IBM Db2 – the AI Database
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Query Optimization Techniques - Tips for Writing Efficient and Faster SQL Queries
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 4, ISSUE 10, OCTOBER 2015 ISSN 2277-8616 Query Optimization Techniques - Tips For Writing Efficient And Faster SQL Queries Jean HABIMANA Abstract: SQL statements can be used to retrieve data from any database. If you've worked with databases for any amount of time retrieving information, it's practically given that you've run into slow running queries. Sometimes the reason for the slow response time is due to the load on the system, and other times it is because the query is not written to perform as efficiently as possible which is the much more common reason. For better performance we need to use best, faster and efficient queries. This paper covers how these SQL queries can be optimized for better performance. Query optimization subject is very wide but we will try to cover the most important points. In this paper I am not focusing on, in- depth analysis of database but simple query tuning tips & tricks which can be applied to gain immediate performance gain. ———————————————————— I. INTRODUCTION Query optimization is an important skill for SQL developers and database administrators (DBAs). In order to improve the performance of SQL queries, developers and DBAs need to understand the query optimizer and the techniques it uses to select an access path and prepare a query execution plan. Query tuning involves knowledge of techniques such as cost-based and heuristic-based optimizers, plus the tools an SQL platform provides for explaining a query execution plan.The best way to tune performance is to try to write your queries in a number of different ways and compare their reads and execution plans. -

IBM Developer for Z/OS Enterprise Edition
Solution Brief IBM Developer for z/OS Enterprise Edition A comprehensive, robust toolset for developing z/OS applications using DevOps software delivery practices Companies must be agile to respond to market demands. The digital transformation is a continuous process, embracing hybrid cloud and the Application Program Interface (API) economy. To capitalize on opportunities, businesses must modernize existing applications and build new cloud native applications without disrupting services. This transformation is led by software delivery teams employing DevOps practices that include continuous integration and continuous delivery to a shared pipeline. For z/OS Developers, this transformation starts with modern tools that empower them to deliver more, faster, with better quality and agility. IBM Developer for z/OS Enterprise Edition is a modern, robust solution that offers the program analysis, edit, user build, debug, and test capabilities z/OS developers need, plus easy integration with the shared pipeline. The challenge IBM z/OS application development and software delivery teams have unique challenges with applications, tools, and skills. Adoption of agile practices Application modernization “DevOps and agile • Mainframe applications • Applications require development on the platform require frequent updates access to digital services have jumped from the early adopter stage in 2016 to • Development teams must with controlled APIs becoming common among adopt DevOps practices to • The journey to cloud mainframe businesses”1 improve their -
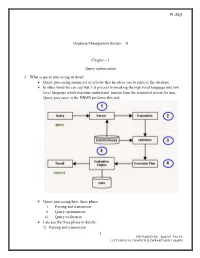
PL/SQL 1 Database Management System
PL/SQL Database Management System – II Chapter – 1 Query optimization 1. What is query processing in detail: Query processing means set of activity that involves you to retrieve the database In other word we can say that it is process to breaking the high level language into low level language which machine understand and perform the requested action for user. Query processor in the DBMS performs this task. Query processing have three phase i. Parsing and transaction ii. Query optimization iii. Query evaluation Lets see the three phase in details : 1) Parsing and transaction : 1 PREPARED BY: RAHUL PATEL LECTURER IN COMPUTER DEPARTMENT (BSPP) PL/SQL . Check syntax and verify relations. Translate the query into an equivalent . relational algebra expression. 2) Query optimization : . Generate an optimal evaluation plan (with lowest cost) for the query plan. 3) Query evaluation : . The query-execution engine takes an (optimal) evaluation plan, executes that plan, and returns the answers to the query Let us discuss the whole process with an example. Let us consider the following two relations as the example tables for our discussion; Employee(Eno, Ename, Phone) Proj_Assigned(Eno, Proj_No, Role, DOP) where, Eno is Employee number, Ename is Employee name, Proj_No is Project Number in which an employee is assigned, Role is the role of an employee in a project, DOP is duration of the project in months. With this information, let us write a query to find the list of all employees who are working in a project which is more than 10 months old. SELECT Ename FROM Employee, Proj_Assigned WHERE Employee.Eno = Proj_Assigned.Eno AND DOP > 10; Input: . -

