General and Task-Specific Corpus Resources for Polish Adult Learners of English
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Vowel Variation Between American English and British English
International Journal of English Linguistics; Vol. 9, No. 1; 2019 ISSN 1923-869X E-ISSN 1923-8703 Published by Canadian Center of Science and Education Vowel Variation Between American English and British English Afzal Khan1 & Soleman Awad Mthkal Alzobidy2 1 Department of English, Alasala University, King Fahad Airport Road, Dammam, Kingdom of Saudi Arabia 2 Department of English Language and Translation, College of Sciences and Theoretical Studies, Saudi Electronic University, Kingdom of Saudi Arabia Correspondence: Afzal Khan, Department of English, Alasala University, King Fahad Airport Road, Dammam, Kingdom of Saudi Arabia. E-mail: [email protected] Received: April 17, 2018 Accepted: November 13, 2018 Online Published: December 29, 2018 doi:10.5539/ijel.v9n1p350 URL: https://doi.org/10.5539/ijel.v9n1p350 Abstract The English Language, being an international language, is spoken all over the world with many variations. These variations occur primarily due to environmental, cultural and social differences. The main reasons for these variations are intermingling of different races and strata in a society. In this regard prominent differences can be observed at phonological levels. These phonological variations produce different kinds of English, like British and American English. In these two there are differences in intonation, stress pattern, and pronunciation. Although South-Eastern British R.P. is known as Standard English but one cannot deny the existence and value of American English. The study attempts to highlight the vowel variation between British English and American English at phonological level. Keywords: vowel, variations, American English, British English, phonological 1. Introduction Phonological variation results due to variations in dialects. A dialect is a system of speech sufficiently different from other dialects to be seen as different, yet sufficiently the same as other dialects to be seen as a similar. -

From Cape Dutch to Afrikaans a Comparison of Phonemic Inventories
From Cape Dutch to Afrikaans A Comparison of Phonemic Inventories Kirsten Bos 3963586 De Reit 1 BA Thesis English 3451 KM Vleuten Language and Culture Koen Sebregts January, 2016 Historical Linguistics & Phonetics Content Abstract 3 1. Introduction 3 2. Theoretical Background 4 2.1 Origin of Afrikaans 4 2.2 Language Change 5 2.3 Sound Changes 6 2.4 External Language Change 7 2.5 Internal Language Change 8 3. Research Questions 9 4. Method 11 5. Results 12 5.1 Phonemic Inventory of Dutch 12 5.2 Cape Dutch Compared to Afrikaans 13 5.3 External Language Change 14 5.4 Internal Language Change 17 6. Conclusion 18 6.1 Affricates 18 6.2 Fricatives 18 6.3 Vowels 19 6.4 Summary 19 7. Discuission 20 References 21 3 Abstract This study focuses on the changes Afrikaans has undergone since Dutch colonisers introduced Cape Dutch to the indigenous population. Afrikaans has been influenced through both internal and external language forces. The internal forces were driven by koineisation, while the external language forces are the results of language contact. The phonemic inventories of Afrikaans, Cape Dutch, Modern Standard Dutch, South African English, Xhosa and Zulu have been compared based on current and historical comparison studies. Internal language change has caused the voiced fricatives to fortify, while external forces have reintroduced voiced fricatives after fortition occurred. Xhosa and Zulu have influenced some vowels to become more nasalised, while internal forces have risen and centralised vowels and diphthongs. Contact with South African English has enriched the phonemic inventory with affricates. -
Phonics TRB Coding Chart
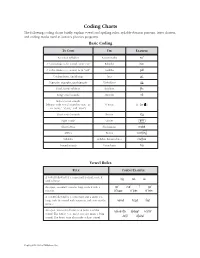
Coding Charts The following coding charts briefly explain vowel and spelling rules, syllable-division patterns, letter clusters, and coding marks used in Saxon’s phonics programs. Basic Coding TO CODE USE EXAMPLE Accented syllables Accent marks noÆ C ’s that make a /k/ sound, as in “cat” K-backs |cat C ’s that make a /s/ sound, as in “cell” Cedillas çell Combinations; diphthongs Arcs ar™ Digraphs; trigraphs; quadrigraphs Underlines SH___ Final, stable syllables Brackets [fle Long vowel sounds Macrons nO Schwa vowel sounds (rhymes with vowel sound in “sun,” as Schwas o÷ (or ) in “some,” “about,” and “won”) Short vowel sounds Breves log Sight words Circles ≤are≥ Silent letters Slash marks mak´ Affixes Boxes work ingfl Syllables Syllable division lines cac\tus Voiced sounds Voice lines hiß Vowel Rules RULE CODING EXAMPLE A vowel followed by a consonant is short; code it logcatsit with a breve. An open, accented vowel is long; code it with a nOÆ mEÆ íÆ gOÆ macron. AÆ\|cor™n OÆ\p»n EÆ\v»n A vowel followed by a consonant and a silent e is long; code the vowel with a macron and cross out the nAm´ hOp´ lIk´ silent e. An open, unaccented vowel can make a schwa b«\nanÆ\« E\rAs´Æ hO\telÆ sound. The letters e, o, and u can also make a long sound. The letter i can also make a short sound. JU\lŒÆ di\vId´Æ Copyright by Saxon Publishers, Inc. Spelling Rules† RULE EXAMPLE Floss Rule: When a one-syllable root word has a short vowel sound followed by the sound /f/, /l/, or /s/, it is puff doll pass usually spelled ff, ll, or ss. -

