Arxiv:2010.01611V2 [Cs.CL] 19 Oct 2020 ( Ulcdtst,Eg QA ( Squad Comprehensive2016 E.G
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Set Info - Player - National Treasures Basketball
Set Info - Player - National Treasures Basketball Player Total # Total # Total # Total # Total # Autos + Cards Base Autos Memorabilia Memorabilia Luka Doncic 1112 0 145 630 337 Joe Dumars 1101 0 460 441 200 Grant Hill 1030 0 560 220 250 Nikola Jokic 998 154 420 236 188 Elie Okobo 982 0 140 630 212 Karl-Anthony Towns 980 154 0 752 74 Marvin Bagley III 977 0 10 630 337 Kevin Knox 977 0 10 630 337 Deandre Ayton 977 0 10 630 337 Trae Young 977 0 10 630 337 Collin Sexton 967 0 0 630 337 Anthony Davis 892 154 112 626 0 Damian Lillard 885 154 186 471 74 Dominique Wilkins 856 0 230 550 76 Jaren Jackson Jr. 847 0 5 630 212 Toni Kukoc 847 0 420 235 192 Kyrie Irving 846 154 146 472 74 Jalen Brunson 842 0 0 630 212 Landry Shamet 842 0 0 630 212 Shai Gilgeous- 842 0 0 630 212 Alexander Mikal Bridges 842 0 0 630 212 Wendell Carter Jr. 842 0 0 630 212 Hamidou Diallo 842 0 0 630 212 Kevin Huerter 842 0 0 630 212 Omari Spellman 842 0 0 630 212 Donte DiVincenzo 842 0 0 630 212 Lonnie Walker IV 842 0 0 630 212 Josh Okogie 842 0 0 630 212 Mo Bamba 842 0 0 630 212 Chandler Hutchison 842 0 0 630 212 Jerome Robinson 842 0 0 630 212 Michael Porter Jr. 842 0 0 630 212 Troy Brown Jr. 842 0 0 630 212 Joel Embiid 826 154 0 596 76 Grayson Allen 826 0 0 614 212 LaMarcus Aldridge 825 154 0 471 200 LeBron James 816 154 0 662 0 Andrew Wiggins 795 154 140 376 125 Giannis 789 154 90 472 73 Antetokounmpo Kevin Durant 784 154 122 478 30 Ben Simmons 781 154 0 627 0 Jason Kidd 776 0 370 330 76 Robert Parish 767 0 140 552 75 Player Total # Total # Total # Total # Total # Autos -

Records All-Time Pistons Team Records All-Time Pistons Team Records
RECORDS ALL-TIME PISTONS TEAM RECORDS ALL-TIME PISTONS TEAM RECORDS SINGLE SEASON SINGLE GAME OR PORTION (CONTINUED) Most Points 9,725 1967-68 Steals 877 1976-77 MOST THREE-POINT FIELD GOALS ATTEMPTED Highest Scoring Average 118.6 1967-68 Blocked Shots 572 1982-83 LEADERSHIP Lowest Defensive Average 84.3 2003-04 Most Turnovers 1,858 1977-78 Game 47 at Memphis Apr. 8, 2018 Field Goals 3,840 1984-85 Fewest Turnovers *931 2005-06 Half 28 vs. Atlanta (2nd) Jan. 9, 2015 Field Goals Attempted 8,502 1965-66 Most Victories 64 2005-06 Quarter 15 vs. Atlanta (4th) Jan. 9, 2015 Field Goal % .494 1988-89 Fewest Victories 16 1979-80 MOST REBOUNDS Free Throws 2,408 1960-61 Best Winning % .780 (64-18) 2005-06 Game 107 vs. Boston (at New York) (OT) Nov. 15, 1960 Free Throws Attempted 3,220 1960-61 Poorest Winning % .195 (16-66) 1979-80 Half 52 vs. Seattle (2nd) Jan. 19, 1968 Free Throw % .788 1984-85 Most Home Victories 37 (of 41) 1988-89; 2005-06 Quarter 38 vs. St. Louis (at Olympia) (2nd) Dec. 7, 1960 Three-Point Field Goals 993 2018-19 Fewest Home Victories 9 (of 30) 1963-64 Three-Point Field Goals Attempted 2,854 2018-19 Most Road Victories 27 (of 41) 2005-06; 2006-07 MOST OFFENSIVE REBOUNDS 3-Point Field Goal % .404 1995-96 Fewest Road Victories 3 (of 19) 1960-61 Game 36 at L.A. Lakers Dec. 14, 1975 Most Rebounds 5,823 1961-62 3 (of 38) 1979-80 Half 19 vs. -

The Role Identity Plays in B-Ball Players' and Gangsta Rappers
