utilized to better train the NPC's behavior. To deal with variance in the initial conditions of such planning problems, we have developed heuristics in the Multi-Heuristic A* framework to adapt demonstration trace data to new problems. -

Player-Character Is What You Are in the Dark the Phenomenology of Immersion in Dungeons & Dragons
Player-Character Is What You Are in the Dark The Phenomenology of Immersion in Dungeons & Dragons William J. White The idea of role-playing makes some people nervous – even some people who play role-playing games (RPGs). Yeah, sure, we pretend to be wizards and talk in funny voices, such players often say. So what? It’s just for fun. It’s not like it means anything. These players tend to find talk about role-playing games being “art” to be pretentious nonsense, and the idea that there could be philosophical value in a game like Dungeons & Dragons strikes them as preposterous on its face. “RPGs as instruction on ethics or metaphysics?” writes one such player in an online forum for discussing role-playing games. “Utter intellectualoid [sic] bullshit … [from those] who want to imagine they’re great thinkers thinking great thoughts while they play RPGs because they’d otherwise feel ashamed about pretending to be an elf.”1 By the same token, people who don’t play RPGs are often quite mystified about what could possibly be going on in a game of Dungeons & Dragons: There’s no board? How do you win? No winners? Then why do you play?2 Making sense of D&D as Dungeons & Dragons and Philosophy: Read and Gain Advantage Copyright © 2014. John Wiley & Sons, Incorporated. All rights reserved. & Sons, Incorporated. © 2014. John Wiley Copyright on All Wisdom Checks, First Edition. Edited by Christopher Robichaud. © 2014 John Wiley & Sons, Inc. Published 2014 by John Wiley & Sons, Inc. 82 Dungeons and Dragons and Philosophy : Read and Gain Advantage on All Wisdom Checks, edited by Christopher Robichaud, John Wiley & Sons, Incorporated, 2014. -

How to Buy DVD PC Games : 6 Ribu/DVD Nama
www.GamePCmurah.tk How To Buy DVD PC Games : 6 ribu/DVD Nama. DVD Genre Type Daftar Game Baru di urutkan berdasarkan tanggal masuk daftar ke list ini Assassins Creed : Brotherhood 2 Action Setup Battle Los Angeles 1 FPS Setup Call of Cthulhu: Dark Corners of the Earth 1 Adventure Setup Call Of Duty American Rush 2 1 FPS Setup Call Of Duty Special Edition 1 FPS Setup Car and Bike Racing Compilation 1 Racing Simulation Setup Cars Mater-National Championship 1 Racing Simulation Setup Cars Toon: Mater's Tall Tales 1 Racing Simulation Setup Cars: Radiator Springs Adventure 1 Racing Simulation Setup Casebook Episode 1: Kidnapped 1 Adventure Setup Casebook Episode 3: Snake in the Grass 1 Adventure Setup Crysis: Maximum Edition 5 FPS Setup Dragon Age II: Signature Edition 2 RPG Setup Edna & Harvey: The Breakout 1 Adventure Setup Football Manager 2011 versi 11.3.0 1 Soccer Strategy Setup Heroes of Might and Magic IV with Complete Expansion 1 RPG Setup Hotel Giant 1 Simulation Setup Metal Slug Anthology 1 Adventure Setup Microsoft Flight Simulator 2004: A Century of Flight 1 Flight Simulation Setup Night at the Museum: Battle of the Smithsonian 1 Action Setup Naruto Ultimate Battles Collection 1 Compilation Setup Pac-Man World 3 1 Adventure Setup Patrician IV Rise of a Dynasty (Ekspansion) 1 Real Time Strategy Setup Ragnarok Offline: Canopus 1 RPG Setup Serious Sam HD The Second Encounter Fusion (Ekspansion) 1 FPS Setup Sexy Beach 3 1 Eroge Setup Sid Meier's Railroads! 1 Simulation Setup SiN Episode 1: Emergence 1 FPS Setup Slingo Quest 1 Puzzle -

