Annotation of Protein Domains Reveals Remarkable Conservation in the Functional Make up of Proteomes Across Superkingdoms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
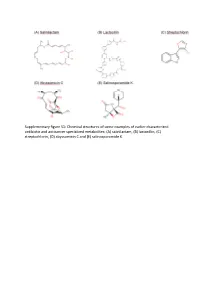
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

Genomics 98 (2011) 370–375
Genomics 98 (2011) 370–375 Contents lists available at ScienceDirect Genomics journal homepage: www.elsevier.com/locate/ygeno Whole-genome comparison clarifies close phylogenetic relationships between the phyla Dictyoglomi and Thermotogae Hiromi Nishida a,⁎, Teruhiko Beppu b, Kenji Ueda b a Agricultural Bioinformatics Research Unit, Graduate School of Agricultural and Life Sciences, University of Tokyo, 1-1-1 Yayoi, Bunkyo-ku, Tokyo 113-8657, Japan b Life Science Research Center, College of Bioresource Sciences, Nihon University, Fujisawa, Japan article info abstract Article history: The anaerobic thermophilic bacterial genus Dictyoglomus is characterized by the ability to produce useful Received 2 June 2011 enzymes such as amylase, mannanase, and xylanase. Despite the significance, the phylogenetic position of Accepted 1 August 2011 Dictyoglomus has not yet been clarified, since it exhibits ambiguous phylogenetic positions in a single gene Available online 7 August 2011 sequence comparison-based analysis. The number of substitutions at the diverging point of Dictyoglomus is insufficient to show the relationships in a single gene comparison-based analysis. Hence, we studied its Keywords: evolutionary trait based on whole-genome comparison. Both gene content and orthologous protein sequence Whole-genome comparison Dictyoglomus comparisons indicated that Dictyoglomus is most closely related to the phylum Thermotogae and it forms a Bacterial systematics monophyletic group with Coprothermobacter proteolyticus (a constituent of the phylum Firmicutes) and Coprothermobacter proteolyticus Thermotogae. Our findings indicate that C. proteolyticus does not belong to the phylum Firmicutes and that the Thermotogae phylum Dictyoglomi is not closely related to either the phylum Firmicutes or Synergistetes but to the phylum Thermotogae. © 2011 Elsevier Inc. -

Investigating Prevalence and Geographical Distribution of Mycoplasma Sp. in the Gut of Atlantic Salmon (Salmo Salar L.)
Master’s Thesis 2020 60 ECTS Faculty of Chemistry, Biotechnology and Food Science Investigating prevalence and geographical distribution of Mycoplasma sp. in the gut of Atlantic Salmon (Salmo salar L.) Mari Raudstein MSc Biotechnology ACKNOWLEDGEMENTS This master project was performed at the Faculty of Chemistry, Biotechnology and Food Science, at the Norwegian University of Life Sciences (NMBU), with Professor Knut Rudi as primary supervisor and associate professor Lars-Gustav Snipen as secondary supervisor. To begin with, I want to express my gratitude to my supervisor Knut Rudi for giving me the opportunity to include fish, one of my main interests, in my thesis. Professor Rudi has helped me execute this project to my best ability by giving me new ideas and solutions to problems that would occur, as well as answering any questions I would have. Further, my secondary supervisor associate professor Snipen has helped me in acquiring and interpreting shotgun data for this thesis. A big thank you to both of you. I would also like to thank laboratory engineer Inga Leena Angell for all the guidance in the laboratory, and for her patience when answering questions. Also, thank you to Ida Ormaasen, Morten Nilsen, and the rest of the Microbial Diversity group at NMBU for always being positive, friendly, and helpful – it has been a pleasure working at the MiDiv lab the past year! I am very grateful to the salmon farmers providing me with the material necessary to study salmon gut microbiota. Without the generosity of Lerøy Sjøtroll in Bømlo, Lerøy Aurora in Skjervøy and Mowi in Chile, I would not be able to do this work. -