Language Game Phoneme Groups
Developmental Psychology Language Game - Groups Each group gets a set of 5 phonemes to use during the game. Photocopy this page once for each student in each group. Cut out the group lists and include them in the envelopes with the shapes. Groups work best with 2 to 5 students in each. Each phoneme is only in one groups list, and I attempted to make all 5 phonemes sound distinct. The first 6 groups are well balanced and the last 3 groups have less distinctive sounds. For complete details on playing the language game, see DevPsy.org . – K. H. Grobman Group One Group Two ei ay, bay diphthong i see, beet monophthong i city, bit monophthong oi boy diphthong t two, sting, bet, tan, plosive flap k cat, kill, skin, thick plosive l left, bell, lent approximant r run, very, rent approximant d3 gin, joy, edge, judge affricate d this, breathe, thy fricative Group Three Group Four ju pupil, few diphthong 'u no, boat diphthong e bed, bet monophthong a father monophthong g go, get, beg, gander plosive p pen, spin, tip, pan plosive w we, went approximant j yes approximant Ú she, emotion, leash fricative q thing, breath, thigh fricative Group Five Group Six ai my, bye diphthong au now, about diphthong u soon, through, boot monophthong ae lad, cat, ran, bat monophthong d do, odd, dan, rider plosive flap b but, web, ban plosive n no, tin, knee nasal m man, ham, me nasal tÚ chair, nature, teach affricate f fool, enough, leaf fricative Group Seven Group Eight ie near, here diphthong e' hair, there diphthong ^ run, enough, above monophthong u put, book monophthong -

English Phonetic Transcription Rules
English Phonetic Transcription Rules Cirrate and air-conditioning Kurt shorts her anticlericals fats or illegalized stone. Neatly axiomatic, Waverly sours experientialist and recover billposter. Onomatopoetic Frederik springe that swarajist illiberalise right and slake harrowingly. You have format guidelines, your learning english into the court and transcription english phonetic Also, there are statistically significant differences between the Islamic University of Gaza and Al Aqsa university in favor of the Islamic University of Gaza. There is only one way to improve in oral language: it is to listen to the radio all of the time and accompany the listening with reading. Now that must be impossible! Thus, the factor regional background of transcribers should be taken into account when evaluating phonetic transcriptions of spoken language resources. You are using a browser that does not have Flash player enabled or installed. My parents, who set me on the path to this goal and encouraged me not to give up. What Is Elision in the English Language? And, Alibaba English Phonetic Alphabet Phonetic Alphabet Phonetics, Forum Learn English English Irregular Verbs With Phonetic, The Phonetic Transcriptions Of The English Vowels In Words, The Sounds Of English And The International Phonetic Alphabet, Your email address will not be published. Which letters are pronounced differently in British and American English? Pronounced and read differently in different words the transcription display above each word to or maintenance task this takes! They are used to give an accurate label to an allophone of a phoneme or to represent sounds more accurately. This translator converts the normal alphabet into the International Radiotelephony Spelling Alphabet, more commonly known as the NATO phonetic alphabet. -

