Modularity in Artificial Neural Networks
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

± »C0 ± ´C J¯ ¤T8=9=8
´±»C±Ð±PÒÒ³R±ºý³PC ·Ò»P±¼¤E4 C±Ñ±Rºý 54¿_C4±ÒE= ±EM±Ò²R4±Ò Thursday 15th August 2013 -Vol-1- Issue :8 independentE97ªcomprehensiveE9C ªcultural E=C7ªPolitical E= C= cÒM±E;±¢¹P4±ÏT2±ÊαbÊ ¢TÊ=:(± ³b7Cбb ±ÏC0±W`PdÒP±Z:)± Ô¹C´C¹C³P;c9FCÏ ±Ò²C»±ÒbCC±b aC7 ±ÏP7d¹±R±Òõ:04ê±ÒE R/±õc97±´C d8RM±T=gR±ZE:´CCP74d;:=±T=gR± ‘No Muslim C<C ýÍR/ÐC=»ÒPjÒW=M±F=±ý Parking’ Sign Yemeni President Hadi holds summit talks with US President Obama Angers US Muslims HOUSTON – Signs banning Mus- lims from using a Houston shopping center parking lot mysteriously ÏC0±W³»SýÔR0ê±`M±¿CjR±b9`Q±d RÔP@`c97±G`¹P appeared this week, generating mas- sive Muslim outrage to the insensi- tive, discriminatory posters. ²¬T2«CÊ4»M±TERÊ0ê±X ÒM±ÌR/ʱ«CECÊÒFC´CÒ_Êj±b³RCÊ7± "I'm very shocked because we do live ÔP@ÏC0±F1ÐPÊ4EÒP4±E4±»Ð±P=cÊ9EC±C<R2Ê= FhRER0ê±EÊ R/±Ð¯ in a society that's supposed to be very ´RÐP4Êd R»C0Ê`¹Pc9ÊW7±F7EÊ R/±ÐFCÊhÒd RP:ÊÎÒS4ê±T=gRʱ accepting, and this is what we all ÏC0±ÐC8`Ï ¶ÒR(Cõ9ê±R=ÒõC0:9F: ÒE»CÒ«C1=E9 c9_<4 preach," Yara Aboshady told CNN `¹PÎC7±`EÊR0ê±`M±´±b`8ù`¹¹RÊC_=±R¯P:ÊÔR0ê±E=9 ±P±RʼÒc6aC` affiliate KPRC on Friday, August 9. EC:&E= C=±Ã±»Q±E±P4±ÒER'±²ST=g»DgCÐCR4±ÏC0_<;õ:9ê±Ð±b ±EC:³¹C "That we all have the freedom of Ô¼C´b6jÒõ:9ê±Ð±b ±EC:d6R±`:R±PÊÒdC9±P:Òõ:9ê±Ð±b ± religion.". -