The Genome of Nanoarchaeum Equitans: Insights Into Early Archaeal Evolution and Derived Parasitism
The genome of Nanoarchaeum equitans: Insights into early archaeal evolution and derived parasitism Elizabeth Waters†‡, Michael J. Hohn§, Ivan Ahel¶, David E. Graham††, Mark D. Adams‡‡, Mary Barnstead‡‡, Karen Y. Beeson‡‡, Lisa Bibbs†, Randall Bolanos‡‡, Martin Keller†, Keith Kretz†, Xiaoying Lin‡‡, Eric Mathur†, Jingwei Ni‡‡, Mircea Podar†, Toby Richardson†, Granger G. Sutton‡‡, Melvin Simon†, Dieter So¨ ll¶§§¶¶, Karl O. Stetter†§¶¶, Jay M. Short†, and Michiel Noordewier†¶¶ †Diversa Corporation, 4955 Directors Place, San Diego, CA 92121; ‡Department of Biology, San Diego State University, 5500 Campanile Drive, San Diego, CA 92182; §Lehrstuhl fu¨r Mikrobiologie und Archaeenzentrum, Universita¨t Regensburg, Universita¨tsstrasse 31, D-93053 Regensburg, Germany; ‡‡Celera Genomics Rockville, 45 West Gude Drive, Rockville, MD 20850; Departments of ¶Molecular Biophysics and Biochemistry and §§Chemistry, Yale University, New Haven, CT 06520-8114; and ʈDepartment of Biochemistry, Virginia Polytechnic Institute and State University, Blacksburg, VA 24061 Communicated by Carl R. Woese, University of Illinois at Urbana–Champaign, Urbana, IL, August 21, 2003 (received for review July 22, 2003) The hyperthermophile Nanoarchaeum equitans is an obligate sym- (6–8). Genomic DNA was either digested with restriction en- biont growing in coculture with the crenarchaeon Ignicoccus. zymes or sheared to provide clonable fragments. Two plasmid Ribosomal protein and rRNA-based phylogenies place its branching libraries were made by subcloning randomly sheared fragments point early in the archaeal lineage, representing the new archaeal of this DNA into a high-copy number vector (Ϸ2.8 kbp library) kingdom Nanoarchaeota. The N. equitans genome (490,885 base or low-copy number vector (Ϸ6.3 kbp library). DNA sequence pairs) encodes the machinery for information processing and was obtained from both ends of plasmid inserts to create repair, but lacks genes for lipid, cofactor, amino acid, or nucleotide ‘‘mate-pairs,’’ pairs of reads from single clones that should be biosyntheses. -

Annual Conference Abstracts
ANNUAL CONFERENCE 14-17 April 2014 Arena and Convention Centre, Liverpool ABSTRACTS SGM ANNUAL CONFERENCE APRIL 2014 ABSTRACTS (LI00Mo1210) – SGM Prize Medal Lecture (LI00Tu1210) – Marjory Stephenson Climate Change, Oceans, and Infectious Disease Prize Lecture Dr. Rita R. Colwell Understanding the basis of antibiotic resistance University of Maryland, College Park, MD, USA as a platform for early drug discovery During the mid-1980s, satellite sensors were developed to monitor Laura JV Piddock land and oceans for purposes of understanding climate, weather, School of Immunity & Infection and Institute of Microbiology and and vegetation distribution and seasonal variations. Subsequently Infection, University of Birmingham, UK inter-relationships of the environment and infectious diseases Antibiotic resistant bacteria are one of the greatest threats to human were investigated, both qualitatively and quantitatively, with health. Resistance can be mediated by numerous mechanisms documentation of the seasonality of diseases, notably malaria including mutations conferring changes to the genes encoding the and cholera by epidemiologists. The new research revealed a very target proteins as well as RND efflux pumps, which confer innate close interaction of the environment and many other infectious multi-drug resistance (MDR) to bacteria. The production of efflux diseases. With satellite sensors, these relationships were pumps can be increased, usually due to mutations in regulatory quantified and comparatively analyzed. More recent studies of genes, and this confers resistance to antibiotics that are often used epidemic diseases have provided models, both retrospective and to treat infections by Gram negative bacteria. RND MDR efflux prospective, for understanding and predicting disease epidemics, systems not only confer antibiotic resistance, but altered expression notably vector borne diseases. -
Microbial Evolution and Diversity
PART V Microbial Evolution and Diversity This material cannot be copied, disseminated, or used in any way without the express written permission of the publisher. Copyright 2007 Sinauer Associates Inc. The objectives of this chapter are to: N Provide information on how bacteria are named and what is meant by a validly named species. N Discuss the classification of Bacteria and Archaea and the recent move toward an evolutionarily based, phylogenetic classification. N Describe the ways in which the Bacteria and Archaea are identified in the laboratory. This material cannot be copied, disseminated, or used in any way without the express written permission of the publisher. Copyright 2007 Sinauer Associates Inc. 17 Taxonomy of Bacteria and Archaea It’s just astounding to see how constant, how conserved, certain sequence motifs—proteins, genes—have been over enormous expanses of time. You can see sequence patterns that have per- sisted probably for over three billion years. That’s far longer than mountain ranges last, than continents retain their shape. —Carl Woese, 1997 (in Perry and Staley, Microbiology) his part of the book discusses the variety of microorganisms that exist on Earth and what is known about their characteris- Ttics and evolution. Most of the material pertains to the Bacteria and Archaea because there is a special chapter dedicated to eukaryotic microorganisms. Therefore, this first chapter discusses how the Bacte- ria and Archaea are named and classified and is followed by several chapters (Chapters 18–22) that discuss the properties and diversity of the Bacteria and Archaea. When scientists encounter a large number of related items—such as the chemical elements, plants, or animals—they characterize, name, and organize them into groups. -