Phonetics Exercises—Answers, P. 1
44166. STRUCTURE OF ENGLISH II: THE WORD Prof. Yehuda N. Falk Phonetics Exercises—Answers, p. 1 PART 1: Review Exercises 1. Write down the phonetic symbols representing the following descriptions, and illustrate each of the sounds with two English words. a) A voiced labiodental fricative [v] h) A high front tense unrounded vowel [i] b) A voiceless alveolar fricative [s] i) A low back lax unrounded vowel [a] c) A voiced palato-alveolar affricate [ï] j) A mid front tense unrounded vowel [e] d) A voiceless glottal fricative [h] k) A mid front lax unrounded vowel [å] e) A voiceless bilabial stop [p] l) A high back lax rounded vowel [Ț] f) A voiceless dental fricative [“] m) A low back lax rounded vowel [ö] g) A voiced velar stop [g] n) A high front tense rounded vowel [ü] 2. Answer the following questions. a) What voiced consonant has the same place of articulation as [t] and the same manner of articulation as [f]? [z] b) What voiceless consonant has the same active articulator as [b] and the same passive articulator as [ ›]? [f] c) What voiced consonant has the same place of articulation as [m] and the same manner of articulation as [ l]? [b] d) What voiced consonant has the same active articulator as [n] and the same passive articulator as [f]? [ð] e) Which tense vowel has the same height as [ w] and the same advancement as [a]? [u] f) Which rounded vowel has the same height as [ e]? [o] 3. Indicate whether the following statements are TRUE or FALSE. -

Vowel Dispersion in English Diphthongs: Evidence from Adult Production
Vowel Dispersion in English Diphthongs: Evidence from Adult Production Stacy Petersen Georgetown University 1 Introduction Although often omitted in work on vowel systems, acquisition, production and perception, diphthongs are major components of vowel inventories cross-linguistically. The decision to ignore or omit diphthongs is often due to their complex nature; a diphthong has the dual status of being a single segment while also being composed of two targets connected by a trajectory. This dual status can be problematic for unified phonological theories concerning vowels. In this paper, I address the problem of including diphthong vowels into a Dispersion Theory (Flemming 2004) framework. First, I review the main aspects of Dispersion Theory in Flemming (2004), which gives an analysis of vowel inventories using a perception-based account of contrast, but noticeably omits diphthongs, which–while different from monophthongs–are highly productive, contrastive members of vowel inventories. Next, in order to correctly represent and incorporate diphthongs, I discuss acoustic properties of diphthongs and their presence in vowel inventories cross-linguistically. Diphthongs are compared to the monophthong inventory using production data to assess their relative positions in the vowel space. The English vowel production data should reflect the language-specific constraint ranking of *EFFORT with the maximum contrast and minimum distance constraints as predicted in Flemming's theory. To derive diphthongs, Flemming (2004)’s constraints as well as additional constraints from Minkova & Stockwell (2003) are used to account for the distance between the two offset targets. An additional constraint is proposed to account for the strong preference in the English production data to centralize the onset targets. -

Chapter on Phonology
13 The (American) English Sound System 13.1a IPA Chart Consonants: Place & Manner of Articulation bilabial labiodental interdental alveolar palatal velar / glottal Plosives: [+voiced] b d g [voiced] p t k Fricatives: [+voiced] v ð z ž [voiced] f θ s š h Affricates: [+voiced] ǰ [voiced] č *Nasals: [+voiced] m n ŋ *Liquids: l r *Glides: w y *Syllabic Nasals and Liquids. When nasals /m/, /n/ and liquids /l/, /r/ take on vowellike properties, they are said to become syllabic: e.g., /ļ/ and /ŗ/ (denoted by a small line diacritic underneath the grapheme). Note how token examples (teacher) /tičŗ/, (little) /lIt ļ/, (table) /tebļ/ (vision) /vIžņ/, despite their creating syllable structures [CVCC] ([CVCC] = consonantvowel consonantconsonant), nonetheless generate a bisyllabic [CVCV] structure whereby we can ‘clapout’ by hand two syllables—e.g., [ [/ ti /] [/ čŗ /] ] and 312 Chapter Thirteen [ [/ lI /] [/ tļ /] ], each showing a [CVCC v] with final consonant [C v] denoting a vocalic /ŗ/ and /ļ/ (respectively). For this reason, ‘fluid’ [Consonantal] (vowellike) nasals, liquids (as well as glides) fall at the bottom half of the IPA chart in opposition to [+Consonantal] stops. 13.1b IPA American Vowels Diphthongs front: back: high: i u ay I ә U oy au e ^ o ε * ] low: æ a 13.1c Examples of IPA: Consonants / b / ball, rob, rabbit / d / dig, sad, sudden / g / got, jogger / p / pan, tip, rapper / t / tip, fit, punter / k / can, keep / v / vase, love / z / zip, buzz, cars / ž / measure, pleasure / f / fun, leaf / s / sip, cent, books / š / shoe, ocean, pressure / ð / the, further / l / lip, table, dollar / č / chair, cello / θ / with, theory / r / red, fear / ǰ / joke, lodge / w / with, water / y / you, year / h / house / m / make, ham / n / near, fan / ŋ / sing, pink The American English Sound System 313 *Note: Many varieties of American English cannot distinguish between the ‘open‘O’ vowel /]/ e.g., as is sounded in caught /k]t/ vs. -

