Driving Data Management Optimization and AI Success with Db2 Databases
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Query Optimization Techniques - Tips for Writing Efficient and Faster SQL Queries
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 4, ISSUE 10, OCTOBER 2015 ISSN 2277-8616 Query Optimization Techniques - Tips For Writing Efficient And Faster SQL Queries Jean HABIMANA Abstract: SQL statements can be used to retrieve data from any database. If you've worked with databases for any amount of time retrieving information, it's practically given that you've run into slow running queries. Sometimes the reason for the slow response time is due to the load on the system, and other times it is because the query is not written to perform as efficiently as possible which is the much more common reason. For better performance we need to use best, faster and efficient queries. This paper covers how these SQL queries can be optimized for better performance. Query optimization subject is very wide but we will try to cover the most important points. In this paper I am not focusing on, in- depth analysis of database but simple query tuning tips & tricks which can be applied to gain immediate performance gain. ———————————————————— I. INTRODUCTION Query optimization is an important skill for SQL developers and database administrators (DBAs). In order to improve the performance of SQL queries, developers and DBAs need to understand the query optimizer and the techniques it uses to select an access path and prepare a query execution plan. Query tuning involves knowledge of techniques such as cost-based and heuristic-based optimizers, plus the tools an SQL platform provides for explaining a query execution plan.The best way to tune performance is to try to write your queries in a number of different ways and compare their reads and execution plans. -

Graph Database for Collaborative Communities Rania Soussi, Marie-Aude Aufaure, Hajer Baazaoui
Graph Database for Collaborative Communities Rania Soussi, Marie-Aude Aufaure, Hajer Baazaoui To cite this version: Rania Soussi, Marie-Aude Aufaure, Hajer Baazaoui. Graph Database for Collaborative Communities. Community-Built Databases, Springer, pp.205-234, 2011. hal-00708222 HAL Id: hal-00708222 https://hal.archives-ouvertes.fr/hal-00708222 Submitted on 14 Jun 2012 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Graph Database For collaborative Communities 1, 2 1 Rania Soussi , Marie-Aude Aufaure , Hajer Baazaoui2 1Ecole Centrale Paris, Applied Mathematics & Systems Laboratory (MAS), SAP Business Objects Academic Chair in Business Intelligence 2Riadi-GDL Laboratory, ENSI – Manouba University, Tunis Abstract Data manipulated in an enterprise context are structured data as well as un- structured data such as emails, documents, social networks, etc. Graphs are a natural way of representing and modeling such data in a unified manner (Structured, semi-structured and unstructured ones). The main advantage of such a structure relies in the dynamic aspect and the capability to represent relations, even multiple ones, between objects. Recent database research work shows a growing interest in the definition of graph models and languages to allow a natural way of handling data appearing. -

History of AI at IBM and How IBM Is Leveraging Watson for Intellectual Property
History of AI at IBM and How IBM is Leveraging Watson for Intellectual Property 2019 ECC Conference June 9-11 at Marist College IBM Intellectual Property Management Solutions 1 IBM Intellectual Property Management Solutions © 2017-2019 IBM Corporation Who are We? At IBM for 37 years I currently work in the Technology and Intellectual Property organization, a combination of CHQ and Research. I have worked as an engineer in Procurement, Testing, MLC Packaging, and now T&IP. Currently Lead Architect on IP Advisor with Watson, a Watson based Patent and Intellectual Property Analytics tool. • Master Inventor • Number of patents filed ~ 24+ • Number of submissions in progress ~ 4+ • Consult/Educate outside companies on all things IP (from strategy to commercialization, including IP 101) • Technical background: Semiconductors, Computers, Programming/Software, Tom Fleischman Intellectual Property and Analytics [email protected] Is the manager of the Intellectual Property Management Solutions team in CHQ under the Technology and Intellectual Property group. Current OM for IP Advisor with Watson application, used internally and externally. Past Global Business Services in the PLM and Supply Chain practices. • Number of patents filed – 2 (2018) • Number of submissions in progress - 2 • Consult/Educate outside companies on all things IP (from strategy to commercialization, including IP 101) • Schaumburg SLE Sue Hallen • Technical background: Registered Professional Engineer in Illinois, Structural Engineer by [email protected] degree, lots of software development and implementation for PLM clients 2 IBM Intellectual Property Management Solutions © 2017-2019 IBM Corporation How does IBM define AI? IBM refers to it as Augmented Intelligence…. • Not artificial or meant to replace Human Thinking…augments your work AI Terminology Machine Learning • Provides computers with the ability to continuing learning without being pre-programmed. -
PL/SQL 1 Database Management System
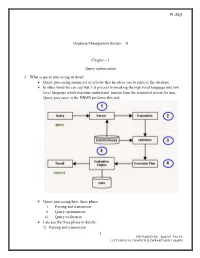
PL/SQL Database Management System – II Chapter – 1 Query optimization 1. What is query processing in detail: Query processing means set of activity that involves you to retrieve the database In other word we can say that it is process to breaking the high level language into low level language which machine understand and perform the requested action for user. Query processor in the DBMS performs this task. Query processing have three phase i. Parsing and transaction ii. Query optimization iii. Query evaluation Lets see the three phase in details : 1) Parsing and transaction : 1 PREPARED BY: RAHUL PATEL LECTURER IN COMPUTER DEPARTMENT (BSPP) PL/SQL . Check syntax and verify relations. Translate the query into an equivalent . relational algebra expression. 2) Query optimization : . Generate an optimal evaluation plan (with lowest cost) for the query plan. 3) Query evaluation : . The query-execution engine takes an (optimal) evaluation plan, executes that plan, and returns the answers to the query Let us discuss the whole process with an example. Let us consider the following two relations as the example tables for our discussion; Employee(Eno, Ename, Phone) Proj_Assigned(Eno, Proj_No, Role, DOP) where, Eno is Employee number, Ename is Employee name, Proj_No is Project Number in which an employee is assigned, Role is the role of an employee in a project, DOP is duration of the project in months. With this information, let us write a query to find the list of all employees who are working in a project which is more than 10 months old. SELECT Ename FROM Employee, Proj_Assigned WHERE Employee.Eno = Proj_Assigned.Eno AND DOP > 10; Input: . -

