SAP HANA Performance Guide for Developers Company
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Changing the Game: Monthly Technology Briefs
the way we see it Changing the Game: Monthly Technology Briefs April 2011 Tablets and Smartphones: Levers of Disruptive Change Read the Capgemini Chief Technology Officers’ Blog at www.capgemini.com/ctoblog Public the way we see it Tablets and Smartphones: Levers of Disruptive Change All 2010 shipment reports tell the same story - of an incredible increase in the shipments of both Smartphones and Tablets, and of a corresponding slowdown in the conventional PC business. Smartphone sales exceeded even the most optimis- tic forecasts of experts, with a 74 percent increase from the previous year – around a battle between Apple and Google Android for supremacy at the expense of traditional leaders Nokia and RIM BlackBerry. It was the same story for Tablets with 17.4 million units sold in 2010 led by Apple, but once again with Google Android in hot pursuit. Analyst predictions for shipments suggest that the tablet market will continue its exponential growth curve to the extent that even the usually cautious Gartner think that by 2013 there will be as many Tablets in use in an enterprise as PCs with a profound impact on the IT environment. On February 7, as part of the Gartner ‘First Thing Monday’ series under the title ‘The Digital Natives are Restless, The impending Revolt against the IT Nanny State’ Gartner analyst Jim Shepherd stated; “I am regularly hearing middle managers and even senior executives complaining bit- terly about IT departments that are so focussed on the global rollout of some monolith- ic solution that they have no time for new and innovative technologies that could have an immediate impact on the business. -

Query Optimization Techniques - Tips for Writing Efficient and Faster SQL Queries
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 4, ISSUE 10, OCTOBER 2015 ISSN 2277-8616 Query Optimization Techniques - Tips For Writing Efficient And Faster SQL Queries Jean HABIMANA Abstract: SQL statements can be used to retrieve data from any database. If you've worked with databases for any amount of time retrieving information, it's practically given that you've run into slow running queries. Sometimes the reason for the slow response time is due to the load on the system, and other times it is because the query is not written to perform as efficiently as possible which is the much more common reason. For better performance we need to use best, faster and efficient queries. This paper covers how these SQL queries can be optimized for better performance. Query optimization subject is very wide but we will try to cover the most important points. In this paper I am not focusing on, in- depth analysis of database but simple query tuning tips & tricks which can be applied to gain immediate performance gain. ———————————————————— I. INTRODUCTION Query optimization is an important skill for SQL developers and database administrators (DBAs). In order to improve the performance of SQL queries, developers and DBAs need to understand the query optimizer and the techniques it uses to select an access path and prepare a query execution plan. Query tuning involves knowledge of techniques such as cost-based and heuristic-based optimizers, plus the tools an SQL platform provides for explaining a query execution plan.The best way to tune performance is to try to write your queries in a number of different ways and compare their reads and execution plans. -

Synopsys: Large Graph Analytics in the SAP HANA Database Through Summarization
SynopSys: Large Graph Analytics in the SAP HANA Database Through Summarization Michael Rudolf1 Marcus Paradies1 Christof Bornhövd2 Wolfgang Lehner3 1SAP AG 2SAP Labs, LLC 3Database Technology Group Walldorf, Germany Palo Alto, CA 94304, USA TU Dresden, Germany [email protected] [email protected] [email protected] ABSTRACT “Cell Phones “Computers & & Accessories” Graph-structured data is ubiquitous and with the advent of social Accessories” 4 networking platforms has recently seen a significant increase in 6 popularity amongst researchers. However, also many business appli- part of part of “Freddy” cations deal with this kind of data and can therefore benefit greatly 10 “Mike” from graph processing functionality offered directly by the underly- 8 5 “Phones” “Tablets” 7 ing database. This paper summarizes the current state of graph data in rates 4/5 processing capabilities in the SAP HANA database and describes our efforts to enable large graph analytics in the context of our research in 11 “Steve” rates 5/5 white 3 “Apple in project SynopSys. With powerful graph pattern matching support at iPhone 4” 16 GB the core, we envision OLAP-like evaluation functionality exposed to rates 5/5 the user in the form of easy-to-apply graph summarization templates. black rates 3/5 black 64 GB 1 32 GB 2 By combining them, the user is able to produce concise summaries 9 of large graph-structured datasets. We also point out open questions “Apple iPad “Apple and challenges that we plan to tackle in the future developments on MC707LL/A” “Carl” iPhone 5” our way towards large graph analytics. -

