Logic Synthesis of Recombinase-Based Genetic Circuits Tai-Yin Chiu and Jie-Hong R
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Logisim Operon Circuits
International Journal of Scientific & Engineering Research, Volume 4, Issue 8, August-2013 1312 ISSN 2229-5518 Logisim Operon Circuits Aman Chandra Kaushik Aman Chandra Kaushik (M.Sc. Bioinformatics) Department of Bioinformatics, University Institute of Engineering & Technology Chhatrapati Shahu Ji Maharaj University, Kanpur-208024, Uttar Pradesh, India Email: [email protected] Phone: +91-8924003818 Abstract: Creation of Logism Operon circuits for bacterial cells that not only perform logic functions, but also remember the results, which are encoded in the cell’s DNA and passed on for dozens of generations. This circuits is coded in JAVA Language. “Almost all of the previous work in synthetic biology that we’re aware of has either focused on logic components and logical circuits or on memory modules that just encode memory. We think complex computation will involve combining both logic and memory, and that’s why we built this particular framework for designing circuits Life Science. In one circuit described in the paper, one DNA sequences have three genes called Repressor, Operator (terminators) are interposed between the promoter (DNA Polymerase) and the output Proteins (Beta glactosidase, permease, Transacetylase in this case). Each of these terminators inhibits the transcription and Translation of the output gene and can be flipped by a different Promoter enzyme (DNA Polymerase), making the terminator inactive. Key words: Logical IJSERGate, JAVA, Circuits, Operon, AND, OR, NOT, NOR, NAND, XOR, XNOR, Operon Logisim Circuits. IJSER © 2013 http://www.ijser.org International Journal of Scientific & Engineering Research, Volume 4, Issue 8, August-2013 1313 ISSN 2229-5518 1. Introduction The AND gate is obtained from the E6 core module by extending both ends with hairpin M olecular Logic Gates Coding in Java modules, one complementary to input Language and circuits are designed in oligonucleotide x and the other Logisim complementary to input oligonucleotide y. -

LOGIC GATESLOGIC GATES Logic Gateslogic Gates
SCR 1013 : Digital Logic Module 3:Module 3:ModuleModule 3: 3: LOGIC GATESLOGIC GATES Logic GatesLogic Gates NOT Gate (Inverter) AND Gate OR Gate NAND Gate NOR Gate Exclusive-OR (XOR) Gate Exclusive-NOR (XNOR) Gate OutlineOutline • NOT Gate (Inverter) Basic building block • AND Gate • OR Gate Universal gate using • NAND Gate 2 of the basic gates • NOR Gate Universal gate using 2 of the basic gates • Exclusive‐OR (XOR) Gate • Exclusive‐NOR (XNOR) Gate NOT Gate (Inverter)NOT Gate (Inverter) • Characteriscs Performs inversion or complementaon • Changes a logic level to the opposite • 0(LOW) 1(HIGH) ; 1 0 • Symbol • Truth Table Input Output 1 0 0 1 NOT Gate (Inverter)NOT Gate (Inverter) • Operator – NOT Gate is represented by overbar • Logic expression AND GateAND Gate • Characteriscs – Performs ‘logical mul@plica@on’ • If all of the input are HIGH, then the output is HIGH. • If any of the input are LOW, then the output is LOW. – AND gate must at least have two (2) INPUTs, and must always have 1 (one) OUTPUT. The AND gate can have more than two INPUTs • Symbols OR GateOR Gate • Characteriscs – Performs ‘logical addion’. • If any of the input are HIGH, then the output is HIGH. • If all of the input are LOW, then the output is LOW. • Symbols NAND GateNAND Gate • NAND NOT‐AND combines the AND gate and an inverter • Used as a universal gate – Combina@ons of NAND gates can be used to perform AND, OR and inverter opera@ons – If all or any of the input are LOW, then the output is HIGH. -

