ANSYS Advanced Analysis Techniques Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

FEA Newsletter October 2011
October Issue - 11th Anniversary Issue PreSys™ R3 Release BETA CAE Systems S.A. FE Modeling Tool release ANSA v13.2.0 ESI engineer David Prono transatlantic boat race The Stealth LLNL M. King (left) and physicist W. Moss B-2 Spirit compression test helmet pad TABLE OF CONTENTS 2. Table of Contents 4. FEA Information Inc. Announcements 5. Participant & Industry Announcements 6. Participants 7. BETA CAE Systems S.A. announces the release of ANSA v13.2.0 11. Making A Difference Guenter & Margareta Mueller 13. LLNL researchers find way to mitigate traumatic brain injury 16. ESI sponsors in-house engineer David Prono for a transatlantic boat race 18. ETA - PreSys™ R3 Release FE Modeling Tool Now Offers ‘Part Groups’ Function 20. Toyota Collaborative Safety Research Center 23. LSTC SID-IIs-D FAST - Finite Element Model 27. Website Showcase The Snelson Atom 28. New Technology - “Where You At?” 29. SGI - Benchmarks- Top Crunch.org 35. Aerospace - The Stealth 2 36. Reference Library - Available Books 38. Solutions - PrePost Processing - Model Editing 39. Solutions - Software 40. Cloud Services – SGI 42. Cloud Services – Gridcore 43. Global Training Courses 50. FEA - CAE Consulting/Consultants 53. Software Distributors 57. Industry News - MSC.Software 59. Industry News – SGI 60. Industry News - CRAY 3 FEA Information Inc. Announcements Welcome to our 11th Anniversary Issue. A special thanks to a few of our first participant’s that supported, and continue to support FEA Information Inc.: Abe Keisoglou and Cathie Walton, (ETA) US, Brian Walker, Oasys, UK Christian Tanasecu, SGI, Guenter and Margareta Mueller, CADFEM Germany, Sam Saltiel, BETA CAE Systems SA, Greece Companies - JSOL - LSTC With this issue we will be adding new directions, opening participation, and have brought on additional staff. -

ANSYS Contact Technology Guide
ANSYS Contact Technology Guide ANSYS Release 9.0 002114 November 2004 ANSYS, Inc. is a UL registered ISO 9001: 2000 Company. ANSYS Contact Technology Guide ANSYS Release 9.0 ANSYS, Inc. Southpointe 275 Technology Drive Canonsburg, PA 15317 [email protected] http://www.ansys.com (T) 724-746-3304 (F) 724-514-9494 Copyright and Trademark Information Copyright © 2004 SAS IP, Inc. All rights reserved. Unauthorized use, distribution or duplication is prohibited. ANSYS, DesignSpace, CFX, DesignModeler, DesignXplorer, ANSYS Workbench environment, AI*Environment, CADOE and any and all ANSYS, Inc. product names referenced on any media, manual or the like, are registered trademarks or trademarks of subsidiaries of ANSYS, Inc. located in the United States or other countries. ICEM CFD is a trademark licensed by ANSYS, Inc. All other trademarks and registered trademarks are property of their respective owners. ANSYS, Inc. is a UL registered ISO 9001: 2000 Company. ANSYS Inc. products may contain U.S. Patent No. 6,055,541. Microsoft, Windows, Windows 2000 and Windows XP are registered trademarks of Microsoft Corporation. Inventor and Mechanical Desktop are registered trademarks of Autodesk, Inc. SolidWorks is a registered trademark of SolidWorks Corporation. Pro/ENGINEER is a registered trademark of Parametric Technology Corporation. Unigraphics, Solid Edge and Parasolid are registered trademarks of Electronic Data Systems Corporation (EDS). ACIS and ACIS Geometric Modeler are registered trademarks of Spatial Technology, Inc. FLEXlm License Manager is a trademark of Macrovision Corporation. This ANSYS, Inc. software product and program documentation is ANSYS Confidential Information and are furnished by ANSYS, Inc. under an ANSYS software license agreement that contains provisions concerning non-disclosure, copying, length and nature of use, warranties, disclaimers and remedies, and other provisions. -