Vassar College Digital Window @ Vassar Senior Capstone Projects 2016 Playin’ tha game: the role identity plays in b-ball players’ and gangsta rappers’ public stances on black sociopolitical issues Kelsey Cox Vassar College Follow this and additional works at: https://digitalwindow.vassar.edu/senior_capstone Recommended Citation Cox, Kelsey, "Playin’ tha game: the role identity plays in b-ball players’ and gangsta rappers’ public stances on black sociopolitical issues" (2016). Senior Capstone Projects. 527. https://digitalwindow.vassar.edu/senior_capstone/527 This Open Access is brought to you for free and open access by Digital Window @ Vassar. It has been accepted for inclusion in Senior Capstone Projects by an authorized administrator of Digital Window @ Vassar. For more information, please contact [email protected]. Cox playin’ tha Game: The role identity plays in b-ball players’ and gangsta rappers’ public stances on black sociopolitical issues A Senior thesis by kelsey cox Advised by bill hoynes and Justin patch Vassar College Media Studies April 22, 2016 !1 Cox acknowledgments I would first like to thank my family for helping me through this process. I know it wasn’t easy hearing me complain over school breaks about the amount of work I had to do. Mom – thank you for all of the help and guidance you have provided. There aren’t enough words to express how grateful I am to you for helping me navigate this thesis. Dad – thank you for helping me find my love of basketball, without you I would have never found my passion. Jon – although your constant reminders about my thesis over winter break were annoying you really helped me keep on track, so thank you for that. -

2014-15 Prestige Premium Basketball - Purple = RC 76ERS Player Set Card # Team Print Run
2014-15 Prestige Premium Basketball - Purple = RC 76ERS Player Set Card # Team Print Run Allen Iverson Bonus Shots Materials Premium (All Parallels Included) 26 76ers 140 Arnett Moultrie Bonus Shots Autographs Premium (All Parallels Included) 11 76ers 438 Bobby Jones Old School Signatures Premium 16 76ers 175 Chet Walker Bonus Shots Autographs Premium (All Parallels Included) 25 76ers 112 Dolph Schayes Bonus Shots Autographs Premium (All Parallels Included) 2 76ers 63 Dolph Schayes Old School Signatures Premium 25 76ers 25 Doug Collins Old School Signatures Premium 60 76ers 175 Doug Collins Stars of the NBA Signatures Premium 36 76ers 149 Hollis Thompson Bonus Shots Autographs Premium (All Parallels Included) 81 76ers 438 Joel Embiid Prestigious Premieres Signatures Premium 13 76ers n/a Maurice Cheeks Old School Signatures Premium 34 76ers 175 Maurice Cheeks Stars of the NBA Signatures Premium 40 76ers 175 Michael Carter-Williams Bonus Shots Autographs Premium (All Parallels Included) 70 76ers 196 Michael Carter-Williams Bonus Shots Materials Premium (All Parallels Included) 28 76ers 116 Nerlens Noel Bonus Shots Autographs Premium (All Parallels Included) 20 76ers 196 Nerlens Noel Preeminent Ink Premium 4 76ers 10 Nerlens Noel Stars of the NBA Signatures Premium 54 76ers 10 Steve Mix Old School Signatures Premium 4 76ers 175 Thaddeus Young Preeminent Ink Premium 14 76ers 175 11/2/14 www.groupbreakchecklists.com 14/15 Prestige Premium 2014-15 Prestige Premium Basketball - Purple = RC BLAZERS Player Set Card # Team Print Run Bill Walton -

Local AIDS Related Services the National Directory
