New York Islanders Playoff Game Notes
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download PDF File -Yvqbvrxd416
NHL Jerseys,MLB Jerseys,NBA Jerseys,nfl youth jerseys,custom nhl jersey,NFL Jerseys,NCAA Jerseys,Custom Jerseys,Soccer Jerseys,Sports Caps.Find jerseys for your favorite team or player with reasonable price from china.Fri May 15 05:29am EDT Morning Juice: If going to be the Rangers pitch, opponents not only can they pitch fits By David Brown This and pertaining to each weekday a.m during baseball season,Mavericks Jerseys,how about we rise and shine together to recap by far the most recent diamond doings. Roll Call starts near going to be the Rio Grande, that whitewater twistin' right through a multi function dusty land where,new era nfl caps,if Matt Harrison(notes) really shines and demonstrates you all of them are he or she can,the Rangers are going to acquire tough for more information on blew because a number of us know they can hit. Game about the Day Rangers 3 Mariners 2 Salt,Saints Jerseys,become familiar with pepper: Good pitching and the Texas Rangers don't usually are preoccupied together like PB & J,cheap nba jerseys for sale,but providing some one their cruel lineup, any kind relating to cheap prices arms would likely make them formidable. Well,article comes to you lefty Matt Harrison,custom sports jerseys, pitching another strong complete game, and there can probably be said Chris Davis(notes) hitting an all in one game-ending homer. StRangers increase to educate yourself regarding 20-14. Pandemonium erupts at Arlington. "We're waiting a multi functional little bit too far away for more information on get the bats going,but take heart a number of us got them going just all over the some time Ian Kinsler(notes) said. -

Pittsburgh Penguins Game Notes
Pittsburgh Penguins Game Notes Sat, Nov 24, 2018 NHL Game #353 Pittsburgh Penguins 8 - 8 - 5 (21 pts) Columbus Blue Jackets 13 - 7 - 2 (28 pts) Team Game: 22 4 - 5 - 2 (Home) Team Game: 23 6 - 4 - 1 (Home) Home Game: 12 4 - 3 - 3 (Road) Road Game: 12 7 - 3 - 1 (Road) # Goalie GP W L OT GAA SV% # Goalie GP W L OT GAA SV% 1 Casey DeSmith 13 4 3 3 2.39 .924 70 Joonas Korpisalo 8 5 0 2 3.67 .885 35 Tristan Jarry 1 0 0 1 1.94 .946 72 Sergei Bobrovsky 15 8 7 0 2.59 .917 # P Player GP G A P +/- PIM # P Player GP G A P +/- PIM 2 D Chad Ruhwedel 11 0 0 0 -8 2 3 D Seth Jones 15 2 7 9 6 2 3 D Olli Maatta 20 0 6 6 6 6 4 D Scott Harrington 18 0 5 5 3 0 6 D Jamie Oleksiak 19 4 5 9 9 23 8 D Zach Werenski 22 4 9 13 -3 6 8 D Brian Dumoulin 21 1 5 6 4 4 9 L Artemi Panarin 21 5 18 23 5 8 12 C Dominik Simon 21 4 6 10 2 6 10 C Alexander Wennberg 22 1 12 13 3 10 14 L Tanner Pearson 22 2 2 4 -7 8 13 R Cam Atkinson 21 14 9 23 4 8 15 C Riley Sheahan 20 1 1 2 -10 5 14 D Dean Kukan 6 0 0 0 -1 4 17 R Bryan Rust 21 1 4 5 -4 6 17 C Brandon Dubinsky 12 2 4 6 0 4 19 C Derick