Soatopicindex - QVIZ
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

User Office, Proposal Handling and Analysis Software
NOBUGS2002/031 October 11, 2002 Session Key: PB-1 User office, proposal handling and analysis software Jörn Beckmann, Jürgen Neuhaus Technische Universität München ZWE FRM-II D-85747 Garching, Germany [email protected] At FRM-II the installation of a user office software is under consideration, supporting tasks like proposal handling, beam time allocation, data handling and report creation. Although there are several software systems in use at major facilities, most of them are not portable to other institutes. In this paper the requirements for a modular and extendable user office software are discussed with focus on security related aspects like how to prevent a denial of service attack on fully automated systems. A suitable way seems to be the creation of a web based application using Apache as webserver, MySQL as database system and PHP as scripting language. PRESENTED AT NOBUGS 2002 Gaithersburg, MD, U.S.A, November 3-5, 2002 1 Requirements of user office software At FRM-II a user office will be set up to deal with all aspects of business with guest scientists. The main part is the handling and review of proposals, allocation of beam time, data storage and retrieval, collection of experimental reports and creation of statistical reports about facility usage. These requirements make off-site access to the user office software necessary, raising some security concerns which will be addressed in chapter 2. The proposal and beam time allocation process is planned in a way that scientists draw up a short description of the experiment including a review of the scientific background and the impact results from the planned experiment might have. -

Xwiki Enterprise 8.4.4 Developer Guide - Xwiki Rendering Macros in Java Xwiki Enterprise 8.4.4 Developer Guide - Xwiki Rendering Macros in Java
XWiki Enterprise 8.4.4 Developer Guide - XWiki Rendering Macros in Java XWiki Enterprise 8.4.4 Developer Guide - XWiki Rendering Macros in Java Table of Contents Page 2 XWiki Enterprise 8.4.4 Developer Guide - XWiki Rendering Macros in Java • XWiki Rendering Macros in Java • Box Macro • Cache Macro • Chart Macro • Children Macro • Code Macro • Comment Macro • Container Macro • Content Macro • Context Macro • Dashboard Macro • Display Macro • Document Tree Macro • Error Message Macro • Footnote Macro • Formula Macro • Gallery Macro • Groovy Macro • HTML Macro • ID Macro • Include Macro • Information Message Macro • Office Macro • Put Footnotes Macro • Python Macro • RSS Macro • Script Macro • Success Macro Message • Table of Contents Macro • Translation Macro • User Avatar Java Macro • Velocity Macro • Warning Message Macro XWiki Rendering Macros in Java Overview XWiki Rendering Macros in Java are created using the XWiki Rendering architecture and Java. In order to implement a Java macro you will need to write 2 classes: • One that representing the allowed parameters, including mandatory parameters, default values, parameter descriptions. An instance of this class will be automatically populated when the user calls the macro in wiki syntax. • Another one that is the macro itself and implements the Macro interface. The XWiki Rendering Architecture can be summarized by the image below: The Parser parses a text input like "xwiki/2.0" syntax or HTML and generates an XDOM object. This object is an Abstract Syntax Tree which represents the input into structured blocks. The Renderer takes an XDOM as input and generates an output like "xwiki/2.0" syntax, XHTML or PDF. The Transformation takes an XDOM as input and generates a modified one. -

An Interdisciplinary Journal
FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISMFast Capitalism FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM ISSNFAST XXX-XXXX CAPITALISM FAST Volume 1 • Issue 1 • 2005 CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM FAST CAPITA LISM FAST CAPITALISM FAST CAPITALISM FAST CAPITALISM -

Wikis in Libraries Matthew M
Wikis in Libraries Matthew M. Bejune Wikis have recently been adopted to support a variety of a type of Web site that allows the visitors to add, collaborative activities within libraries. This article and remove, edit, and change some content, typically with out the need for registration. It also allows for linking its companion wiki, LibraryWikis (http://librarywikis. among any number of pages. This ease of interaction pbwiki.com/), seek to document the phenomenon of wikis and operation makes a wiki an effective tool for mass in libraries. This subject is considered within the frame- collaborative authoring. work of computer-supported cooperative work (CSCW). Wikis have been around since the mid1990s, though it The author identified thirty-three library wikis and is only recently that they have become ubiquitous. In 1995, Ward Cunningham launched the first wiki, WikiWikiWeb developed a classification schema with four categories: (1) (http://c2.com/cgi/wiki), which is still active today, to collaboration among libraries (45.7 percent); (2) collabo- facilitate the exchange of ideas among computer program ration among library staff (31.4 percent); (3) collabora- mers (Wikipedia 2007b). The launch of WikiWikiWeb was tion among library staff and patrons (14.3 percent); and a departure from the existing model of Web communica tion ,where there was a clear divide between authors and (4) collaboration among patrons (8.6 percent). Examples readers. WikiWikiWeb elevated the status of readers, if of library wikis are presented within the article, as is a they so chose, to that of content writers and editors. This discussion for why wikis are primarily utilized within model proved popular, and the wiki technology used on categories I and II and not within categories III and IV. -

