Integrated Machine Learning Pipeline for Aberrant Biomarker
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Edinburgh Research Explorer
Edinburgh Research Explorer International Union of Basic and Clinical Pharmacology. LXXXVIII. G protein-coupled receptor list Citation for published version: Davenport, AP, Alexander, SPH, Sharman, JL, Pawson, AJ, Benson, HE, Monaghan, AE, Liew, WC, Mpamhanga, CP, Bonner, TI, Neubig, RR, Pin, JP, Spedding, M & Harmar, AJ 2013, 'International Union of Basic and Clinical Pharmacology. LXXXVIII. G protein-coupled receptor list: recommendations for new pairings with cognate ligands', Pharmacological reviews, vol. 65, no. 3, pp. 967-86. https://doi.org/10.1124/pr.112.007179 Digital Object Identifier (DOI): 10.1124/pr.112.007179 Link: Link to publication record in Edinburgh Research Explorer Document Version: Publisher's PDF, also known as Version of record Published In: Pharmacological reviews Publisher Rights Statement: U.S. Government work not protected by U.S. copyright General rights Copyright for the publications made accessible via the Edinburgh Research Explorer is retained by the author(s) and / or other copyright owners and it is a condition of accessing these publications that users recognise and abide by the legal requirements associated with these rights. Take down policy The University of Edinburgh has made every reasonable effort to ensure that Edinburgh Research Explorer content complies with UK legislation. If you believe that the public display of this file breaches copyright please contact [email protected] providing details, and we will remove access to the work immediately and investigate your claim. Download date: 02. Oct. 2021 1521-0081/65/3/967–986$25.00 http://dx.doi.org/10.1124/pr.112.007179 PHARMACOLOGICAL REVIEWS Pharmacol Rev 65:967–986, July 2013 U.S. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Predicting Coupling Probabilities of G-Protein Coupled Receptors Gurdeep Singh1,2,†, Asuka Inoue3,*,†, J
Published online 30 May 2019 Nucleic Acids Research, 2019, Vol. 47, Web Server issue W395–W401 doi: 10.1093/nar/gkz392 PRECOG: PREdicting COupling probabilities of G-protein coupled receptors Gurdeep Singh1,2,†, Asuka Inoue3,*,†, J. Silvio Gutkind4, Robert B. Russell1,2,* and Francesco Raimondi1,2,* 1CellNetworks, Bioquant, Heidelberg University, Im Neuenheimer Feld 267, 69120 Heidelberg, Germany, 2Biochemie Zentrum Heidelberg (BZH), Heidelberg University, Im Neuenheimer Feld 328, 69120 Heidelberg, Germany, 3Graduate School of Pharmaceutical Sciences, Tohoku University, Sendai, Miyagi 980-8578, Japan and 4Department of Pharmacology and Moores Cancer Center, University of California, San Diego, La Jolla, CA 92093, USA Received February 10, 2019; Revised April 13, 2019; Editorial Decision April 24, 2019; Accepted May 01, 2019 ABSTRACT great use in tinkering with signalling pathways in living sys- tems (5). G-protein coupled receptors (GPCRs) control multi- Ligand binding to GPCRs induces conformational ple physiological states by transducing a multitude changes that lead to binding and activation of G-proteins of extracellular stimuli into the cell via coupling to situated on the inner cell membrane. Most of mammalian intra-cellular heterotrimeric G-proteins. Deciphering GPCRs couple with more than one G-protein giving each which G-proteins couple to each of the hundreds receptor a distinct coupling profile (6) and thus specific of GPCRs present in a typical eukaryotic organism downstream cellular responses. Determining these coupling is therefore critical to understand signalling. Here, profiles is critical to understand GPCR biology and phar- we present PRECOG (precog.russelllab.org): a web- macology. Despite decades of research and hundreds of ob- server for predicting GPCR coupling, which allows served interactions, coupling information is still missing for users to: (i) predict coupling probabilities for GPCRs many receptors and sequence determinants of coupling- specificity are still largely unknown. -

Serum Albumin OS=Homo Sapiens
