A Modern Optimizer for Real-Time Analytics in a Distributed Database
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Query Optimization Techniques - Tips for Writing Efficient and Faster SQL Queries
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 4, ISSUE 10, OCTOBER 2015 ISSN 2277-8616 Query Optimization Techniques - Tips For Writing Efficient And Faster SQL Queries Jean HABIMANA Abstract: SQL statements can be used to retrieve data from any database. If you've worked with databases for any amount of time retrieving information, it's practically given that you've run into slow running queries. Sometimes the reason for the slow response time is due to the load on the system, and other times it is because the query is not written to perform as efficiently as possible which is the much more common reason. For better performance we need to use best, faster and efficient queries. This paper covers how these SQL queries can be optimized for better performance. Query optimization subject is very wide but we will try to cover the most important points. In this paper I am not focusing on, in- depth analysis of database but simple query tuning tips & tricks which can be applied to gain immediate performance gain. ———————————————————— I. INTRODUCTION Query optimization is an important skill for SQL developers and database administrators (DBAs). In order to improve the performance of SQL queries, developers and DBAs need to understand the query optimizer and the techniques it uses to select an access path and prepare a query execution plan. Query tuning involves knowledge of techniques such as cost-based and heuristic-based optimizers, plus the tools an SQL platform provides for explaining a query execution plan.The best way to tune performance is to try to write your queries in a number of different ways and compare their reads and execution plans. -

Finding Fraud in Large and Diverse Data Sets
Business white paper Finding fraud in large and diverse data sets Applying real-time, next-generation analytics to fraud detection and prevention using the HP Vertica Analytics Platform Developments in data mining In the effort to identify and deter fraud, conventional wisdom still applies: Follow the money. That simple adage notwithstanding, the task of tracking fraud and its perpetrators continues to vex both private and public organizations. Clearly, advancements in information technology have made it possible to capture transaction data at the most granular level. For instance, in the retail trade alone, transmissions of up to 500 megabytes daily between individual point-of-sale sites and their data centers are typical.2 Logically, such detail should result in greater transparency and greater capacity to fight fraud. Yet, the sheer volume of data that organizations now maintain, pulled from so many sources and stored across a range of locations has made the same organizations more vulnerable.3 More points of entry amount to more opportunities for fraud. In its annual Global Fraud Report, The Economist found that 50% of all businesses surveyed acknowledged they were vulnerable to fraud; 35% of North American companies specifically cited IT complexity for increasing their exposure to risk. Accordingly, the application of data mining as a security measure A solution for real-time fraud detection has become increasingly germane to modern fraud detection. Historically, data mining as a means of identifying trends from raw Fraud saps hundreds of billions of dollars each year from the statistics can be traced back to the 1700s with the introduction of bottom line of industries such as banking, insurance, retail, Bayes’ theorem. -

The Vertica Analytic Database: C-Store 7 Years Later
The Vertica Analytic Database: C-Store 7 Years Later Andrew Lamb, Matt Fuller, Ramakrishna Varadarajan Nga Tran, Ben Vandiver, Lyric Doshi, Chuck Bear Vertica Systems, An HP Company Cambridge, MA {alamb, mfuller, rvaradarajan, ntran, bvandiver, ldoshi, cbear} @vertica.com ABSTRACT that they were designed for transactional workloads on late- This paper describes the system architecture of the Ver- model computer hardware 40 years ago. Vertica is designed tica Analytic Database (Vertica), a commercialization of the for analytic workloads on modern hardware and its success design of the C-Store research prototype. Vertica demon- proves the commercial and technical viability of large scale strates a modern commercial RDBMS system that presents distributed databases which offer fully ACID transactions a classical relational interface while at the same time achiev- yet efficiently process petabytes of structured data. ing the high performance expected from modern “web scale” This main contributions of this paper are: analytic systems by making appropriate architectural choices. 1. An overview of the architecture of the Vertica Analytic Vertica is also an instructive lesson in how academic systems Database, focusing on deviations from C-Store. research can be directly commercialized into a successful product. 2. Implementation and deployment lessons that led to those differences. 1. INTRODUCTION 3. Observations on real-world experiences that can in- The Vertica Analytic Database (Vertica) is a distributed1, form future research directions for large scale analytic massively parallel RDBMS system that commercializes the systems. ideas of the C-Store[21] project. It is one of the few new commercial relational database systems that is widely used We hope that this paper contributes a perspective on com- in business critical systems. -
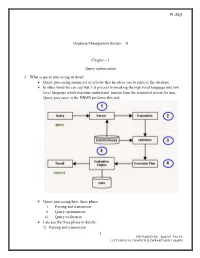
PL/SQL 1 Database Management System
PL/SQL Database Management System – II Chapter – 1 Query optimization 1. What is query processing in detail: Query processing means set of activity that involves you to retrieve the database In other word we can say that it is process to breaking the high level language into low level language which machine understand and perform the requested action for user. Query processor in the DBMS performs this task. Query processing have three phase i. Parsing and transaction ii. Query optimization iii. Query evaluation Lets see the three phase in details : 1) Parsing and transaction : 1 PREPARED BY: RAHUL PATEL LECTURER IN COMPUTER DEPARTMENT (BSPP) PL/SQL . Check syntax and verify relations. Translate the query into an equivalent . relational algebra expression. 2) Query optimization : . Generate an optimal evaluation plan (with lowest cost) for the query plan. 3) Query evaluation : . The query-execution engine takes an (optimal) evaluation plan, executes that plan, and returns the answers to the query Let us discuss the whole process with an example. Let us consider the following two relations as the example tables for our discussion; Employee(Eno, Ename, Phone) Proj_Assigned(Eno, Proj_No, Role, DOP) where, Eno is Employee number, Ename is Employee name, Proj_No is Project Number in which an employee is assigned, Role is the role of an employee in a project, DOP is duration of the project in months. With this information, let us write a query to find the list of all employees who are working in a project which is more than 10 months old. SELECT Ename FROM Employee, Proj_Assigned WHERE Employee.Eno = Proj_Assigned.Eno AND DOP > 10; Input: . -

