System Identification for Tide Prediction in the Venetian Lagoon
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MOSE (EXPERIMENTAL ELECTROMECHANICAL MODULE; ITALIAN: MODULO SPERIMENTALE ELETTROMECCANICO) Overview / Summary of the Initiative
MOSE (EXPERIMENTAL ELECTROMECHANICAL MODULE; ITALIAN: MODULO SPERIMENTALE ELETTROMECCANICO) Overview / summary of the initiative Title: MoSE (Experimental Electromechanical Module; Italian: MOdulo Sperimentale Elettromeccanico) Country: Italy (Veneto region) Thematic area: Security, Climate change Objective(s): 1. To protect from flooding the city of Venice and the Venetian Lagoon, with its towns, villages and inhabitants along with its iconic historic, artistic and environmental heritage. 2. To contribute to the socio-economic growth of the area and hence to the development of the port and related activities. 3. To guarantee the existing and future port activities inside the Lagoon in its various specificities of Chioggia, Cavallino and Venice. Timeline: The launch of the project started in 1973, when for the first time the Italian Government took in consideration the realisation of mechanic structures to prevent Venice from flooding. 2003 (start of the works)-2019 (estimation) Scale of the initiative: EUR 5.493 million (2014 estimation) Scope of the initiative • Focused on new knowledge creation (basic research, TRLs 1-4): TO A CERTAIN EXTENT; the development and following implementation of the MoSE project have focused on knowledge creation and prototypes development since the 1980s. However, this is useful to the construction at the three inlets of the Venice lagoon and mobile barriers. • Focused on knowledge application (applied research, TRLs 5-9): YES; the MoSE project aims to apply the developed technological solutions and to demonstrate its validity. Source of funding (public/private/public-private): Public funding: since 2003 (year of start of the works) the national government has been the financial promoter of the MoSE. -
Prediction Error Methods and Pseudo-Linear Regressions
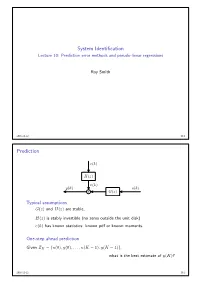
System Identification Lecture 10: Prediction error methods and pseudo-linear regressions Roy Smith 2016-11-22 10.1 Prediction e k p q H z p q v k y k p q u k p q G z p q ` p q Typical assumptions G z and H z are stable, p q p q H z is stably invertible (no zeros outside the unit disk) p q e k has known statistics: known pdf or known moments. p q One-step ahead prediction Given ZK u 0 , y 0 , . , u K 1 , y K 1 , “ t p q p q p ´ q p ´ qu what is the best estimate of y K ? p q 2016-11-22 10.2 Prediction v k e k p q H z p q p q Noise model invertibility Given, v k , k 0,...,K 1, can we determine e k , k 0,...,K 1? p q “ ´ p q “ ´ 8 Inverse filter: Hinv z : e k hinv i v k i p q p q “ i 0 p q p ´ q ÿ“ We also want the inverse filter to be causal and stable: 8 hinv k 0, k 0, and hinv k . p q “ ă k 0 | p q| ă 8 ÿ“ If H z has no zeros for z 1, then, p q | | ě 1 Hinv z . p q “ H z p q 2016-11-22 10.3 Prediction v k e k p q H z p q p q One step ahead prediction Given measurements of v k , k 0,...,K 1, can we predict v K ? p q “ ´ p q Assume that we know H z , how much can we say about v K ? p q p q Assume also that H z is monic (h 0 1). -

