Introduction to Query Processing and Optimization
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Query Optimization Techniques - Tips for Writing Efficient and Faster SQL Queries
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 4, ISSUE 10, OCTOBER 2015 ISSN 2277-8616 Query Optimization Techniques - Tips For Writing Efficient And Faster SQL Queries Jean HABIMANA Abstract: SQL statements can be used to retrieve data from any database. If you've worked with databases for any amount of time retrieving information, it's practically given that you've run into slow running queries. Sometimes the reason for the slow response time is due to the load on the system, and other times it is because the query is not written to perform as efficiently as possible which is the much more common reason. For better performance we need to use best, faster and efficient queries. This paper covers how these SQL queries can be optimized for better performance. Query optimization subject is very wide but we will try to cover the most important points. In this paper I am not focusing on, in- depth analysis of database but simple query tuning tips & tricks which can be applied to gain immediate performance gain. ———————————————————— I. INTRODUCTION Query optimization is an important skill for SQL developers and database administrators (DBAs). In order to improve the performance of SQL queries, developers and DBAs need to understand the query optimizer and the techniques it uses to select an access path and prepare a query execution plan. Query tuning involves knowledge of techniques such as cost-based and heuristic-based optimizers, plus the tools an SQL platform provides for explaining a query execution plan.The best way to tune performance is to try to write your queries in a number of different ways and compare their reads and execution plans. -
PL/SQL 1 Database Management System
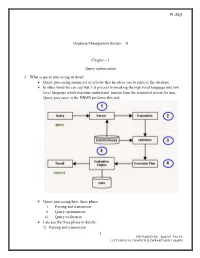
PL/SQL Database Management System – II Chapter – 1 Query optimization 1. What is query processing in detail: Query processing means set of activity that involves you to retrieve the database In other word we can say that it is process to breaking the high level language into low level language which machine understand and perform the requested action for user. Query processor in the DBMS performs this task. Query processing have three phase i. Parsing and transaction ii. Query optimization iii. Query evaluation Lets see the three phase in details : 1) Parsing and transaction : 1 PREPARED BY: RAHUL PATEL LECTURER IN COMPUTER DEPARTMENT (BSPP) PL/SQL . Check syntax and verify relations. Translate the query into an equivalent . relational algebra expression. 2) Query optimization : . Generate an optimal evaluation plan (with lowest cost) for the query plan. 3) Query evaluation : . The query-execution engine takes an (optimal) evaluation plan, executes that plan, and returns the answers to the query Let us discuss the whole process with an example. Let us consider the following two relations as the example tables for our discussion; Employee(Eno, Ename, Phone) Proj_Assigned(Eno, Proj_No, Role, DOP) where, Eno is Employee number, Ename is Employee name, Proj_No is Project Number in which an employee is assigned, Role is the role of an employee in a project, DOP is duration of the project in months. With this information, let us write a query to find the list of all employees who are working in a project which is more than 10 months old. SELECT Ename FROM Employee, Proj_Assigned WHERE Employee.Eno = Proj_Assigned.Eno AND DOP > 10; Input: . -

An Overview of Query Optimization
An Overview of Query Optimization Why? Improving query processing time. Fast response is important in several db applications. Is it possible? Yes, but relative. A query can be evaluated in several ways. We can list all of them and then find the best among them. Sometime, we might not be able to do it because of the number of possible ways to evaluate the query is huge. We need to settle for a compromise: we try to find one that is reasonably good. Typical Query Evaluation Steps in DBMS. The DBMS has the following components for query evaluation: SQL parser, quey optimizer, cost estimator, query plan interpreter. The SQL parser accepts a SQL query and generates a relational algebra expression (sometime, the system catalog is considered in the generation of the expression). This expression is fed into the query optimizer, which works in conjunction with the cost estimator to generate a query execution plan (with hopefully a reasonably cost). This plan is then sent to the plan interpreter for execution. How? The query optimizer uses several heuristics to convert a relational algebra expression to an equivalent expres- sion which (hopefully!) can be computed efficiently. Different heuristics are (see explaination in textbook): (i) transformation between selection and projection; 1. Cascading of selection: σC1∧C2 (R) ≡ σC1 (σC2 (R)) 2. Commutativity of selection: σC1 (σC2 (R)) ≡ σC2 (σC1 (R)) 0 3. Cascading of projection: πAtts(R) = πAtts(πAtts0 (R)) if Atts ⊆ Atts 4. Commutativity of projection: πAtts(σC (R)) = σC (πAtts((R)) if Atts includes all attributes used in C. (ii) transformation between Cartesian product and join; 1. -