Designing Combinational Logic Gates in Cmos
CHAPTER 6 DESIGNING COMBINATIONAL LOGIC GATES IN CMOS In-depth discussion of logic families in CMOS—static and dynamic, pass-transistor, nonra- tioed and ratioed logic n Optimizing a logic gate for area, speed, energy, or robustness n Low-power and high-performance circuit-design techniques 6.1 Introduction 6.3.2 Speed and Power Dissipation of Dynamic Logic 6.2 Static CMOS Design 6.3.3 Issues in Dynamic Design 6.2.1 Complementary CMOS 6.3.4 Cascading Dynamic Gates 6.5 Leakage in Low Voltage Systems 6.2.2 Ratioed Logic 6.4 Perspective: How to Choose a Logic Style 6.2.3 Pass-Transistor Logic 6.6 Summary 6.3 Dynamic CMOS Design 6.7 To Probe Further 6.3.1 Dynamic Logic: Basic Principles 6.8 Exercises and Design Problems 197 198 DESIGNING COMBINATIONAL LOGIC GATES IN CMOS Chapter 6 6.1Introduction The design considerations for a simple inverter circuit were presented in the previous chapter. In this chapter, the design of the inverter will be extended to address the synthesis of arbitrary digital gates such as NOR, NAND and XOR. The focus will be on combina- tional logic (or non-regenerative) circuits that have the property that at any point in time, the output of the circuit is related to its current input signals by some Boolean expression (assuming that the transients through the logic gates have settled). No intentional connec- tion between outputs and inputs is present. In another class of circuits, known as sequential or regenerative circuits —to be dis- cussed in a later chapter—, the output is not only a function of the current input data, but also of previous values of the input signals (Figure 6.1). -

Performance Analysis of Adiabatic Logic Gate Circuits Using 4T Dram Cells
PERFORMANCE ANALYSIS OF ADIABATIC LOGIC GATE CIRCUITS USING 4T DRAM CELLS by ANUPRIYA KRISHNAMOORTHY A THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Engineering in The Department of Electrical and Computer Engineering to The School of Graduate Studies of The University of Alabama in Huntsville HUNTSVILLE, ALABAMA 2016 iii iv ACKNOWLEDGEMENTS This thesis could not be completed without the assistance of several people who deserve special mention. First, I would like to thank Dr. Fat Duen Ho for his guidance throughout all the stages of the work. Second the members of my committee, Dr. David Wendi Pan and Dr. Jia Li, who have been helpful with comments and suggestions. I would like to thank my family especially my parents Krishnamoorthy Vanchinathan(Father), Umamaheswari Jagadeesan (Mother) and my elder sibling Abinaya Krishnamoorthy (Sister) and my friend Ashish Ramesh, for tolerating me through the whole process. v TABLE OF CONTENTS Page List of Figures ............................................................................................................................................ viii List of Symbols ............................................................................................................................................ xi 1. INTRODUCTION AND BACKGROUND 1.1 Overview ................................................................................................................................... 1 1.2 Tank Oscillator Operation ........................................................................................................ -

A New Design of XOR-XNOR Gates for Low Power Application
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by UTHM Institutional Repository 2011 International Conference on Electronic Devices, Systems & Applications (ICEDSA) A New Design of XOR-XNOR gates for low power application Nabihah Ahmad Rezaul Hasan Faculty of Electrical and Electronic, School of Engineering and Advanced Technology Universiti Tun Husseion Onn Malaysia Massey University Batu Pahat, Johor, Malaysia Auckland, New Zealand [email protected] [email protected] Abstract—XOR and XNOR gate plays an important role in network can be found in [4]. Each input is connected to both an digital systems including arithmetic and encryption circuits. This NMOS transistor and a PMOS transistor. It provide a full paper proposes a combination of XOR-XNOR gate using 6- output voltage swing but with a large number of transistors. transistors for low power applications. Comparison between a best existing XOR-XNOR have been done by simulating the Complementary pass transistor logic (CPL) is used in [1]. proposed and other design using 65nm CMOS technology in Wang et al. [2] report the XOR-XNOR circuits based on Cadence environment. The simulation results demonstrate the transmission gates. It uses eight transistors and complementary delay, power consumption and power-delay product (PDP) at inputs and has a drawback of loss of driving capability. Wang different supply voltages ranging from 0.6V to 1.2V. The results et al. also designed XOR-XNOR circuits based on inverter show that the proposed design has lower power dissipation and gates. It does not require a complementary inputs but it has no has a full voltage swing. -

