Rebooting Virtual Memory with Midgard
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

User Office, Proposal Handling and Analysis Software
NOBUGS2002/031 October 11, 2002 Session Key: PB-1 User office, proposal handling and analysis software Jörn Beckmann, Jürgen Neuhaus Technische Universität München ZWE FRM-II D-85747 Garching, Germany [email protected] At FRM-II the installation of a user office software is under consideration, supporting tasks like proposal handling, beam time allocation, data handling and report creation. Although there are several software systems in use at major facilities, most of them are not portable to other institutes. In this paper the requirements for a modular and extendable user office software are discussed with focus on security related aspects like how to prevent a denial of service attack on fully automated systems. A suitable way seems to be the creation of a web based application using Apache as webserver, MySQL as database system and PHP as scripting language. PRESENTED AT NOBUGS 2002 Gaithersburg, MD, U.S.A, November 3-5, 2002 1 Requirements of user office software At FRM-II a user office will be set up to deal with all aspects of business with guest scientists. The main part is the handling and review of proposals, allocation of beam time, data storage and retrieval, collection of experimental reports and creation of statistical reports about facility usage. These requirements make off-site access to the user office software necessary, raising some security concerns which will be addressed in chapter 2. The proposal and beam time allocation process is planned in a way that scientists draw up a short description of the experiment including a review of the scientific background and the impact results from the planned experiment might have. -

Number Symbolism in Old Norse Literature
Háskóli Íslands Hugvísindasvið Medieval Icelandic Studies Number Symbolism in Old Norse Literature A Brief Study Ritgerð til MA-prófs í íslenskum miðaldafræðum Li Tang Kt.: 270988-5049 Leiðbeinandi: Torfi H. Tulinius September 2015 Acknowledgements I would like to thank firstly my supervisor, Torfi H. Tulinius for his confidence and counsels which have greatly encouraged my writing of this paper. Because of this confidence, I have been able to explore a domain almost unstudied which attracts me the most. Thanks to his counsels (such as his advice on the “Blóð-Egill” Episode in Knýtlinga saga and the reading of important references), my work has been able to find its way through the different numbers. My thanks also go to Haraldur Bernharðsson whose courses on Old Icelandic have been helpful to the translations in this paper and have become an unforgettable memory for me. I‟m indebted to Moritz as well for our interesting discussion about the translation of some paragraphs, and to Capucine and Luis for their meticulous reading. Any fault, however, is my own. Abstract It is generally agreed that some numbers such as three and nine which appear frequently in the two Eddas hold special significances in Norse mythology. Furthermore, numbers appearing in sagas not only denote factual quantity, but also stand for specific symbolic meanings. This tradition of number symbolism could be traced to Pythagorean thought and to St. Augustine‟s writings. But the result in Old Norse literature is its own system influenced both by Nordic beliefs and Christianity. This double influence complicates the intertextuality in the light of which the symbolic meanings of numbers should be interpreted. -

Norse Monstrosities in the Monstrous World of J.R.R. Tolkien
Norse Monstrosities in the Monstrous World of J.R.R. Tolkien Robin Veenman BA Thesis Tilburg University 18/06/2019 Supervisor: David Janssens Second reader: Sander Bax Abstract The work of J.R.R. Tolkien appears to resemble various aspects from Norse mythology and the Norse sagas. While many have researched these resemblances, few have done so specifically on the dark side of Tolkien’s work. Since Tolkien himself was fascinated with the dark side of literature and was of the opinion that monsters served an essential role within a story, I argue that both the monsters and Tolkien’s attraction to Norse mythology and sagas are essential phenomena within his work. Table of Contents Abstract Acknowledgements 3 Introduction 4 Chapter one: Tolkien’s Fascination with Norse mythology 7 1.1 Introduction 7 1.2 Humphrey Carpenter: Tolkien’s Biographer 8 1.3 Concrete Examples From Jakobsson and Shippey 9 1.4 St. Clair: an Overview 10 1.5 Kuseela’s Theory on Gandalf 11 1.6 Chapter Overview 12 Chapter two: The monsters Compared: Midgard vs Middle-earth 14 2.1 Introduction 14 2.2 Dragons 15 2.3 Dwarves 19 2.4 Orcs 23 2.5 Wargs 28 2.6 Wights 30 2.7 Trolls 34 2.8 Chapter Conclusion 38 Chapter three: The Meaning of Monsters 41 3.1 Introduction 41 3.2 The Dark Side of Literature 42 3.3 A Horrifically Human Fascination 43 3.4 Demonstrare: the Applicability of Monsters 49 3.5 Chapter Conclusion 53 Chapter four: The 20th Century and the Northern Warrior-Ethos in Middle-earth 55 4.1 Introduction 55 4.2 An Author of His Century 57 4.3 Norse Warrior-Ethos 60 4.4 Chapter Conclusion 63 Discussion 65 Conclusion 68 Bibliography 71 2 Acknowledgements First and foremost I have to thank the person who is evidently at the start of most thesis acknowledgements -for I could not have done this without him-: my supervisor. -