Children Entering Fourth Grade ~
New Canaan Public Schools New Canaan, Connecticut ~ Summer Reading 2018 ~ Children Entering Fourth Grade ~ 2018 Newbery Medal Winner: Hello Universe By Erin Entrada Kelly Websites for more ideas: http://booksforkidsblog.blogspot.com (A retired librarian’s excellent children’s book blog) https://www.literacyworldwide.org/docs/default-source/reading-lists/childrens- choices/childrens-choices-reading-list-2018.pdf Children’s Choice Awards https://www.bankstreet.edu/center-childrens-literature/childrens-book-committee/best- books-year/2018-edition/ Bank Street College Book Recommendations (All suggested titles are for reading aloud and/or reading independently.) Revised by Joanne Shulman, Language Arts Coordinator joanne,[email protected] New and Noteworthy (Reviews quoted from amazon.com) Word of Mouse by James Patterson “…a long tradition of clever mice who accomplish great things.” Fish in a Tree by Lynda Mallaly Hunt “Fans of R.J. Palacio’s Wonder will appreciate this feel-good story of friendship and unconventional smarts.”—Kirkus Reviews Secret Sisters of the Salty Seas by Lynne Rae Perkins “Perkins’ charming black-and-white illustrations are matched by gentle, evocative language that sparkles like summer sunlight on the sea…The novel’s themes of family, friendship, growing up and trying new things are a perfect fit for Perkins’ middle grade audience.”—Book Page Dash (Dogs of World War II) by Kirby Larson “Historical fiction at its best.”—School Library Journal The Penderwicks at Last by Jean Birdsall “The finale you’ve all been -

In- and Out-Of-Character
Florida State University Libraries 2016 In- and Out-of-Character: The Digital Literacy Practices and Emergent Information Worlds of Active Role-Players in a New Massively Multiplayer Online Role-Playing Game Jonathan Michael Hollister Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] FLORIDA STATE UNIVERSITY COLLEGE OF COMMUNICATION & INFORMATION IN- AND OUT-OF-CHARACTER: THE DIGITAL LITERACY PRACTICES AND EMERGENT INFORMATION WORLDS OF ACTIVE ROLE-PLAYERS IN A NEW MASSIVELY MULTIPLAYER ONLINE ROLE-PLAYING GAME By JONATHAN M. HOLLISTER A Dissertation submitted to the School of Information in partial fulfillment of the requirements for the degree of Doctor of Philosophy 2016 Jonathan M. Hollister defended this dissertation on March 28, 2016. The members of the supervisory committee were: Don Latham Professor Directing Dissertation Vanessa Dennen University Representative Gary Burnett Committee Member Shuyuan Mary Ho Committee Member The Graduate School has verified and approved the above-named committee members, and certifies that the dissertation has been approved in accordance with university requirements. ii For Grandpa Robert and Grandma Aggie. iii ACKNOWLEDGMENTS Thank you to my committee, for their infinite wisdom, sense of humor, and patience. Don has my eternal gratitude for being the best dissertation committee chair, mentor, and co- author out there—thank you for being my friend, too. Thanks to Shuyuan and Vanessa for their moral support and encouragement. I could not have asked for a better group of scholars (and people) to be on my committee. Thanks to the other members of 3 J’s and a G, Julia and Gary, for many great discussions about theory over many delectable beers. -