If you have issues viewing or accessing this file contact us at NCJRS.gov. Local AIDS Related Services The National Directory February 1988 . Conference of Mayors The Fund for Human Dignity, Inc. t,,··· Local AIDS Related Services The N ationq,l Directory ~,. February 1988 tt CJRS tAl\R ~l '9M ..... SI1"tON $ ~oQ'Ul The U.S. Conference of Mayors The Fund for Human Dignity, Inc. 1620 Eye Street, NW 666 Broadway Washington, DC 20006 New York, NY 10012 (202) 293-7330 (212) 529-1600 The United States Conference of Mayors Richard L. Berkley President Mayor of Kansas City, Missouri 110092 U.s. Department of Justice National Institute of Justice J. Thomas Cochran This document has been reproduced exactly as received from the person or organization originating it. Points of view or opinions stated Executive Director in this document are those of the authors and do not necessarily U.S. Conference of Mayors represent the official position or policies of the National Institute of Justice. Permission to reproduce this copyrighted material has been granted by U.S. Conference of Mayors to the National Criminal Justice Reference Service (NCJRS). Further reproduction outside of the NCJRS system requires permis Sion of the copyright owner. This publication was prepared by the Conference. of Mayors AIDS Program. Program staff include Ri.chard D. Johnson, Assistant Executive Director; Alan E. Gambrell, Senior Staff Associate, who was responsible for the development of this document; Matthew Murguia, Staff Assistant II; and Phyllis Dickerson-Wheeler, Administrative Assistant II. The Directory was prepared" with assistance from the U.S. -
1980-89 NBA Finals
NBA FINALS 198 0 - 1 9 8 9 Detroit Pistons sweep Los Angeles Lakers 1 63-19 1E under Chuck Daly 57-25 1W under Pat Riley June 6, 8, 11, 13 9 Joe Dumars DET Finals MVP 27.3 pts, 6.0 ast, 1.8 reb 8 Pistons win their first-ever NBA championship 9 During season, Pat Riley trademarked phrase “Three-peat” Lakers 97 @ Pistons 109 at The Palace of Auburn Hills – Isiah Thomas DET 24 pts, 9 ast; Joe Dumars DET 22 pts Lakers 105 @ Pistons 108 – Joe Dumars DET 33 pts; Magic Johnson LAL injures hamstring, plays only 5 more mins in series Pistons 114 @ Lakers 110 at Great Western Forum – Joe Dumars DET 31 pts; Dennis Rodman DET 19 reb Pistons 105 @ Lakers 97 – Joe Dumars DET 23 pts; James Worthy LAL 40 pts Pistons’ starters – G Isiah Thomas, G Joe Dumars, C Bill Laimbeer, F Mark Aguirre, F Rick Mahorn Lakers’ starters – G Magic Johnson, G Michael Cooper, C Kareem Abdul-Jabbar, F A.C. Green, F James Worthy 1 Los Angeles Lakers defeat Detroit Pistons in 7 9 62-20 1W under Pat Riley 54-28 2E under Chuck Daly June 7, 9, 12, 14, 16, 19, 21 8 James Worthy LAL Finals MVP 22.0 pts, 4.4 ast, 7.4 reb 8 Pistons 105 @ Lakers 93 at Great Western Forum – Adrian Dantley DET 34 pts; Isiah Thomas DET 19 pts, 12 ast Pistons 96 @ Lakers 108 – James Worthy LAL 26 pts, 10 reb, 6 ast; Byron Scott LAL 24 pts; Magic Johnson LAL 11 ast Lakers 99 @ Pistons 86 at Pontiac Silverdome – James Worthy LAL 24 pts; Magic Johnson LAL 18 pts, 14 ast Lakers 86 @ Pistons 111 – Adrian Dantley DET 27 pts; Isiah Thomas DET 9 rb, 12 as; Vinnie Johnson DET 16 pts off bench Lakers 94 @ Pistons 104 – Adrian Dantley DET 25 pts; Bill Laimbeer DET 11 reb; John Salley DET 10 reb Pistons 102 @ Lakers 103 – James Worthy LAL 28 pts; Magic Johnson LAL 19 pts, 22 ast Pistons 105 @ Lakers 108 – James Worthy LAL 36 pts, 16 reb, 10 ast; Magic Johnson LAL 19 pts, 14 ast Lakers’ starters – G Magic Johnson, G Byron Scott, C Kareem Abdul-Jabbar, F A.C. -