An Interdisciplinary Journal
FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISMFast Capitalism FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM ISSNFAST XXX-XXXX CAPITALISM FAST Volume 1 • Issue 1 • 2005 CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM -

A Saga of Odin, Frigg and Loki Pdf, Epub, Ebook
DARK GROWS THE SUN : A SAGA OF ODIN, FRIGG AND LOKI PDF, EPUB, EBOOK Matt Bishop | 322 pages | 03 May 2020 | Fensalir Publishing, LLC | 9780998678924 | English | none Dark Grows the Sun : A saga of Odin, Frigg and Loki PDF Book He is said to bring inspiration to poets and writers. A number of small images in silver or bronze, dating from the Viking age, have also been found in various parts of Scandinavia. They then mixed, preserved and fermented Kvasirs' blood with honey into a powerful magical mead that inspired poets, shamans and magicians. Royal Academy of Arts, London. Lerwick: Shetland Heritage Publications. She and Bor had three sons who became the Aesir Gods. Thor goes out, finds Hymir's best ox, and rips its head off. Born of nine maidens, all of whom were sisters, He is the handsome gold-toothed guardian of Bifrost, the rainbow bridge leading to Asgard, the home of the Gods, and thus the connection between body and soul. He came round to see her and entered her home without a weapon to show that he came in peace. They find themselves facing a massive castle in an open area. The reemerged fields grow without needing to be sown. Baldur was the most beautiful of the gods, and he was also gentle, fair, and wise. Sjofn is the goddess who inclines the heart to love. Freyja objects. Eventually the Gods became weary of war and began to talk of peace and hostages. There the surviving gods will meet, and the land will be fertile and green, and two humans will repopulate the world. -

Panel 4 the Creation of Midgard from Ymir the Giant
CREATING THE WORLD FROM YMIR By Mackenzie Stewart THE BEGINNING ‘In no way do we accept him as a god. He was evil, as are all his descendants; we call them frost giants. It is said that as he slept he took to sweating. Then, from under his left arm grew a male and female, while one of his legs got a son with the other. From here the clans that are called the frost giants. The old frost giant, him we call Ymir’ - Snorri Sturluson, The Prose Edda, 14-15 ‘where did Ymir live, and what did he live on?’ ‘Next what happened that as the icy rime dripped, the cow called Audhumla was formed. Four rivers of milk ran from her udders, and she nourished Ymir.’ - Snorri Sturluson, The Prose Edda, 15 ‘She licked the blocks of ice, which were salty. As she licked these stones of icy rime the first day, the hair of a man appeared in the blocks towards the evening. On the second day came the man’s head, and on the third day, the whole man. He was called Buri, and he was beautiful, big and strong. He had a son called Bor, who took as his wife the woman called Bestla. She was the daughter of Bolthorn the giant, and they had three sons. One was called Odin, another Vili and the third Ve.’ - Snorri Sturluson, The Prose Edda, 15 Ymir suckles the udder of Auðumbla as she licks Búri out of the ice painting by Nicolai Abildgaard, 1790 THE DEATH ‘The sons of Bor killed the giant Ymir’…’When he fell, so much blood gushed from his wounds that with it they drowned all the race of the frost giants except for one who escaped with his household. -
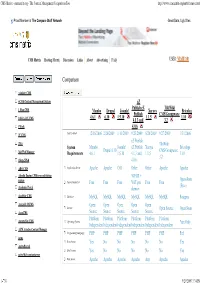
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache -

Using Wordpress to Manage Geocontent and Promote Regional Food Products
Farm2.0: Using Wordpress to Manage Geocontent and Promote Regional Food Products Amenity Applewhite Farm2.0: Using Wordpress to Manage Geocontent and Promote Regional Food Products Dissertation supervised by Ricardo Quirós PhD Dept. Lenguajes y Sistemas Informaticos Universitat Jaume I, Castellón, Spain Co-supervised by Werner Kuhn, PhD Institute for Geoinformatics Westfälische Wilhelms-Universität, Münster, Germany Miguel Neto, PhD Instituto Superior de Estatística e Gestão da Informação Universidade Nova de Lisboa, Lisbon, Portugal March 2009 Farm2.0: Using Wordpress to Manage Geocontent and Promote Regional Food Products Abstract Recent innovations in geospatial technology have dramatically increased the utility and ubiquity of cartographic interfaces and spatially-referenced content on the web. Capitalizing on these developments, the Farm2.0 system demonstrates an approach to manage user-generated geocontent pertaining to European protected designation of origin (PDO) food products. Wordpress, a popular open-source publishing platform, supplies the framework for a geographic content management system, or GeoCMS, to promote PDO products in the Spanish province of Valencia. The Wordpress platform is modified through a suite of plug-ins and customizations to create an extensible application that could be easily deployed in other regions and administrated cooperatively by distributed regulatory councils. Content, either regional recipes or map locations for vendors and farms, is available for syndication as a GeoRSS feed and aggregated with outside feeds in a dynamic web map. To Dad, Thanks for being 2TUF: MTLI 4 EVA. Acknowledgements Without encouragement from Dr. Emilio Camahort, I never would have had the confidence to ensure my thesis handled the topics I was most passionate about studying - sustainable agriculture and web mapping. -

UC Irvine UC Irvine Previously Published Works
UC Irvine UC Irvine Previously Published Works Title Dimethyl Fumarate Alleviates Dextran Sulfate Sodium-Induced Colitis, through the Activation of Nrf2-Mediated Antioxidant and Anti-inflammatory Pathways. Permalink https://escholarship.org/uc/item/7n185057 Journal Antioxidants (Basel, Switzerland), 9(4) ISSN 2076-3921 Authors Li, Shiri Takasu, Chie Lau, Hien et al. Publication Date 2020-04-24 DOI 10.3390/antiox9040354 Peer reviewed eScholarship.org Powered by the California Digital Library University of California antioxidants Article Dimethyl Fumarate Alleviates Dextran Sulfate Sodium-Induced Colitis, through the Activation of Nrf2-Mediated Antioxidant and Anti-nflammatory Pathways Shiri Li 1, Chie Takasu 1 , Hien Lau 1, Lourdes Robles 1, Kelly Vo 1, Ted Farzaneh 2, Nosratola D. Vaziri 3, Michael J. Stamos 1 and Hirohito Ichii 1,* 1 Department of Surgery, University of California, Irvine, CA 92868, USA; [email protected] (S.L.); [email protected] (C.T.); [email protected] (H.L.); [email protected] (L.R.); [email protected] (K.V.); [email protected] (M.J.S.) 2 Department of Pathology, University of California, Irvine, CA 92868, USA; [email protected] 3 Department of Medicine, University of California, Irvine, CA 92868, USA; [email protected] * Correspondence: [email protected]; Tel.: +1-714-456-8590; Fax: +1-714-456-8796 Received: 14 March 2020; Accepted: 22 April 2020; Published: 24 April 2020 Abstract: Oxidative stress and chronic inflammation play critical roles in the pathogenesis of ulcerative colitis (UC) and inflammatory bowel diseases (IBD). A previous study has demonstrated that dimethyl fumarate (DMF) protects mice from dextran sulfate sodium (DSS)-induced colitis via its potential antioxidant capacity, and by inhibiting the activation of the NOD-, LRR- and pyrin domain-containing protein 3 (NLRP3) inflammasome. -

