Comparative Study of Imputation Algorithms Applied To
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

El Espacio Periurbano En Corvera: Los Campos Y Las Vegas
EL ESPACIO PERIURBANO EN CORVERA Año 2020 ÍNDICE INTRODUCCIÓN. OBJETIVOS Y JUSTIFICACIÓN DEL TRABAJO ....................... 1 ¿POR QUÉ PERIURBANO? ............................................................................................ 3 EL BASTIDOR NATURAL Y EL ESTRATO RURAL DEL PAISAJE COMO CONDICIONANTES DEL DESARROLLO URBANO ................................................. 7 LOS CAMPOS Y LAS VEGAS: DOS MODELOS DE DESARROLLO DIFERENCIADOS ........................................................................................................ 13 El estallido de la segunda mitad del siglo XX: de las promociones de casas baratas al barrio bloque ............................................................................................................... 15 Luces y sombras en el cambio de siglo: de las conquistas democráticas a las contradicciones de la burbuja inmobiliaria ................................................................. 19 El desarrollo reciente: la urbanización ordenada y la proliferación de nueva vivienda y equipamientos como forma de dinamización .......................................................... 24 LA SITUACIÓN ACTUAL: LOS PROBLEMAS URBANOS Y LA BÚSQUEDA DE LA SOSTENIBILIDAD ................................................................................................. 29 CONCLUSIONES ........................................................................................................... 34 BIBLIOGRAFÍA Y FUENTES ..................................................................................... -

La Jira Al Embalse De Trasona
Enrique Antuña Gancedo LA JIRA AL EMBALSE DE TRASONA UNA BREVE HISTORIA DE LA FIESTA DE ENSIDESA Enrique Antuña Gancedo Enrique • LA JIRA AL EMBALSE DE TRASONA DE AL EMBALSE LA JIRA José Ángel Gayol Exercicios d’asturianu (Notes, pensamientos, llectures) LA JIRA AL EMBALSE DE TRASONA Enrique Antuña Gancedo LA JIRA AL EMBALSE DE TRASONA UNA BREVE HISTORIA DE LA FIESTA DE ENSIDESA LA JIRA: UNA BREVE HISTORIA DE NUESTRA VIDA a Jira, Fiesta Declarada de Interés Turístico del Principado de Asturias, es una de las referencias del calendario festivo L asturiano. Y esa idea de «referencia», más que como frase hecha o como forma hiperbólica de destacar el evento, se justifica porque, desde 1958, la Jira abre de manera oficiosa (se celebra en mayo) el ciclo de grandes romerías que se desarrollan en Asturies en Primavera/Verano y en el que se distinguen multitudinarios epígonos como «El Carmín» de Siero, «El Carmen» de Cangas, «San Timoteo» en L. l.uarca, «El Xiringüelu» de Pravia o las fiestas de «San Roque» de Llanes. La Jira ha sido y es un encuentro festivo de especial relevancia: mueve a miles de ciudadanos, dinamiza el comercio local, positiva la imagen del territorio, visibilizando las potencialidades del mismo desde todos los puntos de vista. La Jira, por lo tanto, contiene los ingredientes sustanciales de toda gran fiesta… Consecuentemente, no se diferenciaría de cualquier otra convocatoria festiva si no fue- ra porque se desarrolla en un entorno único, singular (el área del Pantano de Trasona/Tresona) y por una historia, una génesis, unos -

Ensidesa Y La Jira Al Embalse De Trasona (Asturias, 1958-1975)