SAQE: Practical Privacy-Preserving Approximate Query Processing for Data Federations
SAQE: Practical Privacy-Preserving Approximate Query Processing for Data Federations Johes Bater Yongjoo Park Xi He Northwestern University University of Illinois (UIUC) University of Waterloo [email protected] [email protected] [email protected] Xiao Wang Jennie Rogers Northwestern University Northwestern University [email protected] [email protected] ABSTRACT 1. INTRODUCTION A private data federation enables clients to query the union of data Querying the union of multiple private data stores is challeng- from multiple data providers without revealing any extra private ing due to the need to compute over the combined datasets without information to the client or any other data providers. Unfortu- data providers disclosing their secret query inputs to anyone. Here, nately, this strong end-to-end privacy guarantee requires crypto- a client issues a query against the union of these private records graphic protocols that incur a significant performance overhead as and he or she receives the output of their query over this shared high as 1,000× compared to executing the same query in the clear. data. Presently, systems of this kind use a trusted third party to se- As a result, private data federations are impractical for common curely query the union of multiple private datastores. For example, database workloads. This gap reveals the following key challenge some large hospitals in the Chicago area offer services for a cer- in a private data federation: offering significantly fast and accurate tain percentage of the residents; if we can query the union of these query answers without compromising strong end-to-end privacy. databases, it may serve as invaluable resources for accurate diag- To address this challenge, we propose SAQE, the Secure Ap- nosis, informed immunization, timely epidemic control, and so on. -

SAP HANA Client Interface Programming Reference for SAP HANA Platform Company
PUBLIC SAP HANA Platform 2.0 SPS 04 Document Version: 1.1 – 2019-10-31 SAP HANA Client Interface Programming Reference for SAP HANA Platform company. All rights reserved. All rights company. affiliate THE BEST RUN 2019 SAP SE or an SAP SE or an SAP SAP 2019 © Content 1 SAP HANA Client Interface Programming Reference.................................17 2 Configuring Clients for Secure Connections.......................................19 2.1 Server Certificate Authentication.................................................19 2.2 Mutual Authentication........................................................ 20 Implement Mutual Authentication..............................................20 2.3 Configuring the Client for Client-Side Encryption and LDAP.............................. 26 3 Connecting to SAP HANA Databases and Servers...................................27 3.1 Setting Session-Specific Client Information..........................................29 3.2 Use the User Store (hdbuserstore)................................................32 4 Client Support for Active/Active (Read Enabled)...................................34 4.1 Connecting Using Active/Active (Read Enabled)...................................... 34 Client Requirements For A Takeover.............................................35 4.2 Hint-Based Statement Routing for Active/Active (Read Enabled)...........................36 4.3 Forced Statement Routing to a Site for Active/Active (Read Enabled)........................37 Implement Forced Statement Routing to a Site for Active/Active -
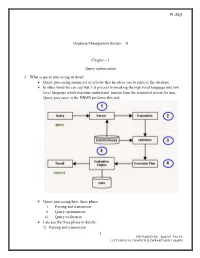
PL/SQL 1 Database Management System
PL/SQL Database Management System – II Chapter – 1 Query optimization 1. What is query processing in detail: Query processing means set of activity that involves you to retrieve the database In other word we can say that it is process to breaking the high level language into low level language which machine understand and perform the requested action for user. Query processor in the DBMS performs this task. Query processing have three phase i. Parsing and transaction ii. Query optimization iii. Query evaluation Lets see the three phase in details : 1) Parsing and transaction : 1 PREPARED BY: RAHUL PATEL LECTURER IN COMPUTER DEPARTMENT (BSPP) PL/SQL . Check syntax and verify relations. Translate the query into an equivalent . relational algebra expression. 2) Query optimization : . Generate an optimal evaluation plan (with lowest cost) for the query plan. 3) Query evaluation : . The query-execution engine takes an (optimal) evaluation plan, executes that plan, and returns the answers to the query Let us discuss the whole process with an example. Let us consider the following two relations as the example tables for our discussion; Employee(Eno, Ename, Phone) Proj_Assigned(Eno, Proj_No, Role, DOP) where, Eno is Employee number, Ename is Employee name, Proj_No is Project Number in which an employee is assigned, Role is the role of an employee in a project, DOP is duration of the project in months. With this information, let us write a query to find the list of all employees who are working in a project which is more than 10 months old. SELECT Ename FROM Employee, Proj_Assigned WHERE Employee.Eno = Proj_Assigned.Eno AND DOP > 10; Input: . -

