Bayesian Regression Using Priors on the Model Fit
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

On Assessing Binary Regression Models Based on Ungrouped Data
Biometrics 000, 1{18 DOI: 000 000 0000 On Assessing Binary Regression Models Based on Ungrouped Data Chunling Lu Division of Global Health, Brigham and Women's Hospital & Department of Global Health and Social Medicine Harvard University, Boston, U.S. email: chunling [email protected] and Yuhong Yang School of Statistics, University of Minnesota, Minnesota, U.S. email: [email protected] Summary: Assessing a binary regression model based on ungrouped data is a commonly encountered but very challenging problem. Although tests, such as Hosmer-Lemeshow test and le Cessie-van Houwelingen test, have been devised and widely used in applications, they often have low power in detecting lack of fit and not much theoretical justification has been made on when they can work well. In this paper, we propose a new approach based on a cross validation voting system to address the problem. In addition to a theoretical guarantee that the probabilities of type I and II errors both converge to zero as the sample size increases for the new method under proper conditions, our simulation results demonstrate that it performs very well. Key words: Goodness of fit; Hosmer-Lemeshow test; Model assessment; Model selection diagnostics. This paper has been submitted for consideration for publication in Biometrics Goodness of Fit for Ungrouped Data 1 1. Introduction 1.1 Motivation Parametric binary regression is one of the most widely used statistical tools in real appli- cations. A central component in parametric regression is assessment of a candidate model before accepting it as a satisfactory description of the data. In that regard, goodness of fit tests are needed to reveal significant lack-of-fit of the model to assess (MTA), if any. -

Recent Advances in Directional Statistics
Recent advances in directional statistics Arthur Pewsey1;3 and Eduardo García-Portugués2 Abstract Mainstream statistical methodology is generally applicable to data observed in Euclidean space. There are, however, numerous contexts of considerable scientific interest in which the natural supports for the data under consideration are Riemannian manifolds like the unit circle, torus, sphere and their extensions. Typically, such data can be represented using one or more directions, and directional statistics is the branch of statistics that deals with their analysis. In this paper we provide a review of the many recent developments in the field since the publication of Mardia and Jupp (1999), still the most comprehensive text on directional statistics. Many of those developments have been stimulated by interesting applications in fields as diverse as astronomy, medicine, genetics, neurology, aeronautics, acoustics, image analysis, text mining, environmetrics, and machine learning. We begin by considering developments for the exploratory analysis of directional data before progressing to distributional models, general approaches to inference, hypothesis testing, regression, nonparametric curve estimation, methods for dimension reduction, classification and clustering, and the modelling of time series, spatial and spatio- temporal data. An overview of currently available software for analysing directional data is also provided, and potential future developments discussed. Keywords: Classification; Clustering; Dimension reduction; Distributional -

A Weakly Informative Default Prior Distribution for Logistic and Other
The Annals of Applied Statistics 2008, Vol. 2, No. 4, 1360–1383 DOI: 10.1214/08-AOAS191 c Institute of Mathematical Statistics, 2008 A WEAKLY INFORMATIVE DEFAULT PRIOR DISTRIBUTION FOR LOGISTIC AND OTHER REGRESSION MODELS By Andrew Gelman, Aleks Jakulin, Maria Grazia Pittau and Yu-Sung Su Columbia University, Columbia University, University of Rome, and City University of New York We propose a new prior distribution for classical (nonhierarchi- cal) logistic regression models, constructed by first scaling all nonbi- nary variables to have mean 0 and standard deviation 0.5, and then placing independent Student-t prior distributions on the coefficients. As a default choice, we recommend the Cauchy distribution with cen- ter 0 and scale 2.5, which in the simplest setting is a longer-tailed version of the distribution attained by assuming one-half additional success and one-half additional failure in a logistic regression. Cross- validation on a corpus of datasets shows the Cauchy class of prior dis- tributions to outperform existing implementations of Gaussian and Laplace priors. We recommend this prior distribution as a default choice for rou- tine applied use. It has the advantage of always giving answers, even when there is complete separation in logistic regression (a common problem, even when the sample size is large and the number of pre- dictors is small), and also automatically applying more shrinkage to higher-order interactions. This can be useful in routine data analy- sis as well as in automated procedures such as chained equations for missing-data imputation. We implement a procedure to fit generalized linear models in R with the Student-t prior distribution by incorporating an approxi- mate EM algorithm into the usual iteratively weighted least squares. -

