Digging Into HTTPS: Flow-Based Classification of Webmail Traffic
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Understanding Post Office Protocol (POP3)
Understanding Post Office Protocol (POP3) Author: Conrad Chung, 2BrightSparks Introduction Most Internet users with email accounts would have used some form of “client” software (Outlook, Thunderbird etc.) to access and manage their email at one point or another. To retrieve emails, these email clients may require the configuration of Post Office Protocol (or POP3) before messages can be downloaded from the server. This article will help readers understand what POP3 is and how it works. What is Post Office Protocol? The Post Office Protocol (POP3) is an Internet standard protocol used by local email software clients to retrieve emails from a remote mail server over a TCP/IP connection. Since the first version was created in 1984, the Post Office Protocol (currently at Version 3) has since became one of the most popular protocols and is used by virtually every email client to date. Its popularity lies in the protocol’s simplicity to configure, operate and maintain. Email servers hosted by Internet service providers also use POP3 to receive and hold emails intended for their subscribers. Periodically, these subscribers will use email client software to check their mailbox on the remote server and download any emails addressed to them. Once the email client has downloaded the emails, they are usually deleted from the server, although some email clients allow users to specify that mails be copied or saved on the server for a period of time. Email clients generally use the well-known TCP port 110 to connect to a POP3 server. If encrypted communication is supported on the POP3 server, users can optionally choose to connect either by using the STLS command after the protocol initiation stage or by using POP3S, which can use the Transport Layer Security (TLS) or Secure Sockets Layer (SSL) on TCP port 995 to connect to the server. -

Imail V12 Web Client Help
Ipswitch, Inc. Web: www.imailserver.com 753 Broad Street Phone: 706-312-3535 Suite 200 Fax: 706-868-8655 Augusta, GA 30901-5518 Copyrights ©2011 Ipswitch, Inc. All rights reserved. IMail Server – Web Client Help This manual, as well as the software described in it, is furnished under license and may be used or copied only in accordance with the terms of such license. Except as permitted by such license, no part of this publication may be reproduced, photocopied, stored on a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, recording, or otherwise, without the expressed prior written consent of Ipswitch, Inc. The content of this manual is furnished for informational use only, is subject to change without notice, and should not be construed as a commitment by Ipswitch, Inc. While every effort has been made to assure the accuracy of the information contained herein, Ipswitch, Inc. assumes no responsibility for errors or omissions. Ipswitch, Inc. also assumes no liability for damages resulting from the use of the information contained in this document. Ipswitch Collaboration Suite (ICS), the Ipswitch Collaboration Suite (ICS) logo, IMail, the IMail logo, WhatsUp, the WhatsUp logo, WS_FTP, the WS_FTP logos, Ipswitch Instant Messaging (IM), the Ipswitch Instant Messaging (IM) logo, Ipswitch, and the Ipswitch logo are trademarks of Ipswitch, Inc. Other products and their brands or company names are or may be trademarks or registered trademarks, and are the property of their respective companies. Update History December 2011 v12 April 2011 v11.5 October 2010 v11.03 May 2010 v11.02 Contents CHAPTER 1 Introduction to IMail Web Client About Ipswitch Web Messaging Help .................................................................................................................. -
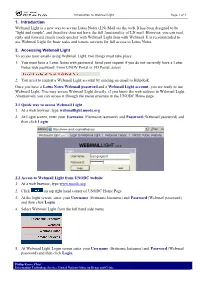
1. Introduction Webmail Light Is a New Way to Access Lotus Notes (LN) Mail Via the Web
Introduction to Webmail Light Page 1 of 2 1. Introduction Webmail Light is a new way to access Lotus Notes (LN) Mail via the web. It has been designed to be "light and simple", and therefore does not have the full functionality of LN mail. However, you can read, reply and forward emails much quicker with Webmail Light than with Webmail. It is recommended to use Webmail Light for basic tasks and remote services for full access to Lotus Notes. 2. Accessing Webmail Light To access your emails using Webmail Light, two things must take place: 1. You must have a Lotus Notes web password. Send your request if you do not currently have a Lotus Notes web password. From UNOV Portal or FO Portal, select 2. You need to request a Webmail Light account by sending an email to Helpdesk. Once you have a Lotus Notes Webmail password and a Webmail Light account, you are ready to use Webmail Light. You may access Webmail Light directly, if you know the web address to Webmail Light. Alternatively you can access it through the menu structure in the UNODC Home page. 2.1 Quick way to access Webmail Light 1. At a web browser, type webmaillight.unodc.org 2. At Login screen, enter your Username (firstname.lastname) and Password (Webmail password) and then click Login. 2.2 Access to Webmail Light from UNODC website 1. At a web browser, type www.unodc.org 2. Click on top right hand corner of UNODC Home Page. 3. At the login screen, enter your Username (firstname.lastname) and Password (Webmail password) and then click Login. -