History All-Time Coaching Records All-Time Coaching Records
HISTORY ALL-TIME COACHING RECORDS ALL-TIME COACHING RECORDS REGULAR SEASON PLAYOFFS REGULAR SEASON PLAYOFFS CHARLES ECKMAN HERB BROWN SEASON W-L PCT W-L PCT SEASON W-L PCT W-L PCT LEADERSHIP 1957-58 9-16 .360 1975-76 19-21 .475 4-5 .444 TOTALS 9-16 .360 1976-77 44-38 .537 1-2 .333 1977-78 9-15 .375 RED ROCHA TOTALS 72-74 .493 5-7 .417 SEASON W-L PCT W-L PCT 1957-58 24-23 .511 3-4 .429 BOB KAUFFMAN 1958-59 28-44 .389 1-2 .333 SEASON W-L PCT W-L PCT 1959-60 13-21 .382 1977-78 29-29 .500 TOTALS 65-88 .425 4-6 .400 TOTALS 29-29 .500 DICK MCGUIRE DICK VITALE SEASON W-L PCT W-L PCT SEASON W-L PCT W-L PCT PLAYERS 1959-60 17-24 .414 0-2 .000 1978-79 30-52 .366 1960-61 34-45 .430 2-3 .400 1979-80 4-8 .333 1961-62 37-43 .463 5-5 .500 TOTALS 34-60 .362 1962-63 34-46 .425 1-3 .250 RICHIE ADUBATO TOTALS 122-158 .436 8-13 .381 SEASON W-L PCT W-L PCT CHARLES WOLF 1979-80 12-58 .171 SEASON W-L PCT W-L PCT TOTALS 12-58 .171 1963-64 23-57 .288 1964-65 2-9 .182 SCOTTY ROBERTSON REVIEW 18-19 TOTALS 25-66 .274 SEASON W-L PCT W-L PCT 1980-81 21-61 .256 DAVE DEBUSSCHERE 1981-82 39-43 .476 SEASON W-L PCT W-L PCT 1982-83 37-45 .451 1964-65 29-40 .420 TOTALS 97-149 .394 1965-66 22-58 .275 1966-67 28-45 .384 CHUCK DALY TOTALS 79-143 .356 SEASON W-L PCT W-L PCT 1983-84 49-33 .598 2-3 .400 DONNIE BUTCHER 1984-85 46-36 .561 5-4 .556 SEASON W-L PCT W-L PCT 1985-86 46-36 .561 1-3 .250 RE 1966-67 2-6 .250 1986-87 52-30 .634 10-5 .667 1967-68 40-42 .488 2-4 .333 1987-88 54-28 .659 14-9 .609 CORDS 1968-69 10-12 .455 1988-89 63-19 .768 15-2 .882 TOTALS 52-60 .464 2-4 .333 -

Vip Transcript Series
VIP TRANSCRIPT SERIES Interview with John Salley John Salley, basketball champion, was the first NBA player to win four championships with three different teams. An outspoken advocate for vegan living, John spent seven years serving as the co-host of the Emmy nominated, critically acclaimed The Best Damn Sports Show Period on Fox Sports Net. http://www.veganpalooza.com/ Winning with A Vegan Diet STEVE PRUSSACK: Hello and welcome to Veganpalooza 2013. I’m your co-host Steve Prussack, and we’re so happy to have you with us. This is our kick-off session, and what better guest than celebrity guest, superstar athlete champion John Salley. Dr. Will Tuttle, I’m going to bring you on the call right now. DR. WILL TUTTLE: Hi, I’m here, and I’m delighted to have basketball champion John Salley with us here on Veganpalooza 2013. He was the first NBA player to win four championships with three different teams. He is an outspoken advocate for vegan living. He spent seven years serving as the co-host of the Emmy-nominated critically acclaimed show “The Best Damn Sports Show Period” on the Fox Sports Network. He’s a frequent speaker at veg fests across the United States and has been involved with PCRM, Physicians Committee for Responsible Medicine, working with them to help persuade Congress to create legislation creating vegan options in public schools. I have had the opportunity myself to hear John Salley speak several times, and I am really glad to have John with us. It’s really an honor. -

THE RUMPH and FREDERICK FAMILIES