An Overview of Query Optimization
An Overview of Query Optimization Why? Improving query processing time. Fast response is important in several db applications. Is it possible? Yes, but relative. A query can be evaluated in several ways. We can list all of them and then find the best among them. Sometime, we might not be able to do it because of the number of possible ways to evaluate the query is huge. We need to settle for a compromise: we try to find one that is reasonably good. Typical Query Evaluation Steps in DBMS. The DBMS has the following components for query evaluation: SQL parser, quey optimizer, cost estimator, query plan interpreter. The SQL parser accepts a SQL query and generates a relational algebra expression (sometime, the system catalog is considered in the generation of the expression). This expression is fed into the query optimizer, which works in conjunction with the cost estimator to generate a query execution plan (with hopefully a reasonably cost). This plan is then sent to the plan interpreter for execution. How? The query optimizer uses several heuristics to convert a relational algebra expression to an equivalent expres- sion which (hopefully!) can be computed efficiently. Different heuristics are (see explaination in textbook): (i) transformation between selection and projection; 1. Cascading of selection: σC1∧C2 (R) ≡ σC1 (σC2 (R)) 2. Commutativity of selection: σC1 (σC2 (R)) ≡ σC2 (σC1 (R)) 0 3. Cascading of projection: πAtts(R) = πAtts(πAtts0 (R)) if Atts ⊆ Atts 4. Commutativity of projection: πAtts(σC (R)) = σC (πAtts((R)) if Atts includes all attributes used in C. (ii) transformation between Cartesian product and join; 1. -

About the Author
ABOUT THE AUTHOR Dr. Arvind Sathi is the World Wide Communication Sector archi- tect for big data at IBM® . Dr. Sathi received his Ph.D. in business administration from Carnegie Mellon University and worked under Nobel Prize winner Dr. Herbert A. Simon. Dr. Sathi is a seasoned professional with more than 20 years of leadership in information management architecture and delivery. His primary focus has been in creating visions and roadmaps for advanced analytics at lead- ing IBM clients in telecommunications, media and entertainment, and energy and utilities organizations worldwide. He has con- ducted a number of workshops on big data assessment and roadmap development. Prior to joining IBM, Dr. Sathi was a pioneer in d eveloping k nowledge-based solutions for CRM at Carnegie Group. At BearingPoint, he led the development of enterprise integration, master data man- agement (MDM), and operations support systems / business support systems (OSS/BSS) solutions for the communications market, and also developed horizontal solutions for communications, fi nancial services, and public services. At IBM, Dr. Sathi has led several infor- mation management programs in MDM, data security, business intel- ligence, advanced analytics, big data, and related areas, and provided strategic architecture oversight to IBM’s strategic accounts. He has also delivered a number of workshops and presentations at industry con- ferences on technical subjects, including MDM and data architecture, 202 ABOUT THE AUTHOR and he holds two patents in data masking. His fi rst book, Customer Experience Analytics , was released by MC Press in October 2011, and his second book, Big Data Analytics , was released in October 2012. -

Interconnect 2017 IBM Watson Iot Journey
IBM Watson IoT InterConnect Journey Map 2017 March 19 – 23 MGM Grand & Mandalay Bay Las Vegas, Nevada It all adds up! This is the conference you cannot afford to miss. 3 2/17/2017 The most influential thinkers, leaders, and innovators will join Ginni Rometty and IBM’s greatest minds to show you everything you need to know about cloud. Amy Wilkinson Bruce Schneier Dr. Sabine Hauert Mike McAvoy Prof Nick Jennings CEO of Ingenuity, Professor at Security Expert and CTO, President and Co-Founder President and CEO – Onion, Inc., CB FREng, Stanford Business School, Resilient of Robohub.org, Asst. Prof in EVP of Sales – Fusion Media Vice-Provost (Research), Author of The Creator's Code Robotics at Univ of Bristol Group (FMG) Imperial College London Adrian Gropper Don Tapscott Wayne Brady Daniel Hoffman Robert S. Mueller III, Former MD CTO, Patient Privacy Co-author, Emmy Winning Actor, Singer, Former Intelligence Officer, CIA Director, FBI and Partner, Rights Foundation Blockchain Revolution Dancer, Comedian, and WilmerHale Cyberbullying Activist 4 Asset Management Keynotes & Sessions This guide provides the comprehensive view of Asset Management journey at 2017 InterConnect. Review the complete sessions and build your personalized agenda with the Watson Sessions Expert Tool. Asset Management Keynotes & Sessions Time Session Title Location Sunday, March 19 Facilities Management Maximo Users Group 13:00 - 13:30 IAB-4388 Facilities MUG: Facilities Management Maximo User Group Business Meeting Mandalay Bay North, Level 0-South Pacific D 13:30 - 14:15 -
Introduction to Query Processing and Optimization
Introduction to Query Processing and Optimization Michael L. Rupley, Jr. Indiana University at South Bend [email protected] owned_by 10 No ABSTRACT All database systems must be able to respond to The drivers relation: requests for information from the user—i.e. process Attribute Length Key? queries. Obtaining the desired information from a driver_id 10 Yes database system in a predictable and reliable fashion is first_name 20 No the scientific art of Query Processing. Getting these last_name 20 No results back in a timely manner deals with the age 2 No technique of Query Optimization. This paper will introduce the reader to the basic concepts of query processing and query optimization in the relational The car_driver relation: database domain. How a database processes a query as Attribute Length Key? well as some of the algorithms and rule-sets utilized to cd_car_name 15 Yes* produce more efficient queries will also be presented. cd_driver_id 10 Yes* In the last section, I will discuss the implementation plan to extend the capabilities of my Mini-Database Engine program to include some of the query 2. WHAT IS A QUERY? optimization techniques and algorithms covered in this A database query is the vehicle for instructing a DBMS paper. to update or retrieve specific data to/from the physically stored medium. The actual updating and 1. INTRODUCTION retrieval of data is performed through various “low-level” operations. Examples of such operations Query processing and optimization is a fundamental, if for a relational DBMS can be relational algebra not critical, part of any DBMS. To be utilized operations such as project, join, select, Cartesian effectively, the results of queries must be available in product, etc. -