Gancedo DEPORTE Y FIESTA EN EL ENSAYO DE UN OCIO TOTALITARIO: ENSIDESA Y LA JIRA AL EMBALSE DE TRASONA (ASTURIAS, 1958-1975) Enrique Antuña Gancedo1 Resumen: Los regímenes políticos dictatoriales, pese a no ser los únicos que han empleado la práctica deportiva como forma de control social, han dado lugar a las estrategias más vistosas en este sentido y por ello han recibido una atención especial por parte de los investigadores. Este trabajo analiza un caso interesante por lo avanzado de su cronología: el experimento social desarrollado en la comarca asturiana de Avilés, España, por la empresa siderúrgica estatal ENSIDESA, durante la dictadura del general Francisco Franco. En este contexto, y en concreto en la fiesta conocida como Jira al Embalse de Trasona, el deporte forma parte de lo que podríamos entender como un ensayo de ocio totalitario. Palabras clave: ocio totalitario; deporte; fiesta; franquismo; ENSIDESA. Esporte e Festa no Ensaio de um Lazer Totalitário: a ENSIDESA e a Excursão para a Represa de Trasona (Asturias, Espanha, 1958-1975) Resumo: Os regimes políticos ditatoriais, embora não os únicos que tenham utilizado o esporte como forma de controle social, produziram as estratégias mais marcantes neste sentido e, portanto, têm recebido atenção especial dos pesquisadores. Este artigo analisa um caso interessante por sua cronologia avançada: a experiência social desenvolvida na comarca asturiana de Avilés, Espanha, pela empresa siderúrgica estatal ENSIDESA, durante a ditadura do general Francisco Franco. Nesse contexto, e em particular na festa conhecida como Excursão para a Represa de Trasona, o esporte é parte do que poderíamos entender como um ensaio de lazer totalitário. -

Asturias Siglo Xxi
ASTURIAS SIGLO XXI CORVERA DE ASTURIAS La industria y la ciudad Fermín RODRÍGUEZ Rafael MENÉNDEZ Corvera ha afrontado, con iniciativa, numerosos obstáculos para afrontar su futuro. Su localización sobre el borde industrial de la ciudad, la herencia urbana y la crisis industrial no han apoyado. Sin embargo ha desarrollado, antes que otros, nuevas funciones y actividades que van a marcar su futuro. Corvera forma el límite sur de la ciudad de Avilés y su polo de industria pesada. Del impacto de la instalación siderúrgica queda el borde norte del concejo ocupado por las factorías e instalaciones industriales y parte del poblamiento, en La Marzaniella (700 habitantes) y los núcleos que componen la parroquia de Trasona, más de 2.000 habitantes, en torno al embalse siderúrgico. Las urbanizaciones y equipamientos recientes en esta zona (centro comercial, campo de golf…) permiten sospechar un cambio en la tendencia declinante en los próximos años y una extensión en baja densidad del ámbito urbano de Avilés, caracterizado hoy por su heterogeneidad, discontinuidad, estancamiento y desarticulación. Extendido por territorio de cinco concejos, no ha conseguido aún consolidar su articulación metropolitana, dominada por los centros urbanos de Gijón y Oviedo.. A pesar de una intensa actividad de búsqueda de nuevas alternativas, Corvera ha continuado perdiendo población. El concejo ha remodelado sus barriadas de borde, ha desarrollado suelo urbano, nuevos equipamientos, ha impulsado un mayor aprovechamiento deportivo y de ocio del embalse de Trasona, ha desarrollado áreas industriales y ha estado a la expectativa del crecimiento del área urbana de Avilés. Sin embargo el estancamiento de la ciudad principal ha obstaculizado las posibilidades de crecimiento del concejo, que se ha visto relegado al estancamiento demográfico, por debajo de los 16.000 habitantes. -