Lifestyle and Genetic Evolution of Coprothermobacter
bioRxiv preprint doi: https://doi.org/10.1101/280602; this version posted July 11, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. 1 From proteins to polysaccharides: lifestyle and genetic evolution of 2 Coprothermobacter proteolyticus. 3 4 5 B.J. Kunath1#, F. Delogu1#, A.E. Naas1, M.Ø. Arntzen1, V.G.H. Eijsink1, B. Henrissat2, T.R. 6 Hvidsten1, P.B. Pope1* 7 8 1. Faculty of Chemistry, Biotechnology and Food Science, Norwegian University of Life 9 Sciences, 1432 Ås, NORWAY. 10 2. Architecture et Fonction des Macromolécules Biologiques, CNRS, Aix-Marseille 11 Université, F-13288 Marseille, France. 12 # Equal contributors 13 14 *Corresponding Author: Phillip B. Pope 15 Faculty of Chemistry, Biotechnology and Food Science 16 Norwegian University of Life Sciences 17 Post Office Box 5003 18 1432, Ås, Norway 19 Phone: +47 6496 6232 20 Email: [email protected] 21 22 23 RUNNING TITLE: 24 The genetic plasticity of Coprothermobacter 25 26 COMPETING INTERESTS 27 The authors declare there are no competing financial interests in relation to the work described. 28 29 KEYWORDS 30 CAZymes; Horizontal gene transfer; strain heterogeneity; Metatranscriptomics 1 bioRxiv preprint doi: https://doi.org/10.1101/280602; this version posted July 11, 2018. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. -
The RDP-II Backbone Tree for Release 8.0. the Tree Was Inferred from a Distance Matrix Generated in PAUP* with the Weighbor (Weighted Neighbor Joining) Algorithm
Methylococcus capsulatus ACM 1292 (T) Oceanospirillum linum ATCC 11336 (T) Halomonas halodenitrificans ATCC 13511 (T) Legionella lytica PCM 2298 (T) Francisella tularensis subsp. tularensis ATCC 6223 (T) Coxiella burnetii Q177 Moraxella catarrhalis ATCC 25238 (T) Pseudomonas fluorescens IAM 12022 (T) Piscirickettsia salmonis LF-89 (T) Thiothrix nivea DSM 5205 (T) Allochromatium minutissimum DSM 1376 (T) Alteromonas macleodii IAM 12920 (T) Aeromonas salmonicida subsp. smithia CCM 4103 (T) Pasteurella multocida NCTC 10322 (T) Enterobacter nimipressuralis LMG 10245 (T) Vibrio vulnificus ATCC 27562 (T) Ectothiorhodospira mobilis DSM237 (T) Xanthomonas campestris LMG 568 (T) Cardiobacterium hominis ATCC 15826 (T) Methylophilus methylotrophus ATCC 53528 (T) Rhodocyclus tenuis DSM 109 (T) Hydrogenophilus thermoluteolus TH-1 (T) Neisseria gonorrhoeae NCTC 8375 (T) Comamonas testosteroni ATCC 11996 (T) Nitrosospira multiformis ATCC 25196 (T) Spirillum volutans ATCC 19554 (T) Burkholderia glathei LMG 14190 (T) Alcaligenes defragrans DSM 12141 (T) Oxalobacter formigenes ATCC 35274 (T) Acetobacter oboediens DSM 11826 (T) clone CS93 PROTEOBACTERIA Caedibacter caryophilus 221 (T) Rhodobacter sphaeroides ATCC 17023 (T) Rickettsia rickettsii ATCC VR-891 (T) Ehrlichia risticii ATCC VR-986 (T) Sphingomonas paucimobilis GIFU 2395 (T) Caulobacter fusiformis ATCC 15257 (T) Rhodospirillum rubrum ATCC 11170 (T) Brucella melitensis ATCC 23459 (T) Rhizobium tropici IFO 15247 (T) Bartonella vinsonii subsp. vinsonii ATCC VR-152 (T) Phyllobacterium myrsinacearum -

