Transformer-Based Multilingual Indic-English Neural Machine Translation System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cross-Language Framework for Word Recognition and Spotting of Indic Scripts
Cross-language Framework for Word Recognition and Spotting of Indic Scripts aAyan Kumar Bhunia, bPartha Pratim Roy*, aAkash Mohta, cUmapada Pal aDept. of ECE, Institute of Engineering & Management, Kolkata, India bDept. of CSE, Indian Institute of Technology Roorkee India cCVPR Unit, Indian Statistical Institute, Kolkata, India bemail: [email protected], TEL: +91-1332-284816 Abstract Handwritten word recognition and spotting of low-resource scripts are difficult as sufficient training data is not available and it is often expensive for collecting data of such scripts. This paper presents a novel cross language platform for handwritten word recognition and spotting for such low-resource scripts where training is performed with a sufficiently large dataset of an available script (considered as source script) and testing is done on other scripts (considered as target script). Training with one source script and testing with another script to have a reasonable result is not easy in handwriting domain due to the complex nature of handwriting variability among scripts. Also it is difficult in mapping between source and target characters when they appear in cursive word images. The proposed Indic cross language framework exploits a large resource of dataset for training and uses it for recognizing and spotting text of other target scripts where sufficient amount of training data is not available. Since, Indic scripts are mostly written in 3 zones, namely, upper, middle and lower, we employ zone-wise character (or component) mapping for efficient learning purpose. The performance of our cross- language framework depends on the extent of similarity between the source and target scripts. -

The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes
Portland State University PDXScholar Mathematics and Statistics Faculty Fariborz Maseeh Department of Mathematics Publications and Presentations and Statistics 3-2018 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hu Sun University of Macau Christine Chambris Université de Cergy-Pontoise Judy Sayers Stockholm University Man Keung Siu University of Hong Kong Jason Cooper Weizmann Institute of Science SeeFollow next this page and for additional additional works authors at: https:/ /pdxscholar.library.pdx.edu/mth_fac Part of the Science and Mathematics Education Commons Let us know how access to this document benefits ou.y Citation Details Sun X.H. et al. (2018) The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes. In: Bartolini Bussi M., Sun X. (eds) Building the Foundation: Whole Numbers in the Primary Grades. New ICMI Study Series. Springer, Cham This Book Chapter is brought to you for free and open access. It has been accepted for inclusion in Mathematics and Statistics Faculty Publications and Presentations by an authorized administrator of PDXScholar. Please contact us if we can make this document more accessible: [email protected]. Authors Xu Hu Sun, Christine Chambris, Judy Sayers, Man Keung Siu, Jason Cooper, Jean-Luc Dorier, Sarah Inés González de Lora Sued, Eva Thanheiser, Nadia Azrou, Lynn McGarvey, Catherine Houdement, and Lisser Rye Ejersbo This book chapter is available at PDXScholar: https://pdxscholar.library.pdx.edu/mth_fac/253 Chapter 5 The What and Why of Whole Number Arithmetic: Foundational Ideas from History, Language and Societal Changes Xu Hua Sun , Christine Chambris Judy Sayers, Man Keung Siu, Jason Cooper , Jean-Luc Dorier , Sarah Inés González de Lora Sued , Eva Thanheiser , Nadia Azrou , Lynn McGarvey , Catherine Houdement , and Lisser Rye Ejersbo 5.1 Introduction Mathematics learning and teaching are deeply embedded in history, language and culture (e.g. -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies
The Kharoṣṭhī Documents from Niya and Their Contribution to Gāndhārī Studies Stefan Baums University of Munich [email protected] Niya Document 511 recto 1. viśu͚dha‐cakṣ̄u bhavati tathāgatānaṃ bhavatu prabhasvara hiterṣina viśu͚dha‐gātra sukhumāla jināna pūjā suchavi paramārtha‐darśana 4 ciraṃ ca āyu labhati anālpakaṃ 5. pratyeka‐budha ca karoṃti yo s̄ātravivegam āśṛta ganuktamasya 1 ekābhirāma giri‐kaṃtarālaya 2. na tasya gaṃḍa piṭakā svakartha‐yukta śamathe bhavaṃti gune rata śilipataṃ tatra vicārcikaṃ teṣaṃ pi pūjā bhavatu [v]ā svayaṃbhu[na] 4 1 suci sugaṃdha labhati sa āśraya 6. koḍinya‐gotra prathamana karoṃti yo s̄ātraśrāvaka {?} ganuktamasya 2 teṣaṃ ca yo āsi subha͚dra pac̄ima 3. viśāla‐netra bhavati etasmi abhyaṃdare ye prabhasvara atīta suvarna‐gātra abhirūpa jinorasa te pi bhavaṃtu darśani pujita 4 2 samaṃ ca pādo utarā7. imasmi dāna gana‐rāya prasaṃṭ́hita u͚tama karoṃti yo s̄ātra sthaira c̄a madhya navaka ganuktamasya 3 c̄a bhikṣ̄u m It might be going to far to say that Torwali is the direct lineal descendant of the Niya Prakrit, but there is no doubt that out of all the modern languages it shows the closest resemblance to it. [...] that area around Peshawar, where [...] there is most reason to believe was the original home of Niya Prakrit. That conclusion, which was reached for other reasons, is thus confirmed by the distribution of the modern dialects. (Burrow 1936) Under this name I propose to include those inscriptions of Aśoka which are recorded at Shahbazgaṛhi and Mansehra in the Kharoṣṭhī script, the vehicle for the remains of much of this dialect. To be included also are the following sources: the Buddhist literary text, the Dharmapada found in Khotan, written likewise in Kharoṣṭhī [...]; the Kharoṣṭhī documents on wood, leather, and silk from Caḍ́ota (the Niya site) on the border of the ancient kingdom of Khotan, which represented the official language of the capital Krorayina [...]. -