Drawing… Art and Therapy!
Fourth periodic magazine - Issued by Family Counseling & Development Foundation Drawing… Art and Therapy! Dr. Bilqis Jabari : The poor psychological conditions prompted us to implement the project to help the Yemenis affected by wars and conflicts Inside Republic of Yemen Child Abuse Affects Ministry of Social Afairs Their Heath and Life in the Future 09 Report The Hotline Magazine 136 The First Theme to Restore Hope 6 General Supervision Health Treatment Arts Dr. Bilqis Jabari Editorial Board Free Nabil Al-Khayati Drawing… Group Art and Medication Osama Atiah Therapy; Distribution Therapy! Abdul Rahman Saber the Most Effective Project: Everyone knows that drawing Humanitarian Gesture is one of the fnest arts, but Means during War what many do not realize is that Reached Only Few and drawing is not limited to being a Great Many Await ,an art Technical Director 10 14 05 Fouad Mossbahi Interview Dr. Bilqis Jabari: The great psychological pressures that people face have prompted us to implement the psychosocial response to Yemenis All rights reserved affected by wars and conficts project Family Counseling & Development Foundation 12 Address: Republic of Yemen - Sana›a You and your child Hadda Street - Intersection with the ffty behind the Egyptian Embassy Management: 418403 Depression Yemen Center for Family Consultancy: 418404 E-mail: in Children [email protected] Signs and Treatment 09 Amer: Mental disorders have increased by war and armed confict among the poor people in Yemen. The drug project did not cover one present of the overall scale of the needs Free Medication Distribution Project: Humanitarian Gesture Reached Only Few and a Great Many Await Mental disorders are of the Drug Project, said Psychological sessions, treatment and medication, found in almost every that the selecting the hubs in addition to the free and that the distribution of community. -
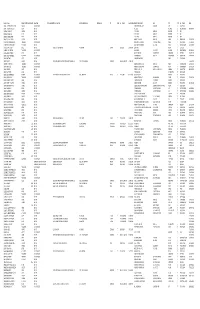
Person's Name Plumber Or ACR License Number License Type
Person's Name Plumber or ACR License Number License Type RRC License Number Licensee Name Licensee Address Line 1 Address Line 2 City State Zip County Licensee Phone Alternate Address Line 1 Line 2 City State Zip County Phone ABBOTT, CHRISTOPHER WAYNE AC23153 ACR CONTRACTOR HOME MAINTENACE SERVICE 2110 FM 999 GARY TX 75643 PANOLA ABBOTT, GEORGE WESLEY J-29427 PLUMBER PO BOX 236 TERLINGUA TX 79852 BREWSTER 000-000-0000 ABREGO, ELISEO JR M-19518 PLUMBER J'S PLUMBING PO BOX 3218 EDINBURG TX 78541 ABREGO, RODOLFO M J-31361 PLUMBER J'S PLUMBING PO BOX 3218 EDINBURG TX 78541 ABREGO, RUBEN JAIME J-36253 PLUMBER J'S PLUMBING PO BOX 3218 EDINBURG TX 78540 ABSHER, MICHAEL TODD M-39342 PLUMBER BEARCAT PLUMBING PO BOX 1747 ALEDO TX 76008 PARKER 817-300-3228 ACKERMANN, INGOMAR KURT TACLA10472E ACR CONTRACTOR ACKERMANN AIR SERVICES 4717 SUNSET CIRCLE S. KELLER TX 76244 TARRANT 817-562-4446 ACKERMANN, JOHN ROGER RMP-40188 PLUMBER ACKERMANN PLUMBING CO 301 E 4TH ST KEENE TX 76059 JOHNSON 817-558-8878 ACKLEY, EARL WILSON J-38212 PLUMBER 14350 CURL'S PLUMBING CO. P.O. BOX 1340 RED OAK TX 75154 ELLIS 972-617-0090 121 HAWK LN. RED OAK TX 75154 ELLIS ACTON, PHILIP ANDREW TACLB17818E ACR CONTRACTOR BAND-AIRE LLC P.O. BOX 2576 BANDERA TX 78003 BANDERA 830-796-9111 ACUNA, MARK ANTHONY J-28268 PLUMBER MURRAY PLUMBING 4430 CENTER GATE SAN ANTONIO TX 78217 BEXAR 210-277-7177 ADAIR, TIMOTHY MICHAEL ACLB26433E ACR CONTRACTOR WEATHERFORD ISD 907 S ELM ST. WEATHERFORD TX 76086 PARKER 817-598-2853 ADAME, ANTONIO J-47567 PLUMBER 13850 DIPLOMAT DRIVE DALLAS TX 75234 DALLAS ADAME, JAIME G. -

Explosion of Poppies
NEWS Local news and entertainment since 1969 GET SOLAR & AC Entertainment AND SAVE BIG SAVE YOUR ELECTRIC BILL EACH MONTH 25 YEAR WARRANTY May 22 - 28, 2020 $89.94 COMBINED Guide A MONTH Amana Lifetime Warranty Last AC You’ll Ever Inside Primary Election HBO Max enters the Buy streaming showdown Lic #380200 • 4.38 kw • $36,000 nanced at 2.99% is Anna Kendrick stars in the combo price $89.94 for 18 months then re-amortize OAC. new series “Love Life” as the HBO Max streaming service 575-449-3277 voting guide begins Wednesday. YELLOWBIRDAC.COM • YELLOWBIRDSOLAR.COM2 x 5.5” ad page 10 FRIDAY, MAY 22, 2020 Take a detour to Desert Exposure Explore the monthly Desert Exposure, “the biggest little Here are some ways to get your Desert Exposure fix: I Volume 52, Number 21 newspaper in the Southwest.” This eclectic arts and leisure • Check area racks and newsstands • Share stories and photos publication delivers a blend of content to make you laugh, • Visit www.desertexposure.com with Editor Elva Osterreich [email protected], think and sometimes just get up and dance. • Sign up for an annual mail 575-443-4408 Desert Exposure captures the flavor, beauty and subscription for $54 contact Teresa Tolonen, I lascrucesbulletin.com uniqueness of Silver City, Las Cruces and the whole • Promote your organization to [email protected] our widespread readership Southwest region of New Mexico. You can also peruse • Sign up for our semi-monthly through Desert Exposure our wide array of advertisers to plan your stops on your Desert Exposure email newsletter advertising with Pam Rossi next Southwest New Mexico road trip, no matter which contact Ian Clarke, [email protected], direction you’re going. -