AMD EPYC™ 7371 Processors Accelerating HPC Innovation
AMD EPYC™ 7371 Processors Solution Brief Accelerating HPC Innovation March, 2019 AMD EPYC 7371 processors (16 core, 3.1GHz): Exceptional Memory Bandwidth AMD EPYC server processors deliver 8 channels of memory with support for up The right choice for HPC to 2TB of memory per processor. Designed from the ground up for a new generation of solutions, AMD EPYC™ 7371 processors (16 core, 3.1GHz) implement a philosophy of Standards Based AMD is committed to industry standards, choice without compromise. The AMD EPYC 7371 processor delivers offering you a choice in x86 processors outstanding frequency for applications sensitive to per-core with design innovations that target the performance such as those licensed on a per-core basis. evolving needs of modern datacenters. No Compromise Product Line Compute requirements are increasing, datacenter space is not. AMD EPYC server processors offer up to 32 cores and a consistent feature set across all processor models. Power HPC Workloads Tackle HPC workloads with leading performance and expandability. AMD EPYC 7371 processors are an excellent option when license costs Accelerate your workloads with up to dominate the overall solution cost. In these scenarios the performance- 33% more PCI Express® Gen 3 lanes. per-dollar of the overall solution is usually best with a CPU that can Optimize Productivity provide excellent per-core performance. Increase productivity with tools, resources, and communities to help you “code faster, faster code.” Boost AMD EPYC processors’ innovative architecture translates to tremendous application performance with Software performance. More importantly, the performance you’re paying for can Optimization Guides and Performance be matched to the appropriate to the performance you need. -

Ansys, Inc. BUY Company Update : Software
March 9, 2020 Ansys, Inc. BUY Company Update : Software Let there be light Ansys has announced the acquisition of Lumerical, a privately- held developer of photonic design and simulation tools. The company, based in Vancouver, was founded in 2003. Jay Vleeschhouwer [email protected] Two decades ago, we asked EDA managements about the 646-442-4251 possible or eventual role of photons in computing, and the answer was that it was something to consider but that it was or would be on the horizon (or event horizon, as it were) for some time . They were Stock Symbol NASDAQ: ANSS right but that role now seems much closer to being meaningful Current Price $228.70 or necessary, though it is premature to quantify (or quanta-fy) in 12 mos. Target Price $284.00 terms of revenues, not to mention what will likely have to be a good Market Cap $19,075.7 mln gestation period vis-à-vis duly modifying or updating customers’ Shares O/S 87.0 mln design and engineering processes and techniques (meaning this acquisition is for strategic positioning as the engineering software Avg Daily Vol. (3 mos.) 472,288 shs. market evolves, as it will in this and in other respects). 52-Week Price Low/High $174.25 - $299.06 P/B 6.8x This acquisition fits with Ansys' history of acquiring physics- Price/ FCF 0.5x based software and IP, and will be part of the physics business unit (rather than, for instance, the semiconductor unit) inasmuch Fiscal Year End Dec as photonics will have a role in addressing multiple simulation ROE 19% types and application/end-market uses, i.e., multi-physics to EPS complement existing simulation functions in the portfolio. -