Inflectional Morphology Analyzer for Sanskrit
Inflectional Morphology Analyzer for Sanskrit Girish Nath Jha, Muktanand Agrawal, Subash, Sudhir K. Mishra, Diwakar Mani, Diwakar Mishra, Manji Bhadra, Surjit K. Singh [email protected] Special Centre for Sanskrit Studies Jawaharlal Nehru University New Delhi-110067 The paper describes a Sanskrit morphological analyzer that identifies and analyzes inflected noun- forms and verb-forms in any given sandhi-free text. The system which has been developed as java servlet RDBMS can be tested at http://sanskrit.jnu.ac.in (Language Processing Tools > Sanskrit Tinanta Analyzer/Subanta Analyzer) with Sanskrit data as unicode text. Subsequently, the separate systems of subanta and ti anta will be combined into a single system of sentence analysis with karaka interpretation. Currently, the system checks and labels each word as three basic POS categories - subanta, ti anta, and avyaya. Thereafter, each subanta is sent for subanta processing based on an example database and a rule database. The verbs are examined based on a database of verb roots and forms as well by reverse morphology based on Pāini an techniques. Future enhancements include plugging in the amarakosha ( http://sanskrit.jnu.ac.in/amara ) and other noun lexicons with the subanta system. The ti anta will be enhanced by the k danta analysis module being developed separately. 1. Introduction The authors in the present paper are describing the subanta and ti anta analysis systems for Sanskrit which are currently running at http://sanskrit.jnu.ac.in . Sanskrit is a heavily inflected language, and depends on nominal and verbal inflections for communication of meaning. A fully inflected unit is called pada . -

Sanskrit Translation Now Made, Be Crowned with Success ! PUBLISHER's NOTE
“KOHAM?” (Who am I ?) Sri Ramanasramam Tiruvannamalai - 606 603. 2008 Koham ? (Who am I ?) Published by V. S. Ramanan, President, Sri Ramanasramam, Tiruvannamalai - 606 603. Phone : 04175-237200 email : [email protected] Website : www.sriramanamaharshi.org © Sri Ramanasramam Tiruvannamalai. Salutations to Sri Ramana Who resides in the Heart Lotus PREFACE TO THE FIRST EDITION Many were the devotees who were attracted to the presence of Bhagavan Sri Ramana while he was living in the Virupaksha Cave, situated in the holy region of Arunachala, the Heart Centre of the world, which confers liberation on those who (merely) think of It. They were drawn to him on account of his wonderful state of tapas - absorption in the silence of yoga samadhi, which is difficult of achievement. One among these devotees was Sivaprakasam Pillai who approached Maharshi in 1901-02 with devotion, faith and humility and prayed that he may be blessed with instructions on Reality. The questions raised over a period of time by Sivaprakasam Pillai were answered by the silent Maharshi in writing - in Tamil. The compilation (of the instruction) in the form of questions and answers has already been translated into Malayalam and many other languages. May this Sanskrit translation now made, be crowned with success ! PUBLISHER'S NOTE The Sanskrit translation of Sri Bhagavan's Who am I ? entitled Koham? by Jagadiswara Sastry was published earlier in 1945. We are happy to bring out a second edition. The special feature of this edition is that the text is in Sri Bhagavan's handwriting. A transliteration of the text into English has also been provided. -

