20280-Taiwan-Kana.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Study of Old Documents of Hokkaido and Kuril Ainu
NINJAL International Symposium 2018 Approaches to Endangered Languages in Japan and Northeast Asia, August 6-8 The study of old documents of Hokkaido and Kuril Ainu: Promise and Challenges Tomomi Sato (Hokkaido U) & Anna Bugaeva (TUS/NINJAL) [email protected] [email protected]) Introduction: Ainu • AINU (isolate, North Japan, moribund) • Is the only non-Japonic lang. of Japan. • Major dialect groups : Hokkaido (moribund), Sakhalin (extinct since 1993), Kuril (extinct since the end of XIX). • Was also spoken in Tōhoku till mid XVIII. • Hokkaido Ainu dialects: Southwestern (well documented) Northeastern (less documented) • Is not used in daily conversation since the 1950s. • Ethnical Ainu: 100,000. 2 Fig. 2 Major language families in Northeast Asia (excluding Sinitic) Amuric Mongolic Tungusic Ainuic Koreanic Japonic • Ainu shares only few features with Northeast Asian languages. • Ainu is typologically “more like a morphologically reduced version of a North American language.” (Johanna Nichols p.c.). • This is due to the strongly head-marking character of Ainu (Bugaeva, to appear). Why is it important to study Ainu? • Ainu culture is widely regarded as a direct descendant of the Jōmon culture which was spread in the Japanese archipelago in the Prehistoric time from about 14,000 BC. • Ainu is the only surviving Jōmon language; there had been other Jōmon lgs too: about 300 lgs (Janhunen 2002), cf. 10 lgs (Whitman, p.c.) . • Ainu is likely to be much more typical of what languages were like in Northeast Asia several millennia ago than the picture we would get from Chinese, Japanese or Korean. • Focusing on Ainu can help us understand a period of northeast Asian history when political, cultural and linguistic units were very different to what they have been since the rise of the great historically-attested states of East Asia. -

Traditions and Foreign Influences: Systems of Law in China and Japan
TRADITIONS AND FOREIGN INFLUENCES: SYSTEMS OF LAW IN CHINA AND JAPAN PERCY R. LUNEY, JR.* I INTRODUCTION By training, what I know about Chinese law comes from my study of the Japanese legal system. Japan imported several early Chinese legal codes in the seventh and eighth centuries and adapted this law to existing Japanese social and economic conditions. The Chinese Confucian philosophy and system of ethics was introduced to Japan in the fourteenth century. The Japanese and Chinese legal systems adopted Western-style legal codes to foster economic growth and international trade; and, more importantly, both have an underlying foundation of Confucian philosophy. As an outsider to the study of China, my views represent those of a comparativist commenting on his perceptions of foreign influences on the Chinese legal system. These perceptions are based on my readings about Chinese law, my professional study of Japanese law, and the presentation given by Professor Whitmore Gray ("The Soviet Background") at the 1987 Duke Conference on Chinese Civil Law. Legal reforms in China are generating much debate by Western legal scholars about the future of the Chinese legal system. After the fall of the Gang of Four, the new Chinese Government has sought to strengthen and to improve the stature of the legal system. The goal is a socialist legal system with Chinese characteristics.' The post-Mao leadership views the legal system as an essential element in the economic development process. 2 Chinese expectations are that a legal system can provide the societal stability necessary for economic Copyright © 1989 by Law and Contemporary Problems * Associate Professor, North Carolina Central University School of Law; Visiting Professor, Duke University School of Law. -