Michael Raad 5667 Clouds Mill Drive, Alexandria, VA, 22310 | (571) 685-0009 | [email protected]
Michael Raad 5667 Clouds Mill Drive, Alexandria, VA, 22310 | (571) 685-0009 | [email protected] Education BACHELOR OF ENGINEERING | MECHANICAL ENGINEERING | CLASS OF 2019 Experience Mechanical Engineer Intern | Consolidated Contractors Company (CCC) | June 2018 – July 2018 . Learned various processes and techniques that streamline communication on big scale projects . Worked under the supervision of engineers from different departments, familiarizing me to various engineering tasks such as Design, Procurement, Quality Assurance and Quality Control . Worked on the technical drawings and validated their accordance to many specifications such as the Qatar Constructions Specifications . Represented CCC under Quality Control by supervising technical and safety tests of elevators . Handled work orders with sub-contractors and clients on the site as part of Quality Assurance, working for 60 hours a week under temperatures exceeding 115 Maintenance Engineer | PepsiCo | January 2018 . Oversaw manufacturing processes in a large scale production facility under strict international food safety standards . Supervised maintenance work over heavy machinery . Researched for means to recover heat losses in boiler setups Engineering Intern | BMW | August 2016 . Familiarized through hands-on experience with the different systems in a vehicle . Repaired different mechanisms such as brakes, gearboxes and engine components Projects SAE SUPERMILEAGE . Designed a hyper-efficient single seater vehicle . Carried stress and CFD analysis on the vehicle that were crucial for the development of the project car using Fluent . Reduced the weight of the engine mount by performing optimization techniques using ANSYS . Developed the vehicle’s powertrain and remodeled the carbon fiber monocoque . Negotiated sponsorship proposals with several companies within the education, oil and gas and logistics industries. -
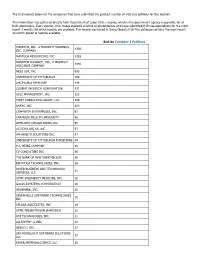
The H1B Records Below List the Companies That Have Submitted the Greatest Number of H1B Visa Petitions for This Location
The H1B records below list the companies that have submitted the greatest number of H1B visa petitions for this location. This information was gathered directly from Department of Labor (DOL) records, which is the government agency responsible for all H1B submissions. Every quarter, DOL makes available a listing of all companies who have submitted H1B visa applications for the most recent 3 months for which records are available. The records contained in Going Global's H1B Plus database contains the most recent 12-month period of records available. Sort by Company | Petitions MASTECH, INC., A MASTECH HOLDINGS, 4339 INC. COMPANY MASTECH RESOURCING, INC. 1393 MASTECH ALLIANCE, INC., A MASTECH 1040 HOLDINGS COMPANY NESS USA, INC. 693 UNIVERSITY OF PITTSBURGH 169 UHCP D/B/A UPMC MEP 144 COGENT INFOTECH CORPORATION 131 SDLC MANAGEMENT, INC. 123 FIRST CONSULTING GROUP, LLC 104 ANSYS, INC. 100 COMPUTER ENTERPRISES, INC. 97 CARNEGIE MELLON UNIVERSITY 96 INTELLECT DESIGN ARENA INC. 95 ACCION LABS US, INC. 63 HM HEALTH SOLUTIONS INC. 57 UNIVERSITY OF PITTSBURGH PHYSICIANS 44 H.J. HEINZ COMPANY 40 CV CONSULTING INC 36 THE BANK OF NEW YORK MELLON 36 INFOYUGA TECHNOLOGIES, INC. 36 BAYER BUSINESS AND TECHNOLOGY 31 SERVICES, LLC UPMC EMERGENCY MEDICINE, INC. 28 GALAX-ESYSTEMS CORPORATION 26 HIGHMARK, INC. 25 SEVEN HILLS SOFTWARE TECHNOLOGIES 25 INC VELAGA ASSOCIATES, INC 24 UPMC PRESBYTERIAN SHADYSIDE 22 DVI TECHNOLOGES, INC. 21 ALLEGHENY CLINIC 20 GENCO I. INC. 17 SRI MOONLIGHT SOFTWARE SOLUTIONS 17 LLC BAYER MATERIALSCIENCE, LLC 16 BAYER HEALTHCARE PHARMACEUTICALS, 16 INC. VISVERO, INC. 16 CYBYTE, INC. 15 BOMBARDIER TRANSPORTATION 15 (HOLDINGS) USA, INC. -

ANSYS Advantage Thermal Managment
™ ADVANADVANTAGETAGE| | Excellence in Engineering Simulation VOLUME X ISSUE 1 2016 6 Beat the Heat 13 Cooling Trend 21 Hot Flash elcome to ANSYS Advantage! We hope you Realize Your Product Promise® enjoy these articles by ANSYS customers, ANSYS enables you to predict with confidence that your staff and partners. Want to be part of a products will thrive in the real world. Customers trust our future issue? Contact the editorial team solutions to help ensure the integrity of products and drive with your idea for an article. business success through innovation. Industry leaders use ANSYS to simulate complete virtual prototypes of complex WThe Editorial Staff, ANSYS Advantage products and systems — comprising mechanical, electronics [email protected] and embedded software components — that incorporate all the physical phenomena that exist in real-world environments. Executive & Editorial Adviser Managing Editor Tom Smithyman ANSYS, Inc. For ANSYS, Inc. sales information, Chris Reeves Southpointe call +1 844.GO ANSYS Editorial Contributor 2600 ANSYS Drive Email the editorial staff at Senior Editor ANSYS Customer Excellence Canonsburg, PA 15317 [email protected]. U.S.A. Tim Palucka North America For address changes, contact Subscribe at [email protected]. ansys.com/advantage Editors Art Directors Erik Ferguson Ron Santillo Kara Gremillion Dan Hart Neither ANSYS, Inc. nor DH4 Design guarantees or warrants accuracy or completeness of the material contained in this publication. Thomas Matich Gregg Weber ANSYS, ALinks, -