Vidyut Documentation
Vidyut A Phonetic Keyboard for Sanskrit Developers: Adolf von Württemberg ([email protected]) Les Morgan ([email protected]) Download: http://www.mywhatever.com/sanskrit/vidyut Current version: 5.0 (August 27, 2010) Requirements: Windows XP, Vista, Windows 7; 32-bit or 64-bit License: Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported http://creativecommons.org/licenses/by-nc-sa/3.0/ Vidyut Keyboard, Version 5 (Documentation as of 17 September 2010) Page 1 Contents Overview and Key Features ...................................................................................................................................... 3 Font Issues ................................................................................................................................................................... 5 Installation instructions ............................................................................................................................................. 6 Typing Method ......................................................................................................................................................... 15 Customization ........................................................................................................................................................... 18 Keyboard Encoding Table (in Keyboard key order) ............................................................................................ 19 Keyboard Layout ..................................................................................................................................................... -

Devan¯Agar¯I for TEX Version 2.17.1
Devanagar¯ ¯ı for TEX Version 2.17.1 Anshuman Pandey 6 March 2019 Contents 1 Introduction 2 2 Project Information 3 3 Producing Devan¯agar¯ıText with TEX 3 3.1 Macros and Font Definition Files . 3 3.2 Text Delimiters . 4 3.3 Example Input Files . 4 4 Input Encoding 4 4.1 Supplemental Notes . 4 5 The Preprocessor 5 5.1 Preprocessor Directives . 7 5.2 Protecting Text from Conversion . 9 5.3 Embedding Roman Text within Devan¯agar¯ıText . 9 5.4 Breaking Pre-Defined Conjuncts . 9 5.5 Supported LATEX Commands . 9 5.6 Using Custom LATEX Commands . 10 6 Devan¯agar¯ıFonts 10 6.1 Bombay-Style Fonts . 11 6.2 Calcutta-Style Fonts . 11 6.3 Nepali-Style Fonts . 11 6.4 Devan¯agar¯ıPen Fonts . 11 6.5 Default Devan¯agar¯ıFont (LATEX Only) . 12 6.6 PostScript Type 1 . 12 7 Special Topics 12 7.1 Delimiter Scope . 12 7.2 Line Spacing . 13 7.3 Hyphenation . 13 7.4 Captions and Date Formats (LATEX only) . 13 7.5 Customizing the date and captions (LATEX only) . 14 7.6 Using dvnAgrF in Sections and References (LATEX only) . 15 7.7 Devan¯agar¯ıand Arabic Numerals . 15 7.8 Devan¯agar¯ıPage Numbers and Other Counters (LATEX only) . 15 1 7.9 Category Codes . 16 8 Using Devan¯agar¯ıin X E LATEXand luaLATEX 16 8.1 Using Hindi with Polyglossia . 17 9 Using Hindi with babel 18 9.1 Installation . 18 9.2 Usage . 18 9.3 Language attributes . 19 9.3.1 Attribute modernhindi . -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