Fungsi Ateji Dalam Lirik Lagu Pada Album Marginal #4 the Best 「Star Cluster 2」 Produksi Rejet
PARAMASASTRA Vol. 6 No. 1 - Maret 2019 p-ISSN 2355-4126 e-ISSN 2527-8754 http://journal.unesa.ac.id/index.php/paramasastra FUNGSI ATEJI DALAM LIRIK LAGU PADA ALBUM MARGINAL #4 THE BEST 「STAR CLUSTER 2」 PRODUKSI REJET Meisha Putri M.R., Agus Budi Cahyono Universitas Brawijaya, [email protected] Universitas Brawijaya, [email protected] ABSTRACT This article aimed to describe why furigana in Japanese songs often found different furigana actually with kanji below it. Data uses the album MARGINAL # 4 THE BEST 「STAR CLUSTER 2」 REJET Production. This study uses qualitative descriptive to examine the type of ateji based on Lewis's theory (2010) and its function based on the theory of Jakobson (1960). Based on analysis, writer find more contrastive ateji than denotive ateji. Fatigue function is found more than other functions. The metalingual function is found on all data. Keywords: Ateji, Furigana, semantic PENDAHULUAN Huruf bahasa Jepang dibagi menjadi 4 yang digunakan sehari-hari. Adapun huruf tersebut adalah Kanji, Hiragana, Katakana dan Romaji. Pada penulisan huruf Kanji kadang diikuti dengan furigana yang merupakan bantuan cara baca serta memaknai kanji itu sendiri karena huruf kanji kadang mempunyai cara baca yang berbeda. Selain pembubuhan dengan furigana ada juga dengan ateji. Furigana itu murni sebagai cara baca dan makna aslinya, maka ateji adalah bantuan cara baca yang dilekatkan untuk menambahkan lapisan ide maupun makna di dalam kanji itu sendiri. Ateji merupakan penulisan bahasa Jepang yang tidak mengikuti cara baca jion (cara baca kanji China) dan jikun (cara baca kanji Jepang) ataupun jigi (makna asli) bahasa Jepang tersebut (Shirose, 2012: 103). -

Uhm Phd 9506222 R.Pdf
INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UM! films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while others may be from any type of computer printer. The quality of this reproduction is dependent UJWD the quality of the copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adverselyaffect reproduction. In the unlikely event that the author did not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g., maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-band comer and continuing from left to right in equal sections with small overlaps. Each original is also photographed in one exposure and is included in reduced form at the back of the book. Photographs included in the original manuscript have been reproduced xerographically in this copy. Higher quality 6" x 9" black and white photographic prints are available for any photographs or illustrations appearing in this copy for an additional charge. Contact UMI directly to order. U·M·I University Microfilms tnternauonat A Bell & Howell tntorrnatron Company 300 North Zeeb Road. Ann Arbor. M148106-1346 USA 313/761-4700 800:521·0600 Order Number 9506222 The linguistic and psycholinguistic nature of kanji: Do kanji represent and trigger only meanings? Matsunaga, Sachiko, Ph.D. University of Hawaii, 1994 Copyright @1994 by Matsunaga, Sachiko. -

Man'yogana.Pdf (574.0Kb)
Bulletin of the School of Oriental and African Studies http://journals.cambridge.org/BSO Additional services for Bulletin of the School of Oriental and African Studies: Email alerts: Click here Subscriptions: Click here Commercial reprints: Click here Terms of use : Click here The origin of man'yogana John R. BENTLEY Bulletin of the School of Oriental and African Studies / Volume 64 / Issue 01 / February 2001, pp 59 73 DOI: 10.1017/S0041977X01000040, Published online: 18 April 2001 Link to this article: http://journals.cambridge.org/abstract_S0041977X01000040 How to cite this article: John R. BENTLEY (2001). The origin of man'yogana. Bulletin of the School of Oriental and African Studies, 64, pp 5973 doi:10.1017/S0041977X01000040 Request Permissions : Click here Downloaded from http://journals.cambridge.org/BSO, IP address: 131.156.159.213 on 05 Mar 2013 The origin of man'yo:gana1 . Northern Illinois University 1. Introduction2 The origin of man'yo:gana, the phonetic writing system used by the Japanese who originally had no script, is shrouded in mystery and myth. There is even a tradition that prior to the importation of Chinese script, the Japanese had a native script of their own, known as jindai moji ( , age of the gods script). Christopher Seeley (1991: 3) suggests that by the late thirteenth century, Shoku nihongi, a compilation of various earlier commentaries on Nihon shoki (Japan's first official historical record, 720 ..), circulated the idea that Yamato3 had written script from the age of the gods, a mythical period when the deity Susanoo was believed by the Japanese court to have composed Japan's first poem, and the Sun goddess declared her son would rule the land below. -