Brassard 12 2 4 6 1 6 18 C Pierre-Luc Dubois 22 10 9 19 3 32 38 C Derek Grant 10 0 1 1 -3 0 20 C Riley Nash 21 0 2 2 -2 11 41 R Daniel Sprong 15 0 4 4 -7 0 27 D Ryan Murray 22 1 10 11 10 4 46 C Zach Aston-Reese 8 1 0 1 0 0 28 R Oliver Bjorkstrand 19 2 2 4 -4 2 50 D Juuso Riikola 10 0 0 0 -1 4 37 L Markus Hannikainen 14 2 2 4 0 0 58 D Kris Letang 20 5 11 16 2 12 38 C Boone Jenner 22 4 6 10 5 10 59 L Jake Guentzel 21 8 7 15 5 4 45 C Lukas Sedlak 16 0 2 2 -1 6 71 C Evgeni Malkin 21 9 20 29 -2 32 58 -
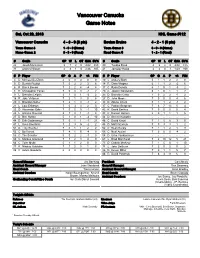
Vancouver Canucks Game Notes
Vancouver Canucks Game Notes Sat, Oct 20, 2018 NHL Game #112 Vancouver Canucks 4 - 3 - 0 (8 pts) Boston Bruins 4 - 2 - 1 (9 pts) Team Game: 8 1 - 0 - 0 (Home) Team Game: 8 3 - 0 - 0 (Home) Home Game: 2 3 - 3 - 0 (Road) Road Game: 5 1 - 2 - 1 (Road) # Goalie GP W L OT GAA SV% # Goalie GP W L OT GAA SV% 25 Jacob Markstrom 3 1 2 0 4.02 .883 40 Tuukka Rask 4 2 2 0 4.08 .875 31 Anders Nilsson 4 3 1 0 2.26 .925 41 Jaroslav Halak 4 2 0 1 1.69 .939 # P Player GP G A P +/- PIM # P Player GP G A P +/- PIM 4 D Michael Del Zotto 2 0 0 0 0 0 10 L Anders Bjork 5 1 1 2 2 0 5 D Derrick Pouliot 7 0 2 2 3 6 14 R Chris Wagner 6 1 1 2 -2 6 6 R Brock Boeser 7 2 2 4 -4 8 17 C Ryan Donato 6 1 0 1 -3 2 8 D Christopher Tanev 7 0 3 3 -2 2 20 C Joakim Nordstrom 6 1 0 1 1 2 9 L Brendan Leipsic 3 1 0 1 -2 2 25 D Brandon Carlo 7 0 2 2 4 2 18 R Jake Virtanen 7 2 1 3 0 8 27 D John Moore 7 0 0 0 4 6 20 C Brandon Sutter 7 2 1 3 -1 2 33 D Zdeno Chara 7 1 1 2 -1 2 21 L Loui Eriksson 7 0 3 3 2 0 37 C Patrice Bergeron 7 6 7 13 5 4 23 D Alexander Edler 7 0 5 5 -1 10 42 R David Backes 7 0 0 0 0 4 26 L Antoine Roussel 3 1 0 1 -1 4 43 C Danton Heinen 5 0 1 1 1 6 27 D Ben Hutton 5 1 0 1 -4 10 44 D Steven Kampfer - - - - - - 44 D Erik Gudbranson 7 0 1 1 -1 21 46 C David Krejci 7 1 5 6 3 0 47 L Sven Baertschi 7 2 3 5 -2 2 48 D Matt Grzelcyk 7 0 3 3 1 2 51 D Troy Stecher 7 0 1 1 2 2 52 C Sean Kuraly 7 1 1 2 1 9 53 C Bo Horvat 7 4 1 5 -4 0 55 C Noel Acciari 7 0 0 0 -4 2 59 C Tim Schaller 5 0 2 2 -1 0 58 D Urho Vaakanainen - - - - - - 60 C Markus Granlund 7 1 2 3 4 0 63 L Brad Marchand -

Carolina Hurricanes
CAROLINA HURRICANES NEWS CLIPPINGS • April 13, 2021 What did the Carolina Hurricanes do at the NHL trade deadline? By Chip Alexander Waddell said he had spoken with several teams Monday about potential deals, saying 10 or 12 trades were For a long time Monday, just before the NHL trade deadline, discussed. By 2 p.m., he said the decision had been made to it appeared the Carolina Hurricanes had made the decision pursue Hakanpaa and get the deal done. that they liked their team and would stick with it. Hakanpaa played with center Sebastian Aho a few years But that changed, just before the 3 p.m. deadline. back in the Finnish league and Waddell said Aho had been The Canes sent defenseman Haydn Fleury to