Protein Name Cluster of Glial fibrillary acidic protein OS=Homo sapiens GN=GFAP PE=1 SV=1 (P14136) Serum albumin OS=Homo sapiens GN=ALB PE=1 SV=2 Cluster of Isoform 3 of Plectin OS=Homo sapiens GN=PLEC (Q15149-3) Cluster of Hemoglobin subunit beta OS=Homo sapiens GN=HBB PE=1 SV=2 (P68871) Vimentin OS=Homo sapiens GN=VIM PE=1 SV=4 Cluster of Tubulin beta-3 chain OS=Homo sapiens GN=TUBB3 PE=1 SV=2 (Q13509) Cluster of Actin, cytoplasmic 1 OS=Homo sapiens GN=ACTB PE=1 SV=1 (P60709) Cluster of Tubulin alpha-1B chain OS=Homo sapiens GN=TUBA1B PE=1 SV=1 (P68363) Cluster of Isoform 2 of Spectrin alpha chain, non-erythrocytic 1 OS=Homo sapiens GN=SPTAN1 (Q13813-2) Hemoglobin subunit alpha OS=Homo sapiens GN=HBA1 PE=1 SV=2 Cluster of Spectrin beta chain, non-erythrocytic 1 OS=Homo sapiens GN=SPTBN1 PE=1 SV=2 (Q01082) Cluster of Pyruvate kinase isozymes M1/M2 OS=Homo sapiens GN=PKM PE=1 SV=4 (P14618) Glyceraldehyde-3-phosphate dehydrogenase OS=Homo sapiens GN=GAPDH PE=1 SV=3 Clathrin heavy chain 1 OS=Homo sapiens GN=CLTC PE=1 SV=5 Filamin-A OS=Homo sapiens GN=FLNA PE=1 SV=4 Cytoplasmic dynein 1 heavy chain 1 OS=Homo sapiens GN=DYNC1H1 PE=1 SV=5 Cluster of ATPase, Na+/K+ transporting, alpha 2 (+) polypeptide OS=Homo sapiens GN=ATP1A2 PE=3 SV=1 (B1AKY9) Fibrinogen beta chain OS=Homo sapiens GN=FGB PE=1 SV=2 Fibrinogen alpha chain OS=Homo sapiens GN=FGA PE=1 SV=2 Dihydropyrimidinase-related protein 2 OS=Homo sapiens GN=DPYSL2 PE=1 SV=1 Cluster of Alpha-actinin-1 OS=Homo sapiens GN=ACTN1 PE=1 SV=2 (P12814) 60 kDa heat shock protein, mitochondrial OS=Homo -

UNITED STATES SECURITIES and EXCHANGE COMMISSION Washington, DC 20549
UNITED STATES SECURITIES AND EXCHANGE COMMISSION Washington, DC 20549 FORM 8-K CURRENT REPORT Pursuant to Section 13 or 15(d) of the Securities Exchange Act of 1934 Date of Report (Date of earliest event reported): May 10, 2012 OMEROS CORPORATION (Exact name of registrant as specified in its charter) Washington 001-34475 91-1663741 (State or other jurisdiction of (Commission (IRS Employer incorporation) File Number) Identification No.) 1420 Fifth Avenue, Suite 2600 Seattle, Washington 98101 (Address of principal executive offices, including zip code) (206) 676-5000 (Registrant’s telephone number, including area code) (Former name or former address, if changed since last report) Check the appropriate box below if the Form 8-K filing is intended to simultaneously satisfy the filing obligation of the registrant under any of the following provisions (see General Instruction A.2. below): ¨ Written communications pursuant to Rule 425 under the Securities Act (17 CFR 230.425) ¨ Soliciting material pursuant to Rule 14a-12 under the Exchange Act (17 CFR 240.14a-12) ¨ Pre-commencement communications pursuant to Rule 14d-2(b) under the Exchange Act (17 CFR 240.14d-2(b)) ¨ Pre-commencement communications pursuant to Rule 13e-4(c) under the Exchange Act (17 CFR 240.13e-4(c)) Item 2.02 Results of Operation and Financial Condition. On May 10, 2012, Omeros Corporation issued a press release announcing financial results for the three months ended March 31, 2012. A copy of such press release is furnished herewith as Exhibit 99.1 and is incorporated herein by reference. The information in this Current Report on Form 8-K, including the exhibit hereto, shall not be deemed to be “filed” for purposes of Section 18 of the Securities Exchange Act of 1934, as amended, or otherwise subject to the liabilities of that Section or Sections 11 and 12(a)(2) of the Securities Act of 1933, as amended. -

Analysis of the Indacaterol-Regulated Transcriptome in Human Airway
Supplemental material to this article can be found at: http://jpet.aspetjournals.org/content/suppl/2018/04/13/jpet.118.249292.DC1 1521-0103/366/1/220–236$35.00 https://doi.org/10.1124/jpet.118.249292 THE JOURNAL OF PHARMACOLOGY AND EXPERIMENTAL THERAPEUTICS J Pharmacol Exp Ther 366:220–236, July 2018 Copyright ª 2018 by The American Society for Pharmacology and Experimental Therapeutics Analysis of the Indacaterol-Regulated Transcriptome in Human Airway Epithelial Cells Implicates Gene Expression Changes in the s Adverse and Therapeutic Effects of b2-Adrenoceptor Agonists Dong Yan, Omar Hamed, Taruna Joshi,1 Mahmoud M. Mostafa, Kyla C. Jamieson, Radhika Joshi, Robert Newton, and Mark A. Giembycz Departments of Physiology and Pharmacology (D.Y., O.H., T.J., K.C.J., R.J., M.A.G.) and Cell