THE RUMPH and FREDERICK FAMILIES GENEALOGICAL AND BIOGRAPHICAL with ALLIED FAMILIES OF Datwyler, Harrisperger, Hesse, Kaigler, Rickenbacker, Murph, Wolfe, Jamison, Carmichael, Cooner, Gholson, Pooser, Wannamaker, Glover, Walter, Farrior, Shuler, Fun ches, Feaster, Cart, Cain, Robinson, Felder, Slappey, Plant, Jones, Davenport, Walker, Everett, Haslam, Walker, Norris, Rowe, and Other Families. By LOUISE FREDERICK HAYS PRIVATELY PUBLISHED-LIMITED EDITION VoLUME No./ 7 'f PUBLISHED FOR: COPYRIGHT 1.942 BY LOUISE FREDERICK HAYS JOHN T. HANCOCK Publisher Atlanta, Georgia ,_·•- ~~-~.-:.:~,.~--.. .,.~ ~.r;'42!t f~ij...~.:·· --: ·:t,,,,,...., .. -· ~: ,,., 5-~·- ;~\- '.,., .· . "-"' . -- ··- . "l . ,,. - ¥'•;./: ·."t":=;!~-~ ~ ~.,. ..... """"' .,. \ ~:- " ...:«--._ ~-~ ,.,J •- • ...., • ,,- r - ~, -~ ......... ~ ---~ . -. ~ . ' -:' .............-. , . -.,. ...... l • ,. ~ .. --.e;.-~-..,II.~ • ... ~.;. ...,.,.__\ , ---· ♦-~ .... .;-: ~-"' :~~- t~ ... ~~ .•. , --~· .... ~~ . ·:. !J../ ;.- . ... ..' ... --...·· ,~ --·-..,II,· • ..... ... " ~~~::,,.·""' .• I . -~~ ,;e--.-.....,._-;. .,.., - ~·;:~tt-~ -........·----~- ... -....,.,.,.,~_....,_,. ~--;-' . ·-:: ...... ~~~ ..... ,.,; -- .,,,. ;.:~~,..--..... --- ....... _~,,. "• -~..,...&~"'•:... ... z:~}~:;?~.(~ .. -· :-.~;~:-:e .. --,,3-! St. John's Lutheran Church, Charleston, South Carolina Rcicrozd John George FricJcrick,, First ),ffoislcr DEDICATION To the Me,nory of ,,ny Father, Major Ja111es Daniel Frederick, a Descendant of both The Frederick and the Rumph Families, This Volume is Dedicated -

The NCAA News
The N ews - January 30, 1985, Volume 22 Number--~- 5 _ ational Collegiate Athletic Association Davis identifies three ‘challenges’ Budget restraints Newly elected NCAA President Problems are solvedand issues John R. Davis has identified three addressed by people of good will “interesting challenges” that he working together in a spirit of likely to continue hopes to address during his two- mutual endeavor. Democracy is year term as the Association’s top built on this premise and so is The NCAA is facing further bud- l The Association’s continued po- elected official. the NCAA. get restraints for the 1986-87 fiscal tential to pay competitors’transporta- Speaking to the delegates at “With the adoption of propos- year on the heels of recent actions by tion costs to NCAA championships the 1985 NCAA Convention in als 29 and 30, and with the the Executive Committee to reduce represents a benefit made possible Nashville, the Oregon State Uni- anticipated decisive actions of the costs in 1985-86. by receipts in excess of those required versity faculty athletics represen- Presidents’ Commission, I am cer- Information developed for The for fundamental NCAA services. “For tative listed academic issues, in- tain that we now are in a good NCAA News by Louis J. Spry, the more than 50 years, the NCAA did tegrity in athletics and NCAA position ~ perhaps the best of all Association’s controller, projects a not pay transportation costs for its governance as the three key areas. time-to address appropriately $158,000 deficit in 1986-87, with ex- championships,” Spry stated. -

MEDIA GUIDE VLADE DIVAC GENERAL MANAGER Vlade Divac Enters His Sixth Season at the Kings, His Fifth As General Manager