UPDATE NEW GAME !!! the Incredible Adventures of Van Helsing + Update 1.1.08 Jack Keane 2: the Fire Within Legends of Dawn Pro E
UPDATE NEW GAME !!! The Incredible Adventures of Van Helsing + Update 1.1.08 Jack Keane 2: The Fire Within Legends of Dawn Pro Evolution Soccer 2013 Patch PESEdit.com 4.1 Endless Space: Disharmony + Update v1.1.1 The Curse of Nordic Cove Magic The Gathering Duels of the Planeswalkers 2014 Leisure Suit Larry: Reloaded Company of Heroes 2 + Update v3.0.0.9704 Incl DLC Thunder Wolves + Update 1 Ride to Hell: Retribution Aeon Command The Sims 3: Island Paradise Deadpool Machines at War 3 Stealth Bastard GRID 2 + Update v1.0.82.8704 Pinball FX2 + Update Build 210613 incl DLC Call of Juarez: Gunslinger + Update v1.03 Worms Revolution + Update 7 incl. Customization Pack DLC Dungeons & Dragons: Chronicles of Mystara Magrunner Dark Pulse MotoGP 2013 The First Templar: Steam Special Edition God Mode + Update 2 DayZ Standalone Pre Alpha Dracula 4: The Shadow of the Dragon Jagged Alliance Collectors Bundle Police Force 2 Shadows on the Vatican: Act 1 -Greed SimCity 2013 + Update 1.5 Hairy Tales Private Infiltrator Rooks Keep Teddy Floppy Ear Kayaking Chompy Chomp Chomp Axe And Fate Rebirth Wyv and Keep Pro Evolution Soccer 2013 Patch PESEdit.com 4.0 Remember Me + Update v1.0.2 Grand Ages: Rome - Gold Edition Don't Starve + Update June 11th Mass Effect 3: Ultimate Collectors Edition APOX Derrick the Deathfin XCOM: Enemy Unknown + Update 4 Hearts of Iron III Collection Serious Sam: Classic The First Encounter Castle Dracula Farm Machines Championships 2013 Paranormal Metro: Last Light + Update 4 Anomaly 2 + Update 1 and 2 Trine 2: Complete Story ZDSimulator -

Diablo 1 Windows 10 Download Diablo
diablo 1 windows 10 download Diablo. Diablo is one of the pioneer and classic game of the action role-playing genre. Play this classic game once again, download Diablo on your computer. 1 2 3 4 5 6 7 8 9 10. Role-playing games (RPG) for computers have always had a very important place within the video game market. In the first PC era, these games were, in their vast majority, games that showed everything from a first-person perspective. But all this changed with the arrival of a new batch of RPG games, led by Diablo , action role-playing games . Play one of the most important classic role-playing games once again. The original Diablo game, which was launched in 1997, set a milestone in the video gaming world and specially role-playing games, and was the start of a very important game saga. One of the changes that could be noticed with greater ease in Diablo was the graphics, due to the fact that it used an isometric view , as well as this, the game was also characterized by the fact that it didn't set so much importance on the story, but focused more on the destruction of every single enemy the player encountered. The player was offered three different characters to choose from, each with its own features and equipment: the warrior (powerful in hand-to-hand combat), the rogue (that was especially gifted in the use of bows and crossbows) and the magician (imbued with arcane power to cast spells). Once the player had chosen his/her character and named it, he/she had to decide which features he/she would improve on each level and set out in search of adventure. -

