A Dynamic Feature Selection Based LDA Approach to Baseball Pitch Prediction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Past CB Pitching Coaches of Year
Collegiate Baseball The Voice Of Amateur Baseball Started In 1958 At The Request Of Our Nation’s Baseball Coaches Vol. 62, No. 1 Friday, Jan. 4, 2019 $4.00 Mike Martin Has Seen It All As A Coach Bus driver dies of heart attack Yastrzemski in the ninth for the game winner. Florida State ultimately went 51-12 during the as team bus was traveling on a 1980 season as the Seminoles won 18 of their next 7-lane highway next to ocean in 19 games after those two losses at Miami. San Francisco, plus other tales. Martin led Florida State to 50 or more wins 12 consecutive years to start his head coaching career. By LOU PAVLOVICH, JR. Entering the 2019 season, he has a 1,987-713-4 Editor/Collegiate Baseball overall record. Martin has the best winning percentage among ALLAHASSEE, Fla. — Mike Martin, the active head baseball coaches, sporting a .736 mark winningest head coach in college baseball to go along with 16 trips to the College World Series history, will cap a remarkable 40-year and 39 consecutive regional appearances. T Of the 3,981 baseball games played in FSU coaching career in 2019 at Florida St. University. He only needs 13 more victories to be the first history, Martin has been involved in 3,088 of those college coach in any sport to collect 2,000 wins. in some capacity as a player or coach. What many people don’t realize is that he started He has been on the field or in the dugout for 2,271 his head coaching career with two straight losses at of the Seminoles’ 2,887 all-time victories. -

RBBA Coaches Handbook
RBBA Coaches Handbook The handbook is a reference of suggestions which provides: - Rule changes from year to year - What to emphasize that season broken into: Base Running, Batting, Catching, Fielding and Pitching By focusing on these areas coaches can build on skills from year to year. 1 Instructional – 1st and 2nd grade Batting - Timing Base Running - Listen to your coaches Catching - “Trust the equipment” - Catch the ball, throw it back Fielding - Always use two hands Pitching – fielding the position - Where to safely stand in relation to pitching machine 2 Rookies – 3rd grade Rule Changes - Pitching machine is replaced with live, player pitching - Pitch count has been added to innings count for pitcher usage (Spring 2017) o Pitch counters will be provided o See “Pitch Limits & Required Rest Periods” at end of Handbook - Maximum pitches per pitcher is 50 or 2 innings per day – whichever comes first – and 4 innings per week o Catching affects pitching. Please limit players who pitch and catch in the same game. It is good practice to avoid having a player catch after pitching. *See Catching/Pitching notations on the “Pitch Limits & Required Rest Periods” at end of Handbook. - Pitchers may not return to game after pitching at any point during that game Emphasize-Teach-Correct in the Following Areas – always continue working on skills from previous seasons Batting - Emphasize a smooth, quick level swing (bat speed) o Try to minimize hitches and inefficiencies in swings Base Running - Do not watch the batted ball and watch base coaches - Proper sliding - On batted balls “On the ground, run around. -

The Bloody Nose
THE BLOODY NOSE AND OTHER STORIES A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Fine Arts Emily D. Dressler May, 2008 THE BLOODY NOSE AND OTHER STORIES Emily D. Dressler Thesis Approved: Accepted: _________________________ ___________________________ Advisor Department Chair Mr. Robert Pope Dr. Diana Reep __________________________ ___________________________ Faculty Reader Dean of the College Dr. Mary Biddinger Dr. Ronald F. Levant __________________________ __________________________ Faculty Reader Dean of the Graduate School Dr. Robert Miltner Dr. George R. Newkome ___________________________ ___________________________ Faculty Reader Date Dr. Alan Ambrisco ii ACKNOWLEDGEMENTS The following stories have previously appeared in the following publications: “The Drought,” Barn Owl Review #1; “The Winters,” akros review vol. 35; “An Old Sock and a Handful of Rocks,” akros review vol. 34 and “Flint’s Fire,” akros review vol. 34. iii TABLE OF CONTENTS Page PART I. HELEN……………………………………………………………………………….1 The Bloody Nose……………………………………………………………………......2 Butterscotch………………………………………………………………………….....17 Makeup…………………………………………………………………………………29 The Magic Show………………………………………………………………………..44 The Drought…………………………………………………………………………….65 Important and Cold……………………………………………………………………..77 Someone Else…………………………………………………………………………...89 II. SHORTS…………………………………………………………………………….100 An Old Sock and a Handful of Rocks………………………………………………….101 Adagio………………………………………………………………………………….105 -