Como Digitar Em Japonês 1
Como digitar em japonês 1 Passo 1: Mudar para o modo de digitação em japonês Abra o Office Word, Word Pad ou Bloco de notas para testar a digitação em japonês. Com o cursor colocado em um novo documento em algum lugar em sua tela você vai notar uma barra de idiomas. Clique no botão "PT Português" e selecione "JP Japonês (Japão)". Isso vai mudar a aparência da barra de idiomas. * Se uma barra longa aparecer, como na figura abaixo, clique com o botão direito na parte mais à esquerda e desmarque a opção "Legendas". ficará assim → Além disso, você pode clicar no "_" no canto superior direito da barra de idiomas, que a janela se fechará no canto inferior direito da tela (minimizar). ficará assim → © 2017 Fundação Japão em São Paulo Passo 2: Alterar a barra de idiomas para exibir em japonês Se você não consegue ler em japonês, pode mudar a exibição da barra de idioma para inglês. Clique em ツール e depois na opção プロパティ. Opção: Alterar a barra de idiomas para exibir em inglês Esta janela é toda em japonês, mas não se preocupe, pois da próxima vez que abrí-la estará em Inglês. Haverá um menu de seleção de idiomas no menu de "全般", escolha "英語 " e clique em "OK". © 2017 Fundação Japão em São Paulo Passo 3: Digitando em japonês Certifique-se de que tenha selecionado japonês na barra de idiomas. Após isso, selecione “hiragana”, como indica a seta. Passo 4: Digitando em japonês com letras romanas Uma vez que estiver no modo de entrada correto no documento, vamos digitar uma palavra prática. -

Handy Katakana Workbook.Pdf
First Edition HANDY KATAKANA WORKBOOK An Introduction to Japanese Writing: KANA THIS IS A SUPPLEMENT FOR BEGINNING LEVEL JAPANESE LANGUAGE INSTRUCTION. \ FrF!' '---~---- , - Y. M. Shimazu, Ed.D. -----~---- TABLE OF CONTENTS Page Introduction vi ACKNOWLEDGEMENlS vii STUDYSHEET#l 1 A,I,U,E, 0, KA,I<I, KU,KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #1 2 PRACTICE: A, I,U, E, 0, KA,KI, KU,KE, KO, GA,GI,GU, GE,GO, N WORKSHEET #2 3 MORE PRACTICE: A, I, U, E,0, KA,KI,KU, KE, KO, GA,GI,GU,GE,GO, N WORKSHEET #~3 4 ADDmONAL PRACTICE: A,I,U, E,0, KA,KI, KU,KE, KO, GA,GI,GU,GE,GO, N STUDYSHEET #2 5 SA,SHI,SU,SE, SO, ZA,JI,ZU,ZE,ZO, TA, CHI, TSU, TE,TO, DA, DE,DO WORI<SHEEI' #4 6 PRACTICE: SA,SHI,SU,SE, SO, ZA,II, ZU,ZE,ZO, TA, CHI, 'lSU,TE,TO, OA, DE,DO WORI<SHEEI' #5 7 MORE PRACTICE: SA,SHI,SU,SE,SO, ZA,II, ZU,ZE, W, TA, CHI, TSU, TE,TO, DA, DE,DO WORKSHEET #6 8 ADDmONAL PRACI'ICE: SA,SHI,SU,SE, SO, ZA,JI, ZU,ZE,ZO, TA, CHI,TSU,TE,TO, DA, DE,DO STUDYSHEET #3 9 NA,NI, NU,NE,NO, HA, HI,FU,HE, HO, BA, BI,BU,BE,BO, PA, PI,PU,PE,PO WORKSHEET #7 10 PRACTICE: NA,NI, NU, NE,NO, HA, HI,FU,HE,HO, BA,BI, BU,BE, BO, PA, PI,PU,PE,PO WORKSHEET #8 11 MORE PRACTICE: NA,NI, NU,NE,NO, HA,HI, FU,HE, HO, BA,BI,BU,BE, BO, PA,PI,PU,PE,PO WORKSHEET #9 12 ADDmONAL PRACTICE: NA,NI, NU, NE,NO, HA, HI, FU,HE, HO, BA,BI,3U, BE, BO, PA, PI,PU,PE,PO STUDYSHEET #4 13 MA, MI,MU, ME, MO, YA, W, YO WORKSHEET#10 14 PRACTICE: MA,MI, MU,ME, MO, YA, W, YO WORKSHEET #11 15 MORE PRACTICE: MA, MI,MU,ME,MO, YA, W, YO WORKSHEET #12 16 ADDmONAL PRACTICE: MA,MI,MU, ME, MO, YA, W, YO STUDYSHEET #5 17 -
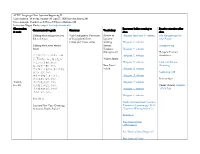
ALTEC Language Class: Japanese Beginning II
ALTEC Language Class: Japanese Beginning II Class duration: 10 weeks, January 28–April 7, 2020 (no class March 24) Class meetings: Tuesdays at 5:30pm–7:30pm in Hellems 145 Instructor: Megan Husby, [email protected] Class session Resources before coming to Practice exercises after Communicative goals Grammar Vocabulary & topic class class Talking about things that you Verb Conjugation: Past tense Review of Hiragana Intro and あ column Fun Hiragana app for did in the past of long (polite) forms Japanese your Phone (~desu and ~masu verbs) Writing Hiragana か column Talking about your winter System: Hiragana song break Hiragana Hiragana さ column (Recognition) Hiragana Practice クリスマス・ハヌカー・お Hiragana た column Worksheet しょうがつ 正月はなにをしましたか。 Winter Sports どこにいきましたか。 Hiragana な column Grammar Review なにをたべましたか。 New Year’s (Listening) プレゼントをかいましたか/ Vocab Hiragana は column もらいましたか。 Genki I pg. 110 スポーツをしましたか。 Hiragana ま column だれにあいましたか。 Practice Quiz Week 1, えいがをみましたか。 Hiragana や column Jan. 28 ほんをよみましたか。 Omake (bonus): Kasajizō: うたをききましたか/ Hiragana ら column A Folk Tale うたいましたか。 Hiragana わ column Particle と Genki: An Integrated Course in Japanese New Year (Greetings, Elementary Japanese pgs. 24-31 Activities, Foods, Zodiac) (“Japanese Writing System”) Particle と Past Tense of desu (Affirmative) Past Tense of desu (Negative) Past Tense of Verbs Discussing family, pets, objects, Verbs for being (aru and iru) Review of Katakana Intro and ア column Katakana Practice possessions, etc. Japanese Worksheet Counters for people, animals, Writing Katakana カ column etc. System: Genki I pgs. 107-108 Katakana Katakana サ column (Recognition) Practice Quiz Katakana タ column Counters Katakana ナ column Furniture and common Katakana ハ column household items Katakana マ column Katakana ヤ column Katakana ラ column Week 2, Feb. -