An Overview of Query Optimization
An Overview of Query Optimization Why? Improving query processing time. Fast response is important in several db applications. Is it possible? Yes, but relative. A query can be evaluated in several ways. We can list all of them and then find the best among them. Sometime, we might not be able to do it because of the number of possible ways to evaluate the query is huge. We need to settle for a compromise: we try to find one that is reasonably good. Typical Query Evaluation Steps in DBMS. The DBMS has the following components for query evaluation: SQL parser, quey optimizer, cost estimator, query plan interpreter. The SQL parser accepts a SQL query and generates a relational algebra expression (sometime, the system catalog is considered in the generation of the expression). This expression is fed into the query optimizer, which works in conjunction with the cost estimator to generate a query execution plan (with hopefully a reasonably cost). This plan is then sent to the plan interpreter for execution. How? The query optimizer uses several heuristics to convert a relational algebra expression to an equivalent expres- sion which (hopefully!) can be computed efficiently. Different heuristics are (see explaination in textbook): (i) transformation between selection and projection; 1. Cascading of selection: σC1∧C2 (R) ≡ σC1 (σC2 (R)) 2. Commutativity of selection: σC1 (σC2 (R)) ≡ σC2 (σC1 (R)) 0 3. Cascading of projection: πAtts(R) = πAtts(πAtts0 (R)) if Atts ⊆ Atts 4. Commutativity of projection: πAtts(σC (R)) = σC (πAtts((R)) if Atts includes all attributes used in C. (ii) transformation between Cartesian product and join; 1. -

Veritas: Shared Verifiable Databases and Tables in the Cloud
Veritas: Shared Verifiable Databases and Tables in the Cloud Lindsey Alleny, Panagiotis Antonopoulosy, Arvind Arasuy, Johannes Gehrkey, Joachim Hammery, James Huntery, Raghav Kaushiky, Donald Kossmanny, Jonathan Leey, Ravi Ramamurthyy, Srinath Settyy, Jakub Szymaszeky, Alexander van Renenz, Ramarathnam Venkatesany yMicrosoft Corporation zTechnische Universität München ABSTRACT A recent class of new technology under the umbrella term In this paper we introduce shared, verifiable database tables, a new "blockchain" [11, 13, 22, 28, 33] promises to solve this conundrum. abstraction for trusted data sharing in the cloud. For example, companies A and B could write the state of these shared tables into a blockchain infrastructure (such as Ethereum [33]). The KEYWORDS blockchain then gives them transaction properties, such as atomic- ity of updates, durability, and isolation, and the blockchain allows Blockchain, data management a third party to go through its history and verify the transactions. Both companies A and B would have to write their updates into 1 INTRODUCTION the blockchain, wait until they are committed, and also read any Our economy depends on interactions – buyers and sellers, suppli- state changes from the blockchain as a means of sharing data across ers and manufacturers, professors and students, etc. Consider the A and B. To implement permissioning, A and B can use a permis- scenario where there are two companies A and B, where B supplies sioned blockchain variant that allows transactions only from a set widgets to A. A and B are exchanging data about the latest price for of well-defined participants; e.g., Ethereum [33]. widgets and dates of when widgets were shipped. -

WIN: an Efficient Data Placement Strategy for Parallel XML Databases
WIN : An Efficient Data Placement Strategy for Parallel XML Databases Nan Tang† Guoren Wang‡ Jeffrey Xu Yu† Kam-Fai Wong† Ge Yu‡ † Department of SE & EM, The Chinese University of Hong Kong, Hong Kong, China ‡ College of Information Science and Engineering, Northeastern University, Shenyang, China {ntang, yu, kfwong}se.cuhk.edu.hk {wanggr, yuge}@mail.neu.edu.cn Abstract graph-based. Distinct from them, XML employs a tree struc- The basic idea behind parallel database systems is to ture. Conventional data placement strategies in perform operations in parallel to reduce the response RDBMSs and OODBMSs cannot serve XML data well. time and improve the system throughput. Data place- Semistructured data involve nested structures; there ment is a key factor on the overall performance of are much intricacy and redundancy when represent- parallel systems. XML is semistructured data, tradi- ing XML as relations. Data placement strategies in tional data placement strategies cannot serve it well. RDBMSs cannot, therefore, well solve the data place- In this paper, we present the concept of intermediary ment problem of XML data. Although graph partition node INode, and propose a novel workload-aware data algorithms in OODBMSs can be applied to tree parti- placement WIN to effectively decluster XML data, to tion problems, the key relationships between tree nodes obtain high intra query parallelism. The extensive ex- such as ancestor-descendant or sibling cannot be clearly periments show that the speedup and scaleup perfor- denoted on graph. Hence data placement strategies mance of WIN outperforms the previous strategies. for OODBMSs cannot well adapt to XML data either. -