JSON Application Programming Interface for Discrete Event Simulation Data Exchange
JSON Application Programming Interface for Discrete Event Simulation data exchange Ioannis Papagiannopoulos Enterprise Research Centre Faculty of Science and Engineering Design and Manufacturing Technology University of Limerick Submitted to the University of Limerick for the degree of Master of Engineering 2015 1. Supervisor: Prof. Cathal Heavey Enterprise Research Centre University of Limerick Ireland ii Abstract This research is conducted as part of a project that has the overall aim to develop an open source discrete event simulation (DES) platform that is expandable, and modular aiming to support the use of DES at multi-levels of manufacturing com- panies. The current work focuses on DES data exchange within this platform. The goal of this thesis is to develop a DES exchange interface between three different modules: (i) ManPy an open source discrete event simulation engine developed in Python on the SimPy library; (ii) A Knowledge Extraction (KE) tool used to populate the ManPy simulation engine from shop-floor data stored within an Enterprise Requirements Planning (ERP) or a Manufacturing Execution System (MES) to allow the potential for real-time simulation. The development of the tool is based on R scripting language, and different Python libraries; (iii) A Graphical User Interface (GUI) developed in JavaScript used to provide an interface in a similar manner to Commercial off-the-shelf (COTS) DES tools. In the literature review the main standards that could be used are reviewed. Based on this review and the requirements above, the data exchange format standard JavaScript Object Notation (JSON) was selected. The proposed solution accom- plishes interoperability between different modules using an open source, expand- able, and easy to adopt and maintain, in an all inclusive JSON file. -

Tutoriel Docker Documentation Release 0.1.0 (2018-03-09)
Tutoriel Docker Documentation Release 0.1.0 (2018-03-09) id3 Technologies 2020-9-14 12:6 Contents 1 Introduction à Docker 2 1.1 Pourquoi utiliser docker ?......................................3 1.1.1 Transformation de la DSI des entreprises..........................3 1.1.2 Pour donner davantage d’autonomie aux développeurs..................4 1.1.3 Faire évoluer son système d’information..........................4 1.1.4 Pour que ça fonctionne aussi sur une autre machine....................5 1.1.5 Livre blanc Ubuntu.....................................5 1.2 Définitions concernant l’agilité et le mouvement Devops ......................5 1.2.1 Définition de Devops p.34 Programmez! p.214 janvier 2018...............5 1.2.2 Définition 2, Le Devops pour répondre à l’appel de l’innovation 2018-01-04.......5 1.2.3 Définition 3, extrait p.53 MISC N95, Janvier/février, 2018, “Ne pas prévoir, c’est déjà gémir” ...........................................6 1.2.3.1 Citations......................................6 1.2.3.1.1 Ne pas prévoir, c’est déjà gémir.....................6 1.2.3.1.2 La vie, c’est comme une bicyclette, il faut avancer pour ne pas perdre l’équilibre................................6 1.2.4 Devops, intégration et déploiement continus, pourquoi est-ce capital et comment y aller ?6 1.2.5 Agilité et Devops: Extrait p. 35 de [Programmez!] , N°214, janvier 2018........7 1.2.6 What is a DevOps Engineer ?................................8 1.3 Définitions concernant Docker....................................8 1.3.1 Définition de Docker sur Wikipedia en français......................8 1.3.2 Docker est “agile”......................................9 1.3.3 Docker est portable..................................... 10 1.3.4 Docker est sécurisé.................................... -

Guide to Open Source Solutions
White paper ___________________________ Guide to open source solutions “Guide to open source by Smile ” Page 2 PREAMBLE SMILE Smile is a company of engineers specialising in the implementing of open source solutions OM and the integrating of systems relying on open source. Smile is member of APRIL, the C . association for the promotion and defence of free software, Alliance Libre, PLOSS, and PLOSS RA, which are regional cluster associations of free software companies. OSS Smile has 600 throughout the World which makes it the largest company in Europe - specialising in open source. Since approximately 2000, Smile has been actively supervising developments in technology which enables it to discover the most promising open source products, to qualify and assess them so as to offer its clients the most accomplished, robust and sustainable products. SMILE . This approach has led to a range of white papers covering various fields of application: Content management (2004), portals (2005), business intelligence (2006), PHP frameworks (2007), virtualisation (2007), and electronic document management (2008), as well as PGIs/ERPs (2008). Among the works published in 2009, we would also cite “open source VPN’s”, “Firewall open source flow control”, and “Middleware”, within the framework of the WWW “System and Infrastructure” collection. Each of these works presents a selection of best open source solutions for the domain in question, their respective qualities as well as operational feedback. As open source solutions continue to acquire new domains, Smile will be there to help its clients benefit from these in a risk-free way. Smile is present in the European IT landscape as the integration architect of choice to support the largest companies in the adoption of the best open source solutions. -