MUNICIPIO: CORVERA Nº Habitantes: 15.795 Año 2004 3
MUNICIPIO: CORVERA Nº Habitantes: 15.795 Año 2004 3.- ABASTECIMIENTO A CANCIENES Titular: AYUNTAMIENTO DE CORVERA Gestor: SERVICIO DE AGUAS Nº determinaciones cloro Población (Nomenclator 2003-SADEI) Tratamiento Nº Análisis residual libre Nº P.M. Entidad singular% Depósito Captación Controlada Controlada De derecho Abastecida Controlada ETAP Cl Tot A NA Tot C H A E.S. P.M. P.M. 9 Cancienes (Parte) 1.060 1.000 1.000 1.015 6,4 Campo La Vega M. Fuentecaliente X 5 5 0 89 73 5 11 Campo La Vega 15 15 15 M. La Pelucona 10 La Sota 61 61 61 327 2,1 Campañones M. Fuentecaliente X 5507610 El Llano 50 50 50 M. La Pelucona Campañones 83 83 83 La Cruzada 11 11 11 Calabaza 16 16 16 Alvares 22 22 22 Rodiles 29 29 29 Agüera 46 46 46 El Monte 9 9 9 El Ponton (Solis) 60 60 0 Monte Grande Santa Marina 8 8 0 Sama De Arriba 11 11 0 Total 1.481 1.421 1.342 1.342 8 10 10 0 96 79 6 11 (1) Infraestructura deficiente (2) Tratamiento inadecuado (3) Mantenimiento incorrecto (4) Limpieza insuficiente (5) No operativo Municipio: Corvera Area III 3 - Abastecimiento a Cancienes M M Punto de Cloración. Depósito muestreo Manantial Manantial Campo la Vega 9 - Cancienes (parte) La Pelucona M. Aguilero 550m3 -1979 Punto sin y otra control Depósito Depósito Depósito de Cloración. Depósito Punto sin bombeo control Campañones II Campañones I 40m3 -1997 Montegrande 170m3 -1976 10m3 -1979 170m3 -1974 Punto de muestreo 10 - La Sota y otras SímbolosSímbolos empleados empleados A R M E S Estación de Agua sin tratamiento Tratamiento tratamiento de Agua tratada Procedencia E.T.A.P. -
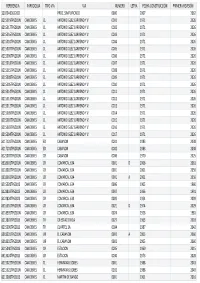
Censo De Edificios Publicar
REFERENCIA PARROQUIA TIPO VIA VIA NUMERO LETRA FECHA CONSTRUCCIÓN PRIMERA REVISIÓN 33020A00612021 PROC. SIMPLIFICADO 0000 2007 2062 8215019TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0001 1971 2026 8215017TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0002 1971 2026 8215016TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0003 1971 2026 8215010TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0004 1971 2026 8215007TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0005 1971 2026 8215006TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0006 1971 2026 8215018TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0007 1971 2026 8215015TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0008 1971 2026 8215008TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0009 1971 2026 8215005TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0010 1971 2026 8215014TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0011 1971 2026 8215013TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0012 1971 2026 8215012TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0013 1971 2026 8215009TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0014 1971 2026 8215002TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0015 1971 2026 8215003TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0016 1971 2026 8215004TP6281N CANCIENES CL ANTONIO GLEZ CARRENO Y V. 0017 1971 2026 8117101TP6281N CANCIENES ED CABANON 0001 1983 2038 8117101TP6281N CANCIENES ED CABANON 0002 1983 2038 8121007TP6281N CANCIENES CR CABANON 0006 1970 2025 8318001TP6281N CANCIENES CR COMARCAL 634 0001 D 2006 2061 8318002TP6281N CANCIENES CR COMARCAL 634 0001 -