An Overview of Query Optimization
An Overview of Query Optimization Why? Improving query processing time. Fast response is important in several db applications. Is it possible? Yes, but relative. A query can be evaluated in several ways. We can list all of them and then find the best among them. Sometime, we might not be able to do it because of the number of possible ways to evaluate the query is huge. We need to settle for a compromise: we try to find one that is reasonably good. Typical Query Evaluation Steps in DBMS. The DBMS has the following components for query evaluation: SQL parser, quey optimizer, cost estimator, query plan interpreter. The SQL parser accepts a SQL query and generates a relational algebra expression (sometime, the system catalog is considered in the generation of the expression). This expression is fed into the query optimizer, which works in conjunction with the cost estimator to generate a query execution plan (with hopefully a reasonably cost). This plan is then sent to the plan interpreter for execution. How? The query optimizer uses several heuristics to convert a relational algebra expression to an equivalent expres- sion which (hopefully!) can be computed efficiently. Different heuristics are (see explaination in textbook): (i) transformation between selection and projection; 1. Cascading of selection: σC1∧C2 (R) ≡ σC1 (σC2 (R)) 2. Commutativity of selection: σC1 (σC2 (R)) ≡ σC2 (σC1 (R)) 0 3. Cascading of projection: πAtts(R) = πAtts(πAtts0 (R)) if Atts ⊆ Atts 4. Commutativity of projection: πAtts(σC (R)) = σC (πAtts((R)) if Atts includes all attributes used in C. (ii) transformation between Cartesian product and join; 1. -
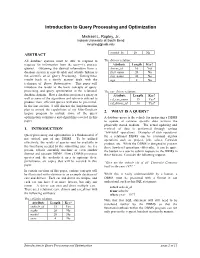
Introduction to Query Processing and Optimization
Introduction to Query Processing and Optimization Michael L. Rupley, Jr. Indiana University at South Bend [email protected] owned_by 10 No ABSTRACT All database systems must be able to respond to The drivers relation: requests for information from the user—i.e. process Attribute Length Key? queries. Obtaining the desired information from a driver_id 10 Yes database system in a predictable and reliable fashion is first_name 20 No the scientific art of Query Processing. Getting these last_name 20 No results back in a timely manner deals with the age 2 No technique of Query Optimization. This paper will introduce the reader to the basic concepts of query processing and query optimization in the relational The car_driver relation: database domain. How a database processes a query as Attribute Length Key? well as some of the algorithms and rule-sets utilized to cd_car_name 15 Yes* produce more efficient queries will also be presented. cd_driver_id 10 Yes* In the last section, I will discuss the implementation plan to extend the capabilities of my Mini-Database Engine program to include some of the query 2. WHAT IS A QUERY? optimization techniques and algorithms covered in this A database query is the vehicle for instructing a DBMS paper. to update or retrieve specific data to/from the physically stored medium. The actual updating and 1. INTRODUCTION retrieval of data is performed through various “low-level” operations. Examples of such operations Query processing and optimization is a fundamental, if for a relational DBMS can be relational algebra not critical, part of any DBMS. To be utilized operations such as project, join, select, Cartesian effectively, the results of queries must be available in product, etc. -