Measures of Fit for Logistic Regression Paul D
Paper 1485-2014 SAS Global Forum Measures of Fit for Logistic Regression Paul D. Allison, Statistical Horizons LLC and the University of Pennsylvania ABSTRACT One of the most common questions about logistic regression is “How do I know if my model fits the data?” There are many approaches to answering this question, but they generally fall into two categories: measures of predictive power (like R-square) and goodness of fit tests (like the Pearson chi-square). This presentation looks first at R-square measures, arguing that the optional R-squares reported by PROC LOGISTIC might not be optimal. Measures proposed by McFadden and Tjur appear to be more attractive. As for goodness of fit, the popular Hosmer and Lemeshow test is shown to have some serious problems. Several alternatives are considered. INTRODUCTION One of the most frequent questions I get about logistic regression is “How can I tell if my model fits the data?” Often the questioner is expressing a genuine interest in knowing whether a model is a good model or a not-so-good model. But a more common motivation is to convince someone else--a boss, an editor, or a regulator--that the model is OK. There are two very different approaches to answering this question. One is to get a statistic that measures how well you can predict the dependent variable based on the independent variables. I’ll refer to these kinds of statistics as measures of predictive power. Typically, they vary between 0 and 1, with 0 meaning no predictive power whatsoever and 1 meaning perfect predictions. -
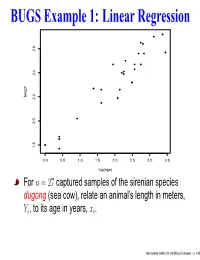
BUGS Example 1: Linear Regression Length 1.8 2.0 2.2 2.4 2.6
BUGS Example 1: Linear Regression length 1.8 2.0 2.2 2.4 2.6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 log(age) For n = 27 captured samples of the sirenian species dugong (sea cow), relate an animal’s length in meters, Yi, to its age in years, xi. Intermediate WinBUGS and BRugs Examples – p. 1/35 BUGS Example 1: Linear Regression length 1.8 2.0 2.2 2.4 2.6 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 log(age) For n = 27 captured samples of the sirenian species dugong (sea cow), relate an animal’s length in meters, Yi, to its age in years, xi. To avoid a nonlinear model for now, transform xi to the log scale; plot of Y versus log(x) looks fairly linear! Intermediate WinBUGS and BRugs Examples – p. 1/35 Simple linear regression in WinBUGS Yi = β0 + β1 log(xi) + ǫi, i = 1,...,n iid where ǫ N(0,τ) and τ = 1/σ2, the precision in the data. i ∼ Prior distributions: flat for β0, β1 vague gamma on τ (say, Gamma(0.1, 0.1), which has mean 1 and variance 10) is traditional Intermediate WinBUGS and BRugs Examples – p. 2/35 Simple linear regression in WinBUGS Yi = β0 + β1 log(xi) + ǫi, i = 1,...,n iid where ǫ N(0,τ) and τ = 1/σ2, the precision in the data. i ∼ Prior distributions: flat for β0, β1 vague gamma on τ (say, Gamma(0.1, 0.1), which has mean 1 and variance 10) is traditional posterior correlation is reduced by centering the log(xi) around their own mean Intermediate WinBUGS and BRugs Examples – p. -