Programa Corvera 19
FIESTAS SAN JUSTO Y PASTOR I SOLÍS 2019 JUEVES 29 DE AGOSTO 17:03 Acondicionamiento interior y exterior del vehículo comisional, chino prepara el Caramba y chango prepara el desengrasante. VIERNES 30 DE AGOSTO 07:43 ¡Arrancamos la fiesta! Todo el que quiera colaborar bienvenido será en la cancha para subir aperos. 22:10 V FARTURA DE CHULETONES. 23:30 Tras muchos años de litigios por fin llega GRUPO IDEAS a Solís. 03:35 D.J. hasta altas horas. SÁBADO 31 DE AGOSTO 13:00 Sesión vermut. 17:00 Gran tobogán gigante acuático de 60 metros, para grandes y pequeños. 00:02 Como nunca defraudan vuelven WAYKAS FAMILY. En el descanso de la orquesta procederemos a realizar la mítica carrera internacional de “pantalones gachos”, para todos los públicos. DOMINGO 01 DE SEPTIEMBRE 11:30 Vestidos como manda la tradición, procesión desde la iglesia parroquial hasta la Ermita de los Santos San Justo y Pastor. 12:30 Misa de campo. 13:30 Actuación de la banda de gaitas de Corvera y Subasta del pan de escanda. 14:00 XVIII GRAN CORDERADA. 17:00 Actuación de la charanga “EL FELECHU”. 18:00 Animación para pequeños y mayores a cargo de TRES COLORES. 19:30 Gran romería a cargo del GRUPO LÍMITE. LUNES 02 DE SEPTIEMBRE 13:30 Sesión vermut, precios populares. 17:03 Acondicionamiento de sillas y mesas para el bollo. 20:30 Entrega del bollo y la botella de vino amenizado por gaiteros. 23:40 Reventamos la fiesta, vuelven GRUPO VIVIANS. RESERVA DE COSTILLAS Y MESA PARA EL DIA DEL BOLLO HASTA EL DOMINGO POR LA NOCHE. -

El Palacio De Los Rodríguez De León En Trasona (Corvera De Asturias)
ALFOZ. Revista del Centro de Estudios del Alfoz de Gauzón. El palacio de los Rodríguez de León en Trasona (Corvera de Asturias) Jesús Antonio González Calle Doctor en Historia RESUMEN: La muestra más representativa de arquitectura civil en el concejo de Corvera de Asturias durante la época del Antiguo Régimen es el palacio de los Rodríguez de León, linaje de origen leonés que hizo fortuna en el siglo XV a través de ocupaciones bur- guesas (escribanías públicas, comercio) y eclesiásticas (en el cabildo catedralicio de San Salvador de Oviedo). El palacio debió ser un elemento clave en la propia transmutación del linaje, que de su condición burguesa da el salto a la nobleza hidalga. El edificio pre- senta tres fases básicas. Así, en primer lugar, la construcción fundacional, impulsada por Rodrigo Alonso de León el mozo a comienzos del siglo XVI, mantiene un gusto aún muy medieval y se articula en torno a una primera torre. Dejando aparte algunas reformas menores, a comienzos del siglo XVII Pedro Rodríguez de León promueve una importante ampliación que configura la fachada principal, flanqueada por la torre antigua y por otra nueva; también debió levantarse la monumental escalera interior. Sin duda, el palacio de Trasona es un temprano seguidor de un modelo palacial barroco inspirado en la universidad de Oviedo y el palacio de Casa Valdés, en Gijón, si bien su forma definitiva no llegará hasta una segunda ampliación no muy posterior, tal vez de mediados del siglo XVII. Una vez que se extingue la línea masculina de los Rodríguez de León, el palacio alternará fases de olvido y recuperación. -

A Hybrid Wavelet Kernel SVM-Based Method Using Artificial Bee Colony