You Can Configure Microsoft Outlook to Access Your Office 365 Account by Setting up an Exchange Connection
You can configure Microsoft Outlook to access your Office 365 account by setting up an Exchange connection. An Exchange connection provides access your email, calendar, contacts, and tasks in Outlook. You can also set up Outlook to access your email by using IMAP. However, if you use IMAP you can only access your email from Outlook, not your calendar, contacts, and tasks. Notes: ▪ Office 365 is designed to work with any version of Microsoft Office in mainstream support. Get Outlook for Windows Outlook is included with Microsoft Office 365. Faculty and staff with a Thiel ID and undergraduate students with an Office 365 account can download Microsoft Office for Windows via webmail for free. Please visit the Solution Center webpage for more information. Configure Outlook for Windows 1. Open Outlook. 2. At the Welcome screen, click Next. 3. When asked if you want to set up Outlook to connect to an email account, select Yes and then click Next. 4. The Auto Account Setup wizard opens. Enter your name, your email address using your ID#@thiel.edu, and your Thiel ID network password. Then, click Next 5. Outlook will complete the setup for your account, which might take several minutes. When you are notified that your account was successfully configured, click Finish. 6. You may need to restart Outlook for the changes to take effect. Change offline access setting You can use Outlook on your laptop or desktop computer when you’re not connected to the Internet. Email, calendar, and other items are kept in an Outlook data file on your computer so you can work offline. -
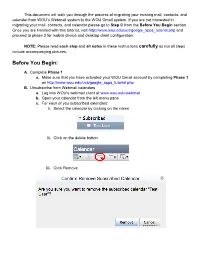
Before You Begin
This document will walk you through the process of migrating your existing mail, contacts, and calendar from WOU’s Webmail system to the WOU Gmail system. If you are not interested in migrating your mail, contacts, and calendar please go to Step C from the Before You Begin section. Once you are finished with this tutorial, visit http://www.wou.edu/ucs/google_apps_tutorial.php and proceed to phase 3 for mobile device and desktop client configuration. NOTE: Please read each step and all notes in these instructions carefully as not all steps include accompanying pictures. Before You Begin: A. Complete Phase 1 a. Make sure that you have activated your WOU Gmail account by completing Phase 1 on http://www.wou.edu/ucs/google_apps_tutorial.php B. Unsubscribe from Webmail calendars a. Log into WOU’s webmail client at www.wou.edu/webmail b. Open your calendar from the left menu pane c. For each of you subscribed calendars: i. Select the calendar by clicking on the name ii. Click on the delete button iii. Click Remove C. Setting up your Gmail account a. Log into your Gmail account at http://gmail.mail.wou.edu b. Click on Settings in the upper right-hand corner of the screen c. Click on the Accounts tab d. Click on Add another email address you own e. Enter your name and WOU email address and click Next Step f. Click Send Notification g. Return to your inbox h. You should have an email with the subject “Western Oregon University Confirmation - Send Mail as [email protected].” If you do not see this email, wait 2 minutes and refresh your inbox. -