Database Software Market: Billy Fitzsimmons +1 312 364 5112
Equity Research Technology, Media, & Communications | Enterprise and Cloud Infrastructure March 22, 2019 Industry Report Jason Ader +1 617 235 7519 [email protected] Database Software Market: Billy Fitzsimmons +1 312 364 5112 The Long-Awaited Shake-up [email protected] Naji +1 212 245 6508 [email protected] Please refer to important disclosures on pages 70 and 71. Analyst certification is on page 70. William Blair or an affiliate does and seeks to do business with companies covered in its research reports. As a result, investors should be aware that the firm may have a conflict of interest that could affect the objectivity of this report. This report is not intended to provide personal investment advice. The opinions and recommendations here- in do not take into account individual client circumstances, objectives, or needs and are not intended as recommen- dations of particular securities, financial instruments, or strategies to particular clients. The recipient of this report must make its own independent decisions regarding any securities or financial instruments mentioned herein. William Blair Contents Key Findings ......................................................................................................................3 Introduction .......................................................................................................................5 Database Market History ...................................................................................................7 Market Definitions -

Vertica Advanced Analytics Platform
Data Sheet Vertica Advanced Analytics Platform Vertica Advanced Analytics Platform The Vertica Advanced Analytics Platform is consciously designed with speed, scalability, simplicity, and openness at its core and architected to handle analytical workloads via a distributed compressed columnar architecture. Vertica Advanced Analytics Platform provides blazingly fast speed (queries run 10–50X faster), exabyte scale (store 10–30X more data per server), openness, and simplicity (use any business intelligence [BI]/ETL tools, Hadoop, etc.)—at a much lower cost than traditional data warehouse solutions and a better time to market than unproven open source solutions. Handling Today’s Massive What Are the Key Technology Quick View Requirements of a Big Data Data Volumes At the core of the Vertica Advanced Analytics In modern data infrastructures, data comes Analytics Platform? Platform is a column-oriented, relational database from everywhere: business systems like CRM So, just what should you look for in a data ana- built specifically to handle today’s analytic workloads. and ERP, IoT sensors, tweets and other social lytics solution to address today and tomorrow’s Unlike commercial and open-source row stores, media data, Web logs and data streams, gas data challenges? Consider the following: which were designed long ago to support small data, the Vertica Advanced Analytics Platform provides and electrical grids, and mobile networks to Analyze huge data volumes in a unified customers with: name a few. With all this data generated from so manner: You are likely looking to analyze many places, companies are turning to dispa- data at unlimited scale combined with the • Complete and advanced SQL-based analytical functions to provide powerful SQL analytics rate, lower-cost storage locations to store and need to store your data in the right place manage these volumes, adding complexity and at the right time. -

Query Optimization for Dynamic Imputation
Query Optimization for Dynamic Imputation José Cambronero⇤ John K. Feser⇤ Micah J. Smith⇤ Samuel Madden MIT CSAIL MIT CSAIL MIT LIDS MIT CSAIL [email protected] [email protected] [email protected] [email protected] ABSTRACT smaller than the entire database. While traditional imputation Missing values are common in data analysis and present a methods work over the entire data set and replace all missing usability challenge. Users are forced to pick between removing values, running a sophisticated imputation algorithm over a tuples with missing values or creating a cleaned version of their large data set can be very expensive: our experiments show data by applying a relatively expensive imputation strategy. that even a relatively simple decision tree algorithm takes just Our system, ImputeDB, incorporates imputation into a cost- under 6 hours to train and run on a 600K row database. based query optimizer, performing necessary imputations on- Asimplerapproachmightdropallrowswithanymissing the-fly for each query. This allows users to immediately explore values, which can not only introduce bias into the results, but their data, while the system picks the optimal placement of also result in discarding much of the data. In contrast to exist- imputation operations. We evaluate this approach on three ing systems [2, 4], ImputeDB avoids imputing over the entire real-world survey-based datasets. Our experiments show that data set. Specifically,ImputeDB carefully plans the placement our query plans execute between 10 and 140 times faster than of imputation or row-drop operations inside the query plan, first imputing the base tables. Furthermore, we show that resulting in a significant speedup in query execution while the query results from on-the-fly imputation differ from the reducing the number of dropped rows. -