Describing Baseball Pitch Movement with Right-Hand Rules
Computers in Biology and Medicine 37 (2007) 1001–1008 www.intl.elsevierhealth.com/journals/cobm Describing baseball pitch movement with right-hand rules A. Terry Bahilla,∗, David G. Baldwinb aSystems and Industrial Engineering, University of Arizona, Tucson, AZ 85721-0020, USA bP.O. Box 190 Yachats, OR 97498, USA Received 21 July 2005; received in revised form 30 May 2006; accepted 5 June 2006 Abstract The right-hand rules show the direction of the spin-induced deflection of baseball pitches: thus, they explain the movement of the fastball, curveball, slider and screwball. The direction of deflection is described by a pair of right-hand rules commonly used in science and engineering. Our new model for the magnitude of the lateral spin-induced deflection of the ball considers the orientation of the axis of rotation of the ball relative to the direction in which the ball is moving. This paper also describes how models based on somatic metaphors might provide variability in a pitcher’s repertoire. ᭧ 2006 Elsevier Ltd. All rights reserved. Keywords: Curveball; Pitch deflection; Screwball; Slider; Modeling; Forces on a baseball; Science of baseball 1. Introduction The angular rule describes angular relationships of entities rel- ative to a given axis and the coordinate rule establishes a local If a major league baseball pitcher is asked to describe the coordinate system, often based on the axis derived from the flight of one of his pitches; he usually illustrates the trajectory angular rule. using his pitching hand, much like a kid or a jet pilot demon- Well-known examples of right-hand rules used in science strating the yaw, pitch and roll of an airplane. -

Baseball Player of the Year: Cam Collier, Mount Paran Christian | Sports | Mdjonline.Com
6/21/2021 Baseball Player of the Year: Cam Collier, Mount Paran Christian | Sports | mdjonline.com https://www.mdjonline.com/sports/baseball-player-of-the-year-cam-collier-mount-paran-christian/article_052675aa- d065-11eb-bf91-f7bd899a73a0.html FEATURED TOP STORY Baseball Player of the Year: Cam Collier, Mount Paran Christian By Christian Knox MDJ Sports Writer Jun 18, 2021 Cam Collier watches a fly ball to center during the first game of Mount Paran Christian’s Class A Private state championship Cam Collier has no shortage of tools, and he displays them all around the diamond. In 2021, the Mount Paran Christian sophomore showed a diverse pitching arsenal that left opponents guessing, home run power as a batter, defensive consistency as a third baseman and the agility of a gazelle as a runner. https://www.mdjonline.com/sports/baseball-player-of-the-year-cam-collier-mount-paran-christian/article_052675aa-d065-11eb-bf91-f7bd899a73a0.html 1/5 6/21/2021 Baseball Player of the Year: Cam Collier, Mount Paran Christian | Sports | mdjonline.com However, Collier’s greatest skill is not limited to the position he is playing at any given time. He carries a finisher’s mentality all over the field. “He wants the better, the harder situation. The more difficult the situation, the more he enjoys it,” Mount Paran coach Kyle Reese said. “You run across those (difficult) paths a lot of the time, and Cam is a guy that absolutely thrives in them. Whether he is in the batter’s box or on the mound, the game’s on the line, he wants to determine the outcome of the game. -

Complete Game.5.4.19
COMPLETE GAME A Play in Nine Innings by Mark Liebert Mark Liebert 69 Fairway Avenue Verona, NJ 07044 201-207-4785 [email protected] Copyright by the author 2019 WARM UP PITCH: CASEY AT THE BAT, Sunday 9/26/20 FIRST INNING: NO JOY IN MUDVILLE, Friday 9/25/70 SECOND INNING: CRUNCH TIME, Saturday afternoon 9/26/70 THIRD INNING: TAKE ME OUT TO THE BALL GAME, Saturday evening 9/26/70 FOURTH INNING: PITCHING IN THE MIRROR, Saturday 10/3/70 FIFTH INNING: FATHER AND SON GAME, Sunday 10/4/70 SIXTH INNING: TURNING TWO, Saturday 10/17/70 SEVENTH INNING: IT'S A STRETCH, Saturday 10/24/70 EIGHTH INNING: TIE GAME, Sunday 11/8/18 NINTH INNING: THE CLOSER, Sunday 11/8/18 SETTING TIME: The fall of 1970 PLACE: 5 different locations in metropolitan NYC PRODUCTION NOTES All scenes use a couch, chair, coffee table, end table and tv rearranged to depict the five different locations. the tv may be real or imagined. additional pieces may be used, but not to the detriment of keeping the scene changes quick and interrupting the flow. It can be performed with or without an intermission. If you choose to use an intermission it should come between the fifth and sixth innings. CAST OF CHARACTERS (IN ORDER OF APPEARANCE) CASEY O'NEILL: MALE, 78, OF "CASEY AT THE BAT" FAME STASH JENGLESKI: MALE, 84, THE PITCHER WHO STRUCK HIM OUT MAX: MALE, 57, AN OBSESSIVE BASEBALL FAN SARAH: FEMALE, 51, MAX'S WIFE ALI: FEMALE, 28 JESS: FEMALE, 28, ALI'S BEST FRIEND JAKE: MALE, 50 TILLIE: FEMALE, 78, JAKE'S MOTHER SAUL: MALE, 90, A RESIDENT OF A NURSING HOME WITH DEMENTIA CHUCK: MALE, 58, SAUL'S SON SANDY: MALE, 30 COMPLETE GAME: WARM UP PITCH “Take Me Out to the Ballgame” is heard, the silhouette lights come up as the song ends. -