1D Regression Models Such As Glms
Chapter 4 1D Regression Models Such as GLMs ... estimates of the linear regression coefficients are relevant to the linear parameters of a broader class of models than might have been suspected. Brillinger (1977, p. 509) After computing β,ˆ one may go on to prepare a scatter plot of the points (βxˆ j, yj), j =1,...,n and look for a functional form for g( ). Brillinger (1983, p. 98) · This chapter considers 1D regression models including additive error re- gression (AER), generalized linear models (GLMs), and generalized additive models (GAMs). Multiple linear regression is a special case of these four models. See Definition 1.2 for the 1D regression model, sufficient predictor (SP = h(x)), estimated sufficient predictor (ESP = hˆ(x)), generalized linear model (GLM), and the generalized additive model (GAM). When using a GAM to check a GLM, the notation ESP may be used for the GLM, and EAP (esti- mated additive predictor) may be used for the ESP of the GAM. Definition 1.3 defines the response plot of ESP versus Y . Suppose the sufficient predictor SP = h(x). Often SP = xT β. If u only T T contains the nontrivial predictors, then SP = β1 + u β2 = α + u η is often T T T T T T used where β = (β1, β2 ) = (α, η ) and x = (1, u ) . 4.1 Introduction First we describe some regression models in the following three definitions. The most general model uses SP = h(x) as defined in Definition 1.2. The GAM with SP = AP will be useful for checking the model (often a GLM) with SP = xT β. -

Bayesian Orientation Estimation and Local Surface Informativeness for Active Object Pose Estimation Sebastian Riedel
Drucksachenkategorie Drucksachenkategorie Bayesian Orientation Estimation and Local Surface Informativeness for Active Object Pose Estimation Sebastian Riedel DEPARTMENT OF INFORMATICS TECHNISCHE UNIVERSITAT¨ MUNCHEN¨ Master’s Thesis in Informatics Bayesian Orientation Estimation and Local Surface Informativeness for Active Object Pose Estimation Bayessche Rotationsschatzung¨ und lokale Oberflachenbedeutsamkeit¨ fur¨ aktive Posenschatzung¨ von Objekten Author: Sebastian Riedel Supervisor: Prof. Dr.-Ing. Darius Burschka Advisor: Dipl.-Ing. Simon Kriegel Dr.-Inf. Zoltan-Csaba Marton Date: November 15, 2014 I confirm that this master’s thesis is my own work and I have documented all sources and material used. Munich, November 15, 2014 Sebastian Riedel Acknowledgments The successful completion of this thesis would not have been possible without the help- ful suggestions, the critical review and the fruitful discussions with my advisors Simon Kriegel and Zoltan-Csaba Marton, and my supervisor Prof. Darius Burschka. In addition, I want to thank Manuel Brucker for helping me with the camera calibration necessary for the acquisition of real test data. I am very thankful for what I have learned throughout this work and enjoyed working within this team and environment very much. This thesis is dedicated to my family, first and foremost my parents Elfriede and Kurt, who supported me in the best way I can imagine. Furthermore, I would like to thank Irene and Eberhard, dear friends of my mother, who supported me financially throughout my whole studies. vii Abstract This thesis considers the problem of active multi-view pose estimation of known objects from 3d range data and therein two main aspects: 1) the fusion of orientation measure- ments in order to sequentially estimate an objects rotation from multiple views and 2) the determination of informative object parts and viewing directions in order to facilitate plan- ning of view sequences which lead to accurate and fast converging orientation estimates. -