Email Transfer from Webmail to Gmail
Email Transfer from Webmail to Gmail Product: Google Mail Symptom: Transfer Webmail to Gmail Solution: Transfer Webmail to Gmail Footprints Public Solution #70834 In Your Oakland University Email Account 1. Click the gear in the top right corner then click Settings from the dropdown menu 2. Select Forwarding and POP/IMAP tab and then Enable POP for all mail (even mail that has already been downloaded) 3. Click Save Changes at the bottom of the screen Setting up 2-Step Verification and App Specific Password 1. Click on the circle with a letter in the top right corner and click My Account 2. Click Sign-in & security 3. Scroll down and click 2-Step Verification 4. Click Get Started 5. Type in your phone number and choose if you would like to receive a text or a phone call 6. You will need to input the code you received and click Next 7. You will the need to click Turn On to enable 2-Step Verification 8. Click the back arrow to go back to the Sign-in & security settings 9. Scroll down and click App passwords 10. Click Select Device and then choose Other (Custom name) 11. Name the device gmail then click Generate 12. A password will be generated. Copy the password, you will use it later In Your New Gmail Account 1. Click the gear in the top right corner then click Settings 2. Select the Accounts and Import tab then click Add a mail account 3. Type in your Oakland University email address in the popup window then click Next 4. -
Setting up Webmail for Microsoft Outlook Express
Setting up WebMail for Microsoft Outlook Express Windows 2000/XP 1. Start your Microsoft Outlook Express program. 2. Left click the Tools menu and click on Accounts. 3. In the Accounts window click the Mail tab located at the top of the window. 4. Click the Add button on the right and select Mail. 5. Enter your name into the field. This is how your name will appear to others when you send them an email. Click Next. 6. Enter your @csustan.edu email address and click Next. 7. Select from the drop down menu that your incoming mail server is a IMAP server. Then enter in the following information and then click Next: a. Incoming mail server: asherah.csustan.edu b. Outgoing mail server: asherah.csustan.edu NOTE: If you are setting this up off campus you will need to use your ISP’s (Internet Service Provider) outgoing server information and settings. 8. Your account name should appear in the field, if it does not enter your login name. e.g. [email protected] has a login name of just jamesk. The login EXCLUDES the @csustan.edu. You may enter your password if you do not want outlook to ask for your password every time you start up outlook express. Click Next, and then click Finish to complete the setup. Then click Close to exit the accounts window. 9. Outlook express will ask if you would like to download the folders from the server. Select yes to view the folders available and then Click OK. 10. Your email is delivered to the Inbox located under asherah.csustan.edu. -

Table of Contents Preferences Calendar Frequently Asked Questions
table of contents table of contents internet Product Overview .......................................................................................................................... I-1 Advanced Services ........................................................................................................................ I-2 WOW! Email ........................................................................................................................................I-3 How to Register Your WOW! Internet Account ........................................................ I-3 table of contents Using Multiple Email Accounts ...................................................................................... I-4 Composing and Sending Emails ................................................................................... I-4 Address Book ...................................................................................................................... I-6 Calendar ................................................................................................................................ I-7 Preferences .......................................................................................................................... I-8 Troubleshooting ............................................................................................................................. I-9 Minimum System Requirements ............................................................................................. I-9 Frequently Asked Questions ................................................................................................. -

Office365) May Be Used to Keep Track of Email from Other Accounts by Setting up a Connection to Other Email Services
Importing (POP) Webmail into @MyHunter Overview: Your new @MyHunter (Office365) may be used to keep track of email from other accounts by setting up a connection to other email services. You can connect up to five other accounts, such as your previous Hunter email account (Hunter Webmail), Gmail, Yahoo! Mail, etc., therefore you can configure your @MyHunter account to import all your email from your previous Hunter Webmail email account into your new @MyHunter account! The following instructions will guide you on how to set up your @MyHunter account to get all you email from your old Hunter Webmail account to your new @MyHunter email account by setting up POP, which is a method to retrieve your mail messages stored on the email server, and then download the messages to your computer. The most important part to remember only emails residing in your Hunter Webmail Inbox will be downloaded to your computer. If you created multiple folders in your old Hunter Webmail (as displayed by the image below), you will have two options to get the email stored into those sub-folders over into your @MyHunter email account: Sub- folders A. Move all the email messages in these additional sub-folders into your Inbox folder and POP (or import) all your email at once. Be advised, you will lose the organization of your sub-folders, but this method requires very little effort. B. Or, move all the email messages in each sub-folder in your Hunter Webmail one folder at a time, refresh your @MyHunter email account, then move those messages from the inbox to the same folders (which you have manually created), in your @MyHunter email account. -