the Anaheim consulted. He said the Canes first talked to Aho when Ducks for defenseman Jani Hakanpaa and a sixth-round Hakanpaa came to the NHL as a free agent in 2019. draft pick in 2022. “Sebastian had nothing but good things to say about his The move was a little surprising in that Fleury was set to play character and what kind of guy he was, and was comfortable for the Canes on Monday against the Detroit Red Wings. that he would come in and fit well with our team and our Canes coach Rod BrindAmour said Monday morning that culture we have,” Waddell said. Fleury would be in the lineup and Jake Bean a scratch. Four hours before the deadline Monday, Canes coach Rod With the Canes 27-9-4 and sitting in first place in the Central Brind’Amour was asked on a media call if he believed he Division, the Canes could have decided to stand pat. -

NHL Club) Adler Mannheim Dennis Seidenberg (Boston Bruins
Country League European Club Name (NHL Club) Adler Mannheim Dennis Seidenberg (Boston Bruins) Krefeld Pinguine Christian Ehrhoff (Buffalo Sabres) Hamburg Freezers Jamie Benn (Dallas Stars) Germany DEL Adler Mannheim Marcel Goc (Florida Panthers) Eisbären Berlin Claude Giroux (Philadelphia Flyers) Eisbären Berlin Danny Briere (Philadelphia Flyers) Heilbronner Falken Jonathan Bernier (Los Angeles Kings) SC Riessersee Rick DiPietro (New York Islanders) Eispiraten Crimmitschau Wayne Simmonds (Philadelphia Flyers) Germany 2nd Bundesliga Beitigheim Steelers T.J. Galiardi (San Jose Sharks) Eispiraten Crimmitschau Chris Stewart (St. Louis Blues) SC Riessersee Matt D'Agostini (St. Louis Blues) Ravensburg Towerstars Adam Hall (Tampa Bay Lightning) Tingsryd Viktor Fasth (Anaheim Ducks) Vasteras Mikael Backlund (Calgary Flames) Djurgarden Gabriel Landeskog (Colorado Avalanche) Tingsryd Mike Santorelli (Florida Panthers) Sweden Allsvenskan Mora IK Anze Kopitar (Los Angeles Kings) Södertälje Carl Hagelin (New York Rangers) Södertälje Matt Read (Philadelphia Flyers) Djurgarden Douglas Murray (San Jose Sharks) Sweden Division 1 Vita Hästen Jonathan Ericsson (Detroit Red Wings) Ceske Budejovice Andrew Ference (Boston Bruins) HC Pardubice David Krejci (Boston Bruins) HC Plzen Tuukka Rask (Boston Bruins) HC Kladno Jiri Tlusty (Carolina Hurricanes) KLH Chomutov Michael Frolik (Chicago Blackhawks) HC Plzen Michal Roszival (Chicago Blackhawks) Ceske Budejovice Radek Martinek (Columbus Blue Jackets) HC Kladno Jaromir Jagr (Dallas Stars) Bili Tygri Liberec Ladislav -

Bruins and Oilers Clinch Playoff Spots