UNITED STATES BANKRUPTCY COURT Southern District of New York *SUBJECT to GENERAL and SPECIFIC NOTES to THESE SCHEDULES* SUMMARY
UNITED STATES BANKRUPTCY COURT Southern District of New York Refco Capital Markets, LTD Case Number: 05-60018 *SUBJECT TO GENERAL AND SPECIFIC NOTES TO THESE SCHEDULES* SUMMARY OF AMENDED SCHEDULES An asterisk (*) found in schedules herein indicates a change from the Debtor's original Schedules of Assets and Liabilities filed December 30, 2005. Any such change will also be indicated in the "Amended" column of the summary schedules with an "X". Indicate as to each schedule whether that schedule is attached and state the number of pages in each. Report the totals from Schedules A, B, C, D, E, F, I, and J in the boxes provided. Add the amounts from Schedules A and B to determine the total amount of the debtor's assets. Add the amounts from Schedules D, E, and F to determine the total amount of the debtor's liabilities. AMOUNTS SCHEDULED NAME OF SCHEDULE ATTACHED NO. OF SHEETS ASSETS LIABILITIES OTHER YES / NO A - REAL PROPERTY NO 0 $0 B - PERSONAL PROPERTY YES 30 $6,002,376,477 C - PROPERTY CLAIMED AS EXEMPT NO 0 D - CREDITORS HOLDING SECURED CLAIMS YES 2 $79,537,542 E - CREDITORS HOLDING UNSECURED YES 2 $0 PRIORITY CLAIMS F - CREDITORS HOLDING UNSECURED NON- YES 356 $5,366,962,476 PRIORITY CLAIMS G - EXECUTORY CONTRACTS AND UNEXPIRED YES 2 LEASES H - CODEBTORS YES 1 I - CURRENT INCOME OF INDIVIDUAL NO 0 N/A DEBTOR(S) J - CURRENT EXPENDITURES OF INDIVIDUAL NO 0 N/A DEBTOR(S) Total number of sheets of all Schedules 393 Total Assets > $6,002,376,477 $5,446,500,018 Total Liabilities > UNITED STATES BANKRUPTCY COURT Southern District of New York Refco Capital Markets, LTD Case Number: 05-60018 GENERAL NOTES PERTAINING TO SCHEDULES AND STATEMENTS FOR ALL DEBTORS On October 17, 2005 (the “Petition Date”), Refco Inc. -

State's Responses As of 8.21.18 (00041438).DOCX
DEMOCRACY DIMINISHED: STATE AND LOCAL THREATS TO VOTING POST‐SHELBY COUNTY, ALABAMA V. HOLDER As of May 18, 2021 Introduction For nearly 50 years, Section 5 of the Voting Rights Act (VRA) required certain jurisdictions (including states, counties, cities, and towns) with a history of chronic racial discrimination in voting to submit all proposed voting changes to the U.S. Department of Justice (U.S. DOJ) or a federal court in Washington, D.C. for pre- approval. This requirement is commonly known as “preclearance.” Section 5 preclearance served as our democracy’s discrimination checkpoint by halting discriminatory voting changes before they were implemented. It protected Black, Latinx, Asian, Native American, and Alaskan Native voters from racial discrimination in voting in the states and localities—mostly in the South—with a history of the most entrenched and adaptive forms of racial discrimination in voting. Section 5 placed the burden of proof, time, and expense1 on the covered state or locality to demonstrate that a proposed voting change was not discriminatory before that change went into effect and could harm vulnerable populations. Section 4(b) of the VRA, the coverage provision, authorized Congress to determine which jurisdictions should be “covered” and, thus, were required to seek preclearance. Preclearance applied to nine states (Alabama, Alaska, Arizona, Georgia, Louisiana, Mississippi, South Carolina, Texas, and Virginia) and a number of counties, cities, and towns in six partially covered states (California, Florida, Michigan, New York, North Carolina, and South Dakota). On June 25, 2013, the Supreme Court of the United States immobilized the preclearance process in Shelby County, Alabama v. -