Biology and Anatomy (M.M.M., R.N.), Snyder Institute for Chronic Diseases, Cumming School of Medicine, University of Calgary, Calgary, Alberta, Canada Received March 22, 2018; accepted April 11, 2018 Downloaded from ABSTRACT The contribution of gene expression changes to the adverse and activity, and positive regulation of neutrophil chemotaxis. The therapeutic effects of b2-adrenoceptor agonists in asthma was general enriched GO term extracellular space was also associ- investigated using human airway epithelial cells as a therapeu- ated with indacaterol-induced genes, and many of those, in- tically relevant target. Operational model-fitting established that cluding CRISPLD2, DMBT1, GAS1, and SOCS3, have putative jpet.aspetjournals.org the long-acting b2-adrenoceptor agonists (LABA) indacaterol, anti-inflammatory, antibacterial, and/or antiviral activity. Numer- salmeterol, formoterol, and picumeterol were full agonists on ous indacaterol-regulated genes were also induced or repressed BEAS-2B cells transfected with a cAMP-response element in BEAS-2B cells and human primary bronchial epithelial cells by reporter but differed in efficacy (indacaterol $ formoterol . -
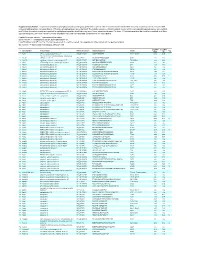
Supplementary Table 1
Supplementary Table 1. Large-scale quantitative phosphoproteomic profiling was performed on paired vehicle- and hormone-treated mTAL-enriched suspensions (n=3). A total of 654 unique phosphopeptides corresponding to 374 unique phosphoproteins were identified. The peptide sequence, phosphorylation site(s), and the corresponding protein name, gene symbol, and RefSeq Accession number are reported for each phosphopeptide identified in any one of three experimental pairs. For those 414 phosphopeptides that could be quantified in all three experimental pairs, the mean Hormone:Vehicle abundance ratio and corresponding standard error are also reported. Peptide Sequence column: * = phosphorylated residue Site(s) column: ^ = ambiguously assigned phosphorylation site Log2(H/V) Mean and SE columns: H = hormone-treated, V = vehicle-treated, n/a = peptide not observable in all 3 experimental pairs Sig. column: * = significantly changed Log 2(H/V), p<0.05 Log (H/V) Log (H/V) # Gene Symbol Protein Name Refseq Accession Peptide Sequence Site(s) 2 2 Sig. Mean SE 1 Aak1 AP2-associated protein kinase 1 NP_001166921 VGSLT*PPSS*PK T622^, S626^ 0.24 0.95 PREDICTED: ATP-binding cassette, sub-family A 2 Abca12 (ABC1), member 12 XP_237242 GLVQVLS*FFSQVQQQR S251^ 1.24 2.13 3 Abcc10 multidrug resistance-associated protein 7 NP_001101671 LMT*ELLS*GIRVLK T464, S468 -2.68 2.48 4 Abcf1 ATP-binding cassette sub-family F member 1 NP_001103353 QLSVPAS*DEEDEVPVPVPR S109 n/a n/a 5 Ablim1 actin-binding LIM protein 1 NP_001037859 PGSSIPGS*PGHTIYAK S51 -3.55 1.81 6 Ablim1 actin-binding -

G Protein-Coupled Receptors
S.P.H. Alexander et al. The Concise Guide to PHARMACOLOGY 2015/16: G protein-coupled receptors. British Journal of Pharmacology (2015) 172, 5744–5869 THE CONCISE GUIDE TO PHARMACOLOGY 2015/16: G protein-coupled receptors Stephen PH Alexander1, Anthony P Davenport2, Eamonn Kelly3, Neil Marrion3, John A Peters4, Helen E Benson5, Elena Faccenda5, Adam J Pawson5, Joanna L Sharman5, Christopher Southan5, Jamie A Davies5 and CGTP Collaborators 1School of Biomedical Sciences, University of Nottingham Medical School, Nottingham, NG7 2UH, UK, 2Clinical Pharmacology Unit, University of Cambridge, Cambridge, CB2 0QQ, UK, 3School of Physiology and Pharmacology, University of Bristol, Bristol, BS8 1TD, UK, 4Neuroscience Division, Medical Education Institute, Ninewells Hospital and Medical School, University of Dundee, Dundee, DD1 9SY, UK, 5Centre for Integrative Physiology, University of Edinburgh, Edinburgh, EH8 9XD, UK Abstract The Concise Guide to PHARMACOLOGY 2015/16 provides concise overviews of the key properties of over 1750 human drug targets with their pharmacology, plus links to an open access knowledgebase of drug targets and their ligands (www.guidetopharmacology.org), which provides more detailed views of target and ligand properties. The full contents can be found at http://onlinelibrary.wiley.com/doi/ 10.1111/bph.13348/full. G protein-coupled receptors are one of the eight major pharmacological targets into which the Guide is divided, with the others being: ligand-gated ion channels, voltage-gated ion channels, other ion channels, nuclear hormone receptors, catalytic receptors, enzymes and transporters. These are presented with nomenclature guidance and summary information on the best available pharmacological tools, alongside key references and suggestions for further reading. -