ARAB TIMES, WEDNESDAY, MAY 5, 2021 SPORTS 15 Bruins and Oilers clinch playoff spots NHL Results/Standings WASHINGTON, May 4, (AP): Results and standings from the NHL games on Monday. Ottawa 2 Winnipeg 1 Boston 3 New Jersey 0 Buffalo 4 NY Islanders 2 Carolina 5 Chicago 2 Nashville 4 Columbus OT 3 Montreal 3 Toronto OT 2 Washington 6 NY Rangers 3 Philadelphia 7 Pittsburgh 2 Florida 5 Dallas OT 4 St Louis 3 Anaheim 1 Minnesota 6 Vegas 5 Edmonton 5 Vancouver 3 Los Angeles 3 Arizona 2 Colorado 5 San Jose OT 4 East Division GP W L OT Pts GF GA x-Washington 52 33 14 5 71 181 155 x-Pittsburgh 53 34 16 3 71 180 149 x-Boston 51 31 14 6 68 153 123 x-NY Islanders 52 31 16 5 67 145 118 NY Rangers 53 26 21 6 58 170 145 Philadelphia 52 23 22 7 53 151 188 New Jersey 52 17 28 7 41 136 181 Buffalo 53 14 32 7 35 130 187 Central Division GP W L OT Pts GF GA x-Carolina 52 35 10 7 77 171 123 x-Florida 54 35 14 5 75 180 152 x-Tampa Bay 52 35 14 3 73 172 131 Nashville 53 29 22 2 60 146 149 Dallas 52 21 17 14 56 144 138 Chicago 52 22 24 6 50 148 172 Detroit 54 18 27 9 45 118 164 Columbus 53 16 25 12 44 126 176 West Division GP W L OT Pts GF GA x-Vegas 51 36 13 2 74 173 116 x-Colorado 50 34 12 4 72 176 124 x-Minnesota 51 33 14 4 70 168 140 St Louis 50 24 19 7 55 150 155 Arizona 53 22 25 6 50 141 166 Los Angeles 50 20 24 6 46 133 149 San Jose 52 20 26 6 46 142 181 Anaheim 53 16 30 7 39 117 169 North Division GP W L OT Pts GF GA x-Toronto 52 33 13 6 72 174 136 x-Edmonton 50 31 17 2 64 163 134 Winnipeg 51 27 21 3 57 154 145 Montreal 51 24 18 9 57 148 147 Calgary 50 22 25 3 47 132 144 Ottawa 52 20 27 5 45 143 178 Vancouver 46 19 24 3 41 122 152 Note: Two points for a win one point for overtime loss. -

New York Islanders Game Notes
New York Islanders Game Notes Thu, Apr 22, 2021 NHL Game #730 New York Islanders 29 - 13 - 4 (62 pts) Washington Capitals 29 - 13 - 4 (62 pts) Team Game: 47 19 - 2 - 2 (Home) Team Game: 47 14 - 6 - 2 (Home) Home Game: 24 10 - 11 - 2 (Road) Road Game: 25 15 - 7 - 2 (Road) # Goalie GP W L OT GAA SV% # Goalie GP W L OT GAA SV% 30 Ilya Sorokin 17 12 4 1 2.02 .922 30 Ilya Samsonov 16 11 3 1 2.84 .898 35 Cory Schneider - - - - - - 41 Vitek Vanecek 31 17 9 3 2.77 .908 40 Semyon Varlamov 30 17 9 3 2.20 .923 # P Player GP G A P +/- PIM # P Player GP G A P +/- PIM 2 D Nick Leddy 46 2 25 27 1 6 2 D Justin Schultz 42 3 20 23 12 8 3 D Adam Pelech 46 2 8 10 10 18 3 D Nick Jensen 43 2 10 12 8 14 4 D Andy Greene 46 1 4 5 11 6 4 D Brenden Dillon 46 2 13 15 10 40 6 D Ryan Pulock 46 1 14 15 12 4 8 L Alex Ovechkin 42 24 18 42 -7 10 7 R Jordan Eberle 46 15 16 31 11 12 9 D Dmitry Orlov 41 7 8 15 9 16 8 D Noah Dobson 37 3 10 13 4 6 10 R Daniel Sprong 34 7 7 14 6 6 11 C Austin Czarnik 4 0 0 0 -1 0 17 L Michael Raffl 34 3 5 8 -5 26 12 R Josh Bailey 44 8 20 28 12 4 19 C Nicklas Backstrom 46 14 33 47 -1 14 13 C Mathew Barzal 46 13 25 38 16 42 20 C Lars Eller 34 7 14 21 -1 12 14 C Travis Zajac 40 8 12 20 0 6 21 R Garnet Hathaway 46 4 10 14 6 59 15 R Cal Clutterbuck 41 3 6 9 -6 10 26 C Nic Dowd 46 8 2 10 1 24 17 L Matt Martin 46 6 5 11 2 31 33 D Zdeno Chara 45 2 7 9 8 27 18 L Anthony Beauvillier 37 9 10 19 10 10 39 R Anthony Mantha 46 15 11 26 -15 17 20 L Kieffer Bellows 14 3 0 3 0 4 43 R Tom Wilson 37 11 17 28 -1 49 21 C Kyle Palmieri 41 9 10 19 -5 18 57 D Trevor van Riemsdyk 10 1 0 1 -4 0 24 D Scott Mayfield 46 2 10 12 0 34 62 L Carl Hagelin 46 5 8 13 4 12 25 D Sebastian Aho 3 1 1 2 -1 2 73 L Conor Sheary 43 12 8 20 -2 14 26 R Oliver Wahlstrom 36 9 7 16 0 19 74 D John Carlson 46 10 32 42 -7 10 28 L Michael Dal Colle 23 1 3 4 3 4 77 R T.J. -