2019-20 PRESEASON MEDIA GUIDE VLADE DIVAC GENERAL MANAGER Vlade Divac enters his sixth season at the Kings, his fifth as General Manager. He joined the Kings on March 3, 2015 as the team’s vice president of basketball and franchise operations and was named General Manager on August 31, 2015. One of the most respected and revered individuals in franchise history, Divac returns to Sacramento having spent more than a decade serving the NBA and international sporting communities with the same distinction that solidified his reputation as a consummate teammate, player, humanitarian and overall difference-maker on and off the basketball court. Divac has served in a variety of administrative and leadership roles since retiring from professional basketball in 2007. In addition to his philanthropic efforts focused on helping children in his native country and other reaches of the globe, he was named President of the Serbian Olympic Committee in 2009. Under his guidance, Serbian athletes have enjoyed greater success and the country is experiencing a resurgence on the international stage. In 16 NBA campaigns with Los Angeles, Charlotte and Sacramento, Divac averaged 11.8 points, 8.2 rebounds, 3.1 assists, 1.1 steals, and 1.4 blocks per game over 1,134 contests. He is only one of four players in league annals to accrue at least 13,000 points, 9,000 rebounds, 3,000 assists, 1,200 steals and 1,600 blocked shots, joining Kareem Abdul-Jabbar, Hakeem Olajuwon and Kevin Garnett with that distinction. His six seasons in a Kings uniform marked the most successful period in team history, including a league-high 61 wins in 2001-02 and a trip to the Western Conference Finals. -
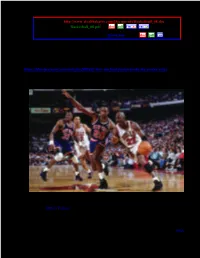
How Michael Jordan Broke the 'Jordan Rules' by Ric Bucher / CNN Bleacher Report / April 24, 2020
archived as http://www.stealthskater.com/Documents/Basketball_08.doc (also …Basketball_08.pdf) => doc pdf URL-doc URL-pdf more sports-related articles are on the /Sports.htm page at doc pdf URL note: because important websites are frequently "here today but gone tomorrow", the following was archived on 04/27/2020. This is NOT an attempt to divert readers from the aforementioned website. Indeed, the reader should only read this back-up copy if the updated original cannot be found at the original author's site. https://bleacherreport.com/articles/2888183-how-michael-jordan-broke-the-jordan-rules how Michael Jordan broke the 'Jordan Rules' by Ric Bucher / CNN Bleacher Report / April 24, 2020 For the last month-or-so, the most eye-catching sports highlights on TV have been those from 30 years ago showing the low blows Michael Jordan suffered at the hands (and elbows, hips, forearms, and knees) of the Detroit Pistons. 3 consecutive postseasons Jordan and the Bulls faced the Pistons. And 3 consecutive postseasons the 'Bad Boys' (as the Pistons were known) recognized they couldn't stop 'Air Jordan' from taking flight. But they could decide when he landed. And how! After falling short (literally and figuratively) to those Pistons again and again and again, Jordan decided to ground himself. And that's when everything changed. For Jordan, the Bulls, and the NBA. 1 The Pistons referred to their strategy as "The Jordan Rules" apparently believing that "Goonery" was too indelicate. "The Jordan Rules by the Pistons were all about not letting him get to the basket," says former Bulls center Will Perdue who played in the last two of those futile Pistons series.