(All.10) +Relazione ISPRA 2010.Pdf
ATTIVITÀ DI MONITORAGGIO PER LA BONIFICA DEI FONDALI ANTISTANTI IL TERMINAL RAVANO NEL PORTO DELLA SPEZIA RELAZIONE TECNICA Luglio 2010 PM-EL-LI-P-01.11 PM-El-LI-P-01.11 Responsabile del Dipartimento II ex ICRAM Dott. Massimo Gabellini Coordinatore scientifico Dott.ssa Antonella Ausili Responsabili Scientifici ISPRA del Progetto Dott. Ing. Elena Mumelter Dott.ssa Maria Elena Piccione Staff tecnico ISPRA Francesco Loreti Ing. Lorenzo Rossi Ing. Andrea Salmeri Dott.ssa Antonella Tornato Laboratorio contaminanti organici ISPRA Dott. Giulio Sesta Laila Baklouti Giuseppina Ciuffa Andrea Colasanti Dott.ssa Anna Lauria Andeka de la Fuente Origlia Laboratorio ecotossicologia ISPRA Dott. Fulvio Onorati Dott. Giacomo Martuccio Giordano Ruggiero Dott.ssa Angela Sarni ISTITUTO SUPERIORE DI SANITA’ Dott.ssa Eleonora Beccaloni Dott.ssa Rosa Paradiso Dott.ssa Federica Scaini UNIVERSITÀ DI SIENA - DIPARTIMENTO DI SCIENZE AMBIENTALI “G. SARFATTI” Dott.ssa Cristina Fossi Dott.ssa Silvia Casini Dott.ssa Letizia Marsili Dott.ssa Daniela Bucalossi Dott. Gabriele Mori Dott.ssa Serena Porcelloni Dott. Giacomo Stefanini Dott.ssa Silvia Maltese 2/97 PM-El-LI-P-01.11 ATTIVITÀ DI MONITORAGGIO PER LA BONIFICA DEI FONDALI ANTISTANTI IL TERMINAL RAVANO NEL PORTO DELLA SPEZIA RELAZIONE TECNICA SOMMARIO 1 INTRODUZIONE .................................................................................................... 5 2 PIANO DI MONITORAGGIO................................................................................... 5 2.1 Piano di monitoraggio ante operam................................................................. -

10. Prediction Error Methods (PEM)
EE531 - System Identification Jitkomut Songsiri 6. Prediction Error Methods (PEM) • description • optimal prediction • examples • statistical results • computational aspects 6-1 Description idea: determine the model parameter θ such that "(t; θ) = y(t) − y^(tjt − 1; θ) is small y^(tjt − 1; θ) is a prediction of y(t) given the data up to time t − 1 and based on θ general linear predictor: y^(tjt − 1; θ) = N(L; θ)y(t) + M(L; θ)u(t) where M and N must contain one pure delay, i.e., N(0; θ) = 0;M(0; θ) = 0 example: y^(tjt − 1; θ) = 0:5y(t − 1) + 0:1y(t − 2) + 2u(t − 1) Prediction Error Methods (PEM) 6-2 Elements of PEM one has to make the following choices, in order to define the method • model structure: the parametrization of G(L; θ);H(L; θ) and Λ(θ) as a function of θ • predictor: the choice of filters N; M once the model is specified • criterion: define a scalar-valued function of "(t; θ) that will assess the performance of the predictor we commonly consider the optimal mean square predictor the filters N and M are chosen such that the prediction error has small variance Prediction Error Methods (PEM) 6-3 Loss function let N be the number of data points sample covariance matrix: 1 XN R(θ) = "(t; θ)"T (t; θ) N t=1 R(θ) is a positive semidefinite matrix (and typically pdf when N is large) loss function: scalar-valued function defined on positive matrices R f(R(θ)) f must be monotonically increasing, i.e., let X ≻ 0 and for any ∆X ⪰ 0 f(X + ∆X) ≥ f(X) Prediction Error Methods (PEM) 6-4 Example 1 f(X) = tr(WX) where W ≻ 0 is a weighting matrix f(X + ∆X) = tr(WX) + tr(W ∆X) ≥ f(X) (tr(W ∆X) ≥ 0 because if A ⪰ 0;B ⪰ 0, then tr(AB) ≥ 0) Example 2 f(X) = det X f(X + ∆X) − f(X) = det(X1/2(I + X−1/2∆XX−1/2)X1/2) − det X = det X[det(I + X−1/2∆XX−1/2) − 1] " # Yn −1/2 −1/2 = det X (1 + λk(X ∆XX )) − 1 ≥ 0 k=1 −1/2 −1/2 the last inequalty follows from X ∆XX ⪰ 0, so λk ≥ 0 for all k both examples satisfy f(X + ∆X) = f(X) () ∆X = 0 Prediction Error Methods (PEM) 6-5 Procedures in PEM 1. -