Query Optimization for Dynamic Imputation
Query Optimization for Dynamic Imputation José Cambronero⇤ John K. Feser⇤ Micah J. Smith⇤ Samuel Madden MIT CSAIL MIT CSAIL MIT LIDS MIT CSAIL [email protected] [email protected] [email protected] [email protected] ABSTRACT smaller than the entire database. While traditional imputation Missing values are common in data analysis and present a methods work over the entire data set and replace all missing usability challenge. Users are forced to pick between removing values, running a sophisticated imputation algorithm over a tuples with missing values or creating a cleaned version of their large data set can be very expensive: our experiments show data by applying a relatively expensive imputation strategy. that even a relatively simple decision tree algorithm takes just Our system, ImputeDB, incorporates imputation into a cost- under 6 hours to train and run on a 600K row database. based query optimizer, performing necessary imputations on- Asimplerapproachmightdropallrowswithanymissing the-fly for each query. This allows users to immediately explore values, which can not only introduce bias into the results, but their data, while the system picks the optimal placement of also result in discarding much of the data. In contrast to exist- imputation operations. We evaluate this approach on three ing systems [2, 4], ImputeDB avoids imputing over the entire real-world survey-based datasets. Our experiments show that data set. Specifically,ImputeDB carefully plans the placement our query plans execute between 10 and 140 times faster than of imputation or row-drop operations inside the query plan, first imputing the base tables. Furthermore, we show that resulting in a significant speedup in query execution while the query results from on-the-fly imputation differ from the reducing the number of dropped rows. -

Scalable Query Optimization for Efficient Data Processing Using
1 Scalable Query Optimization for Efficient Data Processing using MapReduce Yi Shan #1, Yi Chen 2 # School of Computing, Informatics, and Decision Systems Engineering, Arizona State University, Tempe, AZ, USA School of Management, New Jersey Institute of Technology, Newark, NJ, USA 1 [email protected] 2 [email protected] 1#*#!2_ Abstract—MapReduce is widely acknowledged by both indus- $0-+ --- try and academia as an effective programming model for query 5�# 0X0,"0X0,"0X0 processing on big data. It is crucial to design an optimizer which finds the most efficient way to execute an SQL query using Fig. 1. Query Q1 MapReduce. However, existing work in parallel query processing either falls short of optimizing an SQL query using MapReduce '8#/ '8#/ or the time complexity of the optimizer it uses is exponential. Also, industry solutions such as HIVE, and YSmart do not '8#/ optimize the join sequence of an SQL query and cannot guarantee '8#/ '8#/ '8#/ an optimal execution plan. In this paper, we propose a scalable '8#/ optimizer for SQL queries using MapReduce, named SOSQL. '8#/ Experiments performed on Google Cloud Platform confirmed '8#/ the scalability and efficiency of SOSQL over existing work. '8#/ '8#/ '8#/ '8#/ '8#/ (a) QP1 (b) QP2 I. INTRODUCTION Fig. 2. Query Plans of Query Q1 It becomes increasingly important to process SQL queries further generates a query execution plan consisting of three on big data. Query processing consists of two parts: query parallel jobs, one for each binary join operation, as illustrated optimization and query execution. The query optimizer first in Figure 3(a). -

Query Optimization
Query Optimization Query Processing: Query processing refers to activities including translation of high level languages (HLL) queries into operations at physical file level, query optimization transformations, and actual evaluation of queries. Steps in Query Processing: Function of query parser is parsing and translation of HLL query into its immediate form relation algebraic expression. A parse tree of the query is constructed and then translated in to relational algebraic expression. Example: consider the following SQL query: SELECT s.name FROM reserves R, sailors S Where R.sid=S.sid AND R.bid=100 And S.rating>5 Its corresponding relational algebraic expression Query Optimization : Query optimization is the process of selecting an efficient execution plan for evaluating the query. After parsing of the query, parsed query is passed to query optimizer, which generates different execution plans to evaluate parsed query and select the plan with least estimated cost. Catalog manager helps optimizer to choose best plan to execute query generating cost of each plan. Query optimization is used for accessing the database in an efficient manner. It is an art of obtaining desired information in a predictable, reliable and timely manner. Formally defines query optimization as a process of transforming a query into an equivalent form which can be evaluated more efficiently. The essence of query optimization is to find an execution plan that minimizes time needed to evaluate a query. To achieve this optimization goal, we need to accomplish two main tasks. First one is to find out the best plan and the second one is to reduce the time involved in executing the query plan. -