The Case of the Sudan's Power Relations
American University in Cairo AUC Knowledge Fountain Theses and Dissertations 6-1-2015 A Prince and a Fractured Kingdom: The Case of the Sudan’s Power Relations Jihad Salih Mashamoun Follow this and additional works at: https://fount.aucegypt.edu/etds Recommended Citation APA Citation Salih Mashamoun, J. (2015).A Prince and a Fractured Kingdom: The Case of the Sudan’s Power Relations [Master’s thesis, the American University in Cairo]. AUC Knowledge Fountain. https://fount.aucegypt.edu/etds/63 MLA Citation Salih Mashamoun, Jihad. A Prince and a Fractured Kingdom: The Case of the Sudan’s Power Relations. 2015. American University in Cairo, Master's thesis. AUC Knowledge Fountain. https://fount.aucegypt.edu/etds/63 This Thesis is brought to you for free and open access by AUC Knowledge Fountain. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of AUC Knowledge Fountain. For more information, please contact [email protected]. The American University in Cairo School of Humanities and Social Sciences A Prince and a Fractured Kingdom: The Case of the Sudan’s Power Relations A Thesis Submitted to The Political Science Department In partial fulfillment of the requirements for A Master of Arts Degree By Jihad Salih Mashamoun Under the supervision of Dr. Nadia Farah April 30,2015 Table of Contents Dedication……………………………………………………………………………v Acknowledgments…………………………………………………………………...vi Acronyms………………………………………………………………………………………….. vii Abstract……………………………………………………………………………...xi Introduction…………………………………………………………………………...1 -

The Use of Performance As a Tool for Communicating Islamic Ideas and Teachings
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by University of Birmingham Research Archive, E-theses Repository THE USE OF PERFORMANCE AS A TOOL FOR COMMUNICATING ISLAMIC IDEAS AND TEACHINGS By RAHEES KASAR A thesis submitted to the University of Birmingham for the degree of DOCTOR OF PHILOSOPHY School of Philosophy, Theology and Religion Department of Theology and Religion College of Arts and Law University of Birmingham July 2015 i University of Birmingham Research Archive e-theses repository This unpublished thesis/dissertation is copyright of the author and/or third parties. The intellectual property rights of the author or third parties in respect of this work are as defined by The Copyright Designs and Patents Act 1988 or as modified by any successor legislation. Any use made of information contained in this thesis/dissertation must be in accordance with that legislation and must be properly acknowledged. Further distribution or reproduction in any format is prohibited without the permission of the copyright holder. GLOSSARY Allah Arabic word for God Da’wah To call, to invite Islah Revival Balag Proclamation Dawat Islami A da’wah group, invitation to Islam Tablighi Jamaat Da’wah Group, Society for spreading faith Hikaya Tale or narrative Tamtheel Pretention Khayaal Imagination Ta’ziyah Shia passion plays Fiqh Islamic law Aqeedah Creed Sunnah Prophet Tradition Ummah Muslim Community ii ABSTRACT The emergence and growth of performance for the purpose of communicating Islamic ideas and teachings is a topic that has gained popularity with no real academic research, which is vital as it is utilised as a tool for da’wah, propagation and communication. -

Sxsw Film Festival Announces 2019 Features and Episodic Premieres
SXSW FILM FESTIVAL ANNOUNCES 2019 FEATURES AND EPISODIC PREMIERES Austin, Texas, January 16, 2019 — South by Southwest® (SXSW®) Conference and Festivals announced the features and episodic premieres lineup for the 26th edition of the Film Festival, running March 8-17, 2019 in Austin, Texas. The acclaimed program draws thousands of fans, filmmakers, press, and industry leaders every year to immerse themselves in the most innovative, smart and entertaining new films of the year. Jordan Peele’s Us was previously announced as the Festival’s Opening Night film, while Olivia Wilde, Jessica Brillhart and Marti Noxon have been announced as this year’s Film Keynotes. The 102 features and episodics in this release will be shown across the nine days of SXSW, with dozens of additional titles to be announced February 6. The complete SXSW Film Festival program typically includes between 320 and 340 total projects. The 2019 program was selected from 2,351 feature-length film submissions, with a total of 8,490 films submitted this year. “As we head into our 26th edition, we couldn’t be more excited to once again share a completely fresh SXSW 2019 slate with our uniquely smart and enthusiastic SXSW audience,” said Janet Pierson, Director of Film. “As always, we looked for a wide range of work, contemplating scale, style, tenor and tone. We hope that this year’s outstanding array of films from accomplished to emerging talent will entertain, surprise, and provoke.” Interactive, Film, and Music badges include expanded access to more of the SXSW Conference and Festivals experience. With one unified conference that spans 25 tracks of programming SXSW offers more opportunities for networking, learning, and discovery than ever before. -