An Overview of Query Optimization
An Overview of Query Optimization Why? Improving query processing time. Fast response is important in several db applications. Is it possible? Yes, but relative. A query can be evaluated in several ways. We can list all of them and then find the best among them. Sometime, we might not be able to do it because of the number of possible ways to evaluate the query is huge. We need to settle for a compromise: we try to find one that is reasonably good. Typical Query Evaluation Steps in DBMS. The DBMS has the following components for query evaluation: SQL parser, quey optimizer, cost estimator, query plan interpreter. The SQL parser accepts a SQL query and generates a relational algebra expression (sometime, the system catalog is considered in the generation of the expression). This expression is fed into the query optimizer, which works in conjunction with the cost estimator to generate a query execution plan (with hopefully a reasonably cost). This plan is then sent to the plan interpreter for execution. How? The query optimizer uses several heuristics to convert a relational algebra expression to an equivalent expres- sion which (hopefully!) can be computed efficiently. Different heuristics are (see explaination in textbook): (i) transformation between selection and projection; 1. Cascading of selection: σC1∧C2 (R) ≡ σC1 (σC2 (R)) 2. Commutativity of selection: σC1 (σC2 (R)) ≡ σC2 (σC1 (R)) 0 3. Cascading of projection: πAtts(R) = πAtts(πAtts0 (R)) if Atts ⊆ Atts 4. Commutativity of projection: πAtts(σC (R)) = σC (πAtts((R)) if Atts includes all attributes used in C. (ii) transformation between Cartesian product and join; 1. -

Big Blue in the Bottomless Pit: the Early Years of IBM Chile
Big Blue in the Bottomless Pit: The Early Years of IBM Chile Eden Medina Indiana University In examining the history of IBM in Chile, this article asks how IBM came to dominate Chile’s computer market and, to address this question, emphasizes the importance of studying both IBM corporate strategy and Chilean national history. The article also examines how IBM reproduced its corporate culture in Latin America and used it to accommodate the region’s political and economic changes. Thomas J. Watson Jr. was skeptical when he The history of IBM has been documented first heard his father’s plan to create an from a number of perspectives. Former em- international subsidiary. ‘‘We had endless ployees, management experts, journalists, and opportunityandlittleriskintheUS,’’he historians of business, technology, and com- wrote, ‘‘while it was hard to imagine us getting puting have all made important contributions anywhere abroad. Latin America, for example to our understanding of IBM’s past.3 Some seemed like a bottomless pit.’’1 However, the works have explored company operations senior Watson had a different sense of the outside the US in detail.4 However, most of potential for profit within the world market these studies do not address company activi- and believed that one day IBM’s sales abroad ties in regions of the developing world, such as would surpass its growing domestic business. Latin America.5 Chile, a slender South Amer- In 1949, he created the IBM World Trade ican country bordered by the Pacific Ocean on Corporation to coordinate the company’s one side and the Andean cordillera on the activities outside the US and appointed his other, offers a rich site for studying IBM younger son, Arthur K. -