The Mose Machine
THE MOSE MACHINE An anthropological approach to the building oF a Flood safeguard project in the Venetian Lagoon [Received February 1st 2021; accepted February 16th 2021 – DOI: 10.21463/shima.104] Rita Vianello Ca Foscari University, Venice <[email protected]> ABSTRACT: This article reconstructs and analyses the reactions and perceptions of fishers and inhabitants of the Venetian Lagoon regarding flood events, ecosystem fragility and the saFeguard project named MOSE, which seems to be perceived by residents as a greater risk than floods. Throughout the complex development of the MOSE project, which has involved protracted legislative and technical phases, public opinion has been largely ignored, local knowledge neglected in Favour oF technical agendas and environmental impact has been largely overlooked. Fishers have begun to describe the Lagoon as a ‘sick’ and rapidly changing organism. These reports will be the starting point For investigating the fishers’ interpretations oF the environmental changes they observe during their daily Fishing trips. The cause of these changes is mostly attributed to the MOSE’S invasive anthropogenic intervention. The lack of ethical, aFFective and environmental considerations in the long history of the project has also led to opposition that has involved a conFlict between local and technical knowledge. KEYWORDS: Venetian Lagoon, acqua alta, MOSE dams, traditional ecological knowledge, small-scale Fishing. Introduction Sotto acqua stanno bene solo i pesci [Only the fish are fine under the sea]1 This essay focuses on the reactions and perceptions of fishers facing flood events, ecosystem changes and the saFeguarding MOSE (Modulo Sperimentale Elettromeccanico – ‘Experimental Electromechanical Module’) project in the Venetian Lagoon. -

5 Identification Using Prediction Error Methods
5 Identification using Prediction Error Methods The previous chapters have shown how the dynamic behaviour of a civil engineering structure can be modelled by a discrete-time ARMAV model or an equivalent stochastic state space realization. The purpose of this chapter is to investigate how an estimate of a p-variate discrete-time model can be obtained from measurements of the response y(tkk). It is assumed that y(t ) is a realization of a Gaussian stochastic process and thus assumed stationary. The stationarity assumption implies that the behaviour of the underlying system can be represented by a time-invariant model. In the following, the general ARMAV(na,nc), for na nc, model will be addressed. In chapter 2, it was shown that this model can be equivalently represented by an m- dimensional state space realization of the innovation form, with m na#p. No matter how the discrete-time model is represented, all adjustable parameters of the model are assembled in a parameter vector , implying that the transfer function description of the discrete-time model becomes y(tk ) H(q, )e(tk ), k 1, 2, ... , N (5.1) T E e(tk )e (tks ) ( ) (s) The dimension of the vectors y(tkk) and e(t ) are p × 1. Since there is no unique way of computing an estimate of (5.1), it is necessary to select an appropriate approach that balances between the required accuracy and computational effort. The approach used in this thesis is known as the Prediction Error Method (PEM), see Ljung [71]. The reason for this choice is that the PEM for Gaussian distributed prediction errors is asymptotic unbiased and efficient. -

ART HISTORY of VENICE HA-590I (Sec
Gentile Bellini, Procession in Saint Mark’s Square, oil on canvas, 1496. Gallerie dell’Accademia, Venice ART HISTORY OF VENICE HA-590I (sec. 01– undergraduate; sec. 02– graduate) 3 credits, Summer 2016 Pratt in Venice––Pratt Institute INSTRUCTOR Joseph Kopta, [email protected] (preferred); [email protected] Direct phone in Italy: (+39) 339 16 11 818 Office hours: on-site in Venice immediately before or after class, or by appointment COURSE DESCRIPTION On-site study of mosaics, painting, architecture, and sculpture of Venice is the primary purpose of this course. Classes held on site alternate with lectures and discussions that place material in its art historical context. Students explore Byzantine, Gothic, Renaissance, Baroque examples at many locations that show in one place the rich visual materials of all these periods, as well as materials and works acquired through conquest or collection. Students will carry out visually- and historically-based assignments in Venice. Upon return, undergraduates complete a paper based on site study, and graduate students submit a paper researched in Venice. The Marciana and Querini Stampalia libraries are available to all students, and those doing graduate work also have access to the Cini Foundation Library. Class meetings (refer to calendar) include lectures at the Università Internazionale dell’ Arte (UIA) and on-site visits to churches, architectural landmarks, and museums of Venice. TEXTS • Deborah Howard, Architectural History of Venice, reprint (New Haven and London: Yale University Press, 2003). [Recommended for purchase prior to departure as this book is generally unavailable in Venice; several copies are available in the Pratt in Venice Library at UIA] • David Chambers and Brian Pullan, with Jennifer Fletcher, eds., Venice: A Documentary History, 1450– 1630 (Toronto: University of Toronto Press, 2001). -