Bovine Mycoplasmosis
Bovine mycoplasmosis The microorganisms described within the genus Mycoplasma spp., family Mycoplasmataceae, class Mollicutes, are characterized by the lack of a cell wall and by the little size (0.2-0.5 µm). They are defined as fastidious microorganisms in in vitro cultivation, as they require specific and selective media for the growth, which appears slower if compared to other common bacteria. Mycoplasmas can be detected in several hosts (mammals, avian, reptiles, plants) where they can act as opportunistic agents or as pathogens sensu stricto. Several Mycoplasma species have been described in the bovine sector, which have been detected from different tissues and have been associated to variable kind of gross-pathology lesions. Moreover, likewise in other zoo-technical areas, Mycoplasma spp. infection is related to high morbidity, low mortality and to the chronicization of the disease. Bovine Mycoplasmosis can affect meat and dairy animals of different ages, leading to great economic losses due to the need of prophylactic/metaphylactic measures, therapy and to decreased production. The new holistic approach to multifactorial or chronic diseases of human and veterinary interest has led to a greater attention also to Mycoplasma spp., which despite their elementary characteristics are considered fast-evolving microorganisms. These kind of bacteria, historically considered of secondary importance apart for some species, are assuming nowadays a greater importance in the various zoo-technical fields with increased diagnostic request in veterinary medicine. Also Acholeplasma spp. and Ureaplasma spp. are described as commensal or pathogen in the bovine sector. Because of the phylogenetic similarity and the common metabolic activities, they can grow in the same selective media or can be detected through biomolecular techniques targeting Mycoplasma spp. -

The Mínimum Cell
The minimum cell GENOMIC – ADVANCED GENETICS AUTHOR: I. ODEI BARREÑADA Overview The Concept Small genomes Minimal gene set Approache theories Minimal genome proyect Future insight The concept “MINIMUN CELL“ The smallest size (of genetic The smallest unit of life that can information) replicate autonomously = minimum genome Small genomes Circovirus (1.800 base pairs / 3 gens) Virus Carsonella ruddi (159 kb /182 genes) Symbiont Nanoarchaeum equitans (490 kb/ 553 genes) Parasite Mycoplasma genitalium (582 kb/ 521 genes ) Parasite Pelagibacter ubique (1,3 Mb/ 1,370 genes) Free-living Smallest genomes Circovirus (1.800 base pairs / 3 gens) Virus Carsonella ruddi (159 kb /182 genes) Symbiont Nanoarchaeum equitans (490 kb/ 553 genes) Parasite Mycoplasma genitalium (582 kb/ 521 genes ) Parasite Pelagibacter ubique (1,3 Mb/ 1,370 genes) Free-living (Giovannoni et al., 2005) “MINIMAL GENE SET” By genome comparison Ubiquitous genes: Translation Transcription Replication of DNA Variable genes: Depends of environment (Koonin, 2003) Theories for reach the minimum cell Two approaches Top – Down knock-down known organism Bottom-up --> build from synthetics DNA Minimal genome project J. Craig Venter Institute Search of essential genes Gene disruption by transposons Seq the survivors organisms Detect the disrupted gene Declare this genes as NON-ESENTIAL In M. genitalium only 382 of 521 genes are essential (Gibson et al., 2011) Build de novo M. genitalium genome Future insight - Cell design Create artificial cells for: Generation of hydrogen for fuel Capturing excess carbon dioxide in the atmosphere Drug delivery directly into the body As Enzyme therapy Artificial blood cells … And all you can think References Koonin E V. -