High Performance Computing Toolkit: Installation and Usage Guide | Appendix B
IBM Parallel Environment Developer Edition High Performance Computing Toolkit Version 2 Release 1 Installation and Usage Guide SC23-7287-00 IBM Parallel Environment Developer Edition High Performance Computing Toolkit Version 2 Release 1 Installation and Usage Guide SC23-7287-00 Note Before using this information and the product it supports, read the information in “Notices” on page 255. This edition applies to version 2, release 1, modification 0 of the IBM Parallel Environment Developer Edition High Performance Computing Toolkit (HPC Toolkit) (product number 5765-PD2) and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright IBM Corporation 2008, 2014. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Figures ..............vii | Part 3. Using the IBM PE Developer | Edition graphical performance Tables ...............ix || analysis tools ...........21 About this information ........xi | Chapter 6. Using the hpctView Who should read this information .......xi Conventions and terminology used in this || application .............23 information ..............xi || Preparing an application for analysis ......24 Prerequisite and related information ......xii || Working with the application ........25 Parallel Tools Platform component .....xii || Opening the application executable ......25 How to send your comments ........xiii || Instrumenting the application ........28 || Running the instrumented application .....29 Summary of changes ........xv || Viewing performance data .........37 | Chapter 7. Using hardware Limitations and restrictions .....xvii || performance counter profiling.....41 || Preparing an application for profiling......41 Part 1. Introduction .........1 || Instrumenting the application ........41 || Running the instrumented application .....43 Chapter 1. Introduction to the IBM HPC || Viewing hardware performance counter data . 45 Toolkit ...............3 IBM PE Developer Edition components .....3 || Chapter 8. -

Query Optimization for Dynamic Imputation
Query Optimization for Dynamic Imputation José Cambronero⇤ John K. Feser⇤ Micah J. Smith⇤ Samuel Madden MIT CSAIL MIT CSAIL MIT LIDS MIT CSAIL [email protected] [email protected] [email protected] [email protected] ABSTRACT smaller than the entire database. While traditional imputation Missing values are common in data analysis and present a methods work over the entire data set and replace all missing usability challenge. Users are forced to pick between removing values, running a sophisticated imputation algorithm over a tuples with missing values or creating a cleaned version of their large data set can be very expensive: our experiments show data by applying a relatively expensive imputation strategy. that even a relatively simple decision tree algorithm takes just Our system, ImputeDB, incorporates imputation into a cost- under 6 hours to train and run on a 600K row database. based query optimizer, performing necessary imputations on- Asimplerapproachmightdropallrowswithanymissing the-fly for each query. This allows users to immediately explore values, which can not only introduce bias into the results, but their data, while the system picks the optimal placement of also result in discarding much of the data. In contrast to exist- imputation operations. We evaluate this approach on three ing systems [2, 4], ImputeDB avoids imputing over the entire real-world survey-based datasets. Our experiments show that data set. Specifically,ImputeDB carefully plans the placement our query plans execute between 10 and 140 times faster than of imputation or row-drop operations inside the query plan, first imputing the base tables. Furthermore, we show that resulting in a significant speedup in query execution while the query results from on-the-fly imputation differ from the reducing the number of dropped rows. -