The Overlooked Potential of Generalized Linear Models in Astronomy, I: Binomial Regression
Astronomy and Computing 12 (2015) 21–32 Contents lists available at ScienceDirect Astronomy and Computing journal homepage: www.elsevier.com/locate/ascom Full length article The overlooked potential of Generalized Linear Models in astronomy, I: Binomial regression R.S. de Souza a,∗, E. Cameron b, M. Killedar c, J. Hilbe d,e, R. Vilalta f, U. Maio g,h, V. Biffi i, B. Ciardi j, J.D. Riggs k, for the COIN collaboration a MTA Eötvös University, EIRSA ``Lendulet'' Astrophysics Research Group, Budapest 1117, Hungary b Department of Zoology, University of Oxford, Tinbergen Building, South Parks Road, Oxford, OX1 3PS, United Kingdom c Universitäts-Sternwarte München, Scheinerstrasse 1, D-81679, München, Germany d Arizona State University, 873701, Tempe, AZ 85287-3701, USA e Jet Propulsion Laboratory, 4800 Oak Grove Dr., Pasadena, CA 91109, USA f Department of Computer Science, University of Houston, 4800 Calhoun Rd., Houston TX 77204-3010, USA g INAF — Osservatorio Astronomico di Trieste, via G. Tiepolo 11, 34135 Trieste, Italy h Leibniz Institute for Astrophysics, An der Sternwarte 16, 14482 Potsdam, Germany i SISSA — Scuola Internazionale Superiore di Studi Avanzati, Via Bonomea 265, 34136 Trieste, Italy j Max-Planck-Institut für Astrophysik, Karl-Schwarzschild-Str. 1, D-85748 Garching, Germany k Northwestern University, Evanston, IL, 60208, USA article info a b s t r a c t Article history: Revealing hidden patterns in astronomical data is often the path to fundamental scientific breakthroughs; Received 26 September 2014 meanwhile the complexity of scientific enquiry increases as more subtle relationships are sought. Con- Accepted 2 April 2015 temporary data analysis problems often elude the capabilities of classical statistical techniques, suggest- Available online 29 April 2015 ing the use of cutting edge statistical methods. -

Bayesian Methods of Earthquake Focal Mechanism Estimation and Their Application to New Zealand Seismicity Data ’
Final Report to the Earthquake Commission on Project No. UNI/536: ‘Bayesian methods of earthquake focal mechanism estimation and their application to New Zealand seismicity data ’ David Walsh, Richard Arnold, John Townend. June 17, 2008 1 Layman’s abstract We investigate a new probabilistic method of estimating earthquake focal mech- anisms — which describe how a fault is aligned and the direction it slips dur- ing an earthquake — taking into account observational uncertainties. Robust methods of estimating focal mechanisms are required for assessing the tectonic characteristics of a region and as inputs to the problem of estimating tectonic stress. We make use of Bayes’ rule, a probabilistic theorem that relates data to hypotheses, to formulate a posterior probability distribution of the focal mech- anism parameters, which we can use to explore the probability of any focal mechanism given the observed data. We then attempt to summarise succinctly this probability distribution by the use of certain known probability distribu- tions for directional data. The advantages of our approach are that it (1) models the data generation process and incorporates observational errors, particularly those arising from imperfectly known earthquake locations; (2) allows explo- ration of all focal mechanism possibilities; (3) leads to natural estimates of focal mechanism parameters; (4) allows the inclusion of any prior information about the focal mechanism parameters; and (5) that the resulting posterior PDF can be well approximated by generalised statistical distributions. We demonstrate our methods using earthquake data from New Zealand. We first consider the case in which the seismic velocity of the region of interest (described by a veloc- ity model) is presumed to be precisely known, with application to seismic data from the Raukumara Peninsula, New Zealand. -

