Primepcr™Assay Validation Report
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplementary Table 1: Adhesion Genes Data Set
Supplementary Table 1: Adhesion genes data set PROBE Entrez Gene ID Celera Gene ID Gene_Symbol Gene_Name 160832 1 hCG201364.3 A1BG alpha-1-B glycoprotein 223658 1 hCG201364.3 A1BG alpha-1-B glycoprotein 212988 102 hCG40040.3 ADAM10 ADAM metallopeptidase domain 10 133411 4185 hCG28232.2 ADAM11 ADAM metallopeptidase domain 11 110695 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 195222 8038 hCG40937.4 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 165344 8751 hCG20021.3 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 189065 6868 null ADAM17 ADAM metallopeptidase domain 17 (tumor necrosis factor, alpha, converting enzyme) 108119 8728 hCG15398.4 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 117763 8748 hCG20675.3 ADAM20 ADAM metallopeptidase domain 20 126448 8747 hCG1785634.2 ADAM21 ADAM metallopeptidase domain 21 208981 8747 hCG1785634.2|hCG2042897 ADAM21 ADAM metallopeptidase domain 21 180903 53616 hCG17212.4 ADAM22 ADAM metallopeptidase domain 22 177272 8745 hCG1811623.1 ADAM23 ADAM metallopeptidase domain 23 102384 10863 hCG1818505.1 ADAM28 ADAM metallopeptidase domain 28 119968 11086 hCG1786734.2 ADAM29 ADAM metallopeptidase domain 29 205542 11085 hCG1997196.1 ADAM30 ADAM metallopeptidase domain 30 148417 80332 hCG39255.4 ADAM33 ADAM metallopeptidase domain 33 140492 8756 hCG1789002.2 ADAM7 ADAM metallopeptidase domain 7 122603 101 hCG1816947.1 ADAM8 ADAM metallopeptidase domain 8 183965 8754 hCG1996391 ADAM9 ADAM metallopeptidase domain 9 (meltrin gamma) 129974 27299 hCG15447.3 ADAMDEC1 ADAM-like, -

Independent Centromere Formation in a Capricious, Gene-Free Domain of Chromosome 13Q21 in Old World Monkeys and Pigs
Open Access Research2006CardoneetVolume al. 7, Issue 10, Article R91 Independent centromere formation in a capricious, gene-free comment domain of chromosome 13q21 in Old World monkeys and pigs Maria Francesca Cardone*, Alicia Alonso†, Michele Pazienza*, Mario Ventura*, Gabriella Montemurro*, Lucia Carbone*, Pieter J de Jong‡, Roscoe Stanyon§, Pietro D'Addabbo*, Nicoletta Archidiacono*, Xinwei She¶, Evan E Eichler¶, Peter E Warburton† and Mariano Rocchi* reviews Addresses: *Department of Genetics and Microbiology, University of Bari, Bari, Italy. †Department of Human Genetics, Mount Sinai School of Medicine, New York, New York 10029, USA. ‡Children's Hospital Oakland Research Institute, Oakland, California 94609, USA. §Department of Animal Biology and Genetics 'Leo Pardi', University of Florence, Florence, Italy. ¶Howard Hughes Medical Institute, Department of Genome Sciences, University of Washington School of Medicine, Seattle, Washington 98195, USA. Correspondence: Mariano Rocchi. Email: [email protected] Published: 13 October 2006 Received: 3 May 2006 reports Revised: 31 July 2006 Genome Biology 2006, 7:R91 (doi:10.1186/gb-2006-7-10-r91) Accepted: 13 October 2006 The electronic version of this article is the complete one and can be found online at http://genomebiology.com/2006/7/10/R91 © 2006 Cardone et al.; licensee BioMed Central Ltd. This is an open access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which deposited research permits unrestricted -