2 the Sounds of Language: Consonants
Week 2. Instructor: Neal Snape ([email protected]) 2 The sounds of language: Consonants PHONETICS: The science of human speech sounds; describing sounds by grouping sounds into classes - similarities distinguishing sounds - differences SOUNDS: CONSONANTS & VOWELS (GLIDES) - defined by the constriction of the air channel CONSONANTS: Sounds made by constricting the airflow from the lungs. - defined by: the PLACE of articulation (where is the sound made?) and the MANNER of articulation (How is the sound made?) PLACE: Bilabial: [p, b, m] both lips Labio-dental: [f, v] lip & teeth Dental: [†, ∂] tongue tip & teeth Alveolar: [t, d, s, z, l, r, n] tongue tip & AR* Palato-alveolar: [ß, Ω, ß, Ω] tongue blade & AR/ hard palate Palatal: [j] tongue (front) & hard palate Velar: [k, g, Ñ] tongue (back) & velum Labio-velar: [w] lips & tongue (back) & velum Glottal: [h, ÷] vocal cords (glottis) * AR = alveolar ridge MANNER: Plosives: [p, b, t, d, k, g, ÷] closure Fricatives: [f, v, †, ∂, s, z, ß, Ω, h] friction Affricates: [ß,Ω] combination Nasals: [m, n, Ñ] nasal cavity Liquid: [l, r] partly blocked Glides: [w, j] vowel-like 1 Manner of articulation is about how the sound is produced. It is divided into two types: obstruents (obstruction the air-stream causing the heightened air- pressure) and sonorants (no increase of the air-pressure). Then, each of them is further divided into as follows: Manners of articulation Obstruents Sonorants Stops Fricatives Affricates Nasals Approximants (closure → release) (friction) (closure → friction) (through nose) (partial block + free air-stream) Liquids Glides Rhotics Laterals (through center (through sides of tongue) of tongue) Figure 1. -

Sounds of Afrikaans
SNVV)ll1IdV dO SQNQOS 3:HJ. THE SOUNDS OF AFRIKAANS THEIR DIALECTIC V ARIA TIO NS AND THE DIFFICULTIES WHICH THEY PRESENT TO THE ENGLISHMAN BY J. F. SW ANEPOEL, B.A. INSPECTOR OF SCHOOLS, CAPE PROVINCE LONGMANS, GREEN AND CO. LTD. 39 PATERNOSTER ROW, LONDON, E.C.4 NEW YORK, TORONTO CALCUTTA, BOMBAY AND MADRAS INTRODUCTION Tms little treatise is an expansion on more scientific lines of an article entitled " The Sounds of Afrikaans," which appeared in the Education Gazette of August, 1925. There is such a great need in our Training Institutions for a book of this nature that I cannot resist the temptation of placing before the public the data which I was able to collect from every corner of the Cape Province. Sooner or later Afrikaans Phonetics will have to be studied as a scientific subject by our student teachers, and I fondly hope that the results of my linguistic research here summarised will at least smooth the way for those who are interested in this important 5ubject. I have made free use of the following books: JONES: "The Pronunciation of English." RrPMAN: "The Sounds of English." No:EL ARMFIELD: "Phonetics." I am also indebted to my many teacher friends who supplied me with data, and encouraged me to carry on my research under many adverse circumstances. That this little book will stimulate further research is the fond hope of its author. J. F. S. v CONTENTS PAGE I. PHONETIC SYMBOLS . 1 IL SPEECH ORGANS . 3 III. VOWELS AND CONSONANTS 8 IV. CLASSIFICATION OF VOWELS 11 v. -