Previous Mechanical Engineering Industry Employers
The University of Iowa College of Engineering Professional Development Cooperative Education/Internship Program Previous Mechanical Engineering Industry Employers Company Name Location(s) 3M Various Accenture Chicago, IA AGCO Corp Park Jackson ALCAN, Inc. Des Moines, IA Alcoa Riverside, IA All Power Labs Berkeley, CA Alliant Energy Cedar Rapids, IA, Madison, WI Allsteel Muscatine, IA Amana Commercial Products Cedar Rapids, IA Amcor Rigid Plastics Manchester, MI American Ordnance Manchester, MI Andersen Corporation Des Moines, IA Ansys Canonsburg, PA Archer Daniels Midland Fremont, NE Associated Materials, Inc. Cedar Rapids, IA ASV Inventions Huntington Beach, CA AutoTruck Group Bartlett, IA Baker Group Des Moines, IA BASF Malcom, IA Bemis Company, Inc. Des Moines, IA Boeing Seattle, WA, Philadelphia, PA Boston Scientific Marlborough, MA BPC Group Orlando, FL Brooks Borg Skiles Architecture Engineering Des Moines, IA Burlington Northern Santa Fe Harre, MT Cadbury Loves Park, IL Cargill Various Case New Holland Industrial Burlington, IA Caterpillar Various CDW Government Chicago, IL Centro, Inc. North Liberty, IA Charles Industries, Ltd. Rantoul, IL Chicago Bridge & Iron Company Chicago, IL Citgo Lemont, IL CIVCO Medical Solutions Coralville, IA, Kalona, IA Clark, Richardson, and Biskup Consulting St. Louis, MO Clear Sign Seattle, WA Clifford Jacobs Forging Various Climco Coils, Inc. Morrison, IL Clipper Windpower Cedar Rapids, IA The University of Iowa College of Engineering Professional Development Cooperative Education/Internship Program -

Aa-Volume-Xv-Issue-1-2021.Pdf
EXCELLENCE IN ENGINEERING SIMULATION ISSUE 1 | 2021 4 12 23 America’s Cup: Volkswagen Refines ABB Speeds Analysis Sailing With Simulation Vehicle Designs with Twin Builder © 2021 ANSYS, INC. Ansys AdvantageCover1 “Ansys’ acquisition of AGI will help drive our strategy of making simulation pervasive from the smallest component now through a customer’s entire mission.” – Ajei Gopal, President and CEO of Ansys 2 Ansys Advantage Issue 1 / 2021 EDITORIAL Ansys, AGI Extend the Digital Thread Engineered products and systems can involve thousands of components, subsystems, systems and systems of systems that must work together intricately. Ansys software simulates all these pieces of the puzzle and their functional relationships to each other and, increasingly, to their environments. Anthony Dawson The success of a mission can is intended to achieve, and the Vice President & General hinge on the functionality of environment in which it must Manager, Ansys one component. Consider the achieve it. launch of a satellite; once in AGI realized that, too often, orbit, it cannot be recalled. For systems aren’t evaluated in missions like these, there are the full context of their mission has a long history of making no second chances. Simulation until physical prototypes sure that important cargo is critical throughout the entire are put into testing. Many gets where it needs to go. On systems engineering process to organizations may not even Christmas Eve, it continued its ensure that every component realize the extent to which this 23-year tradition of working with — whether part of the payload approach squanders time and the North American Aerospace design, launch system, satellite money, sometimes resulting Defense Command (NORAD) deployment, space propulsion in designs that can’t cooperate Operations Center on the annual system, astrodynamics or with their interdependent assets Santa Tracker experience, which onboard systems — will fulfill or perform adequately in their attracts more than 24 million the mission. -