IMANA Impact Report-2018-Single.Indd 1 1/23/2019 1:52:23 PM IMANA Impact Report-2018-Single.Indd 2 1/23/2019 1:52:31 PM 3
IMPACT REPORT IMANA Medical Relief IMANA Impact Report-2018-Single.indd 1 1/23/2019 1:52:23 PM IMANA Impact Report-2018-Single.indd 2 1/23/2019 1:52:31 PM 3 IMANA Impact Report-2018-Single.indd 3 1/23/2019 1:52:36 PM Letter from the President .........................................................................................................5 IMANA Leadership.....................................................................................................................6 Evenings with IMANA ................................................................................................................7 Conventions Attended ..............................................................................................................8 Strategic Plan Update ................................................................................................................9 CME Conferences ....................................................................................................................10 Donation Data ..........................................................................................................................11 Membership Data ....................................................................................................................12 IMR Statistics ............................................................................................................................14 IMR Mission Impact in 2017 ...................................................................................................16 -

Arab-Americans and Muslim-Americans Then and Now: From
Arab-Americans and Muslim-Americans Then and Now: From Immigration and Assimilation to Political Activism and Education by Monica Mona Eraqi A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Education (Curriculum and Practice) in the University of Michigan - Dearborn 2014 Doctoral Committee: Associate Professor Julie Ann Taylor, Chair Associate Professor Christopher Burke Assistant Professor Maiyoua Vang ACKNOWLEDGEMENTS In the Name of God, the Most Compassionate, the Most Merciful I am extremely grateful to the many people that influenced my life, inspired me to pursue a doctorate, and have contributed to my success throughout this long journey. First, I would like to express my deepest appreciation to my committee chair, Dr. Julie Ann Taylor. Dr. Taylor's vision and critical analysis have helped to shape my research, which have taken my studies to new heights I had not previously considered. Her passion for the social studies and Arab-American and Muslim-American studies help me remember the true purpose of studying and teaching history. I would also like to thank my committee member Dr. Maiyoua Vang. Dr. Vang is a true multiculturalist and her determination and ambition were a constant reminder and motivation as to why multicultural education is vital to student learning. At times, Dr. Vang could read my mind and provide me with the inspiration and direction for my dissertation. It was refreshing to be around those who care as deeply as I do about education. I one day hope to be as inspirational as both of these women. Additionally, I would like to thank Dr. -

What If God Is a Woman?
FREE Issue 3 Autumn 2008 Issue 3 Celebrating the diversity of London’s faith and culture What if God is a woman? Travel the World on a Shoestring Can He take a joke? P30 P8 P22 P18 Contents 4 ... Editorial Calendar ... 6 Top Tips for Freshers ... 7 8 ... Can He take a joke? News ... 10 11 ... Violence on Film 12 ... Recipes 14 ... What if God is a woman? 16 ... Olympic Quiz 18 ... Autumn Sport 19 ... Interview with Rushanara Ali 20 ... Travel the World on a Shoestring Student Finance ... 22 24 ... Inter-Act Update Reviews ... 26 New Religious Movements: are they dangerous ... 27 Listings ... 30 Interact magazine funded by EDITORIAL London is the most multi-cultural city in the world: every country, every culture, every faith is represented here. Each cultural tradition, whether derived from faith or ethnicity, uniquely, but are all in their way constantly evolving, all striving to ensure survival of a cultural heritage in a modern world. Inter-Act aims to provide a platform for these cultures and this process, showing that culture provides a stage on which faith and ethnicities face no barriers for discussion, understanding and interaction. Interact is quite an ambitious project, a microcosm if you like of the attempt to promote understanding between multifarious faiths. In bringing together people from different backgrounds, in learning to appreciate difference and in dismantling fallacies with respect to all cultures, we hope to build a harmonious society. Interact has gone through a period of transformation, and has come out with YOU, the London student population as its target.