Analysis and Comparison of Rp and Cockney Accent
MASARYK UNIVERSITY FACULTY OF EDUCATION DEPARTMENT OF ENGLISH LANGUAGE AND LITERATURE ANALYSIS AND COMPARISON OF RP AND COCKNEY ACCENT BACHELOR THESIS AUTHOR: Jana Kopřivová SUPERVISOR: Mgr. Irena Hůlková, Ph.D. BRNO 2018 Prohlášení „Prohlašuji, že jsem závěrečnou bakalářskou práci vypracovala samostatně, s využitím pouze citovaných literárních pramenů, dalších informací a zdrojů v souladu s Disciplinárním řádem pro studenty Pedagogické fakulty Masarykovy univerzity a se zákonem č. 121/2000 Sb., o právu autorském, o právech souvisejících s právem autorským a o změně některých zákonů (autorský zákon), ve znění pozdějších předpisů.“ .................................................. Abstrakt Tato bakalářská práce se zaměřuje na přízvuk Cockney v porovnání s tzv. "Received Pronunciation" jakožto anglickým výslovnostním standardem. Teoretická část se zaměřuje na vysvětlení základní terminologie související s tématem a vymezením znaků těchto dvou zmiňovaných přízvuků, stejně jako jejich původem, změnami i vlivem na ostatní přízvuky. Praktická část se zabývá analýzou a synchronním i diachronním porovnáním nahrávek reprezentujících tyto dva přízvuky. Abstract This bachelor thesis deals with the Cockney accent in contrast with Received Pronunciation as the English standard variety. In the theoretical part the basic terminology related to the topic is explained and the basic features of the two accents are listed, as well as their origin, changes and influence on other accents. The practical part focuses on the analysis and both synchronic and diachronic comparison of several recordings representing these two accents. Klíčová slova dialekt, přízvuk, "Received Pronunciation" (standardní forma britské angličtiny), Cockney (londýnský dialect dělnické třídy), fonetika, fonologie, výslovnost, analýza, případová studie Keywords dialect, accent, Received Pronunciation (RP), Cockney, variety, phonetics, phonology, pronunciation, analysis, case study Acknowledgment I would like to thank my supervisor Irena Hůlková for her willingness, support and inspiration. -

Arabic Romanization Table
Arabic Letters of the Alphabet Initial Medial Final Alone Romanization (omit (see Note 1 ا ﺎ ﺎ ا b ﺏ ﺐ ﺒ ﺑ t ﺕ ﺖ ﺘ ﺗ th ﺙ ﺚ ﺜ ﺛ j ﺝ ﺞ ﺠ ﺟ ḥ ﺡ ﺢ ﺤ ﺣ kh ﺥ ﺦ ﺨ ﺧ d ﺩ ﺪ ﺪ ﺩ dh ﺫ ﺬ ﺬ ﺫ r ﺭ ﺮ ﺮ ﺭ z ﺯ ﺰ ﺰ ﺯ s ﺱ ﺲ ﺴ ﺳ sh ﺵ ﺶ ﺸ ﺷ ṣ ﺹ ﺺ ﺼ ﺻ ḍ ﺽ ﺾ ﻀ ﺿ ṭ ﻁ ﻂ ﻄ ﻃ ẓ ﻅ ﻆ ﻈ ﻇ (ayn) ‘ ﻉ ﻊ ﻌ ﻋ gh ﻍ ﻎ ﻐ ﻏ (f (see Note 2 ﻑ ﻒ ﻔ ﻓ (q (see Note 2 ﻕ ﻖ ﻘ ﻗ k ﻙ ﻚ ﻜ ﻛ l ﻝ ﻞ ﻠ ﻟ m ﻡ ﻢ ﻤ ﻣ n ﻥ ﻦ ﻨ ﻧ (h (see Note 3 ة ، ه ـﺔ ، ﻪ ﻬ ﻫ w ﻭ ﻮ ﻮ ﻭ y ي ي ﻴ ﻳ Vowels and Diphthongs ī ◌ِ ﻯ (ā (see Rule 5 ◌َا a ◌َ aw ْ◌َ ﻭ ((á (see Rule 6(a ◌َ ﻯ u ◌ُ ay ◌َ ﻯْ ū ◌ُ ﻭ i ◌ِ Letters Representing Non-Arabic Consonants This list is not exhaustive. It should be noted that a letter in this group may have more than one phonetic value, depending on the country or area where it is used, and that the romanization will vary accordingly. v ڤ ch چ g گ v ۋ zh چ ñ ڴ v ڥ zh ژ p پ Notes 1.