Wavelet Analysis for System Identification∗
Wavelet analysis for system identification∗ 大阪教育大学・数理科学 芦野 隆一 (Ryuichi Ashino) Mathematical Sciences, Osaka Kyoiku University 大阪電気通信大学・数理科学研究センター 萬代 武史 (Takeshi Mandai) Research Center for Physics and Mathematics, Osaka Electro-Communication University 大阪教育大学・情報科学 守本 晃 (Akira Morimoto) Information Science, Osaka Kyoiku University Abstract By the Schwartz kernel theorem, to every continuous linear sys- tem there corresponds a unique distribution, called kernel distribution. Formulae using wavelet transform to access time-frequency informa- tion of kernel distributions are deduced. A new wavelet based system identification method for health monitoring systems is proposed as an application of a discretized formula. 1 System Identification A system L illustrated in Figure 1 is an object in which variables of different kinds interact and produce observable signals. The observable signals g that are of interest to us are called outputs. The system is also affected by external stimuli. External signals f that can be manipulated by the observer are called inputs. Others are called disturbances and can be divided into those, denoted by w, that are directly measured, and those, denoted by v, that are only observed through their influence on the output. Mathematically, a system can be regarded as a mapping which relates inputs to outputs. Hereafter, we will use the terminology “system” rather ∗This research was partially supported by the Japanese Ministry of Education, Culture, Sports, Science and Technology, Grant-in-Aid for Scientific Research (C), 15540170 (2003– 2004), and by the Japan Society for the Promotion of Science, Japan-U.S. Cooperative Science Program (2003–2004). 1 Unmeasured Measured disturbance v disturbance w System L Output g Input f Figure 1: System L. -

Localization and System Identification of a Quadcopter AU V
Western Michigan University ScholarWorks at WMU Master's Theses Graduate College 6-2014 Localization and System Identification of a Quadcopter AU V Kenneth Befus Follow this and additional works at: https://scholarworks.wmich.edu/masters_theses Part of the Aeronautical Vehicles Commons, Navigation, Guidance, Control and Dynamics Commons, and the Propulsion and Power Commons Recommended Citation Befus, Kenneth, "Localization and System Identification of a Quadcopter AU V" (2014). Master's Theses. 499. https://scholarworks.wmich.edu/masters_theses/499 This Masters Thesis-Open Access is brought to you for free and open access by the Graduate College at ScholarWorks at WMU. It has been accepted for inclusion in Master's Theses by an authorized administrator of ScholarWorks at WMU. For more information, please contact [email protected]. LOCALIZATION AND SYSTEM IDENTIFICATION OF A QUADCOPTER UAV by Kenneth Befus A thesis submitted to the Graduate College in partial fulfillment of the requirements for the degree of Master of Science in Engineering Department of Mechanical and Aeronautical Engineering Western Michigan University June 2014 Doctoral Committee: Kapseong Ro, Ph.D., Chair Koorosh Naghshineh, Ph.D. James W. Kamman, Ph.D. LOCALIZATION AND SYSTEM IDENTIFICATION OF A QUADCOPTER UAV Kenneth Befus, M.S.E. Western Michigan University, 2014 The research conducted explores the comparison of several trilateration algorithms as they apply to the localization of a quadcopter micro air vehicle (MAV). A localization system is developed employing a network of combined ultrasonic/radio frequency sensors used to wirelessly provide range (distance) measurements defining the location of the quadcopter in 3-dimensional space. A Monte Carlo simulation is conducted using the extrinsic parameters of the localization system to evaluate the adequacy of each trilateration method as it applies to this specific quadcopter application. -