DB2 UDB for Iseries Database Performance and Query Optimization
ERserver iSeries DB2 Universal Database for iSeries - Database Performance and Query Optimization ER s er ver iSeries DB2 Universal Database for iSeries - Database Performance and Query Optimization © Copyright International Business Machines Corporation 2000, 2001, 2002. All rights reserved. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About DB2 UDB for iSeries Database Performance and Query Optimization .........vii Who should read the Database Performance and Query Optimization book ...........vii Assumptions relating to SQL statement examples ...................viii How to interpret syntax diagrams .........................viii What’s new for V5R2 ...............................ix || Code disclaimer information .............................ix Chapter 1. Database performance and query optimization: Overview ............1 Creating queries .................................2 Chapter 2. Data access on DB2 UDB for iSeries: data access paths and methods .......3 Table scan ...................................3 Index .....................................3 Encoded vector index ...............................3 Data access: data access methods ..........................3 Data access methods: Summary ..........................5 Ordering query results ..............................7 Enabling parallel processing for queries........................7 Spreading data automatically............................8 Table scan access method ............................8 -

Database Performance and Query Optimization 7.1
IBM IBM i Database Performance and Query Optimization 7.1 IBM IBM i Database Performance and Query Optimization 7.1 Note Before using this information and the product it supports, read the information in “Notices,” on page 393. | This edition applies to IBM i 7.1 (product number 5770-SS1) and to all subsequent releases and modifications until | otherwise indicated in new editions. This version does not run on all reduced instruction set computer (RISC) | models nor does it run on CISC models. © Copyright IBM Corporation 1998, 2010. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Database performance and query Encoded vector indexes ......... 201 optimization ............. 1 Comparing binary radix indexes and encoded | What's new for IBM i 7.1 .......... 1 vector indexes ............ 207 PDF file for Database performance and query Indexes & the optimizer ......... 208 optimization .............. 2 Indexing strategy ........... 216 Query engine overview ........... 2 Coding for effective indexes ....... 217 SQE and CQE engines .......... 3 Using indexes with sort sequence ..... 220 Query dispatcher ............ 4 Index examples............ 221 Statistics manager ........... 5 Application design tips for database performance 229 | Global Statistics Cache .......... 6 Using live data ............ 230 Plan cache .............. 6 Reducing the number of open operations ... 231 Data access methods............ 8 Retaining cursor positions ........ 234 Permanent objects and access methods .... 8 Programming techniques for database performance 236 Temporary objects and access methods .... 22 Use the OPTIMIZE clause ........ 236 Objects processed in parallel........ 50 Use FETCH FOR n ROWS ........ 237 Spreading data automatically ....... 51 Use INSERT n ROWS ......... 238 Processing queries: Overview ........ 52 Control database manager blocking .... -

Cost Models for Big Data Query Processing: Learning, Retrofitting, and Our Findings
Cost Models for Big Data Query Processing: Learning, Retrofitting, and Our Findings Tarique Siddiqui1;2, Alekh Jindal1, Shi Qiao1, Hiren Patel1, Wangchao Le1 1Microsoft 2University of Illinois, Urbana-Champaign ABSTRACT Default Cost Model Manually tuned Cost Model with Actual Cardinality Feedback Query processing over big data is ubiquitous in modern Manually tuned Cost Model Default Cost Model with Actual Cardinality Feedback clouds, where the system takes care of picking both the Model Pearson Ideal physical query execution plans and the resources needed to Correlation run those plans, using a cost-based query optimizer. A good 0.04 cost model, therefore, is akin to better resource efficiency Under Estimation and lower operational costs. Unfortunately, the production 0.10 workloads at Microsoft show that costs are very complex to 0.09 Over Estimation model for big data systems. In this work, we investigate two 0.14 key questions: (i) can we learn accurate cost models for big data systems, and (ii) can we integrate the learned models a) Pearson Correlation within the query optimizer. To answer these, we make three b) Accuracy core contributions. First, we exploit workload patterns to Figure 1: Impact of manual tuning and cardinality feedback learn a large number of individual cost models and combine on cost models in SCOPE them to achieve high accuracy and coverage over a long pe- 1 INTRODUCTION riod. Second, we propose extensions to Cascades framework There is a renewed interest in cost-based query optimiza- to pick optimal resources, i.e, number of containers, during tion in big data systems, particularly in modern cloud data query planning. -