Sioux Falls Canaries Baseball
SIOUX FALLS CANARIES BASEBALL VS 34-47 53-29 5th in South, 12.5 GB 1st in North CANARIES INFORMATION LAST TIME OUT Sioux City 12, Canaries 5 ON THE MOUND STAFF The Birds came up short against #32 / RHP General Manager: Duell Higbe the Sioux City Explorers Tuesday, splitting the two-game midweek se- Mark Field Manager: Mike Meyer ries between the two teams. Clint Seyler Pitching Coach: Ben Moore Coulter hit his third home run in as Height: 6-2 many games in the defeat. Weight: 190 Hitting Coach: Mitch Glasser DOB: Feb. 2, 1994 Canaries starter Alex Boshers com- Hometown: Ballpark: Sioux Falls Stadium pleted seven innings, allowing four Agoura Hills, CA Address: 1001 N. West Ave. runs on eight hits. Boshers struck out a season-high eight Explorers. Sioux Falls, SD 57104 It’s the third time this season Bosh- 2019 STATISTICS Phone: 605-336-6060 ers has struck out eight batters. The bullpen wasn’t as dominant. G/GS Rec. ERA WHIP BAA They allowed eight runs in the last 19/11 3-6 7.23 1.77 .334 two innings. Listen to the Canaries LIVE... Kevin Taylor bounced back from IP H BB K HR Monday’s 1-for-4 performance with 79.2 112 29 44 12 a 4-for-4 afternoon. 2019 CANARIES ROSTER ...on KWSN and KWSN.com Watch the Canaries LIVE! AmericanAssociationBaseball.tv FOLLOW THE BIRDS! Sioux Falls Canaries @Canaries Canaries_baseball LEAGUE STANDINGS (Top two in each division make the playoffs) BIRDS STORY LINES DAKOTA RIVALS MEET AGAIN NORTH W-L GB The Birds are making their first trip to Fargo of the 2019 season today. -
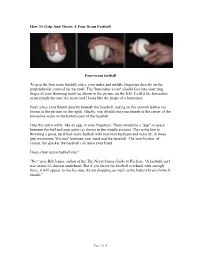
How to Grip and Throw a Four Seam Fastball
How To Grip And Throw A Four Seam Fastball Four-seam fastball To grip the four seam fastball, place your index and middle fingertips directly on the perpendicular seam of the baseball. The "horseshoe seam" should face into your ring finger of your throwing hand (as shown in the picture on the left). I call it the horseshoe seam simply because the seam itself looks like the shape of a horseshoe. Next, place your thumb directly beneath the baseball, resting on the smooth leather (as shown in the picture on the right). Ideally, you should rest your thumb in the center of the horseshoe seam on the bottom part of the baseball. Grip this pitch softly, like an egg, in your fingertips. There should be a "gap" or space between the ball and your palm (as shown in the middle picture). This is the key to throwing a good, hard four-seam fastball with maximal backspin and velocity: A loose grip minimizes "friction" between your hand and the baseball. The less friction, of course, the quicker the baseball can leave your hand. Does a four-seam fastball rise? "No," says Bill James, author of the The Neyer/James Guide to Pitchers. "A fastball can't rise unless it's thrown underhand. But if you throw the fastball overhand with enough force, it will appear to rise because it's not dropping as much as the batter's brain thinks it should." Page 1 of 10 How To Grip And Throw A Two Seam Fastball Two seam fastball A two seam fastball, much like a sinker or cutter (cut fastball), is gripped slightly tighter and deeper in the throwing-hand than the four-seam fastball. -