Mapping the Spatial Proteome of Metastatic Cells in Colorectal Cancer
Mapping the spatial proteome of metastatic cells in colorectal cancer Marta Mendes‡¶, Alberto Peláez-García‡¥, María López-Lucendo‡, Ruben A. Bartolomé‡, Eva Calviño‡, Rodrigo Barderas‡§**, J. Ignacio Casal‡** ‡Department of Cellular and Molecular Medicine, Centro de Investigaciones Biológicas (CIB-CSIC), Madrid, Spain §Instituto de Salud Carlos III. Majadahonda. Spain ¶Present address: Technische Universität Berlin, Germany ¥Present address: Department of Pathology, Hospital Universitario La Paz, IdiPAZ, Madrid, Spain Running title: Mapping the metastatic proteome Keywords: Spatial proteome, cell fractionation, SILAC, metastasis, colorectal cancer ** To whom correspondence should be addressed: Department of Cellular and Molecular Medicine, Centro de Investigaciones Biológicas (CIB-CSIC), Ramiro de Maeztu, 9, 28040 Madrid, Spain. Tel.: +34 918373112; E-mail: [email protected]. Instituto de Salud Carlos III, Majadahonda, Spain Carretera de Majadahonda - Pozuelo, Km. 2.200, 28220 Majadahonda, Madrid, Spain. Tel.: +34 913944155; E-mail: [email protected] 1 ABSTRACT Colorectal cancer (CRC) is the second deadliest cancer worldwide. Here, we aimed to study metastasis mechanisms using spatial proteomics in the KM12 cell model. Cells were SILAC-labeled and fractionated into five subcellular fractions corresponding to: cytoplasm, plasma, mitochondria and ER/golgi membranes, nuclear, chromatin-bound and cytoskeletal proteins and analyzed with high resolution mass spectrometry. We provide localization data of 4863 quantified proteins in the different subcellular fractions. A total of 1318 proteins with at least 1.5-fold change were deregulated in highly metastatic KM12SM cells respect to KM12C cells. The protein network organization, protein complexes and functional pathways associated to CRC metastasis was revealed with spatial resolution. Although 92% of the differentially expressed proteins showed the same deregulation in all subcellular compartments, a subset of 117 proteins (8%) showed opposite changes in different subcellular localizations. -

Multi-Functionality of Proteins Involved in GPCR and G Protein Signaling: Making Sense of Structure–Function Continuum with In
Cellular and Molecular Life Sciences (2019) 76:4461–4492 https://doi.org/10.1007/s00018-019-03276-1 Cellular andMolecular Life Sciences REVIEW Multi‑functionality of proteins involved in GPCR and G protein signaling: making sense of structure–function continuum with intrinsic disorder‑based proteoforms Alexander V. Fonin1 · April L. Darling2 · Irina M. Kuznetsova1 · Konstantin K. Turoverov1,3 · Vladimir N. Uversky2,4 Received: 5 August 2019 / Revised: 5 August 2019 / Accepted: 12 August 2019 / Published online: 19 August 2019 © Springer Nature Switzerland AG 2019 Abstract GPCR–G protein signaling system recognizes a multitude of extracellular ligands and triggers a variety of intracellular signal- ing cascades in response. In humans, this system includes more than 800 various GPCRs and a large set of heterotrimeric G proteins. Complexity of this system goes far beyond a multitude of pair-wise ligand–GPCR and GPCR–G protein interactions. In fact, one GPCR can recognize more than one extracellular signal and interact with more than one G protein. Furthermore, one ligand can activate more than one GPCR, and multiple GPCRs can couple to the same G protein. This defnes an intricate multifunctionality of this important signaling system. Here, we show that the multifunctionality of GPCR–G protein system represents an illustrative example of the protein structure–function continuum, where structures of the involved proteins represent a complex mosaic of diferently folded regions (foldons, non-foldons, unfoldons, semi-foldons, and inducible foldons). The functionality of resulting highly dynamic conformational ensembles is fne-tuned by various post-translational modifcations and alternative splicing, and such ensembles can undergo dramatic changes at interaction with their specifc partners. -