Standardisation and Organisation of Clinical Data and Disease Mechanisms for Comparison Over Heterogeneous Systems in the Context of Neurodegenerative Diseases
PhD-FSTC-2018-51 The Faculty of Sciences, Technology and Communication DISSERTATION Defence held on 03/07/2018 in Luxembourg to obtain the degree of DOCTEUR DE L’UNIVERSITÉ DU LUXEMBOURG EN BIOLOGIE by AISHWARYA ALEX NAMASIVAYAM Born on 12 November 1987 in Bharananganam (India) STANDARDISATION AND ORGANISATION OF CLINICAL DATA AND DISEASE MECHANISMS FOR COMPARISON OVER HETEROGENEOUS SYSTEMS IN THE CONTEXT OF NEURODEGENERATIVE DISEASES Dissertation defence committee Prof. Dr Reinhard Schneider, dissertation supervisor Professor, Université du Luxembourg Dr Inna Kuperstein Researcher and scientific coordinator, Institut Curie, Paris Dr Enrico Glaab, Chairman Senior research scientist, Université du Luxembourg Prof. Dr Karsten Hiller Professor, Technische Universität Braunschweig Dr Marek Ostaszewski, Vice Chairman Research associate, Université du Luxembourg Affidavit I hereby confirm that the PhD thesis entitled "Standardisation and Organisation of Clinical Data and Disease Mechanisms for Comparison Over Heterogeneous Systems in the Context of Neurodegenerative Diseases" has been written independently and without any other sources than cited. Luxembourg, July 26, 2018 Aishwarya Alex Namasivayam i ii Acknowledgements First and foremost, I would like to thank Dr. Reinhard Schneider, my supervisor for giving me the opportunity and support to pursue my PhD in the group. Biocore is a very wonderful working environment. I couldnt ask for a better boss! I would like to thank all my colleagues for their support and making this a memorable journey. Special thanks to Marek, Venkata, Wei and Piotr for their valuable suggestions and feedbacks. My sincere gratitude to Dr. Jochen Schneider and Dr. Karsten Hiller for agreeing to be part of the CET committee and the constructive criticism during the PhD. -
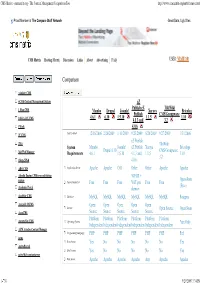
CMS Matrix - Cmsmatrix.Org - the Content Management Comparison Tool
CMS Matrix - cmsmatrix.org - The Content Management Comparison Tool http://www.cmsmatrix.org/matrix/cms-matrix Proud Member of The Compare Stuff Network Great Data, Ugly Sites CMS Matrix Hosting Matrix Discussion Links About Advertising FAQ USER: VISITOR Compare Search Return to Matrix Comparison <sitekit> CMS +CMS Content Management System eZ Publish eZ TikiWiki 1 Man CMS Mambo Drupal Joomla! Xaraya Bricolage Publish CMS/Groupware 4.6.1 6.10 1.5.10 1.1.5 1.10 1024 AJAX CMS 4.1.3 and 3.2 1Work 4.0.6 2F CMS Last Updated 12/16/2006 2/26/2009 1/11/2009 9/23/2009 8/20/2009 9/27/2009 1/31/2006 eZ Publish 2flex TikiWiki System Mambo Joomla! eZ Publish Xaraya Bricolage Drupal 6.10 CMS/Groupware 360 Web Manager Requirements 4.6.1 1.5.10 4.1.3 and 1.1.5 1.10 3.2 4Steps2Web 4.0.6 ABO.CMS Application Server Apache Apache CGI Other Other Apache Apache Absolut Engine CMS/news publishing 30EUR + system Open-Source Approximate Cost Free Free Free VAT per Free Free (Free) Academic Portal domain AccelSite CMS Database MySQL MySQL MySQL MySQL MySQL MySQL Postgres Accessify WCMS Open Open Open Open Open License Open Source Open Source AccuCMS Source Source Source Source Source Platform Platform Platform Platform Platform Platform Accura Site CMS Operating System *nix Only Independent Independent Independent Independent Independent Independent ACM Ariadne Content Manager Programming Language PHP PHP PHP PHP PHP PHP Perl acms Root Access Yes No No No No No Yes ActivePortail Shell Access Yes No No No No No Yes activeWeb contentserver Web Server Apache Apache -