A Comparative Analysis of the Simplification of Chinese Characters in Japan and China
CONTRASTING APPROACHES TO CHINESE CHARACTER REFORM: A COMPARATIVE ANALYSIS OF THE SIMPLIFICATION OF CHINESE CHARACTERS IN JAPAN AND CHINA A THESIS SUBMITTED TO THE GRADUATE DIVISION OF THE UNIVERSITY OF HAWAI‘I AT MĀNOA IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF ARTS IN ASIAN STUDIES AUGUST 2012 By Kei Imafuku Thesis Committee: Alexander Vovin, Chairperson Robert Huey Dina Rudolph Yoshimi ACKNOWLEDGEMENTS I would like to express deep gratitude to Alexander Vovin, Robert Huey, and Dina R. Yoshimi for their Japanese and Chinese expertise and kind encouragement throughout the writing of this thesis. Their guidance, as well as the support of the Center for Japanese Studies, School of Pacific and Asian Studies, and the East-West Center, has been invaluable. i ABSTRACT Due to the complexity and number of Chinese characters used in Chinese and Japanese, some characters were the target of simplification reforms. However, Japanese and Chinese simplifications frequently differed, resulting in the existence of multiple forms of the same character being used in different places. This study investigates the differences between the Japanese and Chinese simplifications and the effects of the simplification techniques implemented by each side. The more conservative Japanese simplifications were achieved by instating simpler historical character variants while the more radical Chinese simplifications were achieved primarily through the use of whole cursive script forms and phonetic simplification techniques. These techniques, however, have been criticized for their detrimental effects on character recognition, semantic and phonetic clarity, and consistency – issues less present with the Japanese approach. By comparing the Japanese and Chinese simplification techniques, this study seeks to determine the characteristics of more effective, less controversial Chinese character simplifications. -