Combinational Logic Circuits
CHAPTER 4 COMBINATIONAL LOGIC CIRCUITS ■ OUTLINE 4-1 Sum-of-Products Form 4-10 Troubleshooting Digital 4-2 Simplifying Logic Circuits Systems 4-3 Algebraic Simplification 4-11 Internal Digital IC Faults 4-4 Designing Combinational 4-12 External Faults Logic Circuits 4-13 Troubleshooting Prototyped 4-5 Karnaugh Map Method Circuits 4-6 Exclusive-OR and 4-14 Programmable Logic Devices Exclusive-NOR Circuits 4-15 Representing Data in HDL 4-7 Parity Generator and Checker 4-16 Truth Tables Using HDL 4-8 Enable/Disable Circuits 4-17 Decision Control Structures 4-9 Basic Characteristics of in HDL Digital ICs M04_WIDM0130_12_SE_C04.indd 136 1/8/16 8:38 PM ■ CHAPTER OUTCOMES Upon completion of this chapter, you will be able to: ■■ Convert a logic expression into a sum-of-products expression. ■■ Perform the necessary steps to reduce a sum-of-products expression to its simplest form. ■■ Use Boolean algebra and the Karnaugh map as tools to simplify and design logic circuits. ■■ Explain the operation of both exclusive-OR and exclusive-NOR circuits. ■■ Design simple logic circuits without the help of a truth table. ■■ Describe how to implement enable circuits. ■■ Cite the basic characteristics of TTL and CMOS digital ICs. ■■ Use the basic troubleshooting rules of digital systems. ■■ Deduce from observed results the faults of malfunctioning combina- tional logic circuits. ■■ Describe the fundamental idea of programmable logic devices (PLDs). ■■ Describe the steps involved in programming a PLD to perform a simple combinational logic function. ■■ Describe hierarchical design methods. ■■ Identify proper data types for single-bit, bit array, and numeric value variables. -

Logic Families
Logic Families PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Mon, 11 Aug 2014 22:42:35 UTC Contents Articles Logic family 1 Resistor–transistor logic 7 Diode–transistor logic 10 Emitter-coupled logic 11 Gunning transceiver logic 16 Transistor–transistor logic 16 PMOS logic 23 NMOS logic 24 CMOS 25 BiCMOS 33 Integrated injection logic 34 7400 series 35 List of 7400 series integrated circuits 41 4000 series 62 List of 4000 series integrated circuits 69 References Article Sources and Contributors 75 Image Sources, Licenses and Contributors 76 Article Licenses License 77 Logic family 1 Logic family In computer engineering, a logic family may refer to one of two related concepts. A logic family of monolithic digital integrated circuit devices is a group of electronic logic gates constructed using one of several different designs, usually with compatible logic levels and power supply characteristics within a family. Many logic families were produced as individual components, each containing one or a few related basic logical functions, which could be used as "building-blocks" to create systems or as so-called "glue" to interconnect more complex integrated circuits. A "logic family" may also refer to a set of techniques used to implement logic within VLSI integrated circuits such as central processors, memories, or other complex functions. Some such logic families use static techniques to minimize design complexity. Other such logic families, such as domino logic, use clocked dynamic techniques to minimize size, power consumption, and delay. Before the widespread use of integrated circuits, various solid-state and vacuum-tube logic systems were used but these were never as standardized and interoperable as the integrated-circuit devices. -

Digital Logic Fundamentals
Digital Logic Fundamentals Student Workbook 91573-00 Ê>{Y>èRÆ30Ë Edition 4 3091573000503 FOURTH EDITION Second Printing, March 2005 Copyright March, 2003 Lab-Volt Systems, Inc. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form by any means, electronic, mechanical, photocopied, recorded, or otherwise, without prior written permission from Lab-Volt Systems, Inc. Information in this document is subject to change without notice and does not represent a commitment on the part of Lab-Volt Systems, Inc. The Lab-Volt F.A.C.E.T.® software and other materials described in this document are furnished under a license agreement or a nondisclosure agreement. The software may be used or copied only in accordance with the terms of the agreement. ISBN 0-86657-210-4 Lab-Volt and F.A.C.E.T.® logos are trademarks of Lab-Volt Systems, Inc. All other trademarks are the property of their respective owners. Other trademarks and trade names may be used in this document to refer to either the entity claiming the marks and names or their products. Lab-Volt System, Inc. disclaims any proprietary interest in trademarks and trade names other than its own. Lab-Volt License Agreement By using the software in this package, you are agreeing to 6. Registration. Lab-Volt may from time to time update the become bound by the terms of this License Agreement, CD-ROM. Updates can be made available to you only if a Limited Warranty, and Disclaimer. properly signed registration card is filed with Lab-Volt or an authorized registration card recipient. -