Tibetan Romanization Table
Tibetan Comment [LRH1]: Transliteration revisions are highlighted below in light-gray or otherwise noted in a comment. ALA-LC romanization of Tibetan letters follows the principles of the Wylie transliteration system, as described by Turrell Wylie (1959). Diacritical marks are used for those letters representing Indic or other non-Tibetan languages, and parallel the use of these marks when transcribing their counterpart letters in Sanskrit. These are applied for the sake of consistency, and to reflect international publishing standards. Accordingly, romanize words of non-Tibetan origin systematically (following this table) in all cases, even though the word may derive from Sanskrit or another language. When Tibetan is written in another script (e.g., ʼPhags-pa) the corresponding letters in that script are also romanized according to this table. Consonants (see Notes 1-3) Vernacular Romanization Vernacular Romanization Vernacular Romanization ka da zha ཀ་ ད་ ཞ་ kha na za ཁ་ ན་ ཟ་ Comment [LH2]: While the current ALA-LC ga pa ’a table stipulates that an apostrophe should be used, ག་ པ་ འ་ this revision proposal recommends that the long- nga pha ya standing defacto LC practice of using an alif (U+02BC) be continued and explicitly stipulated in ང་ ཕ་ ཡ་ the Table. See accompanying Narrative for details. ca ba ra ཅ་ བ་ ར་ cha ma la ཆ་ མ་ ལ་ ja tsa sha ཇ་ ཙ་ ཤ་ nya tsha sa ཉ་ ཚ་ ས་ ta dza ha ཏ་ ཛ་ ཧ་ tha wa a ཐ་ ཝ་ ཨ་ Vowels and Diphthongs (see Notes 4 and 5) ཨི་ i ཨཱི་ ī རྀ་ r̥ ཨུ་ u ཨཱུ་ ū རཱྀ་ r̥̄ ཨེ་ e ཨཻ་ ai ལྀ་ ḷ ཨོ་ o ཨཽ་ au ལཱྀ ḹ ā ཨཱ་ Other Letters or Diacritical Marks Used in Words of Non-Tibetan Origin (see Notes 6 and 7) ṭa gha ḍha ཊ་ གྷ་ ཌྷ་ ṭha jha anusvāra ṃ Comment [LH3]: This letter combination does ཋ་ ཇྷ་ ◌ ཾ not occur in Tibetan texts, and has been deprecated from the Unicode Standard. -
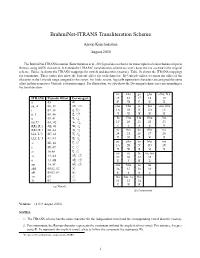
Brahminet-ITRANS Transliteration Scheme
BrahmiNet-ITRANS Transliteration Scheme Anoop Kunchukuttan August 2020 The BrahmiNet-ITRANS notation (Kunchukuttan et al., 2015) provides a scheme for transcription of major Indian scripts in Roman, using ASCII characters. It extends the ITRANS1 transliteration scheme to cover characters not covered in the original scheme. Tables 1a shows the ITRANS mappings for vowels and diacritics (matras). Table 1b shows the ITRANS mappings for consonants. These tables also show the Unicode offset for each character. By Unicode offset, we mean the offset of the character in the Unicode range assigned to the script. For Indic scripts, logically equivalent characters are assigned the same offset in their respective Unicode codepoint ranges. For illustration, we also show the Devanagari characters corresponding to the transliteration. ka kha ga gha ∼Na, N^a ITRANS Unicode Offset Devanagari 15 16 17 18 19 a 05 अ क ख ग घ ङ aa, A 06, 3E आ, ◌ा cha Cha ja jha ∼na, JNa i 07, 3F इ, ि◌ 1A 1B 1C 1D 1E ii, I 08, 40 ई, ◌ी च छ ज झ ञ u 09, 41 उ, ◌ु Ta Tha Da Dha Na uu, U 0A, 42 ऊ, ◌ू 1F 20 21 22 23 RRi, R^i 0B, 43 ऋ, ◌ृ ट ठ ड ढ ण RRI, R^I 60, 44 ॠ, ◌ॄ ta tha da dha na LLi, L^i 0C, 62 ऌ, ◌ॢ 24 25 26 27 28 LLI, L^I 61, 63 ॡ, ◌ॣ त थ द ध न pa pha ba bha ma .e 0E, 46 ऎ, ◌ॆ 2A 2B 2C 2D 2E e 0F, 47 ए, ◌े प फ ब भ म ai 10,48 ऐ, ◌ै ya ra la va, wa .o 12, 4A ऒ, ◌ॊ 2F 30 32 35 o 13, 4B ओ, ◌ो य र ल व au 14, 4C औ, ◌ौ sha Sha sa ha aM 05 02, 02 अं 36 37 38 39 aH 05 03, 03 अः श ष स ह .m 02 ◌ं Ra lda, La zha .h 03 ◌ः 31 33 34 (a) Vowels ऱ ळ ऴ (b) Consonants Version: v1.0 (9 August 2020) NOTES: 1. -

Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati
Component-I (A) – Personal details: Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati. Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati. & Dr. K. Muniratnam Director i/c, Epigraphy, ASI, Mysore Dr. Sayantani Pal Dept. of AIHC, University of Calcutta. Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati. Component-I (B) – Description of module: Subject Name Indian Culture Paper Name Indian Epigraphy Module Name/Title Kharosthi Script Module Id IC / IEP / 15 Pre requisites Kharosthi Script – Characteristics – Origin – Objectives Different Theories – Distribution and its End Keywords E-text (Quadrant-I) : 1. Introduction Kharosthi was one of the major scripts of the Indian subcontinent in the early period. In the list of 64 scripts occurring in the Lalitavistara (3rd century CE), a text in Buddhist Hybrid Sanskrit, Kharosthi comes second after Brahmi. Thus both of them were considered to be two major scripts of the Indian subcontinent. Both Kharosthi and Brahmi are first encountered in the edicts of Asoka in the 3rd century BCE. 2. Discovery of the script and its Decipherment The script was first discovered on one side of a large number of coins bearing Greek legends on the other side from the north western part of the Indian subcontinent in the first quarter of the 19th century. Later in 1830 to 1834 two full inscriptions of the time of Kanishka bearing the same script were found at Manikiyala in Pakistan. After this discovery James Prinsep named the script as ‘Bactrian Pehelevi’ since it occurred on a number of so called ‘Bactrian’ coins. To James Prinsep the characters first looked similar to Pahlavi (Semitic) characters.