Chapter 11 Querying
Oracle TIGHT / Oracle Database 11g & MySQL 5.6 Developer Handbook / Michael McLaughlin / 885-8 Blind folio: 273 CHAPTER 11 Querying 273 11-ch11.indd 273 9/5/11 4:23:56 PM Oracle TIGHT / Oracle Database 11g & MySQL 5.6 Developer Handbook / Michael McLaughlin / 885-8 Oracle TIGHT / Oracle Database 11g & MySQL 5.6 Developer Handbook / Michael McLaughlin / 885-8 274 Oracle Database 11g & MySQL 5.6 Developer Handbook Chapter 11: Querying 275 he SQL SELECT statement lets you query data from the database. In many of the previous chapters, you’ve seen examples of queries. Queries support several different types of subqueries, such as nested queries that run independently or T correlated nested queries. Correlated nested queries run with a dependency on the outer or containing query. This chapter shows you how to work with column returns from queries and how to join tables into multiple table result sets. Result sets are like tables because they’re two-dimensional data sets. The data sets can be a subset of one table or a set of values from two or more tables. The SELECT list determines what’s returned from a query into a result set. The SELECT list is the set of columns and expressions returned by a SELECT statement. The SELECT list defines the record structure of the result set, which is the result set’s first dimension. The number of rows returned from the query defines the elements of a record structure list, which is the result set’s second dimension. You filter single tables to get subsets of a table, and you join tables into a larger result set to get a superset of any one table by returning a result set of the join between two or more tables. -

SQL Database Management Portal
APPENDIX A SQL Database Management Portal This appendix introduces you to the online SQL Database Management Portal built by Microsoft. It is a web-based application that allows you to design, manage, and monitor your SQL Database instances. Although the current version of the portal does not support all the functions of SQL Server Management Studio, the portal offers some interesting capabilities unique to SQL Database. Launching the Management Portal You can launch the SQL Database Management Portal (SDMP) from the Windows Azure Management Portal. Open a browser and navigate to https://manage.windowsazure.com, and then login with your Live ID. Once logged in, click SQL Databases on the left and click on your database from the list of available databases. This brings up the database dashboard, as seen in Figure A-1. To launch the management portal, click the Manage icon at the bottom. Figure A-1. SQL Database dashboard in Windows Azure Management Portal 257 APPENDIX A N SQL DATABASE MANAGEMENT PORTAL N Note You can also access the SDMP directly from a browser by typing https://sqldatabasename.database. windows.net, where sqldatabasename is the server name of your SQL Database. A new web page opens up that prompts you to log in to your SQL Database server. If you clicked through the Windows Azure Management Portal, the database name will be automatically filled and read-only. If you typed the URL directly in a browser, you will need to enter the database name manually. Enter a user name and password; then click Log on (Figure A-2). -

Using the Set Operators Questions
UUSSIINNGG TTHHEE SSEETT OOPPEERRAATTOORRSS QQUUEESSTTIIOONNSS http://www.tutorialspoint.com/sql_certificate/using_the_set_operators_questions.htm Copyright © tutorialspoint.com 1.Which SET operator does the following figure indicate? A. UNION B. UNION ALL C. INTERSECT D. MINUS Answer: A. Set operators are used to combine the results of two ormore SELECT statements.Valid set operators in Oracle 11g are UNION, UNION ALL, INTERSECT, and MINUS. When used with two SELECT statements, the UNION set operator returns the results of both queries.However,if there are any duplicates, they are removed, and the duplicated record is listed only once.To include duplicates in the results,use the UNION ALL set operator.INTERSECT lists only records that are returned by both queries; the MINUS set operator removes the second query's results from the output if they are also found in the first query's results. INTERSECT and MINUS set operations produce unduplicated results. 2.Which SET operator does the following figure indicate? A. UNION B. UNION ALL C. INTERSECT D. MINUS Answer: B. UNION ALL Returns the combined rows from two queries without sorting or removing duplicates. sql_certificate 3.Which SET operator does the following figure indicate? A. UNION B. UNION ALL C. INTERSECT D. MINUS Answer: C. INTERSECT Returns only the rows that occur in both queries' result sets, sorting them and removing duplicates. 4.Which SET operator does the following figure indicate? A. UNION B. UNION ALL C. INTERSECT D. MINUS Answer: D. MINUS Returns only the rows in the first result set that do not appear in the second result set, sorting them and removing duplicates.