Adriatic Odyssey
confluence of historic cultures. Under the billowing sails of this luxurious classical archaeologist who is a curator of Greek and Roman art at The Metropolitan Museum of Art. Starting in the lustrous canals of Venice, journey to Ravenna, former capital of the Western Roman Empire, to admire the 5th- and 6th-century mosaics of its early Christian churches and the elegant Mausoleum of Galla Placidia. Across the Adriatic in the former Roman province of Dalmatia, call at Split, Croatia, to explore the ruined 4th-century palace of the emperor Diocletian. Sail to the stunning walled city of Dubrovnik, where a highlight will be an exclusive concert in a 16th-century palace. Spartan town of Taranto, home to the exceptional National Archaeological Museum. Nearby, in the UNESCO World Heritage Site of Alberobello, discover hundreds of dome-shaped limestone dwellings called Spend a delightful day at sea and call in Reggio Calabria, where you will behold the 5th-century-B.C. , heroic nude statues of Greek warriors found in the sea nearly 50 years ago. After cruising the Strait of Messina, conclude in Palermo, Sicily, where you can stroll amid its UNESCO-listed Arab-Norman architecture on an optional postlude. On previous Adriatic tours aboard , cabins filled beautiful, richly historic coastlines. At the time of publication, the world Scott Gerloff for real-time information on how we’re working to keep you safe and healthy. You’re invited to savor the pleasures of Sicily by extending your exciting Adriatic Odyssey you can also join the following voyage, “ ” from September 24 to October 2, 2021, and receive $2,500 Venice to Palermo Aboard Sea Cloud II per person off the combined fare for the two trips. -

Sequential Monte Carlo Methods for System Identification (A Talk About
Sequential Monte Carlo methods for system identification (a talk about strategies) \The particle filter provides a systematic way of exploring the state space" Thomas Sch¨on Division of Systems and Control Department of Information Technology Uppsala University. Email: [email protected], www: user.it.uu.se/~thosc112 Joint work with: Fredrik Lindsten (University of Cambridge), Johan Dahlin (Link¨opingUniversity), Johan W˚agberg (Uppsala University), Christian A. Naesseth (Link¨opingUniversity), Andreas Svensson (Uppsala University), and Liang Dai (Uppsala University). [email protected] IFAC Symposium on System Identification (SYSID), Beijing, China, October 20, 2015. Introduction A state space model (SSM) consists of a Markov process x ≥ f tgt 1 that is indirectly observed via a measurement process y ≥ , f tgt 1 x x f (x x ; u ); x = a (x ; u ) + v ; t+1 j t ∼ θ t+1 j t t t+1 θ t t θ;t y x g (y x ; u ); y = c (x ; u ) + e ; t j t ∼ θ t j t t t θ t t θ;t x µ (x ); x µ (x ); 1 ∼ θ 1 1 ∼ θ 1 (θ π(θ)): (θ π(θ)): ∼ ∼ Identifying the nonlinear SSM: Find θ based on y y ; y ; : : : ; y (and u ). Hence, the off-line problem. 1:T , f 1 2 T g 1:T One of the key challenges: The states x1:T are unknown. Aim of the talk: Reveal the structure of the system identification problem arising in nonlinear SSMs and highlight where SMC is used. 1 / 14 [email protected] IFAC Symposium on System Identification (SYSID), Beijing, China, October 20, 2015. -

The Ransom of Mussels in the Lagoon of Venice: When the Louses Become “Black Gold”
International Review of Social Research 2017; 7(1): 22–30 Research Article Open Access Rita Vianello The ransom of mussels in the lagoon of Venice: when the louses become “black gold”. DOI 10.1515/irsr-2017-0004 (and still call them today) “peòci”, that is to say louses. Received: February 1, 2016; Accepted: December 20, 2016 They used to consider them not edible and sometimes Abstract: The article presented here is rooted in our doctoral even poisonous. However today, they are known to have research in Ethnology and Social History developed in the an exquisite taste and all the inhabitants eat them as a lagoon of Venice in 2010-2013. It is a research based on the habit. To paraphrase Hobsbawm (Hobsbawm and Ranger methodology of ethnographic field research, in parallel 1983), we are witnessing an example of insular “invented with the bibliographic and archive research. The fieldwork tradition”, applied to the local feeding. The mussels have was conducted between March 2010 and August 2012 become the object of a curious process: if beforehand they with 21 informants, fishermen aged 20 to 90 years. In this were perceived as venomous, as undesirable shells which article we analyze how the formation of a new food taste were damaging fishing nets, they then became a refined is a process that can be defined “cultural”. We can meet an and sought food served in restaurants and in the festive example in the history of mussel-farming on the island of moments and user-friendly. Pellestrina, an island of fishermen in the southern lagoon The main phenomenon of our study is the change of Venice, where the exploitation of this mollusk as food of attitude particularly interesting from an ethnological and economic resource appears rather late in history.