Stoxx® Americas 1200 Technology Index
STOXX® AMERICAS 1200 TECHNOLOGY INDEX Components1 Company Supersector Country Weight (%) Apple Inc. Technology US 17.06 Microsoft Corp. Technology US 12.92 FACEBOOK CLASS A Technology US 8.28 ALPHABET CLASS C Technology US 6.77 Intel Corp. Technology US 4.84 Cisco Systems Inc. Technology US 4.74 International Business Machine Technology US 4.36 Oracle Corp. Technology US 3.95 Qualcomm Inc. Technology US 2.58 Texas Instruments Inc. Technology US 2.02 EMC Corp. Technology US 1.72 Salesforce.com Inc. Technology US 1.63 Adobe Systems Inc. Technology US 1.54 Cognizant Technology Solutions Technology US 1.17 Hewlett Packard Enterprise Technology US 1.07 Yahoo! Inc. Technology US 1.04 Intuit Inc. Technology US 0.90 Applied Materials Inc. Technology US 0.86 NVIDIA Corp. Technology US 0.81 Corning Inc. Technology US 0.77 HP Inc. Technology US 0.76 Analog Devices Inc. Technology US 0.56 Cerner Corp. Technology US 0.56 Red Hat Inc. Technology US 0.46 Symantec Corp. Technology US 0.44 Lam Research Corp. Technology US 0.43 Western Digital Corp. Technology US 0.42 Autodesk Inc. Technology US 0.41 Micron Technology Inc. Technology US 0.41 CGI GROUP 'A' Technology CA 0.41 SKYWORKS SLTN. Technology US 0.39 Xilinx Inc. Technology US 0.38 MOTOROLA SOLUTIONS INC. Technology US 0.38 SERVICENOW Technology US 0.37 PALO ALTO NETWORKS Technology US 0.36 Maxim Integrated Products Inc. Technology US 0.34 Check Point Software Technolog Technology US 0.34 Microchip Technology Inc. Technology US 0.34 CA Inc. -

Integrated Benefits Institute Member List January 2021 1230+ MEMBER ORGANIZATIONS
1901 Harrison Street, Suite 1100 Oakland California 94612 415-222-7280 www.ibiweb.org Integrated Benefits Institute Member List January 2021 1230+ MEMBER ORGANIZATIONS STAKEHOLDERS • AbbVie • Pfizer • Aflac • Prudential Financial, Inc. • AMGEN • Sedgwick • Anthem, Inc. • Standard Insurance • Aon • Sun Life Financial • Arthur J. Gallagher & Co. • Teladoc Health • Exact Sciences • The Guardian Life Insurance • Health Care Service Corporation Company of America/ReedGroup • Johnson & Johnson • The Hartford • Lincoln Financial Group • Trion-MMA • Lockton Companies • UnitedHealthcare • Mercer • UPMC WorkPartners • Novo Nordisk • Willis Towers Watson CHARTERS • AbleTo • New York Life • Alliant Insurance Services • PhRMA • Broadspire • Reliance Standard/Matrix Absence • ESIS Management • Merck • Walgreens • Metropolitan Life Insurance Company ASSOCIATES • Buck • Piper Jordan • Kaiser Permanente • Sera Prognostics • Pacific Resources Benefit Advisors, • Spring Consulting Group LLC • Voya Financial 1901 Harrison Street, Suite 1100 Oakland California 94612 415-222-7280 www.ibiweb.org AFFILIATES • Amazon Disability Leave Services • Heron Therapeutics • CoreHealth Technologies • Inspera Health • Curant Health • Mayo Clinic • EPIC (Edgewood Partners Insurance • Precision for Value Center) • Quantum Health • Erie Insurance Group • Sleepcharge by Nox Health • Evive Health • SWORD Health • Genentech, Inc. • Vida Health • GlaxoSmithKline • Wellthy • Headversity • Health Data & Management Solutions (HDMS) EMPLOYERS • Aleris • 24 Hour Fitness USA, Inc. • -

ANSYS ADVANTAGE 1 Table of Contents
Excellence in Engineering Simulation ISSUE 1 | 2017 SPOTLIGHT ON The DIGITAL TWIN 4 Double Vision Replicating product performance during operation 8 Creating a Digital Twin for a Pump Simulating an operating pump 14 Simulation for the Digital Twin Ecosystem Accurately predicting performance EDITORIAL A NEW ERA IN SIMULATION Combining real-time operational data from working products with digital information about those products enables the digital twin and promises to take simulation into a new era. For over 40 years, engineering simulation has helped engineering simulation to predict the product development teams around the world deliver future performance of that product game-changing innovations, accelerate product within its operating environment. This launches and reduce the costs associated with predictive capability could, for exam- design and development ple, optimize maintenance schedules While the process of creating highly engineered and reduce unplanned asset down- products has never been easy, today’s product devel- time, as well as significantly enhance opment organizations are faced with challenges that operational performance. could not have been imagined 40 years ago. Existing But digital twins have an even products are growing in complexity, with smart func- more important strategic benefit: tionality and more embedded software. Disruptive Product development teams can apply By Ajei Gopal, products are operating in design spaces that have not insights from the twin directly to President and CEO, been explored before. These products are expected their ongoing product development ANSYS to perform in more extreme physical conditions. efforts. Future versions of the product Consumers are demanding bigger and more frequent or process can be designed with new innovations that are delivered affordably.