Multipoint Genome-Wide Linkage Scan for Nonword Repetition in a Multigenerational Family Further Supports Chromosome 13Q As a Locus for Verbal Trait Disorders D
Marshall University Marshall Digital Scholar Biochemistry and Microbiology Faculty Research 12-2016 Multipoint genome-wide linkage scan for nonword repetition in a multigenerational family further supports chromosome 13q as a locus for verbal trait disorders D. T. Truong L. D. Shriberg S. D. Smith K. L. Chapman A. R. Scheer-Cohen See next page for additional authors Follow this and additional works at: https://mds.marshall.edu/sm_bm Part of the Behavioral Medicine Commons, Genetic Phenomena Commons, Genetic Processes Commons, Genetic Structures Commons, and the Speech Pathology and Audiology Commons Recommended Citation Truong DT, Shriberg LD, Smith SD, Chapman KL, Scheer-Cohen AR, DeMille MMC, et al. Multipoint genome-wide linkage scan for nonword repetition in a multigenerational family further supports chromosome 13q as a locus for verbal trait disorders. Hum Genet. 2016;135(12):1329-41. This Article is brought to you for free and open access by the Faculty Research at Marshall Digital Scholar. It has been accepted for inclusion in Biochemistry and Microbiology by an authorized administrator of Marshall Digital Scholar. For more information, please contact [email protected], [email protected]. Authors D. T. Truong, L. D. Shriberg, S. D. Smith, K. L. Chapman, A. R. Scheer-Cohen, M. M.C. DeMille, A. K. Adams, Alejandro Q. Nato Jr., E. M. Wijsman, J. D. Eicher, and J. R. Gruen This article is available at Marshall Digital Scholar: https://mds.marshall.edu/sm_bm/228 Hum Genet (2016) 135:1329–1341 DOI 10.1007/s00439-016-1717-z ORIGINAL INVESTIGATION Multipoint genome‑wide linkage scan for nonword repetition in a multigenerational family further supports chromosome 13q as a locus for verbal trait disorders D. -

Comprehensive Analysis Reveals Novel Gene Signature in Head and Neck Squamous Cell Carcinoma: Predicting Is Associated with Poor Prognosis in Patients
5892 Original Article Comprehensive analysis reveals novel gene signature in head and neck squamous cell carcinoma: predicting is associated with poor prognosis in patients Yixin Sun1,2#, Quan Zhang1,2#, Lanlin Yao2#, Shuai Wang3, Zhiming Zhang1,2 1Department of Breast Surgery, The First Affiliated Hospital of Xiamen University, School of Medicine, Xiamen University, Xiamen, China; 2School of Medicine, Xiamen University, Xiamen, China; 3State Key Laboratory of Cellular Stress Biology, School of Life Sciences, Xiamen University, Xiamen, China Contributions: (I) Conception and design: Y Sun, Q Zhang; (II) Administrative support: Z Zhang; (III) Provision of study materials or patients: Y Sun, Q Zhang; (IV) Collection and assembly of data: Y Sun, L Yao; (V) Data analysis and interpretation: Y Sun, S Wang; (VI) Manuscript writing: All authors; (VII) Final approval of manuscript: All authors. #These authors contributed equally to this work. Correspondence to: Zhiming Zhang. Department of Surgery, The First Affiliated Hospital of Xiamen University, Xiamen, China. Email: [email protected]. Background: Head and neck squamous cell carcinoma (HNSC) remains an important public health problem, with classic risk factors being smoking and excessive alcohol consumption and usually has a poor prognosis. Therefore, it is important to explore the underlying mechanisms of tumorigenesis and screen the genes and pathways identified from such studies and their role in pathogenesis. The purpose of this study was to identify genes or signal pathways associated with the development of HNSC. Methods: In this study, we downloaded gene expression profiles of GSE53819 from the Gene Expression Omnibus (GEO) database, including 18 HNSC tissues and 18 normal tissues. -

A Community-Based Transcriptomics Classification and Nomenclature Of
COMMENT | FOCUS comment | FOCUS A community-based transcriptomics classifcation and nomenclature of neocortical cell types To understand the function of cortical circuits, it is necessary to catalog their cellular diversity. Past attempts to do so using anatomical, physiological or molecular features of cortical cells have not resulted in a unifed taxonomy of neuronal or glial cell types, partly due to limited data. Single-cell transcriptomics is enabling, for the frst time, systematic high-throughput measurements of cortical cells and generation of datasets that hold the promise of being complete, accurate and permanent. Statistical analyses of these data reveal clusters that often correspond to cell types previously defned by morphological or physiological criteria and that appear conserved across cortical areas and species. To capitalize on these new methods, we propose the adoption of a transcriptome-based taxonomy of cell types for mammalian neocortex. This classifcation should be hierarchical and use a standardized nomenclature. It should be based on a probabilistic defnition of a cell type and incorporate data from diferent approaches, developmental stages and species. A community-based classifcation and data aggregation model, such as a knowledge graph, could provide a common foundation for the study of cortical circuits. This community-based classifcation, nomenclature and data aggregation could serve as an example for cell type atlases in other parts of the body. Rafael Yuste, Michael Hawrylycz, Nadia Aalling, Argel Aguilar-Valles, Detlev Arendt, Ruben Armananzas Arnedillo, Giorgio A. Ascoli, Concha Bielza, Vahid Bokharaie, Tobias Borgtoft Bergmann, Irina Bystron, Marco Capogna, Yoonjeung Chang, Ann Clemens, Christiaan P. J. de Kock, Javier DeFelipe, Sandra Esmeralda Dos Santos, Keagan Dunville, Dirk Feldmeyer, Richárd Fiáth, Gordon James Fishell, Angelica Foggetti, Xuefan Gao, Parviz Ghaderi, Natalia A. -