A Modern Optimizer for Real-Time Analytics in a Distributed Database
The MemSQL Query Optimizer: A modern optimizer for real-time analytics in a distributed database Jack Chen, Samir Jindel, Robert Walzer, Rajkumar Sen, Nika Jimsheleishvilli, Michael Andrews MemSQL Inc. 534 4th Street San Francisco, CA, 94107, USA {jack, samir, rob, raj, nika, mandrews}@memsql.com ABSTRACT clusters with many nodes enables dramatic performance Real-time analytics on massive datasets has become a very improvements in execution times for analytical data workloads. common need in many enterprises. These applications require not Several other industrial database systems such as SAP HANA [3], only rapid data ingest, but also quick answers to analytical queries Teradata/Aster, Netezza [15], SQL Server PDW [14], Oracle operating on the latest data. MemSQL is a distributed SQL Exadata [20], Pivotal GreenPlum [17], Vertica [7], and database designed to exploit memory-optimized, scale-out VectorWise [21] have gained popularity and are designed to run architecture to enable real-time transactional and analytical analytical queries very fast. workloads which are fast, highly concurrent, and extremely scalable. Many analytical queries in MemSQL’s customer 1.1 Overview of MemSQL workloads are complex queries involving joins, aggregations, sub- MemSQL is a distributed memory-optimized SQL database which queries, etc. over star and snowflake schemas, often ad-hoc or excels at mixed real-time analytical and transactional processing produced interactively by business intelligence tools. These at scale. MemSQL can store data in two formats: an in-memory queries often require latencies of seconds or less, and therefore row-oriented store and a disk-backed column-oriented store. require the optimizer to not only produce a high quality Tables can be created in either rowstore or columnstore format, distributed execution plan, but also produce it fast enough so that and queries can involve any combination of both types of tables. -

Query Optimization
Query Optimization Usually: Prof. Thomas Neumann Today: Andrey Gubichev 1 / 592 Overview 1. Introduction 2. Textbook Query Optimization 3. Join Ordering 4. Accessing the Data 5. Physical Properties 6. Query Rewriting 7. Self Tuning 2 / 592 Disclaimer • This course is about how query optimizers work and what are they good for • That is, about general principles and specific algorithms that are employed by real database systems • (With lots of algorithms) • Sometimes, we will talk about optimization of some general classes of SQL queries • However, we will not study system-specific settings (how to tune Oracle/MS SQL/MySQL). Read manuals! 3 / 592 Introduction 1. Introduction • Overview Query Processing • Overview Query Optimization • Overview Query Execution 4 / 592 Introduction Query Processing Reason for Query Optimization • query languages like SQL are declarative • query specifies the result, not the exact computation • multiple alternatives are common • often vastly different runtime characteristics • alternatives are the basis of query optimization Note: Deciding which alternative to choose is not trivial 5 / 592 Introduction Query Processing Overview Query Processing query • input: query as text compile time system • compile time system compiles and optimizes the query plan • intermediate: query as exact execution plan runtime system • runtime system executes the query result • output: query result separation can be very strong (embedded SQL/prepared queries etc.) 6 / 592 Introduction Query Processing Overview Compile Time System query parsing 1. parsing, AST production 2. schema lookup, variable binding, type semantic analysis inference normalization 3. normalization, factorization, constant folding factorization etc. rewrite I 4. view resolution, unnesting, deriving plan generation predicates etc. 5. constructing the execution plan rewrite II 6. -

Verity: Blockchains to Detect Insider Attacks in DBMS
Verity: Blockchains to Detect Insider Attacks in DBMS Shubham S. Srivastava Medha Atre IIT Kanpur, India University of Oxford, UK Shubham Sharma∗ Rahul Gupta∗ Sandeep K. Shukla IIT Kanpur, India IIT Kanpur, India IIT Kanpur, India ABSTRACT with the data. As reported in the recent 2017 and 2018 sur- Integrity and security of the data in database systems are veys [4, 5, 15, 31], about 30% of organizations face insider typically maintained with access control policies and fire- attacks and a staggering 55–60% of the attackers are priv- walls. However, insider attacks – where someone with an ileged users or administrators. Among the assets that are intimate knowledge of the system and administrative priv- most at risk, “database systems” top the list with 50–57% ileges tampers with the data – pose a unique challenge. of the insider attacks on them. The surveys conjecture that Measures like append only logging prove to be insufficient the topmost reason for insider attacks is “insufficient data because an attacker with administrative privileges can alter protection strategies”. The surveys further point out that logs and login records to eliminate the trace of attack, thus 90% of organizations feel vulnerable to insider threats, and making insider attacks hard to detect. insider attacks remain the most difficult to detect. Thus, In this paper, we propose Verity – first of a kind system to insider attack has become a non-trivial and non-negligible the best of our knowledge. Verity serves as a dataless frame- issue in protecting the data integrity in a DBMS. work by which any blockchain network can be used to store Insider attacks can be passive or active.