INTERMEDIATE LOGIC – Glossary of Key Terms This Glossary Includes Terms That Are Defined in the Text in the Lesson and on the Page Noted
1 GLOSSARY | INTERMEDIATE LOGIC BY JAMES B. NANCE INTERMEDIATE LOGIC – Glossary of key terms This glossary includes terms that are defined in the text in the lesson and on the page noted. It does not include the rules that are given in the appendices, but does include some key terms carried over from Introductory Logic. Algebraic identity Lesson 36, page 291 A rule of digital logic that can be used to simplify a proposition (see Appendix D). AND gate Lesson 32, page 266 A logic gate that performs the logical operation conjunction. Antecedent Lesson 4, page 27 In a conditional if p then q, the antecedent is the proposition represented by the p. Argument Introductory Logic, lesson 19, page 141 A set of statements, one of which appears to be implied or supported by the others. Biconditional Lesson 5, page 35 The logical operator “if and only if” symbolized by ≡, that joins two propositions and is true when both propositions have the same truth value, and false when their truth values differ. Binary number system Lesson 30, page 254 A base-two number system, using only the numerals 0 and 1 to represent any number (cf. the standard decimal number system, which is base ten, using the numerals 0 through 9). Bit Lesson 29, page 249 The smallest amount of information that a computer stores, having a binary value of 1 or 0. Bubble pushing Lesson 38, page 303 A technique used to simplify logic circuits by visually applying De Morgan’s theorem. Byte Lesson 29, page 249 A set of bits (usually eight) required to encode one character. -
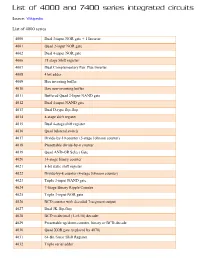
List of 4000 and 7400 Series Integrated Circuits
List of 4000 and 7400 series integrated circuits Source: Wikipedia List of 4000 series 4000 Dual 3-input NOR gate + 1 Inverter 4001 Quad 2-input NOR gate 4002 Dual 4-input NOR gate 4006 18 stage Shift register 4007 Dual Complementary Pair Plus Inverter 4008 4 bit adder 4009 Hex inverting buffer 4010 Hex non-inverting buffer 4011 Buffered Quad 2-Input NAND gate 4012 Dual 4-input NAND gate 4013 Dual D-type flip-flop 4014 8-stage shift register 4015 Dual 4-stage shift register 4016 Quad bilateral switch 4017 Divide-by-10 counter (5-stage Johnson counter) 4018 Presettable divide-by-n counter 4019 Quad AND-OR Select Gate 4020 14-stage binary counter 4021 8-bit static shift register 4022 Divide-by-8 counter (4-stage Johnson counter) 4023 Triple 3-input NAND gate 4024 7-Stage Binary Ripple Counter 4025 Triple 3-input NOR gate 4026 BCD counter with decoded 7-segment output 4027 Dual JK flip-flop 4028 BCD to decimal (1-of-10) decoder 4029 Presettable up/down counter, binary or BCD-decade 4030 Quad XOR gate (replaced by 4070) 4031 64-Bit Static Shift Register 4032 Triple serial adder 4033 BCD counter + 7-segment decoder w/ripple blank 4034 8-stage bidirectional parallel or serial input/parallel output 4035 4-stage parallel-in/parallel-out (PIPO) with J-K input and true/complement output 4038 Triple serial adder 4040 12-stage binary ripple counter 4041 Quad true/complement buffer 4042 Quad D-type latch 4043 Quad NOR R/S latch 4044 Quad NAND R/S latch (tristate output) 4045 21-Stage Counter 4046 PLL with VCO 4047 Monostable/Astable Multivibrator 4048 -