Table S1. 103 Ferroptosis-Related Genes Retrieved from the Genecards
Table S1. 103 ferroptosis-related genes retrieved from the GeneCards. Gene Symbol Description Category GPX4 Glutathione Peroxidase 4 Protein Coding AIFM2 Apoptosis Inducing Factor Mitochondria Associated 2 Protein Coding TP53 Tumor Protein P53 Protein Coding ACSL4 Acyl-CoA Synthetase Long Chain Family Member 4 Protein Coding SLC7A11 Solute Carrier Family 7 Member 11 Protein Coding VDAC2 Voltage Dependent Anion Channel 2 Protein Coding VDAC3 Voltage Dependent Anion Channel 3 Protein Coding ATG5 Autophagy Related 5 Protein Coding ATG7 Autophagy Related 7 Protein Coding NCOA4 Nuclear Receptor Coactivator 4 Protein Coding HMOX1 Heme Oxygenase 1 Protein Coding SLC3A2 Solute Carrier Family 3 Member 2 Protein Coding ALOX15 Arachidonate 15-Lipoxygenase Protein Coding BECN1 Beclin 1 Protein Coding PRKAA1 Protein Kinase AMP-Activated Catalytic Subunit Alpha 1 Protein Coding SAT1 Spermidine/Spermine N1-Acetyltransferase 1 Protein Coding NF2 Neurofibromin 2 Protein Coding YAP1 Yes1 Associated Transcriptional Regulator Protein Coding FTH1 Ferritin Heavy Chain 1 Protein Coding TF Transferrin Protein Coding TFRC Transferrin Receptor Protein Coding FTL Ferritin Light Chain Protein Coding CYBB Cytochrome B-245 Beta Chain Protein Coding GSS Glutathione Synthetase Protein Coding CP Ceruloplasmin Protein Coding PRNP Prion Protein Protein Coding SLC11A2 Solute Carrier Family 11 Member 2 Protein Coding SLC40A1 Solute Carrier Family 40 Member 1 Protein Coding STEAP3 STEAP3 Metalloreductase Protein Coding ACSL1 Acyl-CoA Synthetase Long Chain Family Member 1 Protein -