The Mysterious Orphans of Mycoplasmataceae
The mysterious orphans of Mycoplasmataceae Tatiana V. Tatarinova1,2*, Inna Lysnyansky3, Yuri V. Nikolsky4,5,6, and Alexander Bolshoy7* 1 Children’s Hospital Los Angeles, Keck School of Medicine, University of Southern California, Los Angeles, 90027, California, USA 2 Spatial Science Institute, University of Southern California, Los Angeles, 90089, California, USA 3 Mycoplasma Unit, Division of Avian and Aquatic Diseases, Kimron Veterinary Institute, POB 12, Beit Dagan, 50250, Israel 4 School of Systems Biology, George Mason University, 10900 University Blvd, MSN 5B3, Manassas, VA 20110, USA 5 Biomedical Cluster, Skolkovo Foundation, 4 Lugovaya str., Skolkovo Innovation Centre, Mozhajskij region, Moscow, 143026, Russian Federation 6 Vavilov Institute of General Genetics, Moscow, Russian Federation 7 Department of Evolutionary and Environmental Biology and Institute of Evolution, University of Haifa, Israel 1,2 [email protected] 3 [email protected] 4-6 [email protected] 7 [email protected] 1 Abstract Background: The length of a protein sequence is largely determined by its function, i.e. each functional group is associated with an optimal size. However, comparative genomics revealed that proteins’ length may be affected by additional factors. In 2002 it was shown that in bacterium Escherichia coli and the archaeon Archaeoglobus fulgidus, protein sequences with no homologs are, on average, shorter than those with homologs [1]. Most experts now agree that the length distributions are distinctly different between protein sequences with and without homologs in bacterial and archaeal genomes. In this study, we examine this postulate by a comprehensive analysis of all annotated prokaryotic genomes and focusing on certain exceptions. -

MIB–MIP Is a Mycoplasma System That Captures and Cleaves Immunoglobulin G
MIB–MIP is a mycoplasma system that captures and cleaves immunoglobulin G Yonathan Arfia,b,1, Laetitia Minderc,d, Carmelo Di Primoe,f,g, Aline Le Royh,i,j, Christine Ebelh,i,j, Laurent Coquetk, Stephane Claveroll, Sanjay Vasheem, Joerg Joresn,o, Alain Blancharda,b, and Pascal Sirand-Pugneta,b aINRA (Institut National de la Recherche Agronomique), UMR 1332 Biologie du Fruit et Pathologie, F-33882 Villenave d’Ornon, France; bUniversity of Bordeaux, UMR 1332 Biologie du Fruit et Pathologie, F-33882 Villenave d’Ornon, France; cInstitut Européen de Chimie et Biologie, UMS 3033, University of Bordeaux, 33607 Pessac, France; dInstitut Bergonié, SIRIC BRIO, 33076 Bordeaux, France; eINSERM U1212, ARN Regulation Naturelle et Artificielle, 33607 Pessac, France; fCNRS UMR 5320, ARN Regulation Naturelle et Artificielle, 33607 Pessac, France; gInstitut Européen de Chimie et Biologie, University of Bordeaux, 33607 Pessac, France; hInstitut de Biologie Structurale, University of Grenoble Alpes, F-38044 Grenoble, France; iCNRS, Institut de Biologie Structurale, F-38044 Grenoble, France; jCEA, Institut de Biologie Structurale, F-38044 Grenoble, France; kCNRS UMR 6270, Plateforme PISSARO, Institute for Research and Innovation in Biomedicine - Normandie Rouen, Normandie Université, F-76821 Mont-Saint-Aignan, France; lProteome Platform, Functional Genomic Center of Bordeaux, University of Bordeaux, F-33076 Bordeaux Cedex, France; mJ. Craig Venter Institute, Rockville, MD 20850; nInternational Livestock Research Institute, 00100 Nairobi, Kenya; and oInstitute of Veterinary Bacteriology, University of Bern, CH-3001 Bern, Switzerland Edited by Roy Curtiss III, University of Florida, Gainesville, FL, and approved March 30, 2016 (received for review January 12, 2016) Mycoplasmas are “minimal” bacteria able to infect humans, wildlife, introduced into naive herds (8).