Scalable Query Optimization for Efficient Data Processing Using
1 Scalable Query Optimization for Efficient Data Processing using MapReduce Yi Shan #1, Yi Chen 2 # School of Computing, Informatics, and Decision Systems Engineering, Arizona State University, Tempe, AZ, USA School of Management, New Jersey Institute of Technology, Newark, NJ, USA 1 [email protected] 2 [email protected] 1#*#!2_ Abstract—MapReduce is widely acknowledged by both indus- $0-+ --- try and academia as an effective programming model for query 5�# 0X0,"0X0,"0X0 processing on big data. It is crucial to design an optimizer which finds the most efficient way to execute an SQL query using Fig. 1. Query Q1 MapReduce. However, existing work in parallel query processing either falls short of optimizing an SQL query using MapReduce '8#/ '8#/ or the time complexity of the optimizer it uses is exponential. Also, industry solutions such as HIVE, and YSmart do not '8#/ optimize the join sequence of an SQL query and cannot guarantee '8#/ '8#/ '8#/ an optimal execution plan. In this paper, we propose a scalable '8#/ optimizer for SQL queries using MapReduce, named SOSQL. '8#/ Experiments performed on Google Cloud Platform confirmed '8#/ the scalability and efficiency of SOSQL over existing work. '8#/ '8#/ '8#/ '8#/ '8#/ (a) QP1 (b) QP2 I. INTRODUCTION Fig. 2. Query Plans of Query Q1 It becomes increasingly important to process SQL queries further generates a query execution plan consisting of three on big data. Query processing consists of two parts: query parallel jobs, one for each binary join operation, as illustrated optimization and query execution. The query optimizer first in Figure 3(a). -

Gartner Magic Quadrant for Data Management Solutions for Analytics
16/09/2019 Gartner Reprint Licensed for Distribution Magic Quadrant for Data Management Solutions for Analytics Published 21 January 2019 - ID G00353775 - 74 min read By Analysts Adam Ronthal, Roxane Edjlali, Rick Greenwald Disruption slows as cloud and nonrelational technology take their place beside traditional approaches, the leaders extend their lead, and distributed data approaches solidify their place as a best practice for DMSA. We help data and analytics leaders evaluate DMSAs in an increasingly split market. Market Definition/Description Gartner defines a data management solution for analytics (DMSA) as a complete software system that supports and manages data in one or many file management systems, most commonly a database or multiple databases. These management systems include specific optimization strategies designed for supporting analytical processing — including, but not limited to, relational processing, nonrelational processing (such as graph processing), and machine learning or programming languages such as Python or R. Data is not necessarily stored in a relational structure, and can use multiple data models — relational, XML, JavaScript Object Notation (JSON), key-value, graph, geospatial and others. Our definition also states that: ■ A DMSA is a system for storing, accessing, processing and delivering data intended for one or more of the four primary use cases Gartner identifies that support analytics (see Note 1). ■ A DMSA is not a specific class or type of technology; it is a use case. ■ A DMSA may consist of many different technologies in combination. However, any offering or combination of offerings must, at its core, exhibit the capability of providing access to the data under management by open-access tools. -

Query Optimization
Query Optimization Query Processing: Query processing refers to activities including translation of high level languages (HLL) queries into operations at physical file level, query optimization transformations, and actual evaluation of queries. Steps in Query Processing: Function of query parser is parsing and translation of HLL query into its immediate form relation algebraic expression. A parse tree of the query is constructed and then translated in to relational algebraic expression. Example: consider the following SQL query: SELECT s.name FROM reserves R, sailors S Where R.sid=S.sid AND R.bid=100 And S.rating>5 Its corresponding relational algebraic expression Query Optimization : Query optimization is the process of selecting an efficient execution plan for evaluating the query. After parsing of the query, parsed query is passed to query optimizer, which generates different execution plans to evaluate parsed query and select the plan with least estimated cost. Catalog manager helps optimizer to choose best plan to execute query generating cost of each plan. Query optimization is used for accessing the database in an efficient manner. It is an art of obtaining desired information in a predictable, reliable and timely manner. Formally defines query optimization as a process of transforming a query into an equivalent form which can be evaluated more efficiently. The essence of query optimization is to find an execution plan that minimizes time needed to evaluate a query. To achieve this optimization goal, we need to accomplish two main tasks. First one is to find out the best plan and the second one is to reduce the time involved in executing the query plan.