20 0124 Bridgeport Bios
BRIDGEPORT SOUND TIGERS: COACHES BIOS BRENT THOMPSON - HEAD COACH Brent Thompson is in his seventh season as head coach of the Bridgeport Sound Tigers, which also marks his ninth year in the New York Islanders organization. Thompson was originally hired to coach the Sound Tigers on June 28, 2011 and led the team to a division title in 2011-12 before being named assistant South Division coach of the Islanders for two seasons (2012-14). On May 2, 2014, the Islanders announced Thompson would return to his role as head coach of the Sound Tigers. He is 246-203-50 in 499 career regular-season games as Bridgeport's head coach. Thompson became the Sound Tigers' all-time winningest head coach on Jan. 28, 2017, passing Jack Capuano with his 134th career victory. Prior to his time in Bridgeport, Thompson served as head coach of the Alaska Aces (ECHL) for two years (2009-11), winning the Kelly Cup Championship in 2011. During his two seasons as head coach in Alaska, Thompson amassed a record of 83- 50-11 and won the John Brophy Award as ECHL Coach of the Year in 2011 after leading the team to a record of 47-22-3. Thompson also served as a player/coach with the CHL’s Colorado Eagles in 2003-04 and was an assistant with the AHL’s Peoria Rivermen from 2005-09. Before joining the coaching ranks, Thompson enjoyed a 14-year professional playing career from 1991-2005, which included 121 NHL games and more than 900 professional contests. The Calgary, AB native was originally drafted by the Los Angeles Kings in the second round (39th overall) of the 1989 NHL Entry Draft. -

NHL Playoffs PDF.Xlsx
Anaheim Ducks Boston Bruins POS PLAYER GP G A PTS +/- PIM POS PLAYER GP G A PTS +/- PIM F Ryan Getzlaf 74 15 58 73 7 49 F Brad Marchand 80 39 46 85 18 81 F Ryan Kesler 82 22 36 58 8 83 F David Pastrnak 75 34 36 70 11 34 F Corey Perry 82 19 34 53 2 76 F David Krejci 82 23 31 54 -12 26 F Rickard Rakell 71 33 18 51 10 12 F Patrice Bergeron 79 21 32 53 12 24 F Patrick Eaves~ 79 32 19 51 -2 24 D Torey Krug 81 8 43 51 -10 37 F Jakob Silfverberg 79 23 26 49 10 20 F Ryan Spooner 78 11 28 39 -8 14 D Cam Fowler 80 11 28 39 7 20 F David Backes 74 17 21 38 2 69 F Andrew Cogliano 82 16 19 35 11 26 D Zdeno Chara 75 10 19 29 18 59 F Antoine Vermette 72 9 19 28 -7 42 F Dominic Moore 82 11 14 25 2 44 F Nick Ritchie 77 14 14 28 4 62 F Drew Stafford~ 58 8 13 21 6 24 D Sami Vatanen 71 3 21 24 3 30 F Frank Vatrano 44 10 8 18 -3 14 D Hampus Lindholm 66 6 14 20 13 36 F Riley Nash 81 7 10 17 -1 14 D Josh