Modelling Player Understanding of Non-Player Character Paths
Proceedings of the Fourteenth Artificial Intelligence and Interactive Digital Entertainment Conference (AIIDE 2018) Modelling Player Understanding of Non-Player Character Paths Mengxi Xoey Zhang, Clark Verbrugge McGill University Montreal,´ Canada [email protected], [email protected] Abstract enable an exploration tool to better understand and experi- ment with what information becomes available to a player, Modelling a player’s understanding of NPC movements can given specific NPC routes, level geometry, and incomplete be useful for adapting gameplay to different play styles. For observation. We thus define a baseline system that allows stealth games, what a player knows or suspects of enemy movements is important to how they will navigate towards for exhaustive modelling of possible NPC positions, con- a solution. In this work, we build a uniform abstraction of strained by the gap-time and filtered by knowledge of level potential player path knowledge based on their partial obser- geometry. Players may also attribute movement character- vations. We use this representation to compute different path istics or make assumptions about NPC behaviours as well. estimates according to different player expectations. We aug- Our design naturally incorporates different constraint mod- ment our work with a user study that validates what kinds of els that reduce pathing possibilities to better represent player NPC behaviour a player may expect, and develop a tool that expectation. can build and explore appropriate (expected) paths. We find Algorithmic and representational design is supported by that players prefer short simple paths over long or complex a non-trivial experimentation and visualization tool built paths with looping or backtracking behaviour. -
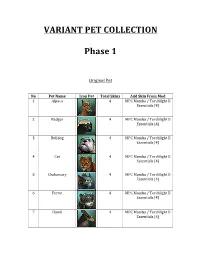
VARIANT PET COLLECTION Phase 1
VARIANT PET COLLECTION Phase 1 Original Pet No Pet Name Icon Pet Total Skins Add Skin From Mod 1 Alpaca 4 MPC Mamba / Torchlight II Essentials [4] 2 Badger 4 MPC Mamba / Torchlight II Essentials [4] 3 Bulldog 4 MPC Mamba / Torchlight II Essentials [4] 4 Cat 4 MPC Mamba / Torchlight II Essentials [4] 5 Chakawary 4 MPC Mamba / Torchlight II Essentials [4] 6 Ferret 4 MPC Mamba / Torchlight II Essentials [4] 7 Hawk 4 MPC Mamba / Torchlight II Essentials [4] 8 Headcrap 6 MPC Mamba / Torchlight II Essentials [6] 9 Owl 11 MPC Mamba / Torchlight II Essentials [11] 10 Panda 5 MPC Mamba / Torchlight II Essentials [4] EV Modpack [1] 11 Panther 11 MPC Mamba / Torchlight II Essentials [8] Variant Class [3] 12 Papillon 4 MPC Mamba / Torchlight II Essentials [4] 13 Stag 4 MPC Mamba / Torchlight II Essentials [4] 14 Wolf 7 MPC Mamba / Torchlight II Essentials [4] Dire Wolf SynergiesMOD Pet [1] Wolf Pack [2] Add Pets No Pet Name Icon Pet Total Skins Add Mod From 1 Alchemic Construct 2 MPC Mamba / Torchlight II Essentials [2] 2 Ancient Automaton 2 MPC Mamba [2] 3 Ancient Skeleton 6 MPC Mamba / Torchlight II Essentials [6] 4 Armadax 3 MPC Mamba [1] Xev Pet [1] Phan Big Pet [1] 5 Armored 1 Phan Big Pet [1] Strumbeorn 6 Armored Warbeast 1 Phan Big Pet [1] [*] 7 Artificer 1 Boss Pet [1] 8 Avatar 1 MPC Mamba / Torchlight II Essentials [1] 9 Baneling 1 MPC Mamba / Torchlight II Essentials [1] By: Gao 10 Banshee 3 Anarch Pet / Torchlight II Essentials [3] 11 Basilisk 4 MPC Mamba / Torchlight II Essentials [4] 12 Bat 4 MPC Mamba [4] 13 Bear 5 MPC Mamba [5] By: -

Toward a Theory of the Dark Fantastic: the Role of Racial Difference in Young Adult Speculative Fiction and Media
Journal of Language and Literacy Education Vol. 14 Issue 1—Spring 2018 Toward a Theory of the Dark Fantastic: The Role of Racial Difference in Young Adult Speculative Fiction and Media Ebony Elizabeth Thomas Abstract: Humans read and listen to stories not only to be informed but also as a way to enter worlds that are not like our own. Stories provide mirrors, windows, and doors into other existences, both real and imagined. A sense of the infinite possibilities inherent in fairy tales, fantasy, science fiction, comics, and graphic novels draws children, teens, and adults from all backgrounds to speculative fiction – also known as the fantastic. However, when people of color seek passageways into &the fantastic, we often discover that the doors are barred. Even the very act of dreaming of worlds-that-never-were can be challenging when the known world does not provide many liberatory spaces. The dark fantastic cycle posits that the presence of Black characters in mainstream speculative fiction creates a dilemma. The way that this dilemma is most often resolved is by enacting violence against the character, who then haunts the narrative. This is what readers of the fantastic expect, for it mirrors the spectacle of symbolic violence against the Dark Other in our own world. Moving through spectacle, hesitation, violence, and haunting, the dark fantastic cycle is only interrupted through emancipation – transforming objectified Dark Others into agentive Dark Ones. Yet the success of new narratives fromBlack Panther in the Marvel Cinematic universe, the recent Hugo Awards won by N.K. Jemisin and Nnedi Okorafor, and the blossoming of Afrofuturistic and Black fantastic tales prove that all people need new mythologies – new “stories about stories.” In addition to amplifying diverse fantasy, liberating the rest of the fantastic from its fear and loathing of darkness and Dark Others is essential. -