Journal of Computational and Applied Mathematics 309 (2017) 587–602 Contents lists available at ScienceDirect Journal of Computational and Applied Mathematics journal homepage: www.elsevier.com/locate/cam A hybrid wavelet kernel SVM-based method using artificial bee colony algorithm for predicting the cyanotoxin content from experimental cyanobacteria concentrations in the Trasona reservoir (Northern Spain) P.J. García Nieto a,∗, E. García-Gonzalo a, J.R. Alonso Fernández b, C. Díaz Muñiz b a Department of Mathematics, Faculty of Sciences, University of Oviedo, 33007 Oviedo, Spain b Cantabrian Basin Authority, Spanish Ministry of Agriculture, Food and Environment, 33071 Oviedo, Spain article info a b s t r a c t Article history: Cyanotoxins, a kind of poisonous substances produced by cyanobacteria, are responsible Received 21 October 2015 for health risks in surface waters used for drinking or for recreation. Additionally, Received in revised form 18 January 2016 cyanobacteria blooms are often called blue–green algae. A harmful algal bloom (HAB) is an algal bloom that causes negative impacts to other organisms via production of Keywords: natural toxins such as cyanotoxins. Consequently, anticipating its presence is a matter Support vector machines (SVMs) of importance to prevent risks. This study presents a novel hybrid algorithm, support Wavelet kernel vector machines with Mexican hat wavelet kernel function (wavelet SVMs) in combination Artificial bee colony (ABC) Microcystis aeruginosa with the artificial bee colony (ABC) technique, for predicting the cyanotoxin content Woronichinia naegeliana from cyanobacterial concentrations determined experimentally in the Trasona reservoir Regression analysis (recreational reservoir used as a high performance training center of canoeing in the Northern Spain). -
Plazas De Estacionamiento Para Personas Con Minusvalia
PLAZAS DE ESTACIONAMIENTO PARA PERSONAS CON MINUSVALIA TRASONA – CORVERA DE ASTURIAS LUGAR NUM.de PLAZAS ESCUELA DE FAVILA 1 CENTRO DE SALUD 1 MAR TIRRENO 1 MAR CANTÁBRICO, 7 1 APEADERO FEVE GUDIN 2 GUDÍN, 5 1 LA MARZANIELLA, 41 1 AREA RECREATIVA DE GAVITOS 2 HOTEL KRIS 4 HOTEL ZEN BALAGARES 4 C.C. PARQUE ASTUR - Puerta OVIEDO 16 C.C. PARQUE ASTUR - Puerta GIJON 16 C.C. PARQUE ASTUR - Puerta AVILES 8 C.C. PARQUE ASTUR - Puerta TRASERA 2 C.C. PARQUEASTUR - BRICO DEPOT 5 CENTRO ALTO RENDIMIENTO 3 TOTAL PLAZAS 68 PLAZAS DE ESTACIONAMIENTO PARA PERSONAS CON MINUSVALIA LOS CAMPOS – CORVERA DE ASTURIAS LUGAR NUM.de PLAZAS CENTRO SOCIAL 2 C/HORACIO FERNANDEZ. INGUANZO, 3 1 C/HORACIO FERNANDEZ. INGUANZO, 3 B 1 C/HORACIO FERNANDEZ. INGUANZO, 13 1 C/HORACIO FERNANDEZ. INGUANZO, 21 1 C/HORACIO FERNANDEZ. INGUANZO, 26 1 EDIFICIO HORANSO, 1 1 BARRIO SINDULFO, 20 1 POLIDEPORTIVO LOS CAMPOS 2 SUPERMERCADO ALIMERKA LOS CAMPOS 1 INSTITUTO ED. SECUNDARIA LOS CAMPOS 1 EDIFICIO COSTA VERDE 1 C/ANTON DE MARIRREGUERA 1 C/PEPÍN DE PRIA, 30 1 EDIFICIO COLISEO, 2 1 MERCADONA – CALLE CASTAÑO 1 APEADERO RENFE LOS CAMPOS 1 C/EL ABEDUL 1 TOTAL PLAZAS 21 PLAZAS DE ESTACIONAMIENTO PARA PERSONAS CON MINUSVALIA LAS VEGAS – CORVERA DE ASTURIAS LUGAR NUM.de PLAZAS C/VICENTE ALEIXANDRE, 8 2 C/JOVELLANOS, 11 1 C/JOVELLANOS, 15 1 C/ASTURIAS X C/COVADONGA 1 C/ASTURIAS X C/SEVERO OCHOA 1 C/ASTURIAS – PLAZA ZAMORA 1 C/ASTURIAS – PLAZA LEÓN 1 C/SUBIDA LA ESTEBANINA, 3 1 CENTRO REHABILITACIÓN LAS VEGAS 2 C/ESTEBANINA, 8 1 C/ESTEBANINA, 20 1 C/RUBEN DARIO – CENTRO TOMAS Y VALIENTE 2 CENTRO SOCIAL LAS VEGAS 2 CENTRO DE SALUD LAS VEGAS 1 PLAZA VISTAHERMOSA, 8 2 C/COVADONGA, 3 1 C/LA ÑORA, 4 1 C/RAMÓN DE CAMPOAMOR X C/A. -