Systematic Detection of Brain Protein-Coding Genes Under Positive Selection During Primate Evolution and Their Roles in Cognition
Downloaded from genome.cshlp.org on October 7, 2021 - Published by Cold Spring Harbor Laboratory Press Title: Systematic detection of brain protein-coding genes under positive selection during primate evolution and their roles in cognition Short title: Evolution of brain protein-coding genes in humans Guillaume Dumasa,b, Simon Malesysa, and Thomas Bourgerona a Human Genetics and Cognitive Functions, Institut Pasteur, UMR3571 CNRS, Université de Paris, Paris, (75015) France b Department of Psychiatry, Université de Montreal, CHU Ste Justine Hospital, Montreal, QC, Canada. Corresponding author: Guillaume Dumas Human Genetics and Cognitive Functions Institut Pasteur 75015 Paris, France Phone: +33 6 28 25 56 65 [email protected] Dumas, Malesys, and Bourgeron 1 of 40 Downloaded from genome.cshlp.org on October 7, 2021 - Published by Cold Spring Harbor Laboratory Press Abstract The human brain differs from that of other primates, but the genetic basis of these differences remains unclear. We investigated the evolutionary pressures acting on almost all human protein-coding genes (N=11,667; 1:1 orthologs in primates) based on their divergence from those of early hominins, such as Neanderthals, and non-human primates. We confirm that genes encoding brain-related proteins are among the most strongly conserved protein-coding genes in the human genome. Combining our evolutionary pressure metrics for the protein- coding genome with recent datasets, we found that this conservation applied to genes functionally associated with the synapse and expressed in brain structures such as the prefrontal cortex and the cerebellum. Conversely, several genes presenting signatures commonly associated with positive selection appear as causing brain diseases or conditions, such as micro/macrocephaly, Joubert syndrome, dyslexia, and autism. -
Downloaded from the Mouse Lysosome Gene Database, Mlgdb
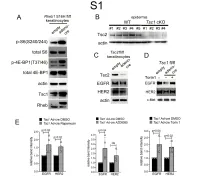
1 Supplemental Figure Legends 2 3 Supplemental Figure S1: Epidermal-specific mTORC1 gain-of-function models show 4 increased mTORC1 activation and down-regulate EGFR and HER2 protein expression in a 5 mTORC1-sensitive manner. (A) Immunoblotting of Rheb1 S16H flox/flox keratinocyte cultures 6 infected with empty or adenoviral cre recombinase for markers of mTORC1 (p-S6, p-4E-BP1) 7 activity. (B) Tsc1 cKO epidermal lysates also show decreased expression of TSC2 by 8 immunoblotting of the same experiment as in Figure 2A. (C) Immunoblotting of Tsc2 flox/flox 9 keratinocyte cultures infected with empty or adenoviral cre recombinase showing decreased EGFR 10 and HER2 protein expression. (D) Expression of EGFR and HER2 was decreased in Tsc1 cre 11 keratinocytes compared to empty controls, and up-regulated in response to Torin1 (1µM, 24 hrs), 12 by immunoblot analyses. Immunoblots are contemporaneous and parallel from the same biological 13 replicate and represent the same experiment as depicted in Figure 7B. (E) Densitometry 14 quantification of representative immunoblot experiments shown in Figures 2E and S1D (r≥3; error 15 bars represent STDEV; p-values by Student’s T-test). 16 17 18 19 20 21 22 23 Supplemental Figure S2: EGFR and HER2 transcription are unchanged with epidermal/ 24 keratinocyte Tsc1 or Rptor loss. Egfr and Her2 mRNA levels in (A) Tsc1 cKO epidermal lysates, 25 (B) Tsc1 cKO keratinocyte lysates and(C) Tsc1 cre keratinocyte lysates are minimally altered 26 compared to their respective controls. (r≥3; error bars represent STDEV; p-values by Student’s T- 27 test). -

Cell Type Marker Enrichment Across Brain Regions and Experimental Conditions
Cell type marker enrichment across brain regions and experimental conditions by Powell Patrick Cheng Tan B. Sc. (Honours), Simon Fraser University, 2010 A THESIS SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF Master of Science in THE FACULTY OF GRADUATE STUDIES (Bioinformatics) The University Of British Columbia (Vancouver) November 2012 c Powell Patrick Cheng Tan, 2012 Abstract The first chapter of this thesis explored the dominant gene expression pattern in the adult human brain. We discovered that the largest source of variation can be explained by cell type marker expression. Across brain regions, expression of neuron cell type markers are anti-correlated with the expression of oligodendrocyte cell type markers. Next, we explored gene function convergence and divergence in the adult mouse brain. Our contributions are as follows. First, we provide candidate cell type markers for investigating specific cell type populations. Second, we highlight orthologous genes that show functional divergence between human and mouse brains. In the second chapter, we present our preliminary work on the effects of tissue types and experimen- tal conditions on human microarray studies. First, we measured the expression and differential expression levels of tissue-enriched genes. Next, we identified modules with similar expression levels and differen- tial expression p-values. Our results show that expression levels reflect tissue type variation. In contrast, differential expression levels are more complex, owing to the large diversity of experimental conditions in the data. In summary, our work provides a different perspective on the functional roles of genes in human microarray studies. ii Table of Contents Abstract . -
Can We Treat Congenital Blood Disorders by Transplantation Of
Can we Treat Congenital Blood Disorders by Transplantation of Stem Cells, Gene Therapy to the Fetus? Panicos Shangaris University College London 2019 A thesis submitted for the degree of Doctor of Philosophy 1 Declaration I, Panicos Shangaris confirm that the work presented in this thesis is my own. Where information has been derived from other sources, I confirm that this has been indicated in the thesis. 2 Abstract Congenital diseases such as blood disorders are responsible for over a third of all pediatric hospital admissions. In utero transplantation (IUT) could cure affected fetuses but so far in humans, successful IUT has been limited to fetuses with severe immunologic defects, due to the maternal immune system and a functionally developed fetal immune system. I hypothesised that using autologous fetal cells could overcome the barriers to engraftment. Previous studies show that autologous haematopoietic progenitors can be easily derived from amniotic fluid (AF), and they can engraft long term into fetal sheep. In normal mice, I demonstrated that IUT of mouse AFSC results in successful haematopoietic engraftment in immune-competent mice. Congenic AFSCs appear to have a significant advantage over allogenic AFSCs. This was seen both by their end haematopoietic potential and the immune response of the host. Expansion of haematopoietic stem cells (HSC) has been a complicated and demanding process. To achieve adequate numbers for autologous stem cells for IUT, HSCs need to be expanded efficiently. I expanded and compared AFSCs, fetal liver stem cells and bone marrow stem cells. Culturing and expanding fetal and adult stem cells in embryonic stem cell conditions maintained their haematopoietic potential. -