Na Kana Magiti Kei Na Lotu
1 NA KANA MAGITI KEI NA LOTU (Vola Tabu : Maciu 22:1-10; Luke 14:12-24) Vola ko Rev. Dr. Ilaitia S. Tuwere. Sa inaki ni vunau oqo me taroga ka sauma talega na taro : A cava na Lotu? Ni da tekivu edaidai ena noda solevu vakalotu, sa na yaga meda taroga ka tovolea talega me sauma na taro oqori. Ia, ena levu na kena isau eda na solia, me vaka na: gumatuataki ni masu kei na vulici ni Vola Tabu, bula vakayalo, muria na ivakarau se lawa ni lotu ka vuqa tale. Na veika oqori era ka dina ka tu kina eso na isau ni taro : A Cava na Lotu. Na i Vola Tabu e sega ni tuvalaka vakavosa vei keda na ibalebale ni lotu. E vakavuqa me boroya vei keda na iyaloyalo me vakadewataka kina na veika eso e vinakata me tukuna. E sega talega ni solia e duabulu ga na iyaloyalo me baleta na lotu. E vuqa sara e solia vei keda. Oqori me vaka na Qele ni Sipi kei na i Vakatawa Vinaka; na Vuni Vaini kei na Tabana; na i Vakavuvuli kei iratou na nona Gonevuli se Tisaipeli, na Masima se Rarama kei Vuravura, na Ulu kei na Vo ni Yago taucoko, ka vuqa tale. Ena mataka edaidai, meda raica vata yani na iyaloyalo ni kana magiti. E rua na kena ivakamacala eda rogoca, mai na Kosipeli i Maciu kei na nei Luke. Na kana magiti se na solevu edua na ivakarau vakaitaukei. Eda soqoni vata kina vakaveiwekani ena noda veikidavaki kei na marau, kena veitalanoa, kena sere kei na meke, kena salusalu kei na kumuni iyau. -

KANA Response Live Organization Administration Tool Guide
This is the most recent version of this document provided by KANA Software, Inc. to Genesys, for the version of the KANA software products licensed for use with the Genesys eServices (Multimedia) products. Click here to access this document. KANA Response Live Organization Administration KANA Response Live Version 10 R2 February 2008 KANA Response Live Organization Administration All contents of this documentation are the property of KANA Software, Inc. (“KANA”) (and if relevant its third party licensors) and protected by United States and international copyright laws. All Rights Reserved. © 2008 KANA Software, Inc. Terms of Use: This software and documentation are provided solely pursuant to the terms of a license agreement between the user and KANA (the “Agreement”) and any use in violation of, or not pursuant to any such Agreement shall be deemed copyright infringement and a violation of KANA's rights in the software and documentation and the user consents to KANA's obtaining of injunctive relief precluding any further such use. KANA assumes no responsibility for any damage that may occur either directly or indirectly, or any consequential damages that may result from the use of this documentation or any KANA software product except as expressly provided in the Agreement, any use hereunder is on an as-is basis, without warranty of any kind, including without limitation the warranties of merchantability, fitness for a particular purpose, and non-infringement. Use, duplication, or disclosure by licensee of any materials provided by KANA is subject to restrictions as set forth in the Agreement. Information contained in this document is subject to change without notice and does not represent a commitment on the part of KANA. -

Writing As Aesthetic in Modern and Contemporary Japanese-Language Literature
At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Washington 2021 Reading Committee: Edward Mack, Chair Davinder Bhowmik Zev Handel Jeffrey Todd Knight Program Authorized to Offer Degree: Asian Languages and Literature ©Copyright 2021 Christopher J Lowy University of Washington Abstract At the Intersection of Script and Literature: Writing as Aesthetic in Modern and Contemporary Japanese-language Literature Christopher J Lowy Chair of the Supervisory Committee: Edward Mack Department of Asian Languages and Literature This dissertation examines the dynamic relationship between written language and literary fiction in modern and contemporary Japanese-language literature. I analyze how script and narration come together to function as a site of expression, and how they connect to questions of visuality, textuality, and materiality. Informed by work from the field of textual humanities, my project brings together new philological approaches to visual aspects of text in literature written in the Japanese script. Because research in English on the visual textuality of Japanese-language literature is scant, my work serves as a fundamental first-step in creating a new area of critical interest by establishing key terms and a general theoretical framework from which to approach the topic. Chapter One establishes the scope of my project and the vocabulary necessary for an analysis of script relative to narrative content; Chapter Two looks at one author’s relationship with written language; and Chapters Three and Four apply the concepts explored in Chapter One to a variety of modern and contemporary literary texts where script plays a central role.