Program Directory for IBM Enterprise COBOL for Z/OS
IBM Program Directory for IBM Enterprise COBOL for z/OS V06.02.00 Program Number 5655-EC6 FMIDs HADB620, JADB621, JADB622, JADB62H for Use with z/OS Document Date: September 2017 GI13-4526-01 Note Before using this information and the product it supports, be sure to read the general information under 7.0, “Notices” on page 30. © Copyright International Business Machines Corporation 1991, 2017. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents 1.0 Introduction . 1 1.1 Enterprise COBOL Description ......................................... 1 1.2 Enterprise COBOL FMIDs ........................................... 4 2.0 Program Materials . 5 2.1 Basic Machine-Readable Material ....................................... 5 2.2 Optional Machine-Readable Material ..................................... 6 2.3 Program Publications . 6 2.3.1 Optional Program Publications ...................................... 7 2.4 Program Source Materials ........................................... 7 2.5 Publications Useful During Installation .................................... 7 3.0 Program Support . 8 3.1 Program Services . 8 3.2 Preventive Service Planning .......................................... 8 3.3 Statement of Support Procedures ....................................... 9 4.0 Program and Service Level Information ................................. 10 4.1 Program Level Information .......................................... 10 4.2 Service Level Information .......................................... -

DB2 Product Overview
PH061-Martineau.book Page 3 Wednesday, August 6, 2003 7:40 PM C HAPTER 1 DB2 Product Overview he relational database of choice for modern distributed applications is IBM’s DB2 Univer- T sal Database(UDB). Relational databases form the core backend of most enterprise scale applications because of their capability to deliver high performance, support advanced features such as transactions, and maintain data integrity. The Structured Query Language (SQL) provides a powerful standard for accessing and manipulating databases. Its widespread acceptance across all major vendors has also contributed to the success of relational database technology. This chapter introduces major DB2 products so that you can plan the products required for your environment. This is a key to planning the DB2 UDB solution, as shown in Figure 1.1, that is suitable for your project or your organization. OBJECTIVES After reading this chapter you should have an understanding of the following DB2 UDB products: • DB2 UDB Server Products ° DB2 UDB Enterprise Server Edition (ESE) ° DB2 UDB Workgroup Server Edition (WSE) ° DB2 UDB Workgroup Server Unlimited Edition (WSUE) • DB2 UDB Personal Edition (PE) • DB2 UDB Developer’s Products ° DB2 UDB Personal Developer’s Edition ° DB2 UDB Universal Developer’s Edition • DB2 UDB Connect Products ° DB2 UDB Connect Enterprise Edition ° DB2 UDB Connect Unlimited Edition 3 PH061-Martineau.book Page 4 Wednesday, August 6, 2003 7:40 PM 4 Chapter 1 • DB2 Product Overview ° DB2 Connect Personal Edition ° DB2 Connect Application Server Edition • DB2 UDB Clients ° DB2 Run-Time Client ° DB2 Administration Client ° DB2 Application Development Client DB2 UDB SERVER PRODUCTS DB2 UDB server products provide a relational database engine for storing, maintaining, and accessing data. -

IBM Z Open Development Version 1.0: Host Configuration Guide Figures
IBM Z Open Development Version 1.0 Host Configuration Guide IBM SC27-9297-01 IBM Z Open Development Version 1.0 Host Configuration Guide IBM SC27-9297-01 Note Before using this information, be sure to read the general information under “Notices” on page 27. Second edition (March 2019) This edition applies to IBM Z Open Development Version 1.0 and to all subsequent releases and modifications until otherwise indicated in new editions. IBM welcomes your comments. You can send your comments by mail to the following address: IBM Corporation Attn: Information Development Department 53NA Building 501 P.O. Box 12195 Research Triangle Park NC 27709-2195 USA You can fax your comments to: 1-800-227-5088 (US and Canada) When you send information to IBM, you grant IBM a nonexclusive right to use or distribute the information in any way it believes appropriate without incurring any obligation to you. © Copyright IBM Corporation 2015, 2019. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents Figures ............... v Customization setup ........... 11 PARMLIB changes ............ 12 Tables ............... vii Set the z/OS UNIX definitions in BPXPRMxx .. 12 Product enablement in IFAPRDxx ...... 12 LINKLIST definitions in PROGxx ...... 14 About this document ......... ix Requisite LINKLIST and LPA definitions ... 15 Who should use this document ........ ix PROCLIB changes ............ 16 ELAXF* remote build procedures ...... 16 Host Configuration Guide ...... 1 Security definitions ............ 18 idz.env, the environment configuration file .... 18 Chapter 1. Planning.......... 3 Migration considerations .......... 3 Chapter 3. Other customization tasks 21 Planning considerations .......... 3 z/OS UNIX subprojects .........