Pitching Grips Cheat Sheet
PITCHING GRIPS CHEAT SHEET FOUR-SEAM FASTBALL CURVEBALL Movement: None Movement:Top left to bottom right of the Purpose: To throw straight and fast. strike zone with a strong downward spin. Grip: Place your index finger and middle Purpose: To throw slower with tons of finger on the seam of the baseball. movement. Grip: Place your middle finger along the bottom seam of the baseball with your thumb on the back seam. When this pitch is thrown, your thumb should rotate upward, and your middle finger should snap downward. TWO-SEAM FASTBALL KNUCKLE CURVEBALL Movement: Away from the hitter (right Movement: Top to bottom of the strike side of the plate for a RHP, left side for a zone. LHP.) Purpose: To throw slow with slight Purpose: To throw hard with movement. movement. Grip: Place your index finger and middle Grip: Use your thumb and index fingers to finger on the seam of the baseball. create a circle or an “OK” on the ball. Then, center the baseball between your three other fingers. CHANGEUP KNUCKLEBALL Movement: Top to bottom of the strike Movement: Tons of movement scattered zone. all around the strike zone. Purpose: To throw slow with slight Purpose: To deceive the hitter. movement. Grip: Dig your fingertips into the baseball Grip: Use your thumb and index fingers to with your middle and ring fingers. Let your create a circle or an “OK” on the ball. Then, pink dangle loose. When you throw this center the baseball between your three pitch, make sure to keep your wrist stiff. other fingers.. -

FORTY MYTHS of SOFTBALL RULES (ASA Rules) 1. the Hands
FORTY MYTHS OF SOFTBALL RULES (ASA Rules) 1. The hands are considered part of the bat. If a batter is hit with a pitch on the hands, it is simply a dead ball and the batter is awarded first base. Remember that anytime a batter is hit, it is ALWAYS a dead ball. If the batter is swinging and the ball contacts her hands first, we have a DEAD BALL/ STRIKE. If the ball contacts the batter in the strike zone…same result – if it is the third strike in either of these cases – the batter is out. See ASA 7-4-G trough I, and 8-1-F 2. The batter-runner must turn to her right after over-running first base. The runner is protected back to first base regardless of which way they turn as long as they don’t make an attempt or feint towards second base (umpire judgement). Merely turning to the left, and/or being in fair territory, does NOT put the runner in jeopardy of being tagged out unless they make an attempt to advance to 2nd. See ASA 8-7-H and 8-8-I. Also ASA POE#32 3. If the batter breaks her wrists when swinging, it's a strike. The umpire’s first priority on this play is (a) was the pitch in the strike zone…if so, it is merely a strike. If not, the umpire must then judge did the batter attempt to hit the ball (did she offer at it). If in the umpire’s judgement, she offered, then the umpire should rule a strike. -

Thrive with the Power of Mobile Giving
Fundraising Kit for Charities Thrive With The Power of Mobile Giving TM Fundraising Kit for Charities | 2019- 2020 1 The most comprehensive mobile giving app in the market. Share via email, text and social media. Your logo and copy can be updated in the app. Email us! Donors select fixed amount monthly or round-ups of spare change. Any debit or credit card accepted, whether plastic or digital (Apple Pay now included too)! PS: We pull data from IRS.gov every month, so it’s likely that your 501c3 is already on our platform. Search for it now and tell us if you’d like your page modified in any way. TM 2 Fundraising Kit for Charities | 2019- 2020 2 Home RoundUps Giving Feed Tax Report Your members enroll in Monthly Each donor can see their spare An individual can make one-time Users can request a complete Giving for your charity and see change donations in the tab donations to any other charity tax report to share with their updates on their home screen. called “My ChangeUps.” too, all recorded in “My Giving.” CPA at anytime. TM 3 Fundraising Kit for Charities | 2019- 2020 3 Your Fundraising Pre-Game Confirm that your charity is on our platform: download the app for free and 1 search “Charities” with the name used when your entity was formally registered with the IRS. We pull data monthly from the IRS, so most likely your 501c3 is already in our database, but please double check. Email us at [email protected] 2 Share your updated logo and mission statement, if needed. -

Bill Bethea Baseball Story
Bill Bethea - My Baseball Story My name is Bill Bethea, and I am the founder and owner of Power Pitching & Hitting, Inc. I have dedicated the last 10 years to developing baseball players of all ages and abilities. Below is a summary of my baseball career, which I hope will provide insight to the knowledge that I have acquired throughout the years, and help communicate my love for the game of baseball. My goal is to share this knowledge with players and parents who are as passionate about the game as I am. LITTLE LEAGUE YEARS As a young player, I was a below-average little leaguer. I was only allowed to pitch one time when I was 9, and I walked 11 batters! I was not allowed to pitch again after that. At age 12, I had a coach (Mr. Jones) who was a mainstay in the Midtown Edison Little League (God rest his soul), was the first coach that believed that I had potential. I was a big kid that had power, but could never utilize the size to my advantage. As a hitter, I could make good contact, primarily hitting singles and doubles. But as a pitcher, I could not throw a strike to save my life. Needless to say, I never made an all-star or travel team. After Little League I played senior league baseball for two years before moving on to high school. At this point, I didn’t even want to try out for high school, as I didn’t think I would make the team, and I considered playing Lacrosse.