Whole Exome Sequencing in Adult-Onset Hearing Loss Reveals A
Lewis et al. BMC Medical Genomics (2018) 11:77 https://doi.org/10.1186/s12920-018-0395-1 RESEARCHARTICLE Open Access Whole exome sequencing in adult-onset hearing loss reveals a high load of predicted pathogenic variants in known deafness-associated genes and identifies new candidate genes Morag A. Lewis1,2, Lisa S. Nolan3, Barbara A. Cadge3, Lois J. Matthews4, Bradley A. Schulte4, Judy R. Dubno4, Karen P. Steel1,2† and Sally J. Dawson3*† Abstract Background: Deafness is a highly heterogenous disorder with over 100 genes known to underlie human non- syndromic hearing impairment. However, many more remain undiscovered, particularly those involved in the most common form of deafness: adult-onset progressive hearing loss. Despite several genome-wide association studies of adult hearing status, it remains unclear whether the genetic architecture of this common sensory loss consists of multiple rare variants each with large effect size or many common susceptibility variants each with small to medium effects. As next generation sequencing is now being utilised in clinical diagnosis, our aim was to explore the viability of diagnosing the genetic cause of hearing loss using whole exome sequencing in individual subjects as in a clinical setting. Methods: We performed exome sequencing of thirty patients selected for distinct phenotypic sub-types from well- characterised cohorts of 1479 people with adult-onset hearing loss. Results: Every individual carried predicted pathogenic variants in at least ten deafness-associated genes; similar findings were obtained from an analysis of the 1000 Genomes Project data unselected for hearing status. We have identified putative causal variants in known deafness genes and several novel candidate genes, including NEDD4 and NEFH that were mutated in multiple individuals. -

Histone H2bub1 Deubiquitylation Is Essential for Mouse Development, but Does Not Regulate Global RNA Polymerase II Transcription
Cell Death & Differentiation (2021) 28:2385–2403 https://doi.org/10.1038/s41418-021-00759-2 ARTICLE Histone H2Bub1 deubiquitylation is essential for mouse development, but does not regulate global RNA polymerase II transcription 1,2,3,4 1,2,3,4,6 1,2,3,4,5 1,2,3,4 1,2,3,4 Fang Wang ● Farrah El-Saafin ● Tao Ye ● Matthieu Stierle ● Luc Negroni ● 1,2,3,4 1,2,3,4 1,2,3,4 1,2,3,4 1,2,3,4 Matej Durik ● Veronique Fischer ● Didier Devys ● Stéphane D. Vincent ● László Tora Received: 7 July 2020 / Revised: 18 February 2021 / Accepted: 23 February 2021 / Published online: 17 March 2021 © The Author(s) 2021. This article is published with open access Abstract Co-activator complexes dynamically deposit post-translational modifications (PTMs) on histones, or remove them, to regulate chromatin accessibility and/or to create/erase docking surfaces for proteins that recognize histone PTMs. SAGA (Spt-Ada-Gcn5 Acetyltransferase) is an evolutionary conserved multisubunit co-activator complex with modular organization. The deubiquitylation module (DUB) of mammalian SAGA complex is composed of the ubiquitin-specific protease 22 (USP22) and three adaptor proteins, ATXN7, ATXN7L3 and ENY2, which are all needed for the full activity of 1234567890();,: 1234567890();,: the USP22 enzyme to remove monoubiquitin (ub1) from histone H2B. Two additional USP22-related ubiquitin hydrolases (called USP27X or USP51) have been described to form alternative DUBs with ATXN7L3 and ENY2, which can also deubiquitylate H2Bub1. Here we report that USP22 and ATXN7L3 are essential for normal embryonic development of mice, however their requirements are not identical during this process, as Atxn7l3−/− embryos show developmental delay already at embryonic day (E) 7.5, while Usp22−/− embryos are normal at this stage, but die at E14.5.