Horario Y Mapa De La Línea L5 - AVILÉS-PARQUEASTUR De Autobús
Horario y mapa de la línea L5 - AVILÉS-PARQUEASTUR de autobús L5 - AVILÉS-PARQUEASTUR Avilés Ver En Modo Sitio Web La línea L5 - AVILÉS-PARQUEASTUR de autobús (Avilés) tiene 2 rutas. Sus horas de operación los días laborables regulares son: (1) a Avilés: 7:30 - 21:30 (2) a Parque Astur: 7:10 - 22:00 Usa la aplicación Moovit para encontrar la parada de la línea L5 - AVILÉS-PARQUEASTUR de autobús más cercana y descubre cuándo llega la próxima línea L5 - AVILÉS-PARQUEASTUR de autobús Sentido: Avilés Horario de la línea L5 - AVILÉS-PARQUEASTUR de 23 paradas autobús VER HORARIO DE LA LÍNEA Avilés Horario de ruta: lunes 7:30 - 21:30 Parqueastur martes 7:30 - 21:30 Faƒlán miércoles 7:30 - 21:30 S/N Al Faƒlan (trasona Pq), Corvera De Asturias jueves 7:30 - 21:30 Overo viernes 7:30 - 21:30 7 Al Overo (trasona Pq), Corvera De Asturias sábado 7:30 - 21:30 Pantano 2 Tresona/Trasona - Los Campos, Corvera De Asturias domingo 7:30 - 21:30 Pantano 124A Lg Santa Cruz (los Campos Pq), Corvera De Asturias Santa Cruz 2 - El Pantano Información de la línea L5 - AVILÉS-PARQUEASTUR 33 Lg Santa Cruz (los Campos Pq), Corvera De Asturias de autobús Dirección: Avilés Santa Cruz Paradas: 23 1 Cl Sindulfo (los Campos), Corvera De Asturias Duración del viaje: 30 min Resumen de la línea: Parqueastur, Faƒlán, Overo, Poceña Pantano 2, Pantano, Santa Cruz 2 - El Pantano, 8 Lg Santa Cruz (los Campos Pq), Corvera De Asturias Santa Cruz, Poceña, San Ramón, Pueblo Nuevo, Los Campos - Ediƒcio Pradera, Los Campos - Ediƒcio San Ramón Horanso, Avda. -

Bibliotecas De Corvera
Normas de préstamo BIBLIOTECAS DE CORVERA • Necesitarás presentar el carnet de socio cada BIBLIOTECA ANGEL GONZALEZ vez que vayas a realizar un préstamo. • C/ Miguel Angel Blanco s/n CP 33404 Las Vegas Para conseguir el carnet de socio sólo es necesario que rellenes en la biblioteca un Teléfono 985 51 40 01 cuestionario con tus datos personales Horario de Lunes a Viernes Mañanas de 10.00 a 13.00 • Podrás llevarte a casa 3 libros para adultos y 4 Tardes 17.00 a 20.00 infantiles, 3 revistas, 2 DVD y 2 CD-Rom* [email protected] durante. 15 días. • Podrás renovar el préstamo otros 15 días BIBLIOTECA DE LOS CAMPOS siempre y cuando hagas la renovación antes de la fecha de finalización del préstamo. C/ Pepín de Pría Nº9 CP 33404 Los Campos Teléfono 985 57 62 82 • Las renovaciones podrás hacerlas personalmente Horario de Lunes a Viernes en la biblioteca o por Internet (excepto las Mañanas de 11.00 a 13.00 BIBLIOTECAS DE CORVERA revistas y materiales especiales) Tardes de 16.30 a 19.30 [email protected] • Podrás realizar las renovaciones siempre y cuando los documentos no hayan sido solicitados BIBLIOTECA DE CANCIENES por otro usuario. Bajo San José Nº1 CP 33470 Cancienes • Si deseas reservar un documento podrás hacerlo por internet (excepto revistas y Teléfono 985 51 82 08 materiales especiales) Horario Lunes a Viernes Mañanas de 12.00 a 13.00 • Tardes de 17.00 a 20.00 Si te retrasas en la devolución de los [email protected] documentos prestados, estarás sancionado y no podrás hacer uso del servicio de préstamo BIBLIOTECA DE TRASONA durante un período de tiempo que calcula el programa informático de la biblioteca.