Manson 82 5 12 17 14 82 D Brandon Carlo 82 6 10 16 9 59 F Ondrej Kase 53 5 10 15 -1 18 F Tim Schaller 59 7 7 14 -6 23 D Kevin Bieksa 81 3 11 14 0 63 F Austin Czarnik 49 5 8 13 -10 12 F Logan Shaw 55 3 7 10 3 10 D Kevan Miller 58 3 10 13 1 50 D Shea Theodore 34 2 7 9 -6 28 D Colin Miller 61 6 7 13 0 55 D Korbinian Holzer 32 2 5 7 0 23 D Adam McQuaid 77 2 8 10 4 71 F Chris Wagner 43 6 1 7 2 6 F Matt Beleskey 49 3 5 8 -10 47 D Brandon Montour 27 2 4 6 11 14 F Noel Acciari 29 2 3 5 3 16 D Clayton Stoner 14 1 2 3 0 28 D John-Michael Liles 36 0 5 5 1 4 F Ryan Garbutt 27 2 1 3 -3 20 F Jimmy Hayes 58 2 3 5 -3 29 F Jared Boll 51 0 3 3 -3 87 F Peter Cehlarik 11 0 2 2 -

1988-1989 Panini Hockey Stickers Page 1 of 3 1 Road to the Cup
1988-1989 Panini Hockey Stickers Page 1 of 3 1 Road to the Cup Calgary Flames Edmonton Oilers St. Louis Blues 2 Flames logo 50 Oilers logo 98 Blues logo 3 Flames uniform 51 Oilers uniform 99 Blues uniform 4 Mike Vernon 52 Grant Fuhr 100 Greg Millen 5 Al MacInnis 53 Charlie Huddy 101 Brian Benning 6 Brad McCrimmon 54 Kevin Lowe 102 Gordie Roberts 7 Gary Suter 55 Steve Smith 103 Gino Cavallini 8 Mike Bullard 56 Jeff Beukeboom 104 Bernie Federko 9 Hakan Loob 57 Glenn Anderson 105 Doug Gilmour 10 Lanny McDonald 58 Wayne Gretzky 106 Tony Hrkac 11 Joe Mullen 59 Jari Kurri 107 Brett Hull 12 Joe Nieuwendyk 60 Craig MacTavish 108 Mark Hunter 13 Joel Otto 61 Mark Messier 109 Tony McKegney 14 Jim Peplinski 62 Craig Simpson 110 Rick Meagher 15 Gary Roberts 63 Esa Tikkanen 111 Brian Sutter 16 Flames team photo (left) 64 Oilers team photo (left) 112 Blues team photo (left) 17 Flames team photo (right) 65 Oilers team photo (right) 113 Blues team photo (right) Chicago Blackhawks Los Angeles Kings Toronto Maple Leafs 18 Blackhawks logo 66 Kings logo 114 Maple Leafs logo 19 Blackhawks uniform 67 Kings uniform 115 Maple Leafs uniform 20 Bob Mason 68 Glenn Healy 116 Alan Bester 21 Darren Pang 69 Rolie Melanson 117 Ken Wregget 22 Bob Murray 70 Steve Duchense 118 Al Iafrate 23 Gary Nylund 71 Tom Laidlaw 119 Luke Richardson 24 Doug Wilson 72 Jay Wells 120 Borje Salming 25 Dirk Graham 73 Mike Allison 121 Wendel Clark 26 Steve Larmer 74 Bobby Carpenter 122 Russ Courtnall 27 Troy Murray -

For Immediate Release Contacts: Aaron Sickman (651) 602-6009 Friday, March 19, 2021 Megan Kogut (651) 312-3439
For Immediate Release Contacts: Aaron Sickman (651) 602-6009 Friday, March 19, 2021 Megan Kogut (651) 312-3439 TOP TEN CANDIDATES FOR 2021 MR. HOCKEY AWARD ANNOUNCED HENRY BOUCHA RECIPIENT OF MR. HOCKEY AMBASSADOR AWARD SAINT PAUL, Minn. – The Minnesota All Sports Alliance today announced the Top Ten Candidates for the 37th Annual Mr. Hockey Award are: Carter Batchelder (Eden Prairie), Cam Boche (Lakeville South), Jackson Hallum (St. Thomas Academy), Kyle Kukkonen (Maple Grove), Luke Levandowski (Rosemount), Luke Mittelstadt (Eden