Campaign Setting
TM Campaign Setting Lead Designer Wolfgang Baur Chapter Design Cover Art Jeff Grubb, Brandon Hodge, Christina Stiles, and Dan Voyce Aaron Miller Additional Design Interior Art Ben Armitage, Michael Franke, Ed Greenwood,Josh Jarman, Darren Calvert, Nicole Cardiff, Richard Clark, Storn Cook, Michael Kortes, Chris Lozaga, Michael Matkin, Ben McFarland, Emile Denis, Rick Hershey, Michael Jaecks, Stephanie Law, Chad Middleton, Carlos Ovalle, Adam Roy, and Henry Wong Pat Loboyko, Malcolm McClinton, Aaron Miller, Marc Radle, Game Material Development Blanca Martinez de Rituerto, Mark Smylie, Hugo Solis, Sigfried Trent Christophe Swal, Stephen Wood, and Kieran Yanner AGE Appendix Cartography and Heraldry Josh Jarman, with additional design by Simon English, Jonathan Roberts, Sean Macdonald, Lucas Haley Emmet Byrne, Daniel Perez, Jesse Butler, and Wolfgang Baur Cover Graphic Design Editor Callie Winters Michele Carter Layout Proofreading Callie Winters Chris Harris, Ed Possing, and Joey Smith Indexer Lori Ann Curley Dedication: This book is dedicated to my parents, Werner and Renate Baur, who many years ago gave me a little blue box with a dragon on the cover. Thank you for always supporting my love of fantasy, gaming, and legends. Setting Champions Champion of Midgard: Steve Geddes Despot of the Ruby Sea: Carlos Ovalle Exarch of the Magocracy: Christopher Lozaga Druid of the Emerald Order: Shawn “Bran Ravensong” Nolan God-King of Nuria-Natal: Henry Wong Lord of Thunder Mountain: DJ Yoho Lord of Midgard: Sebastian Dietz River King of the Arbonesse: Chad Middleton Sultana of the Empire: Christina Stiles Midgard Campaign Setting is © 2012 Open Design LLC. All rights reserved. Midgard, Open Design, Kobold Press, Free City of Zobeck, and their associated logos are trademarks of Open Design LLC. -

Yggdrasil: Asgard Rulebook
All the base rules for Yggdrasil still apply when playing with this expansion except for the transe and Hel’s effect. In renouncing my divinity, My brothers’ power grew mightily. For, by the magic of the Sejdr, Trance These worlds and I are now bound. In a selfless act of sacrifice, a God can enter a trance to increase all of the other Gods’ power. This expansion adds a new action in addition to the original nine. For one action, the active God can enter or leave a trance. Simply turn the God sheet over to the other side (normal or trance). The active God cannot enter and leave a trance during the same turn. Trance As long as a God is in a trance, • he and all the Gods get a new power: the Trance Power of the God under the trance. The Trance Power can be used by any of the Gods, including the one under the trance. However • This God under a trance loses his Personal Power and • the God under a trance cannot perform an action in Asgard, i.e., the God under a trance cannot attack one of the six enemies. Personal Power Trance Power el The Viking counters that Hel removes from the H bags are not placed on the World of the Dead any more, but are permanently discarded. The Gods cannot use them again during the game. At the beginning of his turn, Odin draws 2 When they play on the Ice Fortress and Enemy cards instead of one, chooses which defeat a Giant, the Gods discard the Giant one he wants to play and puts the other one of their choice, one who is active or one odin back on or under the deck. -

Open Source Katalog 2009 – Seite 1
Optaros Open Source Katalog 2009 – Seite 1 OPEN SOURCE KATALOG 2009 350 Produkte/Projekte für den Unternehmenseinsatz OPTAROS WHITE PAPER Applikationsentwicklung Assembly Portal BI Komponenten Frameworks Rules Engine SOA Web Services Programmiersprachen ECM Entwicklungs- und Testumgebungen Open Source VoIP CRM Frameworks eCommerce BI Infrastrukturlösungen Programmiersprachen ETL Integration Office-Anwendungen Geschäftsanwendungen ERP Sicherheit CMS Knowledge Management DMS ESB © Copyright 2008. Optaros Open Source Katalog 2009 - Seite 2 Optaros Referenz-Projekte als Beispiele für Open Source-Einsatz im Unternehmen Kunde Projektbeschreibung Technologien Intranet-Plattform zur Automatisierung der •JBossAS Geschäftsprozesse rund um „Information Systems •JBossSeam Compliance“ •jQuery Integrationsplattform und –architektur NesOA als • Mule Enterprise Bindeglied zwischen Vertriebs-/Service-Kanälen und Service Bus den Waren- und Logistiksystemen •JBossMiddleware stack •JBossMessaging CRM-Anwendung mit Fokus auf Sales-Force- •SugarCRM Automation Online-Community für die Entwickler rund um die •AlfrescoECM Endeca-Search-Software; breit angelegtes •Liferay Enterprise Portal mit Selbstbedienungs-, •Wordpress Kommunikations- und Diskussions-Funktionalitäten Swisscom Labs: Online-Plattform für die •AlfrescoWCMS Bereitstellung von zukünftigen Produkten (Beta), •Spring, JSF zwecks Markt- und Early-Adopter-Feedback •Nagios eGovernment-Plattform zur Speicherung und •AlfrescoECM Zurverfügungstellung von Verwaltungs- • Spring, Hibernate Dokumenten; integriert