Dark Romanticism Notes (1840-1865)
Dark Romanticism Notes (1840-1865) Authors Associated with Dark Romanticism (172) Characteristics of Dark Romanticism Philosophy (173) Beliefs of the Dark Romantics: B elieve that perfection was not ingrained in humanity. Some Mr. Randon Notes (PPT) Believe that individuals were prone to sin and self-destruction, not as inherently possessing divinity and wisdom. Edgar Allan Poe “Factoids” (Documentary) Frequently shows individuals failing in their attempts to make changes for the better. Romantics and Dark Romantics both believe that nature is a deeply spiritual force, however, Dark Romanticism views nature as sinister and evil. When nature does reveal truth to man, its revelations are pessemistic and soul-crushing. 1 An Occurrence at Owl Creek Bridge Film Guide Think about the director’s decisions as he adapts Ambrose Bierce’s short story to film. Analysis: What does it mean for the Detail How is the detail distorted? character? Sound 2 Berenice (Abridged) By Edgar Allen Poe (1835) Dicebant mihi sodales, si sepulchrum amicae visitarem, curas meas aliquantulum forelevatas. - Ebn Zaiat MISERY is manifold. The wretchedness of earth is multiform. Overreaching the wide horizon as the rainbow, its hues are as various as the hues of that arch - as distinct too, yet as intimately blended. Overreaching the wide horizon as the rainbow! How is it that from beauty I have derived a type of unloveliness? - from the covenant of peace, a simile of sorrow? But as, in ethics, evil is a consequence of good, so, in fact, out of joy is sorrow born. Either the memory of past bliss is the anguish of to-day, or the agonies which are, have their origin in the ecstasies which might have been. -

FATE User Guide
TORCHLIGHT User Guide V 1.0 Ember! Merchants prize it for trade. Enchanters distill it for raw magical energy. But a shadowy few crave it for the lure of unsurpassed power and potential immortality. For years the town of Torchlight thrived on these rich deposits of crystallized magic, at least until something else was unearthed in Orden Mines. Now miners fear that recently recovered relics and unusual monsters indicate something or someone tunneled beneath the bedrock long before Torchlight existed. Is it true? Is ember a commodity? Or a curse? Table of Contents Important Stuff to Know Before Reading Further Getting Started System Requirements Installing TORCHLIGHT Installing Direct X Settings Part I: The Tutorial Begin the Adventure Choose Your Character Explore Torchlight Village Select a Quest Exploring with AutoMap Exploring the Mine and Other Underground Places Combat Melee or Close Combat Ranged Combat Artifacts, Gold and Items Dealing with Defeat Part II: Beyond the Tutorial (The Details) The TORCHLIGHT Perspective and Game Menus Take in the Details The Game Interface Using Your Pet Interface during Game Play How to Customize Skills & Items on the Game Interface How to Assign or Replace a Spell in a Spell Slot How to use an Inventory Item Talk Around Torchlight Town Transactions Your Faithful Companion Pet Levels and Attributes How to Fish Stash and Shared Stash Inventories Character Development How to Gain Experience Points and Levels Character Classes and Starting Attributes The Four Attributes of Adventure Strength Dexterity