Prairie), Henry Nelson (Maple Grove), Joe Palodichuk (Hill-Murray), Jack Peart (Grand Rapids) and Joey Pierce (Hermantown). The Minnesota All Sports Alliance also announced today that Aksel Reid (Blake), Alex Timmons (Gentry Academy) and Jack Wieneke (Maple Grove) are the finalists for The Frank Brimsek Award, in recognition of the state’s top senior goaltender. Henry Boucha is the recipient of the fourth annual Mr. Hockey Ambassador Award, given to an influential leader dedicated to the growth and development of hockey in Minnesota. The 37th annual Mr. Hockey Awards Banquet will be held virtually starting at 4 p.m. on Monday, April 5 at TRIA Rink in downtown Saint Paul and hosted by Katie Emmer. Click here for the Zoom link. The Minnesota State High School League Boys’ Hockey Tournament will be held at Xcel Energy Center March 30-31 and April 2-3. The Minnesota Wild sponsor the Mr. Hockey Awards Banquet. The Mr. Hockey Award is hosted, coordinated, and presented by the Minnesota All Sports Alliance. The Mr. Hockey Award is given to the outstanding senior high school boys’ hockey player in the state of Minnesota and is selected by a panel of National Hockey League Scouts, Junior Scouts/Coaches and selected media members from around the state. -

Feature Selection and Dimension Reduction
DATA SCIENCE REPORT SERIES Feature Selection and Data Reduction (DRAFT) Patrick Boily1,2,3,4, Olivier Leduc1, Andrew Macfie3, Aditya Maheshwari3, Maia Pelletier1 Abstract Data mining is the collection of processes by which we can extract useful insights from data. Inherent in this definition is the idea of data reduction: useful insights (whether in the form of summaries, sentiment analyses, etc.) ought to be “smaller” and “more organized” than the original raw data. The challenges presented by high data dimensionality (the so-called curse of dimensionality) must be addressed in order to achieve insightful and interpretable analytical results. In this report, we introduce the basic principles of dimensionality reduction and a number of feature selection methods (filter, wrapper, regularization), discuss some current advanced topics (SVD, spectral feature selection, UMAP) and provide examples (with code). Keywords feature selection, dimension reduction, curse of dimensionality, principal component analysis, manifold hypothesis, manifold learning, regularization, subset selection, spectral feature selection, uniform manifold approximation and projection Funding Acknowledgement Parts of this report were funded by a University of Ottawa grant to develop teaching material in French (2019-2020). These were subsequently translated into English before being incorporated into this document. 1Department of Mathematics and Statistics, University of Ottawa, Ottawa 2Sprott School of Business, Carleton University, Ottawa 3Idlewyld Analytics and Consulting