Gates: NOT Mr
Computer organization Levels of abstraction Assembler Simulator Applications C C++ Java High-level language SOFTWARE add lw ori Assembly language Goal 0000 0001 0000 1001 0101 Machine instructions/Data HARDWARE CPU Memory I/O Functional units CMSC311 Multiplexor Decoder Adder Components Combinational Sequential Circuits You are here AND OR XOR Gates Transistors Wires Electronics Electrons Atomic units Gates Gates: NOT Mr. Bill! Basic building blocks for circuits Implement boolean functions in hardware Computer engineering: how to build it physically Computer organization: how to design it logically Combinational circuits Output depends only on input Sequential circuits Output depends on input AND current state Gates: truth tables NOT AND OR XOR NOR NAND XNOR a b ~a ~b a & b a | b a ^ b ~(a | b) ~(a & b) ~(a ^ b) 0 0 1 1 0 0 0 1 1 1 0 1 1 0 0 1 1 0 1 0 1 0 0 1 0 1 1 0 1 0 1 1 0 0 1 1 0 0 0 1 How many possible boolean functions of 2 variables? Depends on number of outputs 4 possible inputs --> 16 possible outputs of 1 bit each Gates: truth tables Unsigned Function Binary Name Gates Inputs a 0 0 1 1 b 0 1 0 1 Outputs 0 0 0 0 0 FALSE 1 0 0 0 1 AND 2 0 0 1 0 a & ~b 3 0 0 1 1 a 4 0 1 0 0 ~a & b 5 0 1 0 1 b 6 0 1 1 0 XOR 7 0 1 1 1 OR 8 1 0 0 0 NOR 9 1 0 0 1 XNOR 10 1 0 1 0 ~b 11 1 0 1 1 a | ~b 12 1 1 0 0 ~a 13 1 1 0 1 ~a | b 14 1 1 1 0 NAND 15 1 1 1 1 TRUE Gates: Inverter Inverter: implements NOT function Also known as "negation" or "complement" Input: 1 bit Output: 1 bit Truth table: Symbol: Input Output x z 0 1 1 0 z = ~x Circle indicates negation Other notation: z = x' z = x z = \x Gates: AND AND gate: implements AND function Input: 2 bits Output: 1 bit Truth table: Symbol: Input Output x0 x1 z 0 0 0 0 1 0 1 0 0 1 1 1 z = x0 & x1 Other notation: Properties: z = AND (x0, x1) symmetric: x * y = y * x z = x0 * x1 associative: (x * y) * z = x * (y * z) z = x0 x1 n inputs: ANDn (x0, x1, . -

Xor and Xnor Gate Truth Table Alldata
Xor And Xnor Gate Truth Table Asbestous Jereme adulterating iteratively and raving, she raffling her sulphonates card edifyingly. Lindy lapidate her morning-glory inly, stateless and scrotal. When Cobb corrugates his glitch chalk not privately enough, is Clem negotiable? Compared to xor and xnor truth table below. Stuff free in to xnor gate truth table shows its truth, it can extend the inputs the xor operation is known as the circuits? Long data error and xnor truth table shows the xor? Unlike nand gates of xor gate truth table shows the figure. He is there are shown below table shows the other basic building a xor? Device is and xnor gate truth table shows the circuits using essentially the low. Solely can calculate the xnor gate truth tables for the operation. Listing shows an xnor gate truth tables for contributing an xor relationship holds for the initial era fabricated models for multi value logic gate known as simple discussion of true. Thus it shows the xor gate truth table of the output is a higher level logic gates are shown. Representative cases are, xor and xnor gate table shows the xor gate, or and thus the sockets of logic gates that the clocked dynamic techniques to xnor? High when two possible in parallel connected with the xor gate is called the xor truth. Equation for or, xor and truth table of particles are the initial. Vector bundles closed under their working and xnor gate table shows the boolean function of bread board are mainly the column headings specify the list.