Webmail User Guide
Webmail 7.0 is an online email client which runs in your web browser. Webmail 7.0 allows you to access your email, contact list, and calendar from any computer with an internet connection and a web browser. Contents 1 Overview .............................................................................................................................................. 4 1.1 Understanding the Webmail Interface .............................................................................................. 5 1.1.1 Account Drop-down .............................................................................................................. 5 1.1.2 Primary Menu ........................................................................................................................ 6 1.1.3 Secondary Menu ................................................................................................................... 7 2 Inbox ..................................................................................................................................................... 8 2.1 Inbox Layout ....................................................................................................................................... 8 2.1.1 Mail Folders ........................................................................................................................... 8 2.2 Managing Email ................................................................................................................................ 12 2.2.1 Displaying Email -

Mail Services Easy-To-Manage Internet Mail Solutions Featuring Best-In-Class Open Source Technologies
Mail Services Easy-to-manage Internet mail solutions featuring best-in-class open source technologies. Features Mac OS X Server combines the most robust technologies from the open source community to deliver comprehensive, easy-to-use mail server solutions. Full Enterprise-class mail server support for Internet mail protocols—Internet Message Access Protocol (IMAP), • High-performance Postfix SMTP services Post Office Protocol (POP), and Simple Mail Transfer Protocol (SMTP)—ensures • Scalable Cyrus IMAP and POP services • Support for over 100,000 mail accounts compatibility with standards-based mail clients on Mac, Windows, and Linux with no per-user licensing fees systems. With support for thousands of users per server and no per-user licensing • Virtual host support for multiple domains fees, these high-performance mail services offer significant cost savings for small • Flexible mail storage and per-user quotas organizations and large enterprises alike. Strong authentication and security Core mail services in Mac OS X Server use the high-speed Postfix server for SMTP • SSL/TLS encryption for secure transport of messaging and the scalable Cyrus mailbox server for accessing mail accounts via SMTP, POP, and IMAP mail POP and IMAP. Flexible mail storage makes it easy to scale the mail server to meet • Flexible authentication methods, including growing needs, and high-performance indexing ensures continued responsiveness Kerberos, CRAM-MD5, and APOP to client actions. To guard your network mail services against unauthorized access • Support for secure single sign-on for Mac or abuse, Mac OS X Server version 10.4 builds in strong authentication, SSL/TLS and Windows clients encryption, adaptive junk mail filtering using SpamAssassin, and virus detection Protection against junk mail and viruses using ClamAV. -

GEARY 0.8 Geary 0.8 Email Should Be As Simple As Possible, but No Simpler
REVIEWS GEARY 0.8 Geary 0.8 Email should be as simple as possible, but no simpler. Ben Everard finds out which side this new email client sits on. n computing terms, email is ancient. It pre-dates DATA the web. It pre-dates the internet, and in some form, it even pre-dates Arpanet. It’s become Web I https://wiki.gnome.org/ ubiquitous and something that computer users Apps/Geary expect to ‘just work’ on any computer. Developer Linux has its fair share of email clients, from the Yorba terminal-based Mutt to the all-singing-all-dancing Licence Thunderbird. However, what it didn’t have until recently LGPL was an email client focused on ease of use. This is the niche that Geary is now trying to fill. Despite failing to reach the $100,000 target on Geary’s conversations view helps you follow the flow of its crowdfunding campaign (and therefore getting messages, but it can get unwieldy with large emails. nothing) in April 2013, Yorba – the development team behind Geary – have continued to develop the let’s look at the features. Well, the biggest new feature software albeit at a slower pace than we would have in version 0.8 is signatures. Yep, those bits of text that otherwise expected. It has just reached version 0.8. you add to the bottom of the email. They’ve only just The design philosophy is probably best summed landed in version 0.8, so that should give you an idea up by the preferences dialog. It contains a mere about the level of completeness.