The Evolution of Ibm Research Looking Back at 50 Years of Scientific Achievements and Innovations
FEATURES THE EVOLUTION OF IBM RESEARCH LOOKING BACK AT 50 YEARS OF SCIENTIFIC ACHIEVEMENTS AND INNOVATIONS l Chris Sciacca and Christophe Rossel – IBM Research – Zurich, Switzerland – DOI: 10.1051/epn/2014201 By the mid-1950s IBM had established laboratories in New York City and in San Jose, California, with San Jose being the first one apart from headquarters. This provided considerable freedom to the scientists and with its success IBM executives gained the confidence they needed to look beyond the United States for a third lab. The choice wasn’t easy, but Switzerland was eventually selected based on the same blend of talent, skills and academia that IBM uses today — most recently for its decision to open new labs in Ireland, Brazil and Australia. 16 EPN 45/2 Article available at http://www.europhysicsnews.org or http://dx.doi.org/10.1051/epn/2014201 THE evolution OF IBM RESEARCH FEATURES he Computing-Tabulating-Recording Com- sorting and disseminating information was going to pany (C-T-R), the precursor to IBM, was be a big business, requiring investment in research founded on 16 June 1911. It was initially a and development. Tmerger of three manufacturing businesses, He began hiring the country’s top engineers, led which were eventually molded into the $100 billion in- by one of world’s most prolific inventors at the time: novator in technology, science, management and culture James Wares Bryce. Bryce was given the task to in- known as IBM. vent and build the best tabulating, sorting and key- With the success of C-T-R after World War I came punch machines. -

Property Graph Vs RDF Triple Store: a Comparison on Glycan Substructure Search
RESEARCH ARTICLE Property Graph vs RDF Triple Store: A Comparison on Glycan Substructure Search Davide Alocci1,2, Julien Mariethoz1, Oliver Horlacher1,2, Jerven T. Bolleman3, Matthew P. Campbell4, Frederique Lisacek1,2* 1 Proteome Informatics Group, SIB Swiss Institute of Bioinformatics, Geneva, 1211, Switzerland, 2 Computer Science Department, University of Geneva, Geneva, 1227, Switzerland, 3 Swiss-Prot Group, SIB Swiss Institute of Bioinformatics, Geneva, 1211, Switzerland, 4 Department of Chemistry and Biomolecular Sciences, Macquarie University, Sydney, Australia * [email protected] Abstract Resource description framework (RDF) and Property Graph databases are emerging tech- nologies that are used for storing graph-structured data. We compare these technologies OPEN ACCESS through a molecular biology use case: glycan substructure search. Glycans are branched Citation: Alocci D, Mariethoz J, Horlacher O, tree-like molecules composed of building blocks linked together by chemical bonds. The Bolleman JT, Campbell MP, Lisacek F (2015) molecular structure of a glycan can be encoded into a direct acyclic graph where each node Property Graph vs RDF Triple Store: A Comparison on Glycan Substructure Search. PLoS ONE 10(12): represents a building block and each edge serves as a chemical linkage between two build- e0144578. doi:10.1371/journal.pone.0144578 ing blocks. In this context, Graph databases are possible software solutions for storing gly- Editor: Manuela Helmer-Citterich, University of can structures and Graph query languages, such as SPARQL and Cypher, can be used to Rome Tor Vergata, ITALY perform a substructure search. Glycan substructure searching is an important feature for Received: July 16, 2015 querying structure and experimental glycan databases and retrieving biologically meaning- ful data. -
Introduction to Query Processing and Optimization
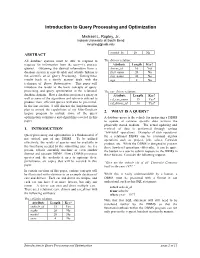
Introduction to Query Processing and Optimization Michael L. Rupley, Jr. Indiana University at South Bend [email protected] owned_by 10 No ABSTRACT All database systems must be able to respond to The drivers relation: requests for information from the user—i.e. process Attribute Length Key? queries. Obtaining the desired information from a driver_id 10 Yes database system in a predictable and reliable fashion is first_name 20 No the scientific art of Query Processing. Getting these last_name 20 No results back in a timely manner deals with the age 2 No technique of Query Optimization. This paper will introduce the reader to the basic concepts of query processing and query optimization in the relational The car_driver relation: database domain. How a database processes a query as Attribute Length Key? well as some of the algorithms and rule-sets utilized to cd_car_name 15 Yes* produce more efficient queries will also be presented. cd_driver_id 10 Yes* In the last section, I will discuss the implementation plan to extend the capabilities of my Mini-Database Engine program to include some of the query 2. WHAT IS A QUERY? optimization techniques and algorithms covered in this A database query is the vehicle for instructing a DBMS paper. to update or retrieve specific data to/from the physically stored medium. The actual updating and 1. INTRODUCTION retrieval of data is performed through various “low-level” operations. Examples of such operations Query processing and optimization is a fundamental, if for a relational DBMS can be relational algebra not critical, part of any DBMS. To be utilized operations such as project, join, select, Cartesian effectively, the results of queries must be available in product, etc. -