Generalized Linear Models I
Statistics 203: Introduction to Regression and Analysis of Variance Generalized Linear Models I Jonathan Taylor - p. 1/18 Today's class ● Today's class ■ Logistic regression. ● Generalized linear models ● Binary regression example ■ ● Binary outcomes Generalized linear models. ● Logit transform ■ ● Binary regression Deviance. ● Link functions: binary regression ● Link function inverses: binary regression ● Odds ratios & logistic regression ● Link & variance fns. of a GLM ● Binary (again) ● Fitting a binary regression GLM: IRLS ● Other common examples of GLMs ● Deviance ● Binary deviance ● Partial deviance tests 2 ● Wald χ tests - p. 2/18 Generalized linear models ● Today's class ■ All models we have seen so far deal with continuous ● Generalized linear models ● Binary regression example outcome variables with no restriction on their expectations, ● Binary outcomes ● Logit transform and (most) have assumed that mean and variance are ● Binary regression ● Link functions: binary unrelated (i.e. variance is constant). regression ● Link function inverses: binary ■ Many outcomes of interest do not satisfy this. regression ● Odds ratios & logistic ■ regression Examples: binary outcomes, Poisson count outcomes. ● Link & variance fns. of a GLM ● Binary (again) ■ A Generalized Linear Model (GLM) is a model with two ● Fitting a binary regression GLM: IRLS ingredients: a link function and a variance function. ● Other common examples of GLMs ◆ The link relates the means of the observations to ● Deviance ● Binary deviance predictors: linearization ● Partial deviance tests 2 ◆ ● Wald χ tests The variance function relates the means to the variances. - p. 3/18 Binary regression example ● Today's class ■ A local health clinic sent fliers to its clients to encourage ● Generalized linear models ● Binary regression example everyone, but especially older persons at high risk of ● Binary outcomes ● Logit transform complications, to get a flu shot in time for protection against ● Binary regression ● Link functions: binary an expected flu epidemic. -

UNIVERSITY of CALIFORNIA Los Angeles Models for Spatial Point
UNIVERSITY OF CALIFORNIA Los Angeles Models for Spatial Point Processes on the Sphere With Application to Planetary Science A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Statistics by Meihui Xie 2018 c Copyright by Meihui Xie 2018 ABSTRACT OF THE DISSERTATION Models for Spatial Point Processes on the Sphere With Application to Planetary Science by Meihui Xie Doctor of Philosophy in Statistics University of California, Los Angeles, 2018 Professor Mark Stephen Handcock, Chair A spatial point process is a random pattern of points on a space A ⊆ Rd. Typically A will be a d-dimensional box. Point processes on a plane have been well-studied. However, not much work has been done when it comes to modeling points on Sd−1 ⊂ Rd. There is some work in recent years focusing on extending exploratory tools on Rd to Sd−1, such as the widely used Ripley's K function. In this dissertation, we propose a more general framework for modeling point processes on S2. The work is motivated by the need for generative models to understand the mechanisms behind the observed crater distribution on Venus. We start from a background introduction on Venusian craters. Then after an exploratory look at the data, we propose a suite of Exponential Family models, motivated by the Von Mises-Fisher distribution and its gener- alization. The model framework covers both Poisson-type models and more sophisticated interaction models. It also easily extends to modeling marked point process. For Poisson- type models, we develop likelihood-based inference and an MCMC algorithm to implement it, which is called MCMC-MLE. -

Chapter 12 Generalized Linear Models
Chapter 12 Generalized Linear Models 12.1 Introduction Generalized linear models are an important class of parametric 1D regression models that include multiple linear regression, logistic regression and loglin- ear Poisson regression. Assume that there is a response variable Y and a k × 1 vector of nontrivial predictors x. Before defining a generalized linear model, the definition of a one parameter exponential family is needed. Let f(y) be a probability density function (pdf) if Y is a continuous random variable and let f(y) be a probability mass function (pmf) if Y is a discrete random variable. Assume that the support of the distribution of Y is Y and that the parameter space of θ is Θ. Definition 12.1. A family of pdfs or pmfs {f(y|θ):θ ∈ Θ} is a 1-parameter exponential family if f(y|θ)=k(θ)h(y)exp[w(θ)t(y)] (12.1) where k(θ) ≥ 0andh(y) ≥ 0. The functions h, k, t, and w are real valued functions. In the definition, it is crucial that k and w do not depend on y and that h and t do not depend on θ. The parameterization is not unique since, for example, w could be multiplied by a nonzero constant m if t is divided by m. Many other parameterizations are possible. If h(y)=g(y)IY(y), then usually k(θ)andg(y) are positive, so another parameterization is f(y|θ)=exp[w(θ)t(y)+d(θ)+S(y)]IY(y) (12.2) 401 where S(y)=log(g(y)),d(θ)=log(k(θ)), and the support Y does not depend on θ.