Tripwire Connect 3.0.1 Installation Guide
Appendix I. Third-Party License Agreements The Apache Software License, Version 2.0 This product includes software licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. Apache Batik Copyright 1999-2007 The Apache Software Foundation This product includes software developed at The Apache Software Foundation (http://www.apache.org/). This software contains code from the World Wide Web Consortium (W3C) for the Document Object Model API (DOM API) and SVG Document Type Definition (DTD). This software contains code from the International Organisation for Standardization for the definition of character entities used in the software's documentation. This product includes images from the Tango Desktop Project (http://tango.freedesktop.org/). This product includes images from the Pasodoble Icon Theme (http://www.jesusda.com/projects/pasodoble). AntiSamy Copyright (c) 2007-2012, Arshan Dabirsiaghi, Jason Li All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: - Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. - Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. -

Wikis in Companies
CONSULTING WIKIS IN COMPANIES Collect, use and expand your knowledge. /WIKI HOW COMPANIES CAN BENEFIT FROM EVERY EMPLOYEE’S KNOWLEDGE WHY DO COMPANIES NEED WIKIS? Your intranet contains lots of information – but just how quickly can your employees find this information? And how quickly can they modify data? How much time do they spend dealing with e-mail messages popping up, and how efficient is their preparation for meetings and projects? How uncomplicated can new employees access important process knowledge? How much know-how at your company is unstructured or even unmapped? “IN 2009, IT IS PREDICTED THAT AT LEAST 50% OF ALL COMPANIES WILL BE UTILIZING Many intranets lack editorial dynamism and “up-to-dateness”. Information can sometimes become outdated extremely quickly, partially because employees – due to lacking aesthetics or complicated administration procedures – do not participate. The daily flood of e-mail WIKIS AS A VITAL INSTRUMENT is also inefficient and is an obstacle for companies: Often enough, information goes missing, or employees are confronted with information that is irrelevant. In addition, information becomes spread about, stored unused in mailboxes and various databanks that may be accessed only FOR COLLABORATION.” by a few employees. This inefficient form of communication and know-how management slows down companies, WILL YOU BE ONE OF THEM? leads to knowledge loss, and wastes resources. This is why companies need wikis. A wiki allows professional, systematic and uncomplicated knowledge management; it also allows Society for Information Management’s Advanced Practices employees to communicate actively and efficiently regarding the topics of the day. With a wiki, the entire know-how of a company can be mapped, actively used, and organically expanded. -

Architecture of a P2P Distributed Adaptive Directory
Architecture of a P2P Distributed Adaptive Directory Gennaro Cordasco Vittorio Scarano Cristiano Vitolo [email protected] [email protected] [email protected] Dipartimento di Informatica e Applicazioni “R.M.Capocelli” Universit`a di Salerno, 84081 Baronissi (SA) – Italy Categories and Subject Descriptors C.2.4 [Distributed Systems]: Distributed Applications; H.3.4 [Systems and Software]: Distributed Systems; H.5.4 [Hypertext/Hypermedia]: Navigation General Terms Design Keywords Adaptivity, Bookmark sharing, Peer to Peer 1. INTRODUCTION Bookmarks are, nowadays, an important aid to navigation since they represent an easy way to reduce the cognitive load of man- aging and typing URLs. All the browsers have always provided, since the very beginning of the WWW, friendly ways of managing bookmarks. In this paper we deal with the problem of enriching this Figure 1: The diagram of the architecture of our system. supportive framework for bookmarks (as provided by the browsers) The middle layer, named DAD, exploits the bottom level to ob- by adding collaboration and (group) adaptation with a P2P system. tain information about bookmarks and users, providing a collabora- In this paper, we describe a system that offers a distributed, co- tive and adaptive system to manage bookmarks. Shared bookmarks operative and adaptive environment for bookmark sharing. DAD are placed in an ontology that is common to all the peers and the (Distributed Adaptive Directory) offers an adaptive environment adaptivity provided by the system is based on a modified applica- since it provides suggestions about the navigation based on (a) the tion of the Kleinberg algorithm to evaluate hub and authorities on a bookmarks, (b) the feedback implicitly provided by users and (c) web structure.