Treatment and Differential Diagnosis Insights for the Physician's
Treatment and differential diagnosis insights for the physician’s consideration in the moments that matter most The role of medical imaging in global health systems is literally fundamental. Like labs, medical images are used at one point or another in almost every high cost, high value episode of care. Echocardiograms, CT scans, mammograms, and x-rays, for example, “atlas” the body and help chart a course forward for a patient’s care team. Imaging precision has improved as a result of technological advancements and breakthroughs in related medical research. Those advancements also bring with them exponential growth in medical imaging data. The capabilities referenced throughout this document are in the research and development phase and are not available for any use, commercial or non-commercial. Any statements and claims related to the capabilities referenced are aspirational only. There were roughly 800 million multi-slice exams performed in the United States in 2015 alone. Those studies generated approximately 60 billion medical images. At those volumes, each of the roughly 31,000 radiologists in the U.S. would have to view an image every two seconds of every working day for an entire year in order to extract potentially life-saving information from a handful of images hidden in a sea of data. 31K 800MM 60B radiologists exams medical images What’s worse, medical images remain largely disconnected from the rest of the relevant data (lab results, patient-similar cases, medical research) inside medical records (and beyond them), making it difficult for physicians to place medical imaging in the context of patient histories that may unlock clues to previously unconsidered treatment pathways. -

Cell Broadband Engine Spencer Dennis Nicholas Barlow the Cell Processor
Cell Broadband Engine Spencer Dennis Nicholas Barlow The Cell Processor ◦ Objective: “[to bring] supercomputer power to everyday life” ◦ Bridge the gap between conventional CPU’s and high performance GPU’s History Original patent application in 2002 Generations ◦ 90 nm - 2005 ◦ 65 nm - 2007 (PowerXCell 8i) ◦ 45 nm - 2009 Cost $400 Million to develop Team of 400 engineers STI Design Center ◦ Sony ◦ Toshiba ◦ IBM Design PS3 Employed as CPU ◦ Clocked at 3.2 GHz ◦ theoretical maximum performance of 23.04 GFLOPS Utilized alongside NVIDIA RSX 'Reality Synthesizer' GPU ◦ Complimented graphical performance ◦ 8 Synergistic Processing Elements (SPE) ◦ Single Dual Issue Power Processing Element (PPE) ◦ Memory IO Controller (MIC) ◦ Element Interconnect Bus (EIB) ◦ Memory IO Controller (MIC) ◦ Bus Interface Controller (BIC) Architecture Overview SPU/SPE Synergistic Processing Unit/Element SXU - Synergistic Execution Unit LS - Local Store SMF - Synergistic Memory Frontend EIB - Element Interconnect Bus PPE - Power Processing Element MIC - Memory IO Controller BIC - Bus Interface Controller Synergistic Processing Element (SPE) 128-bit dual-issue SIMD dataflow ○ “Single Instruction Multiple Data” ○ Optimized for data-level parallelism ○ Designed for vectorized floating point calculations. ◦ Workhorses of the Processor ◦ Handle most of the computational workload ◦ Each contains its own Instruction + Data Memory ◦ “Local Store” ▫ Embedded SRAM SPE Continued Responsible for governing SPEs ◦ “Extensions” of the PPE Shares main memory with SPE ◦ can initiate -

Application of Graph Databases for Static Code Analysis of Web-Applications
Application of Graph Databases for Static Code Analysis of Web-Applications Daniil Sadyrin [0000-0001-5002-3639], Andrey Dergachev [0000-0002-1754-7120], Ivan Loginov [0000-0002-6254-6098], Iurii Korenkov [0000-0002-8948-2776], and Aglaya Ilina [0000-0003-1866-7914] ITMO University, Kronverkskiy prospekt, 49, St. Petersburg, 197101, Russia [email protected], [email protected], [email protected], [email protected], [email protected] Abstract. Graph databases offer a very flexible data model. We present the approach of static code analysis using graph databases. The main stage of the analysis algorithm is the construction of ASG (Abstract Source Graph), which represents relationships between AST (Abstract Syntax Tree) nodes. The ASG is saved to a graph database (like Neo4j) and queries to the database are made to get code properties for analysis. The approach is applied to detect and exploit Object Injection vulnerability in PHP web-applications. This vulnerability occurs when unsanitized user data enters PHP unserialize function. Successful exploitation of this vulnerability means building of “object chain”: a nested object, in the process of deserializing of it, a sequence of methods is being called leading to dangerous function call. In time of deserializing, some “magic” PHP methods (__wakeup or __destruct) are called on the object. To create the “object chain”, it’s necessary to analyze methods of classes declared in web-application, and find sequence of methods called from “magic” methods. The main idea of author’s approach is to save relationships between methods and functions in graph database and use queries to the database on Cypher language to find appropriate method calls.