G Protein‐Coupled Receptors
S.P.H. Alexander et al. The Concise Guide to PHARMACOLOGY 2019/20: G protein-coupled receptors. British Journal of Pharmacology (2019) 176, S21–S141 THE CONCISE GUIDE TO PHARMACOLOGY 2019/20: G protein-coupled receptors Stephen PH Alexander1 , Arthur Christopoulos2 , Anthony P Davenport3 , Eamonn Kelly4, Alistair Mathie5 , John A Peters6 , Emma L Veale5 ,JaneFArmstrong7 , Elena Faccenda7 ,SimonDHarding7 ,AdamJPawson7 , Joanna L Sharman7 , Christopher Southan7 , Jamie A Davies7 and CGTP Collaborators 1School of Life Sciences, University of Nottingham Medical School, Nottingham, NG7 2UH, UK 2Monash Institute of Pharmaceutical Sciences and Department of Pharmacology, Monash University, Parkville, Victoria 3052, Australia 3Clinical Pharmacology Unit, University of Cambridge, Cambridge, CB2 0QQ, UK 4School of Physiology, Pharmacology and Neuroscience, University of Bristol, Bristol, BS8 1TD, UK 5Medway School of Pharmacy, The Universities of Greenwich and Kent at Medway, Anson Building, Central Avenue, Chatham Maritime, Chatham, Kent, ME4 4TB, UK 6Neuroscience Division, Medical Education Institute, Ninewells Hospital and Medical School, University of Dundee, Dundee, DD1 9SY, UK 7Centre for Discovery Brain Sciences, University of Edinburgh, Edinburgh, EH8 9XD, UK Abstract The Concise Guide to PHARMACOLOGY 2019/20 is the fourth in this series of biennial publications. The Concise Guide provides concise overviews of the key properties of nearly 1800 human drug targets with an emphasis on selective pharmacology (where available), plus links to the open access knowledgebase source of drug targets and their ligands (www.guidetopharmacology.org), which provides more detailed views of target and ligand properties. Although the Concise Guide represents approximately 400 pages, the material presented is substantially reduced compared to information and links presented on the website. -

Diverse Immunoregulatory Roles of Oxysterols— the Oxidized Cholesterol Metabolites
H OH metabolites OH Review Diverse Immunoregulatory Roles of Oxysterols— The Oxidized Cholesterol Metabolites Chloe Choi 1,* and David K. Finlay 1,2,* 1 School of Biochemistry and Immunology, Trinity Biomedical Sciences Institute, Trinity College Dublin, Pearse Street 152-160, Dublin 2, Ireland 2 School of Pharmacy and Pharmaceutical Sciences, Trinity Biomedical Sciences Institute, Trinity College Dublin, Pearse Street 152-160, Dublin 2, Ireland * Correspondence: [email protected] (C.C.); fi[email protected] (D.K.F.); Tel.: +353-1-896-3564 (D.K.F.) Received: 13 August 2020; Accepted: 24 September 2020; Published: 28 September 2020 Abstract: Intermediates of both cholesterol synthesis and cholesterol metabolism can have diverse roles in the control of cellular processes that go beyond the control of cholesterol homeostasis. For example, oxidized forms of cholesterol, called oxysterols have functions ranging from the control of gene expression, signal transduction and cell migration. This is of particular interest in the context of immunology and immunometabolism where we now know that metabolic processes are key towards shaping the nature of immune responses. Equally, aberrant metabolic processes including altered cholesterol homeostasis contribute to immune dysregulation and dysfunction in pathological situations. This review article brings together our current understanding of how oxysterols affect the control of immune responses in diverse immunological settings. Keywords: oxysterols; cholesterol; SREBP; LXR; GPR183; ROR; SERM; Ch25h; Cyp27a1; inflammation; cancer; infection; obesity; autoimmunity; endometriosis; immunometabolism 1. Introduction Cholesterol is a vital component of our cells and our bodies. It is a structural component of cellular membranes, plays a role in regulating intracellular signal transduction and is a precursor for the generation of other important molecules such as bile acids and steroid hormones.